一次线上事故的处理流程和总结
某个旧版本业务功能中运行了一个失败重试的job,因一位离职的同事编码时未考虑周全出现死循环,导致线上从24日下午2点一直到27日晚9点持续3天一直在刷日志。异常日志内容如下:

2、事故过程分析:
①、根据异常日志内容,初步考虑为redis中缓存的token失效了,后检查token并与请求方token对比,发现token正确,故排除token过期原因
②、通过grep命令查找更多日志内容后,依然无法显示更多有用信息(包括调用入口,更多代码中打印的日志信息等),于是核查所有可能的代码入口,并依次打印相关日志,结果均未打印有效信息。
③、考虑之前该服务已经接入公司自研的日志链调用分析系统,先后根据日志关键内容和traceid在系统中查询,结果发现traceId的调用链无法正常显示,依旧无法找到异常日志准确的入口,后找到故障原因后,架构组同事猜测可能是因为该调用链一直未调用结束,导致无法通过traceId来查找调用链。
④、由于持续重复调用同一个接口,开始以为是安全问题怀疑被人刷接口(前段时间公司有进行安全验证),后看到所有日志内容均是由同一个线程所打印的,因此怀疑可能是有死循环存在。后与同事确认,了解到旧版某个业务中有一个失败订单重试job,目前已经弃用了,理论上应该不存在问题,然后又找到该job的入口,使用grep命令查看第一行日志,发现仍未打印日志,于是排除了该job的入口。后来发现被迷惑了,因为该job是在7.24下午2点开始的,因为死循环该方法一直没调用完,所以到27号查找该日志内容时依然未打印。
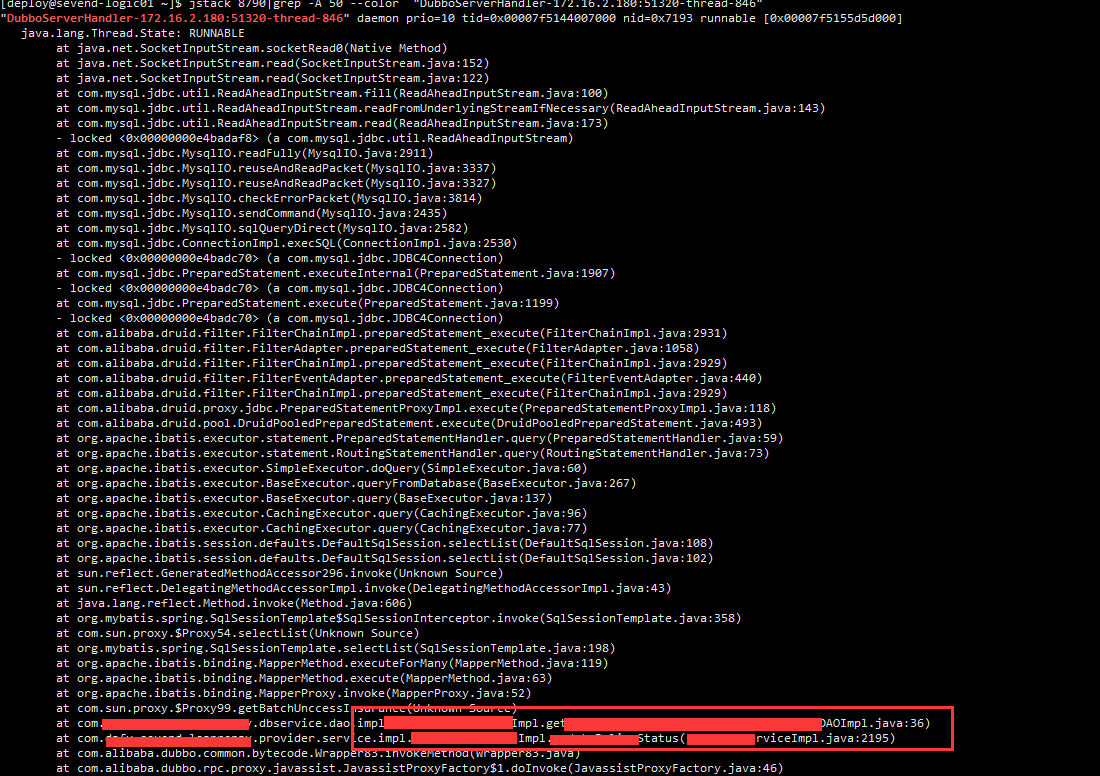
