
数据挖掘之关联分析七(非频繁模式)
非频繁模式
非频繁模式,是一个项集或规则,其支持度小于阈值minsup.
绝大部分的频繁模式不是令人感兴趣的,但其中有些分析是有用的,特别是涉及到数据中的负相关时,如一起购买DVD的顾客多半不会购买VCR,反之亦然,这种负相关模式有助于识别竞争项(competing item),即可以相互替代的项。
某些非频繁模式也可能暗示数据中出现了某些罕见事件或例外情况。如,如果{火灾=yes}是频繁的,但是{火灾=yes,警报=on}是非频繁的,则后者是有趣的非频繁模式,因为可能指出报警系统出问题,为了检测这种情况,可以确定模式的期望支持度,当模式支持度小于期望支持度时,表明其实一个有趣的非频繁模式。
挖掘非频繁模式的主要问题是:
- 如何识别有趣的非频繁模式。
- 如何在大数据集中有效地发现它们。
负模式
设\(I = { i_1, i_2, \cdots, i_d }\)是项的集合。负项\(\bar{i_k}\)表示项\(i_k\)不在给定事务中出现。如事务不包含咖啡,则\(\bar{咖啡}\)是一个值为1的负项。
负项集,负项集X是一个具有如下性质的项集:(1)\(X = A \cup \bar{B}\),其中A是正项的集合,而\(\bar{B}\)是负项的集合,\(|\bar{B}| \geq 1\);(2)\(s(X) \geq minsup\)。
负关联规则,(1)规则是从负项集中提取的,(2)规则支持度大于或等于minsup,(3)规则的置信度大于或等于minconf。
负项集和负关联规则称为负模式(negative pattern)。负关联规则的一个例子是\(茶 \to \bar{咖啡}\)。
负相关模式
用\(X = {x_1, x_2, \cdots, x_k}\)表示k-项集,P(X)表示事务包含X的概率。在关联分析中,这个概率通常用项集的支持度s(X)估计。
负相关项集 项集X是负相关的,如果
其中\(s(x_j)\)是项\(x_j\)的支持度。s(X)是给出了X的所有项统计独立的概率估计。如果它的支持度小于使用统计独立性假设计算出的期望支持度。s(X)越小,模式就越负相关。
负相关关联规则,规则\(X \to Y\)是负相关的,如果
其中$X \cap Y = \varnothing $,这里定义的X和Y中的项的负相关部分条件,负相关的完全条件为
其中\(x_i \in X\)而\(y_i \in Y\)。因为X或Y中的项通常是正相关的,因此使用部分条件而不是完全条件来定义负相关关联规则更实际。如规则
是负相关的,但是其中项集内的项之间是负相关的,眼镜盒镜头清洁剂是负相关的,如果使用完全条件,可能就不能发现该规则了。
负相关条件也可以用正项集和负项集的支持度表示
(不知道为什么博客园的markdown不支持多行公式?在其他地方都可以的,如果知道怎么做的希望能告知~~)
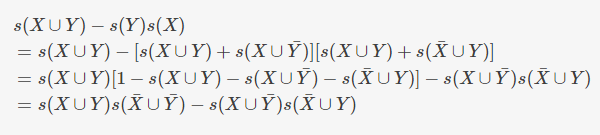
可以得到负相关的条件为
负相关项集和负相关关联规则统称为负相关模式(negatively correlated pattern)
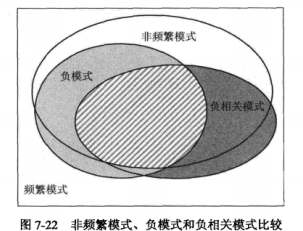
非频繁模式、负模式和负相关模式比较
根据上面的定义,我们得到,非频繁模式与负相关模式只涉及包含正项的项集或模式,而负模式涉及包含正项和负项的项集或模式。
挖掘有趣的非频繁模式技术
非频繁项集是未被的频繁项集产生算法如Apriori或FP所提取的有所项集,如下面边界下的那些项集

