
Java豆瓣电影爬虫——使用Word2Vec分析电影短评数据
在上篇实现了电影详情和短评数据的抓取。到目前为止,已经抓了2000多部电影电视以及20000多的短评数据。
数据本身没有规律和价值,需要通过分析提炼成知识才有意义。抱着试试玩的想法,准备做一个有关情感分析方面的统计,看看这些评论里面的小伙伴都抱着什么态度来看待自己看过的电影,怀着何种心情写下的短评。
鉴于爬取的是短评数据,少则10来个字,多则百来个字,网上查找了下,发现Google开源的Word2Vec比较合适,于是今天捣鼓了一天,把自己遇到的问题和运行的结果在这里做个总结。
Word2Ve是google 推出的做词嵌入(word embedding)的开源工具。 简单的说,它在给定的语料库上训练一个模型,然后会输出所有出现在语料库上的单词的向量表示,这个向量称为"word embedding"。基于这个向量表示,可以计算词与词之间的关系,例如相似性(同义词等),语义关联性(中国 - 北京 = 英国 - 伦敦)等。
算法的原理如果有兴趣,可以找资料了解。
这里使用Word2Vec的大致流程如下:
1. 获取数据(这里是豆瓣电影短评数据)
2. 数据处理(将短评数据使用分词器分词,并以空格连接分词结果)
3. 训练数据(将上述处理好符合要求的数据作为输入进行训练,得到训练模型)
4. 载入训练模型,分析感兴趣的维度(比如,近义词分词,关联词分析)
Github: https://github.com/NLPchina/Word2VEC_java
获取数据
数据就用短评数据,2万多条,对应的大概是2000多部的电影,一部电影抓的短评数在10条左右。(这个样本量很小了,数量越大,越来接近真实情况。)
将这些短评数据中从数据库(Mysql)中抽出来放入一个txt文档中。

数据处理
主要是对短评分词。显然这里要用到中文分词器,可以选的很多,比如Ansj、IKAnalyzer等等。在我看来都差不多,无非就是做个分词,当然了起码需要过滤停用词,比如“啊”“哦”“的”这样几乎没有意义的词往往出现的频率还比较高,如果不过滤会增加没有意义的权重,影响结果。网上找了个停用词库,已经放云盘上了,点击这里可以下载。
起初准备用Ansj,测试代码也写好了,可以发现停用词库总是加载不上去。
package com.jackie.crawler.doubanmovie.utils;
import org.ansj.recognition.impl.FilterRecognition;
import org.ansj.splitWord.analysis.ToAnalysis;
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.logging.Filter;
/**
* Created by Administrator on 2016/12/3 0003.
*/
public class TokenizerAnalyzerUtils {
public TokenizerAnalyzerUtils(){
}
public static void main(String args[]) {
getAnalyzerResult("不同于计算机,人类一睁眼就能迅速看到和看明白一个场景,因为人的大脑皮层至少有一半以上海量神经元参与了视觉任务的完成。");
}
public static String getAnalyzerResult(String input) {
HashMap<String, String> filterMap = new HashMap<String, String>();
List<String> stopWordsList = getStopWordsList();
FilterRecognition filterRecognition = new FilterRecognition();
filterRecognition.insertStopWords(stopWordsList);
System.out.println(ToAnalysis.parse(input));
return null;
}
private static List<String> getStopWordsList(){
List<String> stopWordList = null;
File stopWordFile = new File(TokenizerAnalyzerUtils.class.getResource("/library/stopwords.dic").getPath());
