

软件开发过程自动化原理及技术(完整示例)
软件开发过程自动化原理及技术
一个简单完整的自动化示例
1 概述
关于本文,最开始只是想写一些关于 软件自动化测试开发 的文章,但是后来写着写着,发现不先在宏观上的软件开发过程进行介绍,不会引起大家对 自动化 技术形成了解和重视。所以本文从软件工程宏观层次进行了介绍,并和传统的实现方法做了一些对比,并附了一些代码,让有兴趣的朋友对自动化的理念及具体的实现技术手段有一些初步的认识。
既然是要 自动化 那么肯定就是冲着 效率 来的。在正式开始系统化的自动化技术学习之前,先来一个完整的示例来有个对 自动化 的概念整体认识。
2 使用场景
可以先定义一个最简单的场景:提供第三方前端js库的产品(例如: jQuery)。
使用过 jQuery 的人,可以很清楚这样的产品具有如下的特征:
- 静态文件支持CDN方式的在线引用,可以不必下载成离线文件
- js文件后面有版本号标识
- 静态文件是增量式发布,而非覆盖替换式
下面是一些jquery的备注,方便读者了解前面所谈到的一些特点的具体表现形式。
jQuery 的CDN在线引用的方式
<script src="https://code.jquery.com/jquery-2.1.4.min.js"></script>
每个 jQuery 的库文件都带有版本号,例如: jquery-2.1.4.min.js
如果有新的文件版本发布,则增加一个带新版本号的文件即可。
基本上这样的产品的开发和上线的步骤如下:
- 开发工程师本地开发好js项目,并做好单元测试和功能性自测
- 使用构建工具打包成js文件(为简化问题,此处假设最终只有一个文件)
- 发布工程师收到构建好的文件,向公网上发布静态文件
- 检查静态文件是否成功部署成功且能正常被公网访问
3 传统方案
在前面所定义的步骤里面,传统的方案就是:
-
开发人员开发完毕,并进行简单自测,和 手动 功能测试
-
开发人员利用IDE 手动 打包
-
发布工程师将构建后的文件 手动 复制到公网服务器指定目录
- 发布工程师在浏览器里面 手动 输入文件的公网链接,确定可以访问到相应的资源
-
有可能出现公网文件权限或者服务器配置问题,导致即使文件在那个位置,但是不一定能够访问到。比如出现 403forbidden 的情况
这样的过程都是要通过程序员去手动完成,在现在讲究快速迭代的软件研究趋势下,长期这样手动重复的后果就是:
- 一直手工操作导致效率低下
- 重复工作会扼杀人的创造性
对于会持续做加法迭代的有稳定产品线路的项目,最好还是能够做自动化的的操作,一方面是为了解放程序员,另外一方面也确实提升效率以适应现在的快速开发和迭代的客观需求。
4 自动化方案
4.1 自动化单元测试
其实开发人员在开发过程,就是为了让程序能够达到预期的目标,那么就肯定是存在一定的自测过程。但是仅仅是当时自测之后是不行,还需要对于核心的算法函数进行单元测试代码的编写,以保证后续的迭代和重构的时候,不会出现拆东补西的情况。
此时的情况是:
- 核心函数---- 自动化 单元测试
- 界面功能---- 手动 功能性自测
一般情况,功能测试都特指 端到端 的直接面向用户的界面型测试,由于界面存在太多的不确定性,这一块不是适合编写自动化测试代码的,虽然对于界面的自动化已经有一部分的脚本录制工具或者开发工具,但是都不提倡。
注意
自动化测试涉及到自动化代码的编写,这部分的额外付出成本是在 回归测试 的时候收回的,回归的次数越多,边际成本就越小。所以只有相当稳定下来的功能才有回归的价值。
由于目前很多产品的开发,都不再是独立的系统,都往往会存在一些外部调用的接口,所以在自动化打包构建之前,还要在测试环境下进行接口测试。此处的在做自动化方案的时候,基本原理和单元测试差不多,所以本文略去不表,后面会专门有专门介绍自动化测试部分的内容。
4.2 自动化打包构建
有相当多的IDE提供了一些打包的可视化操作工具。但是这些工具需要人工在IDE里面根据向导,进行一步步地点击操作,这样的做的好处就是降低了打包构建的门槛,普通人也可以在不了解原理,不用编写构建代码的情况下,也能完成相应的构建工作。当然缺点就是: 无法实现无人值守的自动化。
基本上现在各种语言都有自己相应的成熟的构建工具,本文所举的前端的开发的例子,就有 grunt 这样的打包构建工具。
可以完成的自动化任务有:
- 去除掉js源码里面的注释
- 压缩js
- 混淆js
- 合并文件
通过写好相应的配置文件,运行grunt的相应参数命令,可以很好地实现开发构建阶段的自动化工作流。
4.3 自动化发布
自动化发布的具体实现技术手段有很多种。
像脚本型的语言(php,python,nodejs)可以使用 Git 这样的版本管理工具,使用调用shell命令,或者第三方操作库(例如python语言的Gitpython)可以实现代码的自动化部署。