非频繁模式的数量可能是指数的,挖掘非频繁模式主要是为了挖掘那些有趣的非频繁模式。可以通过删除那些不满足负相关条件的非频繁项集得到。但是与挖掘频繁项集的支持度度量不同,挖掘负相关项集使用的基于相关性的度量不具有用于指数搜索空间剪枝的反单调性,因而计算量很大。
基于挖掘负模式的技术
使用负项增广,将事务数据二元化,把原始数据变成具有正项和负项的事务。对增广的事务使用已有的频繁项集生成算法。可以导出所有的负项集。
(下面的右表中B和D两项标好像错了,应为\(\bar{B}\)和\(\bar{D}\))
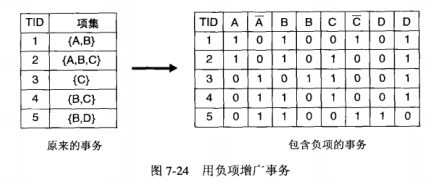
如果只有少量变量被视为对称的二元变量时,该方法可行的,但是如果很多项,则会出现一些问题
- 数据集翻倍
- 引入负项后,会出现\(x\)和\(\bar{x}\),其中必有一个项的支持度超过50%,因而导致使用基于支持度剪枝策略算法时,频繁项集的数量将呈指数增长。
- 增加负项后,事务的宽度增加,将会增加候选项集的数量,很多算法都不能使用。
前面的方法是蛮力计算方法,代价很高,因为迫使我们确定大量正模式和负模式的支持度。另一种方法不是用负项集增广数据集,而利用正项集来计算负项集的支持度。如
通常项集\(X \cup Y\)的支持度可以
可以用其他的方法来进一步提高算法性能,仅桑y频繁时,\(\bar{y}\)才是有趣的。稀有项易于产生非频繁项集。
基于支持度期望的技术。
仅当非频繁模式的支持度显著小于期望支持度时,才认为是有趣的,期望支持度根据统计独立性假设计算。使用概念分层和基于近邻的方法,称作间接关联。
1. 基于概念分层的支持度期望
仅用客观度量还不足以删除不感兴趣的非频繁模式。如面包和台式机是不同的产品类,他们的支持度较低,但是他们不是有趣的非频繁模式,因而需要使用领域知识裁剪不感兴趣的项。
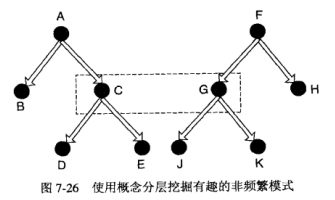
假定{C, G}是频繁的,用s(.)表示模式的实际支持度,\(\varepsilon(.)\)表示期望支持度。则
2. 基于间接关联的支持度期望
商品(a, b),如果是不相关商品,则预期支持度较低,如果是相关的商品,预期支持度较高。上面使用概念分层来计算期望支持度,下面使用另外一种方法:通过考察与这两个商品一起购买的其他商品。
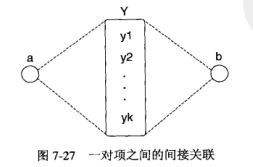
间接关联,一对项a,b是通过中介集间接关联的,如果下列条件成立
(1)\(s({a, b}) < t_x\) (项对支持度条件)
(2)\(\exists Y \neq \varnothing\)使得
(a) \(s({a} \cup Y) \geq t_f\)并且\(s({b} \cup Y) \geq t_f\) (中介支持度条件)
(b) \(d({a}, Y) \geq t_d, d({b}, Y) \geq t_d\),其中d(X, Z)是X和Z之间关联的客观度量 (中介依赖条件)
中介支持度和依赖条件确保Y中的项形成a和b的近邻。可以使用兴趣因子、余弦或其他依赖度量。
进阶关联有很多应用,如a和b可能是竞争商品。文本挖掘中可以识别同义词和反义词。
数据挖掘之关联分析一(基本概念)
数据挖掘之关联分析二(频繁项集的产生)
数据挖掘之关联分析三(规则的产生)
数据挖掘之关联分析四(连续属性处理)
数据挖掘之关联分析五(序列模式)
数据挖掘之关联分析六(子图模式)
数据挖掘之关联分析七(非频繁模式)

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步