
java之HashMap讲解
HashMap是一中比较常用的,也比较好用的集合,是一种键值对(K-V)形式的存储结构
但是hashMap不是线程安全的。
先看一个HashMap的使用实例


1 public static void main(String[] args) {
2 Map<String, Object> hasMap = new HashMap<String, Object>();
3 hasMap.put("name", "zhangsan");
4 hasMap.put("age", 20);
5 hasMap.put("addr", "北京市");
6 hasMap.put(null, null);
7 hasMap.put("info", null);
8 hasMap.put(null, "who");
9
10 for (Map.Entry<String, Object> entry : hasMap.entrySet()) {
11 System.out.println(entry.getKey() + "=" + entry.getValue());
12 }
13 }
输出:
name=zhangsan
age=20
addr=北京市
null=who
info=null
从这个输出的结果我们可以得出一下结论:
a)插入的顺序和迭代输出的顺序不一样。
b)允许Key和Value都为null
c)HashMap如果插入相同的Key,则后面的value将会覆盖前面的Value
二: HashMap的具体实现
HashMap是通过 数组+链表 来实现的,数组长度会通过扩展因子来自动增加。
1:HashMap的构造函数有多个,但是最终的构造函数如下,
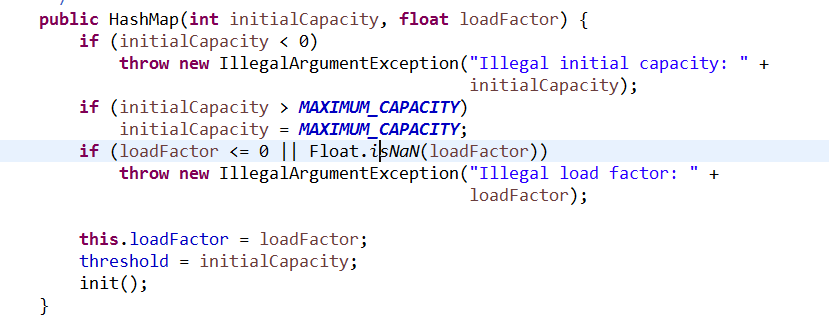
对初始容量(默认为: 16)和扩展因子赋值 (默认值为: 0.75 )。
2: 添加/修改元素
HashMap的一个存储单元为Entry, Entry是HashMap定义的一个内部类,部分结构定义如下

可以发现Entry应该是一个单向链表,属性next表示后继的Entry,但是没有向前的Entry.
HashMap的元素添加就通过put方法来实现的,put方法定义如下;

插入的过程:
1:如果table为空,则初始化table 数组,其中有两个方法的定义如下:
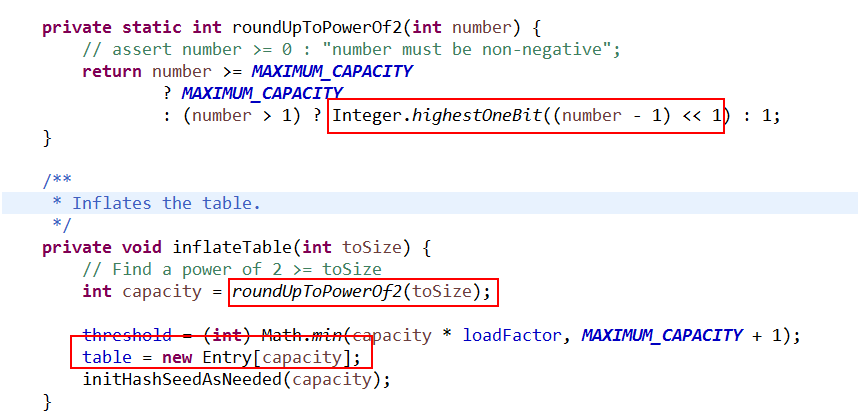
其中 roundUpToPowerOf2 方法是重新计算capacity,如果不是大于MAXIMUM_CAPACITY,并且不为1,必须是 2的N次幂,
做了一个测试,结果
Integer.highestOneBit((5 - 1) << 1) //输出:8
Integer.highestOneBit((26 - 1) << 1) //输出:32
Integer.highestOneBit((64 - 1) << 1) //输出:64
也就是大于等于number的最接近的一个2的N次幂的值。
2:如果key值为null,则直接放在table的0位置
3:计算key的hash值,获取key值在table数组的位置, 查找的方法是利用 & 来进行取模运算,但是这中取模方法必须建立在table的length必须就2的N次幂的基础上。

