
刨根究底字符编码之七——ANSI编码与代码页(Code Page)
ANSI编码与代码页(Code Page)

一、ANSI编码
1.
如前所述,在全世界所有国家和民族的文字符号统一编码的Unicode编码方案问世之前,各个国家、民族为了用计算机记录并显示自己的字符,都在ASCII编码方案的基础上,设计了各自的编码方案。
比如欧洲先后设计了EASCII和ISO/IEC 8859系列字符编码方案;为了显示中文及相关字符,中国设计了GB系列编码(“GB”为“国标”的汉语拼音首字母缩写,即“国家标准”之意)。
同样,日文、韩文、世界各国文字都有它们各自的编码。所有这些各个国家和地区所独立制定的既兼容ASCII又互相不兼容的字符编码,微软统称为ANSI编码。
所以,即使知道是ANSI编码,还需要知道这是哪一个国家的才能解码;另外,也无法用同一种ANSI编码表示既有汉字、又有韩文的文本。
2.
严格来说,ANSI的字面意思并非字符编码,而是美国的一个非营利组织——美国国家标准学会(American National Standards Institute)的缩写。ANSI这个组织做了很多标准制定工作,包括C语言规范ANSI C,还有各国字符编码对应的“代码页(code page)”标准。(具体什么是代码页,详见后文解释)
ANSI规定简体中文GB编码的代码页是936,所以GB编码又叫做ANSI code page 936(ANSI标准的代码页936),各国编码之所以被微软统称为ANSI编码的原因即在这里。
后来,或许是出于沿用统一的称呼之目的,有些在当时还并未被ANSI定为标准的代码页,也被微软称之为ANSI代码页,比如CP943代码页。
在Windows系统的编码处理中,ANSI编码一般代表系统默认编码方式,而且并不是确定的某一种编码方式——在简体中文操作系统中ANSI编码默认指的是GB系列编码(GB2312、GBK、GB18030);在繁体中文操作系统中ANSI编码默认指的是BIG5;在日文操作系统中ANSI编码默认指的是Shift JIS,等等。可在系统区域设置的系统Locale中更改。
(笨笨阿林原创文章,转载请注明出处)
二、代码页(Code Page)
1.
代码页也称为“内码表”,是与特定语言的字符集相对应的一张表。操作系统中不同的语言和区域设置可能使用不同的代码页。
例如,微软所用的ANSI代码页1252(CP1252)对应于ISO 8859-1字符集(即Latin-1字符集,但CP1252对Latin-1有扩展,其中编码128~159也被定义了字符,这是与Latin-1字符集不同之处),用于英语和大多数欧洲语言(西班牙语和各种日耳曼/斯堪的纳维亚语),而IBM所用的OEM代码页932(CP932)对应于Shift JIS字符集(但CP932对Shift JIS有扩展;另外,对应的微软ANSI代码页为CP943,也对Shift JIS有扩展),用于日本字符。
代码页一般与其所直接对应的字符集之间并非完全等同,往往因为种种原因(比如标准跟不上现实实践的需要)而会对字符集有所扩展。
2.
早期,代码页是IBM称呼计算机的BIOS所支持的字符集编码。当时通用的操作系统都是命令行界面的,这些操作系统直接使用BIOS提供的字符绘制功能来显示字符(或者是一组嵌入在显卡字符生成器中的字形)。这些BIOS代码页也被称为OEM代码页。
随着图形用户界面操作系统的广泛使用(最初被广为接受的图形用户界面操作系统是Windows3.1),操作系统本身具有了字符绘制的功能。微软于是在Windows操作系统没有转向UTF-16(UTF-16的推出要早于现在被广为认可的UTF-8)作为编码实现之前(即Windows2000发布之前),定义了一系列支持不同国家和地区所制定的字符集的代码页,被称作“Windows代码页”或“ANSI代码页”。代表性的是实现了ISO-8859-1(即Latin-1)的代码页1252(即CP1252),以及实现了GBK的代码页936(即CP936)。
3.
代码页可以在从字符映射到单字节值或多字节值的表格中表现。注意,这里的单字节值与多字节值指的是特定于系统平台的物理意义上的字节序列,不是指与系统平台无关的逻辑意义上的码元序列。正因为这样,代码页也被称之内码表。
也就是说,代码页是字符集的具体实现,可以将其理解为一张“字符-字节”映射表,通过查表实现“字符-字节”的翻译。
代码页主要用于字符在计算机中的存储和显示,比如,计算机读取了一个二进制字节,那这个字节到底代表哪个字符,就需要到指定的代码页中查找,这个查找的过程就被称为查表。
4.
代码页的指定在Windows中是系统默认设置的(即默认系统区域设置),也可在(Windows7的)“控制面板-区域和语言-管理-非Unicode程序的语言-更改系统区域设置”中选择列表中的语言进行更改。
注意:系统区域设置System Locale可用于确定在不使用Unicode编码的程序中输入和显示信息的默认字符集和字体,这样就可以让非Unicode程序在计算机上使用指定的语言得以正常运行。因此,在计算机上安装某些非Unicode程序时,可能需要更改默认的系统区域设置。为系统区域设置选择不同的语言并不会影响Windows系统本身或其他使用Unicode编码的程序的菜单和对话框中的语言显示。
(笨笨阿林原创文章,转载请注明出处)
5.
早期在IBM和微软内部使用数字来标记不同的字符集,不同的厂商对同一个字符集使用各自不同的名称。
例如,UTF-8在IBM称作代码页1208,在微软称作代码页65001,在SAP称作代码页4110;Windows使用936代码页(Code Page 936,即CP936)、Mac系统使用EUC-CN代码页实现GBK字符集的编码(EUC:Extended Unix Code;EUC-CN是类Unix系统中GBK编码方案的别名,等同于Windows下的cp936代码页),名字虽然不一样,但对于同一汉字的编码肯定是一样的。
三、微软Windows操作系统中ANSI代码页的设置
1.
