8.13.1 集合框架, 数据结构
Collection集合选取规则:(Vector现在用的不多了所以不考虑)
if(数据唯一,无序(输入顺序)){
if(需要排序){ 选用TreeSet
}
else{
选用HashSet
}
}
else{
if(查询多){
选用ArrayList
}
if(增删多){ 选用LinkedList
}
}
如果你知道是Set,但是不知道是哪个Set,就用HashSet。
如果你知道是List,但是不知道是哪个List,就用ArrayList。
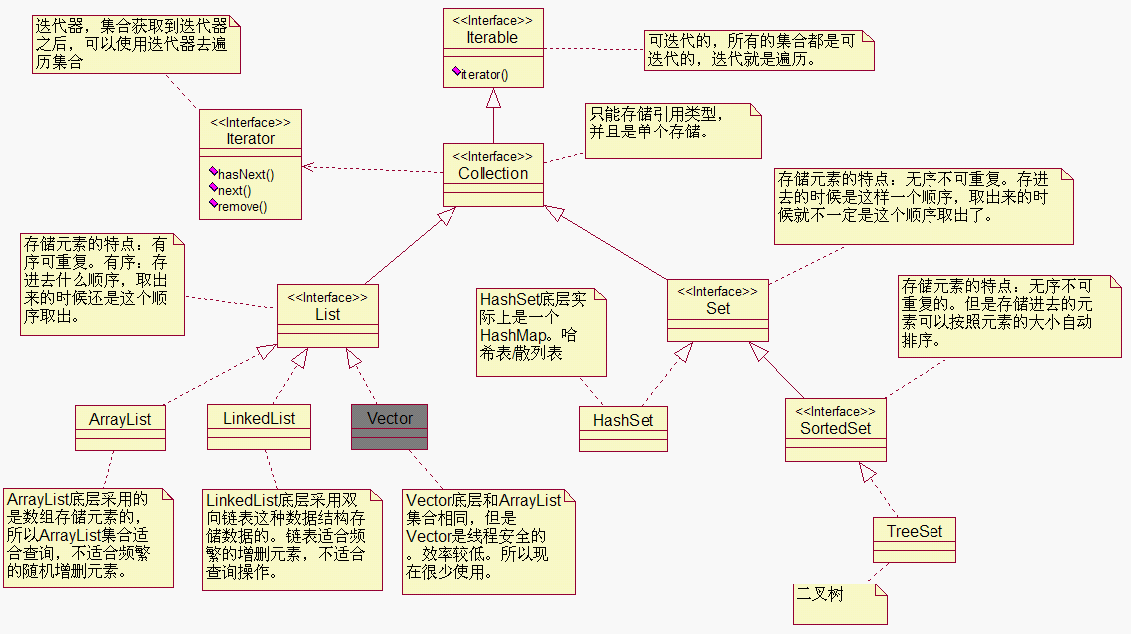
List集合存储元素特点:
1.有序(List集合中存储有下标):存进去是这样的顺序,取出来还是按照这个顺序取出。
2.可重复
ArrayList集合底层默认初始化容量是 10. 扩大之后的容量是原容量的1.5倍.
Vector集合底层默认初始化容量也是10.扩大之后的容量是原容量的2倍.
HashMap和HashSet初始化容量都是 16,默认加载因子是0.75(在数组元素占75%时扩容)
如果优化ArrayList和Vector?