try {
stopWordList = FileUtils.readLines(stopWordFile, "UTF-8");
} catch (IOException e) {
e.printStackTrace();
System.out.println("fail to load stop word dictionary");
}
return stopWordList;
}
}
有人说Ansj现在已经没人维护了,而且在找资料的过程中,发现很多博文有不一致的地方,或者可能是没有交代清楚吧,比如这里的FileRecognition类是在5.0.2版本才有的,而之前的一个版本居然是0.9,0.9版本用的是FilterModifWord,总之没有成功加载到停用词库,而且显示的结果也不是我想要的。
得到结果如下(包含了停用词的,还有标点符号)
不同于/c,计算机/n,,/w,人类/n,一/m,睁眼/n,就/d,能/v,迅速/ad,看到/v,和/c,看/v,明白/v,一个/m,场景/n,,/w,因为/c,人/n,的/uj,大脑皮层/l,至少/d,有/v,一半/m,以上/f,海量/n,神经元/n,参与/v,了/ul,视觉/n,任务/n,的/uj,完成/v,。/w
后来开始用IKAnalyzer,使用IKAnalyzer倒是异常的顺利
public class TokenizerAnalyzerUtils {
public TokenizerAnalyzerUtils(){
}
public static void main(String args[]) throws IOException {
String tokenizerResult = getAnalyzerResult("不同于计算机,人类一睁眼就能迅速看到和看明白一个场景,因为人的大脑皮层至少有一半以上海量神经元参与了视觉任务的完成。");
System.out.println(tokenizerResult);
}
public static String getAnalyzerResult(String input) {
StringReader sr=new StringReader(input);
IKSegmenter ik=new IKSegmenter(sr, true);//true is use smart
Lexeme lex=null;
List<String> stopWordsList = getStopWordsList();
StringBuilder stringBuilder = new StringBuilder();
try {
while((lex=ik.next())!=null){
if(stopWordsList.contains(lex.getLexemeText())) {
continue;
}
stringBuilder.append(lex.getLexemeText() + Constants.BLANKSPACE);
}
} catch (IOException e) {
e.printStackTrace();
System.out.println("failed to parse input content");
}
return stringBuilder.toString();
}
private static List<String> getStopWordsList(){
List<String> stopWordList = null;
File stopWordFile = new File(TokenizerAnalyzerUtils.class.getResource("/library/stopwords.dic").getPath());
try {
stopWordList = FileUtils.readLines(stopWordFile, Constants.ENCODING);
} catch (IOException e) {
e.printStackTrace();
System.out.println("fail to load stop word dictionary");
}
return stopWordList;
}
}
结果如下:
不同于 计算机 人类 睁眼 就能 明白 场景 为人 大脑皮层 至少有 一半 海量 神经元 参与 视觉
这个结果我很满意^^.
于是这里是IKAnalyzer完成了短评分词,过程如下

总共耗时20s左右,分词后部分结果