对于一些构建的产物本身是很大的二进制文件的,比如exe文件,或者Android的apk应用,动辙是几百M的,显然不适合使用Git这样的精细化的版本管理工具来进行发布。可以使用FTP或者SSH的第三方编程接口进行自动化的发布。此处可以推荐一款基于python的三方扩展 fabric,可以完成文件的远程传输及远端的服务器的命令行操作。
本文的的jQuery静态js发布方案使用整体文件上传到公网服务器的方式(使用fabric工具),以基本的流程如下:
- 扫描自动化构建的目录
- 使用fabric上传文件到N台指定的服务器的相应目录
- 使用fabric操控N台服务器设置静态文件的权限
以下是一段代码示例(将本地的某个目录下的文件上传分发到N台服务器,并进行简单的设置):
#!coding:utf8
"""
自动上传文件到静态服务器上,和测试服务器上面
"""
from __future__ import with_statement
import sys
import os
from fabric.api import lcd
from fabric.operations import put, run
from dtlib.dtlog import dlog
server_folder_path = '/static_folder'
local_folder_path = server_folder_path
user_name = 'xxx'#服务器登录用户名
server_ssh_pwd = 'xxxxxxxx'#服务器登录密码
lcoal_dirlist = []
#所有的需要上传文件的服务器的登录信息列表
server_list = [
# (host,user,password)
('192.168.1.201', user_name, server_ssh_pwd),
('xxx.xxx.xxx.xxx', user_name, server_ssh_pwd)
]
def scandir():
"""
上传本地某个目录到服务器的指定目录
:return:
"""
list = os.listdir(local_folder_path)
for i in list:
dirpath = os.path.join(local_folder_path, i)
if os.path.isdir(dirpath):
lcoal_dirlist.append(i)
dlog.debug(lcoal_dirlist)
for j in lcoal_dirlist:
dlog.debug("subdir:" + j)
with lcd(local_folder_path):
run('uname -s')
put(j, server_folder_path, use_sudo=True) # 上传本地文件到服务器端
# 在远程机器上批量修改文件权限
run('chmod a+rw %s/js/jquery-2.1.4.min.js' % (server_folder_path)) # 修改文件权限为可读写
run('cp %s/js/jquery-2.1.4.min.js %s/js/jquery-2.1.4.min.js' % (server_folder_path,
server_folder_path))
print '%s has synced' % j
if __name__ == '__main__':
currentpath = sys.path[0]
for item in server_list:
fab_cmd = 'fab -f scp_static.py -H %s -u %s -p %s scandir' % (item[0], item[1], item[2])
dlog.debug(fab_cmd)
os.system(fab_cmd)
4.4 自动化检测发布结果
关于指定的版本的静态文件是否发布成功,最后还需要一道检测,才能实现 闭环。当然,根据不同的要求,检测的用例也会不同。一般情况下,如果前面的流程都比较规范,此处就不太需要对功能进行太多检测了,但是需要对发布结果进行检测:检测指定版本的js是否能够成功被公网访问。
一般人可能不太理解,之前不是已经完成发布了么,此处为何还要多此一举?经验告诉我们,一个 开环 的系统的结果往往是存在不可预知的,往往是不可信的。特别是在远程发布的时候,网络环境稳定性、服务器的硬件配额(磁盘容量已满)、web服务器配置(权限问题)都会成为发布失败的原因。只有形成 闭环 才会形成可靠的交付。
发布的目的不是执行发布的流程,而是最终能够让开发产出物能够提供正常的服务。
关于 jQuery 是否发布成功,本文设计了两个测试用例:
- 能够Http请求到正常的js源码
- jQuery的头部信息里面支持跨域
手工的检测方式是在浏览器输入链接:
https://code.jquery.com/jquery-2.1.4.min.js
观看浏览器的显示结果。
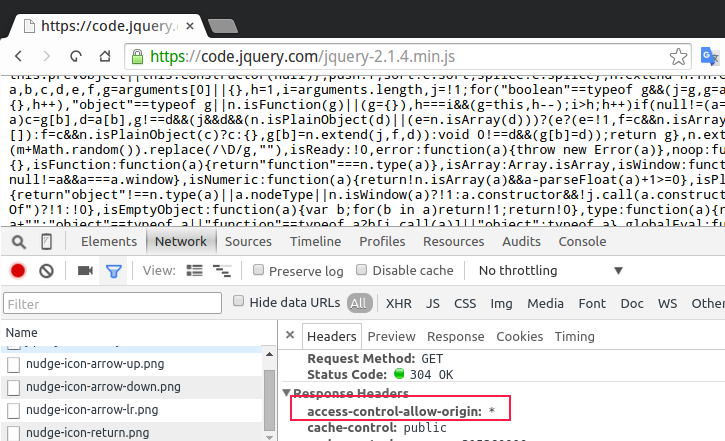
显然:
-
浏览器的内容框里面显示了正常的返回了js的内容
- 浏览器的调试框里面也可以看到头部信息里面是支持跨域的