尽量减少扩容操作,因为扩容需要数组拷贝。数组拷贝很耗内存。
一般推荐在创建集合的时候指定初始化容量。
//List l = new ArrayList(500);
Set集合存储元素特点:无序不可重复
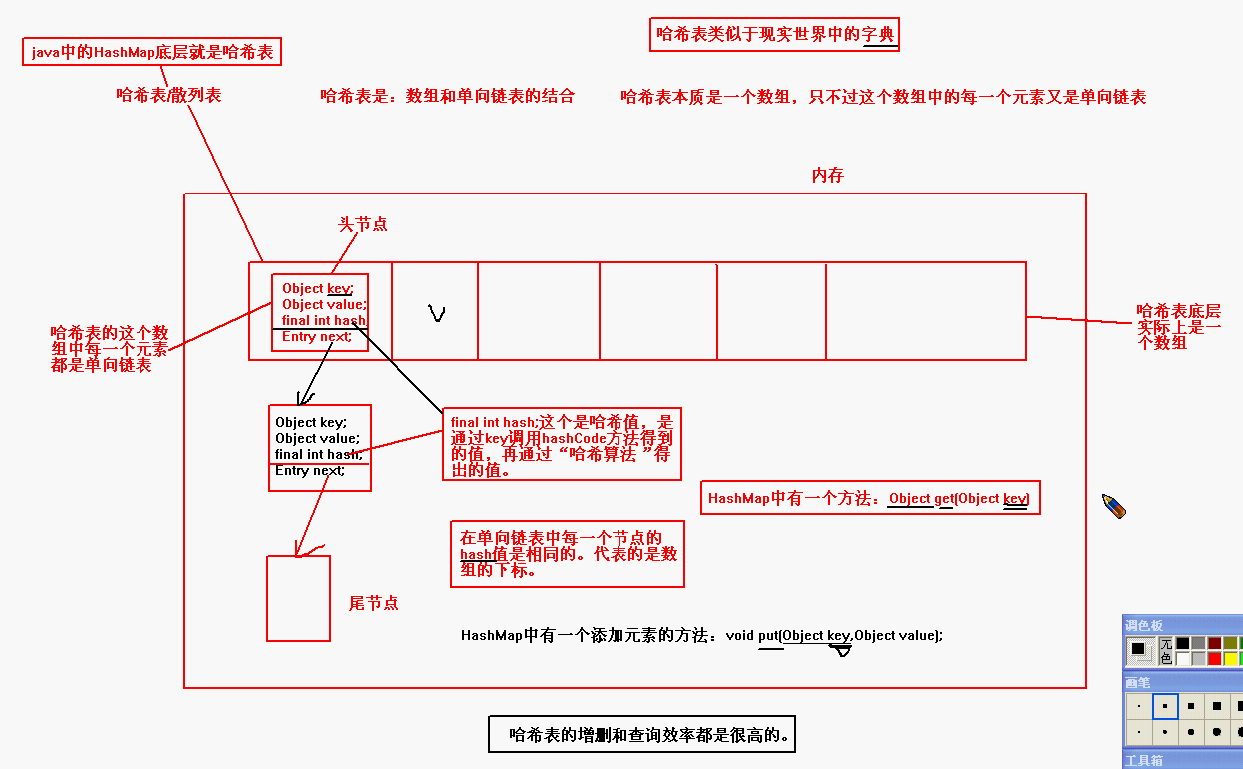
get方法:根据key算出hash值,再去查找相对应得分支,找到key.equals==true的那个对象的value返回(可以类比查字典!)
put方法:根据可以算出hash值,再去相应分支,判断key.equals,全部为false则插入,否则说明已经存在该元素了,如果hash值没有分支,则再数组中新建一个链表存储新的分支。
Set集合:HashSet
1.HashSet底层实际上是一个HashMap,HashMap底层采用了哈希表数据结构。
2.哈希表又叫做散列表,哈希表底层是一个数组,这个数组中每一个元素
是一个单向链表。每个单向链表都有一个独一无二的hash值,代表数组的
下标。在某个单向链表中的每一个节点上的hash值是相等的。hash值实际上
是key调用hashCode方法,在通过"hash function"转换成的值。
3.如何向哈希表中添加元素:
先调用被存储的key的hashCode方法,经过某个算法得出hash值,如果在
这个哈希表中不存在这个 hash值,则直接加入元素。如果该hash值已经
存在,继续调用key之间的equals方法,如果equals方法返回false,则将
该元素添加。如果equals方法返回true,则放弃添加该元素。
4.HashSet其实是HashMap中的key部分。HashSet有什么特点,HashMap中的key 应该具有相同的特点。
SortedSet; 无序不可重复,但是存进去的元素可以按照元素大小顺序自动排列.