⑤、后使用jstack命令通过线程名称最终查找到异常代码入口,确定事故原因是由于旧版业务的job导致,
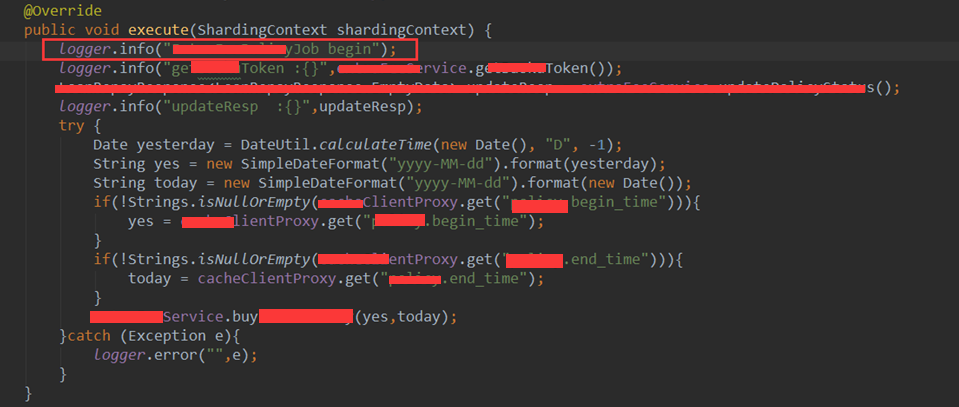
该job的部分代码如下:
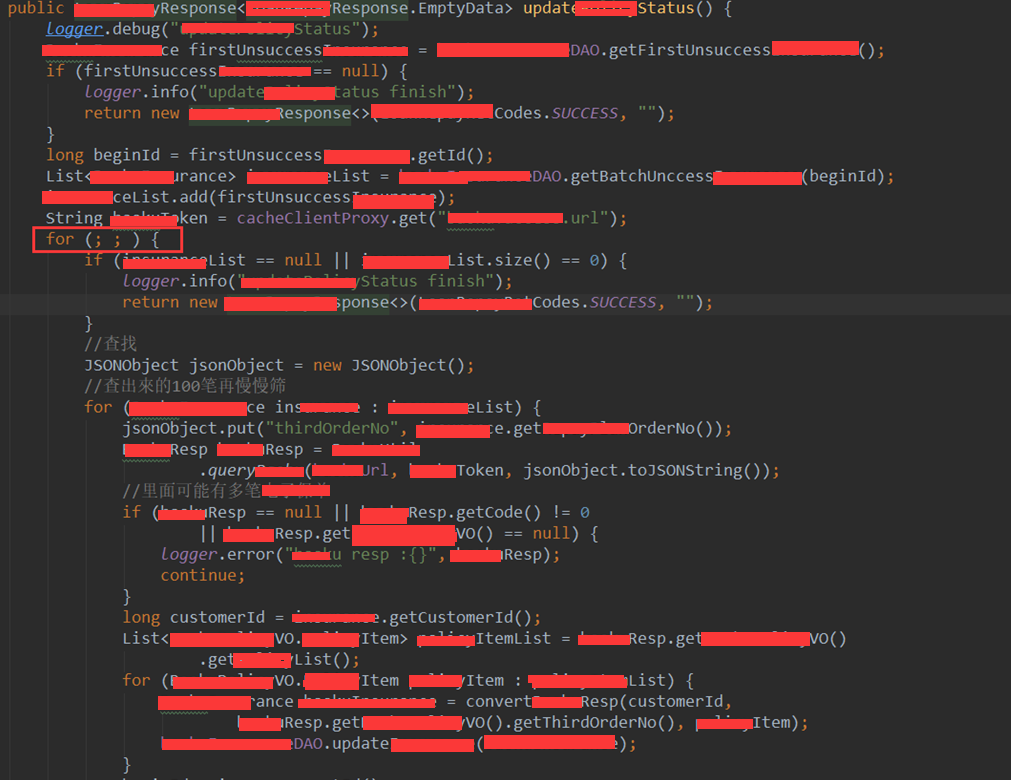
可以看到,最外层的for循环的终止条件只能依赖于xxList变量,并且token是在循环外层定义的(这也解释了为何日志一直显示token校验失败了,因为token是24号的,正常情况token为1小时更新一次),而在job执行过程中,token过期了,因此后面的query方法返 回的code一直不为0,于是进入死循环,导致一直刷日志。
3、事故解决:
找到问题后,重启了1台服务后观察一段时间,发现日志恢复正常,于是重启剩余2台机器,并在es-job中将该job禁用。
4、事故影响分析:
由于只是打印日志,且日志量不大,未对平台核心相关服务产生明显影响,但由于重复请求服务方,导致对方机器磁盘爆满后发现了该问题。
5、事故总结:
①、使用for循环时,必须确保循环终止条件能达到,避免产生死循环。
②、良好的日志能有效提升问题定位的效率,有关日志打印规范,请参考阿里巴巴日志规约(http://www.cnblogs.com/dragonsuc/p/6937584.html)
③、对于已经弃用的业务和功能,注意一些旧的job可能产生的影响,如有必要需要停止。
④、尽量通过多角度快速定位问题,比如重复日志就要考虑是否有死循环,熟练使用jstack等命令快来速定位代码。
如有其他建议和意见,欢迎指出批评。