-
当然此处还是使用了稍微高级的数据层面的检测方式,如果不了解http的原理,可能还会专门做一个测试页面,看能够正常加载到js文件。
这样太耗时,所以本文推荐自动化的方案。上面的手式的方式,其实本质上就是利用浏览器对指定的http链接发起请求,然后用眼睛来判断返回的数据结果,这一切都可以通过程序来实现。
做自动化的首要本领就是要会 透过现象看本质 ,即 透过界面看数据,以上两个用例的主要的技术原理:
- 请求js资源,Http返回的状态码是200。当然如果要更精细化,可以对其返回内容做进一步严格的判断。
- Http的请求头部数据里面的 access-control-allow-origin 字段的值为 * (星号通配符)
下面贴上一段python的 pyunit 框架下的自动化检测代码:
# coding:utf-8
"""
测试静态服务器文件是否发布成功
"""
import requests
import unittest
__author__ = 'Harmo'
class StaticServerTest(unittest.TestCase):
""" 静态文件请求
"""
def setUp(self):
pass
def tearDown(self):
pass
def test_jquery_js_release(self):
"""http是否正常返回
:return:
"""
test_js_url = 'https://code.jquery.com/jquery-2.1.4.min.js'
res = requests.get(test_js_url)
self.assertEqual(200, res.status_code, msg='检查是否正常返回')
def test_http_static_allow_origin(self):
"""http下不应该支持跨域
:return:
"""
test_js_url = 'https://code.jquery.com/jquery-2.1.4.min.js'
res = requests.get(test_js_url)
self.assertNotEquals('*', res.headers["access-control-allow-origin"], msg='http不允许跨域')
上面的代码是两个小的自动化测试用例,为了作为对比,特意 做了一个运行成功的例子(成功请求到文件)和一个运行失败的检测例子(要求文件支持跨域,其实jquery是应该支持跨域引用的)。
为了简单起见,在IDE下面运行此测试代码并查看结果:
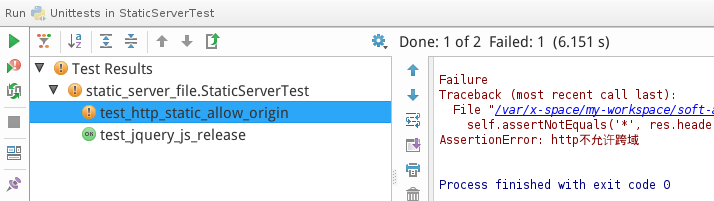
检测服务器上面的静态库文件是否加载成功。 当然,正常的结果应该是这样全成功的状态:
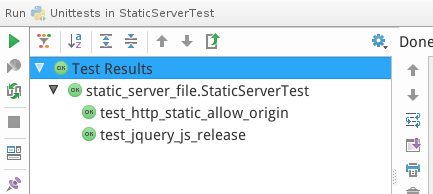
如果检测通过,那么就证明是成功发布了。
5 总结
本文的目的是为了说明什么叫自动化及自动化的好处,前面所介绍的内容的范围并不局限于“测试自动化”,但是最后的落脚点还是要到 自动化测试 及现在高级的 测试 职责:持续集成。
自动化测试 还有如下一些需要深入研究的地方:
- 对不同的测试用例进行数据的抽象化,以达到自动化实现的目的
-
这需要比较扎实的计算机的基础知识
- 能够通过代码组织好成规模(比如几千几万)的自动化测试脚本
-
这个就需要一定的软件工程基础和系统开发能力
-
能够掌握和其它系统集成的能力以达到持续集成的全自动化软件生产过程
这些技能也不是此处简单的只言片语就能道尽的,本文只能作为一个引子来进行后续内容的预热吧。
持续集成 也是建立在前面所介绍的各个环节形成自动化之后,然后再使用一定的技术手段,将这一系列事件进行被扣,来触发下一事件,从而环环相扣,形成稳定的软件生产自动化 流水线。形成持续稳定的软件交付物。
至于 持续集成 的好处,可以使用一个制造业的例子来描述:
1913年,福特将 流水线 应用到汽车组装中,第一条流水线使每辆T型汽车的组装时间由原来的12小时28分钟缩短至10秒钟,生产效率提高了4488倍!
在现代软件工业领域也需要这样:先自动化,然后持续集成,才可以实现快速迭代,以产生巨大的生产力,符合现代人对软件工程的预期。希望相关从业人员一起努力吧,提升自己的知识结构的竞争力,也提升整体的行业的生产力。
(未完,待续。。。)
| 作者: | Harmo哈莫 |
|---|---|
| 作者介绍: | https://zhengwh.github.io |
| 技术博客: | http://www.cnblogs.com/beer |
| Email: | dreamzsm@gmail.com |
| QQ: | 1295351490 |
| 时间: | 2015-11 |
| 版权声明: | 欢迎以学习交流为目的读者随意转载,但是请 【注明出处】 |
| 支持本文: | 如果文章对您有启发,可以点击博客右下角的按钮进行 【推荐】 |