SortedSet集合存储元素为什么可以自动排序?
因为被存储的元素实现了Comparable接口,
SUN编写TreeSet集合在添加元素的时候,会
调用compareTo方法完成比较.
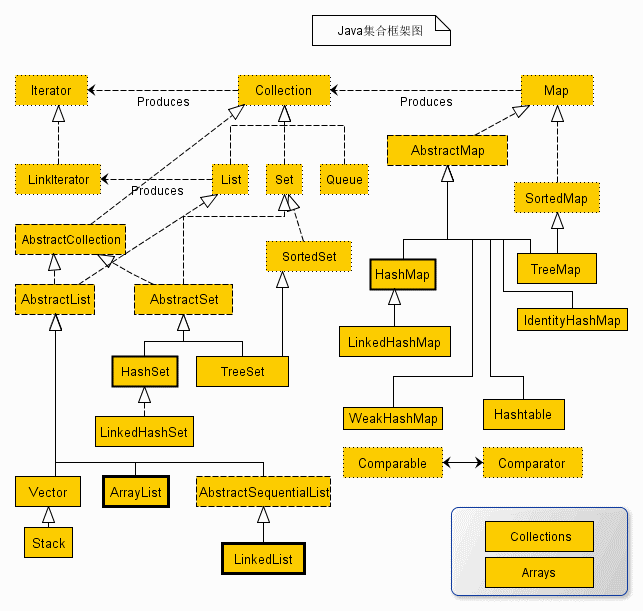
Colllection集合的UML关系图:
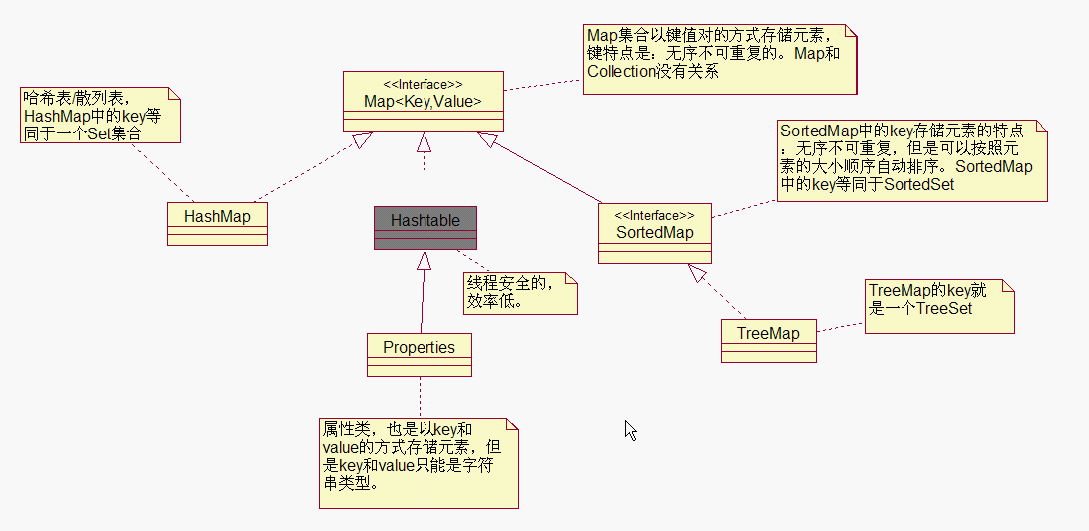
Map集合的UML关系图:
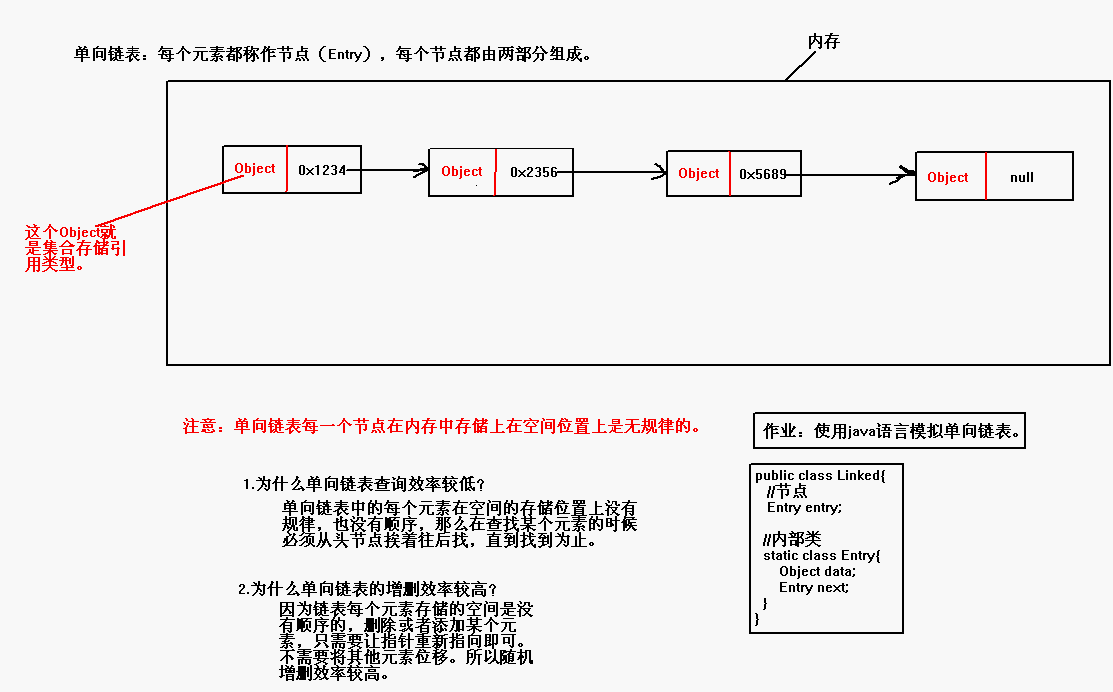
单向链表数据结构特点(和数组比较)
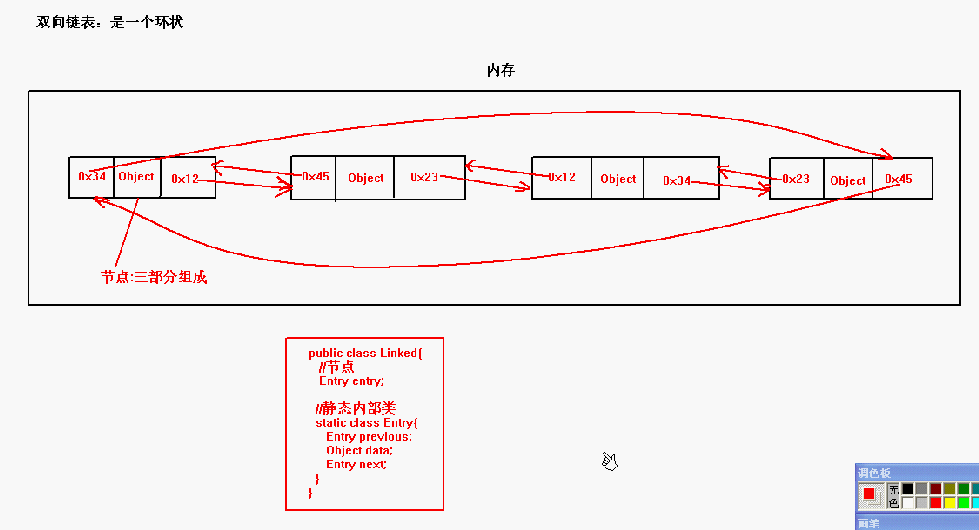
双向链表数据结构:
哈希表数据结构: