
CTR预估中的贝叶斯平滑方法(一)原理及实验介绍
1. 背景介绍
2. 数据的层级结构
我们假设事件的发生并不是相互独立的,相反,在层级结构中相对比较靠近的两个事件的相关性要大于距离较远的两个事件,它们之间拥有很多共通之处。于是,我们便可以利用“相似”事件的信息来丰富某个我们感兴趣的事件(这个事件本事的发生的次数比较少)。具体到我们现有的场景下,可以利用与我们需要预估的事件(比如query-ad pair,或者page-ad pair)的“相似”事件的信息来帮助我们来做出预估计算。
假设有相同account下的N个ad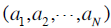 ,以及所在的page,我们感兴趣的是page-ad pair的CTR,于是我们可以利用贝叶斯的方法来结合(1)这个ad本身的信息,以及(2)该page下与这个ad来自相同account的其它ad的信息。我们观测到的点击信息为
,以及所在的page,我们感兴趣的是page-ad pair的CTR,于是我们可以利用贝叶斯的方法来结合(1)这个ad本身的信息,以及(2)该page下与这个ad来自相同account的其它ad的信息。我们观测到的点击信息为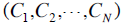 ,这些点击信息源自各个ad的隐含CTR信息
,这些点击信息源自各个ad的隐含CTR信息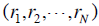 ,点击信息服从二项分布
,点击信息服从二项分布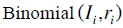 。而隐含的每个ad的CTR,可以看做是来自于它们相同的account的公有信息,其服从贝塔分布
。而隐含的每个ad的CTR,可以看做是来自于它们相同的account的公有信息,其服从贝塔分布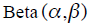 。于是乎,每个ad的隐含CTR值,不仅与观测到的展示点击数据
。于是乎,每个ad的隐含CTR值,不仅与观测到的展示点击数据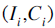 有关,还与其所属的account的整体信息有关,即与
有关,还与其所属的account的整体信息有关,即与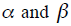 这对超参数有关。我们可以利用二项分布和贝塔分布的共轭特性,计算所有ad所属的相同account的似然函数,然后利用最大似然估计(MLE)来计算超参数
这对超参数有关。我们可以利用二项分布和贝塔分布的共轭特性,计算所有ad所属的相同account的似然函数,然后利用最大似然估计(MLE)来计算超参数 。当有了
。当有了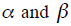 的估计值
的估计值 后,我们便可以得到每个ad的后验估计:
后,我们便可以得到每个ad的后验估计: 。这个后验估计值可以作为一个平滑后的CTR值,它要比单纯地统计CTR
。这个后验估计值可以作为一个平滑后的CTR值,它要比单纯地统计CTR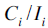 拥有更小的方差,更加稳定。
拥有更小的方差,更加稳定。
3. 数据的连续性
在很多场景下,我们更关心CTR的趋势,而不是一个特定时间点的CTR值。因为对于展示量较少的page-ad pair,某个特定时间点的CTR预估值是包含很大噪声的。我们将展现和点击看做是离散集合的重复观测值,然后使用指数平滑技术进行CTR平滑。
假设对于page-ad pair,我们有M天的展现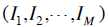 和点击
和点击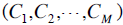 ,然后我们希望预估出第M天的CTR。我们将平滑后的展现和点击记为
,然后我们希望预估出第M天的CTR。我们将平滑后的展现和点击记为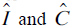 ,它们可由下面公式得到(这里只给出了点击的公式计算,展现也同理):
,它们可由下面公式得到(这里只给出了点击的公式计算,展现也同理):
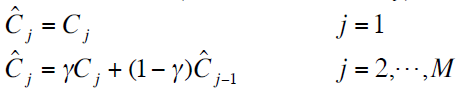
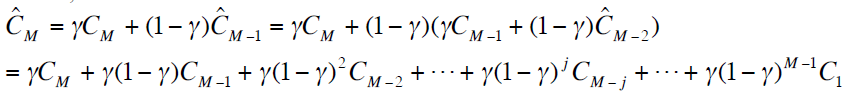
其中,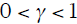 是平滑系数,它控制着我们把历史信息纳入我们平滑的计算中的权重大小。
是平滑系数,它控制着我们把历史信息纳入我们平滑的计算中的权重大小。
上述的两种方法:(1)数据层级结构的贝叶斯平滑,(2)时间窗口的指数平滑,可以结合使用。
4. 数据层级结构的贝叶斯平滑方法具体介绍
这里我们规定将page-ad pair的信息在层级结构上上升到publisher-account pair的信息(不同page隶属于相同的publisher,不同的ad隶属于相同的account)。
有两个假设:
(1)对于publisher-account pair,有1个隐含的CTR概率分布,而每个page-ad pair的CTR可以看作是从这个整体的CTR分布中随机采样出来的。
![]()
(2)对于page-ad pair,我们观测到其对应的展现信息和点击信息。
![]()
其对应的概率图模型如下,灰色部分是观测变量,白色部分是隐含变量:
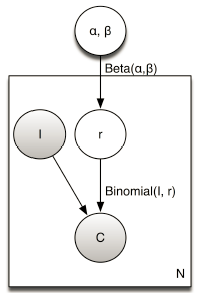
对于该publisher-account下的所有page-ad pair的点击计算出似然函数:
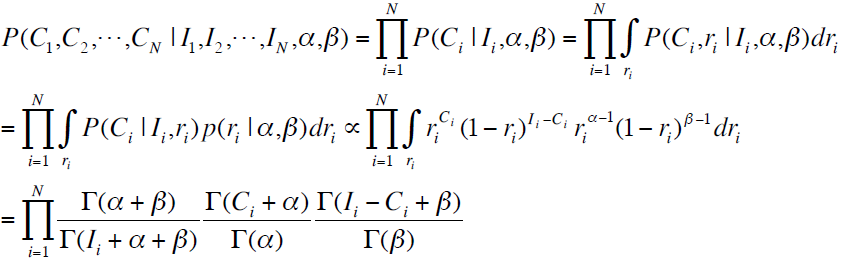
将上述的log似然函数分别对α和β求导数,即为:
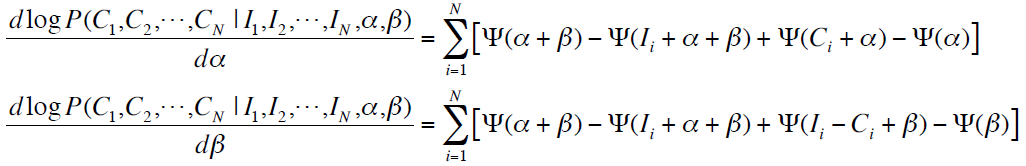
通过fixed-point iteration方法,我们可以得到α和β在每一轮迭代中的更新公式:

迭代的终止条件为一个固定的迭代次数(如1000次),或者α和β在一次迭代中的变化值都小于一个epsilon(如1E-10)。一旦有了的估计值后,我们便可以得到每个ad的后验估计:![]() 。
。
5. 贝叶斯参数估计
这里简单介绍一下为什么有了的估计值后,便可以得到后验估计:。
我们知道贝叶斯参数估计的基本过程是:先验分布 + 似然函数 = 后验分布
由于我们假定了先验分布是Beta分布,而似然函数是二项分布,由Beta-Binomial共轭,我们可以得到,后验分布也是Beta分布,如下:
Beta(p|a,b) + BinomCount(m1,m2) = Beta(p|a+m1,b+m2)
这种共轭形式的好处是,我们能够在先验分布中赋予参数很明显的物理意义,这个物理意义可以延续到后验分布中进行解释,同时从先验分布变换到后验分布过程中从数据中补充的知识也容易有物理解释。
在我们这里,先验分布是服从Beta(α,β)分布的,而通过似然函数BinomCount(C,I-C)后,后验分布变为Beta(α+C,β+I-C)。
对这个后验分布,我们有两种参数估计方法:
1)MAP估计:直接看后验分布Beta(α+C,β+I-C)取值最大时候的参数,这时候为:(α+C-1) / (α+β+I-2)。
2)贝叶斯估计:对服从后验分布Beta(α+C,β+I-C)的变量求数学期望,这时候为:(α+C) / (α+β+I)。
数学期望的计算过程如下所示:
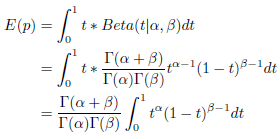
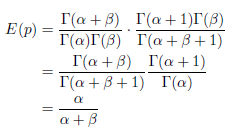
6. 实验介绍
评估指标:
1)MSE

2)KL_divergence
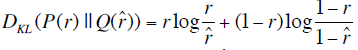
实验策略:
选取展示数不低于10000次的page-ad pair作为实验数据集,从中采样1% / 0.1% / 0.001% 用于预测page-ad ctr,剩余99% / 99.9% / 99.99% 的数据集用于对预测值进行评估。
PS:具体如何对贝叶斯平滑的参数进行估计,以及具体的代码实现,可见另一篇博客http://www.cnblogs.com/bentuwuying/p/6498370.html。
7. 参考文献
1. Click-Through Rate Estimation for Rare Events in Online Advertising
版权声明:
本文由笨兔勿应所有,发布于http://www.cnblogs.com/bentuwuying。如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号