4: 从table数组中找到 hash值所在的位置,查找是否存在相同的Key值,key的hash值和key值都必须相同;如果存在则覆盖并返回,
5: 如果步骤4中不存在,则执行 addEntry 方法
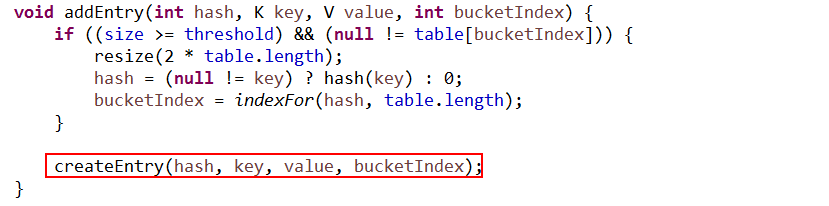

a) 判断是否需要对table扩容,
b) 从table中获取hash值的链表,如果没有,则为null,将当前的k-v 添加到链表的最前面。
HashMap序列化
HashpMap实现了Serializable了接口,但是数据表table有 transient 修饰符,主要是为了避免不同平台HashCode的不一致问题,
所以Java采取了重写自己序列化table的方法,自定义了 writeObject 和 readObject 方法
在writeObject选择将key和value追加到序列化的文件最后面:
hash算法的重要性:
一个好的hash算法可以是key的hash值更均匀的分布在表table中,这样,每个table中的链表可能会更短,提高了查询的效率。
在执行put方法中有一个modCount的变量, 迭代之前先将值赋给 expectedModCount
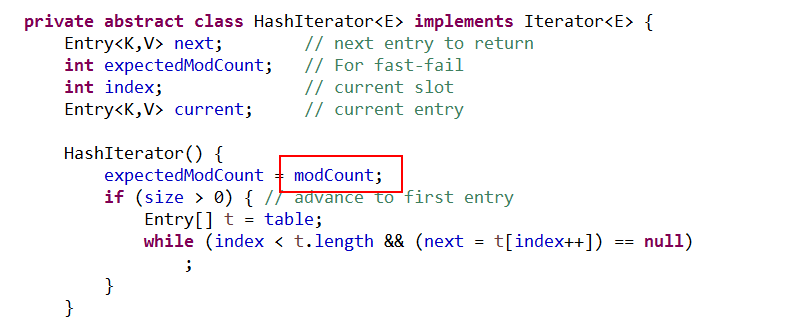
进行迭代的时候会用到,如下图,haoxian
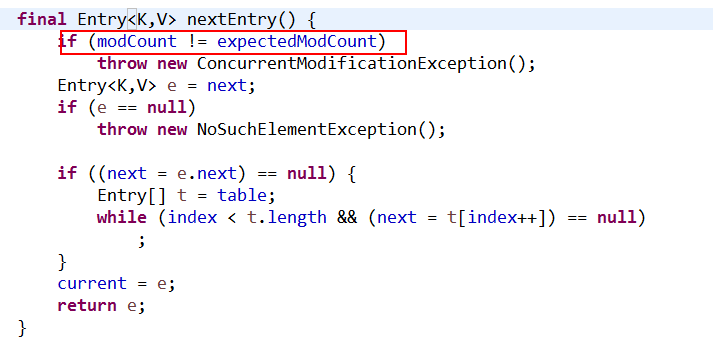
在迭代器遍历的过程中,一旦发现这个对象的modCountt和迭代器中存储的expectedModCount值不一样那就抛异常
Fail-Fast 机制
我们知道 java.util.HashMap 不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。这一策略在源码中的实现是通过 modCount 域,modCount 顾名思义就是修改次数,对HashMap 内容的修改都将增加这个值,那么在迭代器初始化过程中会将这个值赋给迭代器的 expectedModCount。在迭代过程中,判断 modCount 跟 expectedModCount 是否相等,如果不相等就表示已经有其他线程修改了 Map。
所以在遍历那些非线程安全的数据结构时,尽量使用迭代器
fail-safe机制
对于那些线程安全的集合类,在调用iterator方法产生迭代器的时候,会将当前集合的素有元素都做一个快照,即复制一份副本。每次迭代的时候都是访问这个快照内的元素,而不是原集合的元素。代码示例如下:
public static void failSafe() {
List<String> list = new CopyOnWriteArrayList<>();
list.add("item-1");
list.add("item-2");
list.add("item-3");
list.add("item-4");
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String item = it.next();
System.out.println(item);
list.add("itme-5");
}
System.out.println(list.size()); // 会打印出来8,迭代四次,四个新元素插入到了集合中。
}
这种设计的好处是保证了在多线程操纵同一个集合的时候,不会因为某个线程修改了集合,而影响其他正在迭代访问集合的线程,任何对集合结构的修改都会在一个复制的集合上进行修改,因此不会抛出ConcurrentModificationException
fail-safe机制有两个问题
(1)需要复制集合,产生大量的无效对象,一定程度上也增加了内存的消耗
(2)不能正确及时的反应集合中的内容,无法保证读取的数据是目前原始数据结构中的数据。