注意
这里可能会遇到停用词乱码问题,在加载到停用词文件的时候会发现如下情况
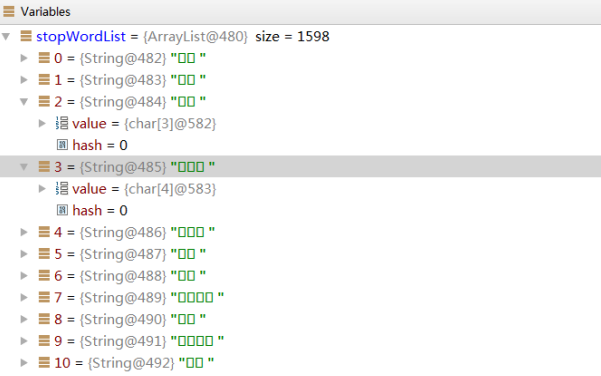
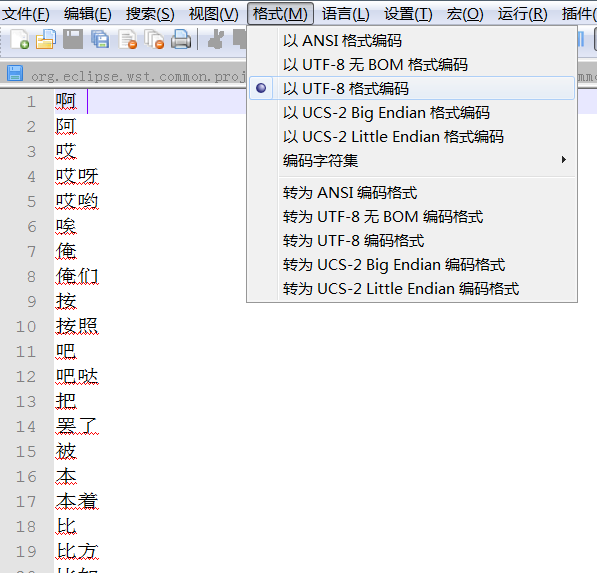
这时候需要打开停用词文件,将其设置以UTF-8编码
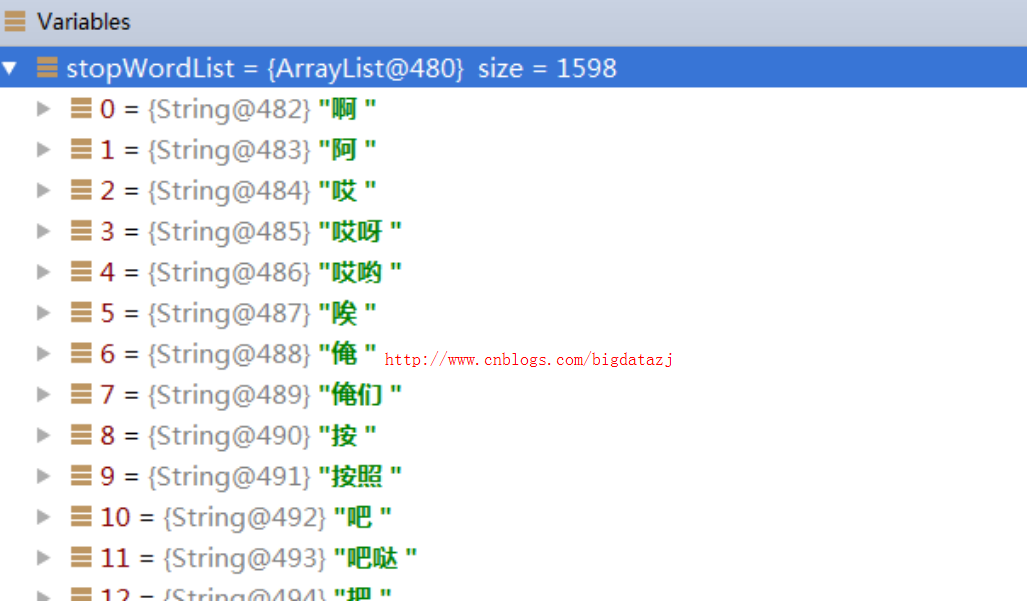
再次加载停用词文件,没有乱码情况
训练数据
有了上述的分词后的文件,就可以作为Word2Vec算法的输入用来训练模型了。
这部分代码可以参看上面的GitHub代码中的Word2VEC.java类。这里稍作修改,完成了数据分词,模型训练和使用。
Learn learn = new Learn();
learn.learnFile(new File("src/main/resource/library/comment/tokenizerResult.txt"));
learn.saveModel(new File("src/main/resource/library/comment/vector.mod"));
这里的tokenizerResult.txt是第二步分词后结果保存的文件, vector.mod是用于存储训练后的模型的。
执行的过程信息如下
alpha:0.025 Progress: 0% alpha:0.02425520272641302 Progress: 2% alpha:0.023510777182349687 Progress: 5% alpha:0.022766202946476896 Progress: 8% alpha:0.02202244651555614 Progress: 11% alpha:0.021277946625588077 Progress: 14% alpha:0.020533446735620017 Progress: 17% alpha:0.019789318575175605 Progress: 20% alpha:0.019045041722921735 Progress: 23% alpha:0.018301433983810438 Progress: 26% alpha:0.0175555215216525 Progress: 29% alpha:0.01681057555625606 Progress: 32% alpha:0.01606689347124003 Progress: 35% alpha:0.01532283965670035 Progress: 38% alpha:0.01457930626349378 Progress: 41% alpha:0.013835772870287213 Progress: 44% alpha:0.013092090785271182 Progress: 47% alpha:0.012348185662540964 Progress: 50% alpha:0.011604503577524936 Progress: 53% alpha:0.010859334574414304 Progress: 56% alpha:0.010115429451684083 Progress: 59% alpha:0.009371673020763324 Progress: 62% alpha:0.008627619206223644 Progress: 65% alpha:0.007880814593208949 Progress: 68% alpha:0.007136091665526695 Progress: 71% alpha:0.006392260888701207 Progress: 74% alpha:0.005648430111875719 Progress: 77% alpha:0.0049033354546698165 Progress: 80% alpha:0.004158240797463914 Progress: 83% alpha:0.0034141126370195035 Progress: 86% alpha:0.0026687949420994093 Progress: 89% alpha:0.001923551593084047 Progress: 92% alpha:0.0011763752505457 Progress: 95% Vocab size: 41817 Words in train file: 336265 sucess train over!