微软为了适应世界上不同地区用户的文化背景和生活习惯,在Windows中设计了区域(Locale)设置的功能。
Locale是指特定于某个国家或地区的一组设定,包括代码页,以及数字、货币、时间和日期的格式等。
在Windows内部,其实有两个Locale设置:系统Locale和用户Locale。系统Locale决定代码页,用户Locale决定数字、货币、时间和日期的格式。
可以在Windows控制面板的“区域和语言选项”中设置系统Locale(非Unicode程序的语言)和用户Locale(标准和格式):
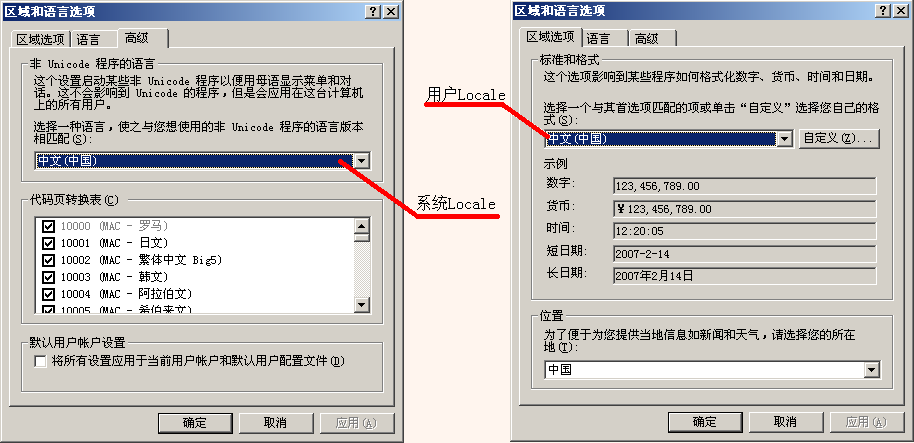
(Windows XP中的Locale设置)
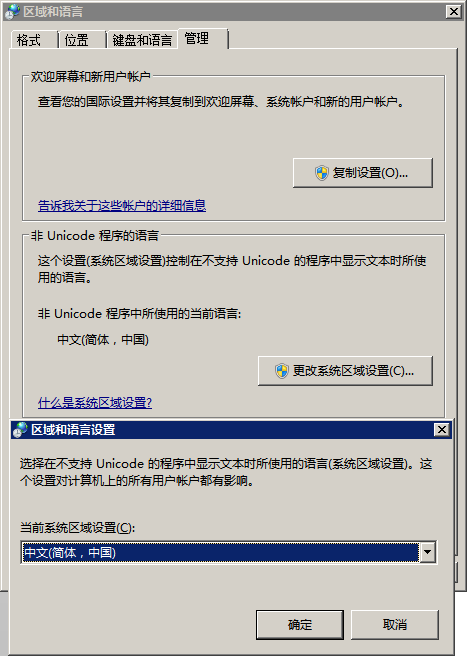
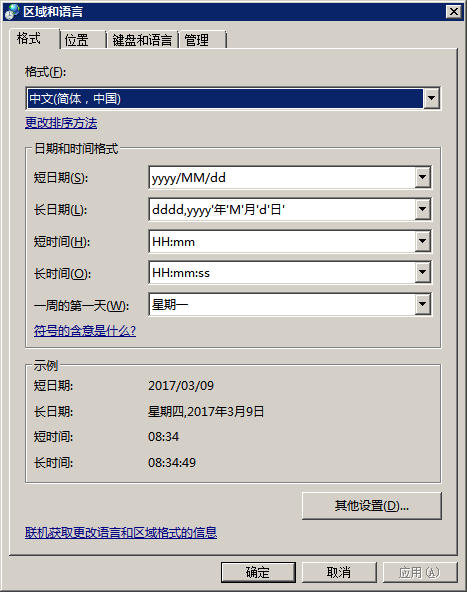
(Windows 7中的Locale设置)
2.
系统Locale对应的代码页被作为Windows的默认代码页。在没有明确指定某个文本的编码信息时,Windows将按照指定的默认代码页的编码方案来解释该文本数据。这个默认代码页通常被称作ANSI代码页(ACP)。
在历史上,IBM的个人计算机和微软公司的操作系统曾经是PC的标准配置。微软公司将IBM公司定义的代码页称作OEM代码页,在IBM公司的代码页基础上作了些增补后,称为ANSI代码页。
在Windows XP的“区域和语言选项”高级页面的“代码页转换表”中可看到各个语种的代码页(Windows7中已经不能直接看到了)。例如:
·874 (ANSI/OEM -泰文)
·932 (ANSI/OEM -日文Shift-JIS)
·936 (ANSI/OEM -简体中文GBK)
·949 (ANSI/OEM -韩文)
·950 (ANSI/OEM -繁体中文Big5)
·1250 (ANSI -中欧)
·1251 (ANSI -西里尔文)
·1252 (ANSI -拉丁文)
·1253 (ANSI -希腊文)
·1254 (ANSI -土耳其文)
·1255 (ANSI -希伯来文)
·1256 (ANSI -阿拉伯文)
·1257 (ANSI -波罗的海文)
·1258 (ANSI/OEM -越南)
(笨笨阿林原创文章,转载请注明出处)
【预告:下一篇将开始正式讲解Unicode编码方案,敬请关注!】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号