载入训练模型,分析感兴趣的维度
载入模型,挑一个关键字/词,就可以找到与之相关联的近义词,这里挑了一些字词做测试。
Word2VEC vec = new Word2VEC();
vec.loadJavaModel("src/main/resource/library/comment/vector.mod");
List<String> wordList = new ArrayList<String>();
wordList.add("烂片");
wordList.add("画面");
wordList.add("星");
wordList.add("幽默");
for (String word : wordList) {
System.out.println(word + "\t" +
vec.distance(word));
}
于是得到这样的结果
烂片 [找出 0.8132788, 赔得 0.80554706, 国产 0.7825366, low. 0.7741908, com 0.7687579, 给钱 0.767631, 一连 0.7641382, 跑不了 0.7631712, 新锐 0.7623174, 同义词 0.75706816, 稳准狠 0.7499448, 边远 0.7494703, 上榜 0.7416989, 发生地 0.7386223, 不露 0.73250484, 合璧 0.72888064, 强烈要求 0.72720224, ph 0.7261214, 看了 0.7227549, 800万 0.7197921, 评为 0.7159896, 拍 0.7146899, 中港 0.711021, 洗澡水 0.7107486, 尤其在 0.70475745, 回收站 0.6954223, 圈钱 0.69508225, 茴 0.6948879, 预告 0.6924497, 名头 0.69223696, 视频短片 0.69158596, 烂 0.6871433, 海报 0.6825464, trejo 0.68159693, 好吧 0.68023074, visconti 0.6795105, 包场 0.6774618, 解衣 0.67674035, 恐怖片 0.673455] 画面 [老套 0.89498436, 还算 0.8892616, 硬伤 0.88743657, 新意 0.88360095, 整部 0.88049525, 起码 0.87579376, 效果 0.8723363, 剪辑 0.8638494, 整体 0.8612348, 制作 0.86086303, 昏昏欲睡 0.857126, 特效 0.85197854, 打斗 0.85099876, 摄影 0.84997845, 质量 0.84938455, 六段 0.8493726, 逻辑 0.8487664, 弱智 0.84785265, 中规中矩 0.8462457, 紧凑 0.84502685, 抗战 0.84373015, 亮点 0.84305227, 烂了 0.8415472, 狗血 0.8381111, 硬生生 0.8376552, 纪实 0.83595145, 凑合 0.8355879, 速度感 0.8338623, 小成本 0.8309567, 没啥 0.82943296, 糟糕了 0.8270213, 套路 0.82666814, 津津有味 0.82574165, 拖沓 0.82400554, 六分 0.82379186, 设计 0.82302237, 不好 0.8223004, 动作 0.82218575, 场面 0.8185956] 星 [1 0.88681066, 3 0.85820633, 一颗 0.8508274, 4 0.8403223, 两 0.83607787, 挤车 0.8331463, 100人 0.8301175, 拉萨 0.8287235, 小角 0.8236963, 2 0.8233104, 6条 0.8203937, 加 0.81798214, 大热天 0.8086839, 5 0.807189, 1房 0.8015023, 怦然 0.7956209, 一星 0.7947131, 水瓶 0.7909956, 沈迷 0.7895043, 送给 0.78651863, 2.6 0.7715048, 12房 0.77091134, 犹豫 0.7638156, 五花八门 0.7578704, 顆 0.7568228, 我弟 0.75334215, 蠍 0.74807864, 居于 0.7474736, 翠 0.7466134, 吵着 0.74357903, 三颗 0.7402853, 闹着 0.7341734, 羽泉 0.73370975, 保底 0.7296697, 扣 0.7204362, 绝壁 0.7204167, 彤 0.7147855, 14条 0.71267885, 水军 0.7117269] 幽默 [调度 0.94056773, 平面 0.92473197, 没必要 0.91582817, 故事情节 0.9113235, 缓 0.90921956, 笑出来 0.9008162, 轻松愉快 0.89958227, 本该 0.8973848, 掌控 0.8947682, 不俗 0.8913032, 差点 0.89119893, 手持 0.8907271, 不舒服 0.89064366, 很棒 0.8881191, 十几 0.8875753, 捧腹大笑 0.8866181, 色调 0.88600373, 搞怪 0.88330764, 一直都 0.88276887, 都很 0.8826765, 人选 0.88094795, 刺耳 0.8807346, 情爱 0.88056815, 桥段 0.8788211, 成人 0.8787862, 狗咬狗 0.8783484, 灾难 0.8778411, 表现力 0.87725157, 网 0.87571883, 平稳 0.87560874, 更没有 0.8752619, 一乐 0.8751746, 港片 0.87489885, 漫画 0.8747164, 不下来 0.87460196, 万万 0.8739581, 群体性 0.87352765, 推进 0.8735161, 疯癫 0.8726621]
这里每个词后面的系数表示关联性,在0-1之间,数值越大,表示关联性越强。
从这里还是能够看出一些关联性的,比如“烂片”-“赔的”- “low”(居然还有“国产”),“画面”-“老套”-“硬伤”-“紧凑”,“星”-“一颗”-“1”-“送给”, “幽默”-“笑出来”-“轻松愉快”-“很棒”
当然了,如果数据量足够大,我们就能够看到更加有趣的东西了。
至此,我们明白了
- Word2Vec是什么,有什么用,怎么用
- 常用的中文分词器以及具体用法,如何加载停用词库等
- Word2Vec如何训练数据得到模型
- Word2Vec如何使用训练的模型分析有趣的维度
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!如果您想持续关注我的文章,请扫描二维码,关注JackieZheng的微信公众号,我会将我的文章推送给您,并和您一起分享我日常阅读过的优质文章。

友情赞助
如果你觉得博主的文章对你那么一点小帮助,恰巧你又有想打赏博主的小冲动,那么事不宜迟,赶紧扫一扫,小额地赞助下,攒个奶粉钱,也是让博主有动力继续努力,写出更好的文章^^。
1. 支付宝 2. 微信


