

2017-2018-1 20155223 《信息安全系统设计基础》第11周学习总结
2017-2018-1 20155223 《信息安全系统设计基础》第11周学习总结
实验四报告博客
教材学习内容总结
虚拟存储器
虚拟存储器的另一个称呼是虚拟内存。
当电脑内运行的程序占用太多内存时,操作系统会将一部分硬盘存储空间用作内存,以缓解内存的紧张。
因为使用部分硬盘空间做内存,各个进程的地址空间不用被修改或删除,各进程的地址空间由此得到保护。
正因为各进程的地址空间未被破坏,存储器可以给每个进程提供完全一致的地址空间,存储器的管理得到简化。
地址翻译
计算机最自然的寻址方式是物理寻址,即CPU直接通过物理地址访问主存。
虚拟寻址则是CPU生成一个虚拟地址,虚拟地址通过地址翻译转换成对应的物理地址,再通过生成的物理地址访问主存。
地址翻译需要CPU硬件与操作系统之间的密切配合才可实现。
CPU芯片上有一个称作内存管理单元的专用硬件,利用存放在主存中的查询表来动态翻译虚拟地址,该表内容由操作系统来管理。
存储器映射
存储器映射是指把芯片中或芯片外的FLASH,RAM,外设,BOOTBLOCK等进行统一编址。即用地址来表示对象。
由于各个硬件是由厂家生产制造的,所有设备的地址在生产结束后就被确定下来,用户只能使用地址而不能修改地址。
一个简单的存储器映射:内存单元A的地址为X,把它映射到地址Y,这样访问Y时,就可以访问到A了。当然,访问原来的地址X,也可以访问到A。
动态存储器分配的方法
动态存储分配,即指在目标程序或操作系统运行阶段动态地为源程序中的量分配存储空间,动态存储分配包括栈式或堆两种分配方式。
动态存储分配方式是不一次性将整个程序装入到主存中。可根据执行的需要,部分地动态装入。同时,在装入主存的程序不执行时,系统可以收回该程序所占据的主存空间。
动态存储分配方式在存储空间的分配和释放上,表现得十分灵活,现代的操作系统常采用这种存储方式。
分配算法
-
首次适应算法
算法要求空闲分区链以地址递增的次序链接。在分配内存时,从链首开始顺序查找,直至找到一个大小能满足要求的空闲分区为止;然后再按照作业的大小,从该分区中划出一块内存空间分配给请求者,余下的空闲分区仍留在空闲链中。若从链首直至链尾都不能找到一个能满足要求的分区,则此次内存分配失败,返回。
此算法都是从低地址开始找,空间分配之后剩下很多的小碎片,增加寻找可用空闲分区的开销。 -
循环首次适应算法
从上次找到的空闲分区的下一个空闲分区开始查找,直至找到一个能满足要求的空闲分区,从中划出一块与请求大小相等的内存空间分配给作业。
此算法很难产生较大的可用空闲分区。 -
最佳适应算法
将空闲分区链中的空闲分区按照空闲分区由小到大的顺序排序,从而形成空闲分区链。每次从链首进行查找合适的空闲分区为作业分配内存,这样每次找到的空闲分区是和作业大小最接近的,所谓“最佳”。
此算法产生大量难以利用的外部碎片。 -
最坏适应算法
将空闲分区链的分区按照从大到小的顺序排序形成空闲分区链,每次查找时只要看第一个空闲分区是否满足即可。
当一个小作业占用大空间时,大作业就没有可用空间。 -
快速适应算法
将空闲分区根据其容量大小进行分类,对于每一类具有相同容量的所有空闲分区,单独设立一个空闲分区链表,这样,系统中存在多个空闲分区链表,同时在内存中设立一张管理索引表,该表的每一个表项对应了一种空闲分区类型,并记录了该类型空闲分区链表表头的指针。
五种算法当中最吃硬件处理能力的算法,而且此算法是看进程给分区的,不方便大的多进程程序正常运行。
垃圾收集
计算机的垃圾通常是指不用的空间或分区,垃圾收集器是一种动态存储分配器,自动释放程序已经不再需要的已分配空间和资源。
C语言中与存储器有关的错误
C语言中与存储器有关的错误经常是在据错误源一段距离才表现出来。
- 间接引用坏指针
虚拟存储器的某些区域是只读的,如果试图往这些区域写数据,程序将会以保护异常中止。 - 读未初始化的存储器
虽然bss存储器位置(比如未初始化的全局变量)总是会被加载器初始化为零,但是对于堆存储器并不会初始化为零,也就是说如果用malloc函数分配了一段空间,记得对这些空间进行初始化。 - 允许栈缓冲区溢出
在栈中分配某个字节数组来保存一个字符串,但是字符串的长度超出了为数组分配的空间,也就是一个程序不检查输入串的大小就写入栈中的目标缓冲区,这个程序就会有缓冲区溢出错误(buffer overflow bug)。 - 假设指针和它们指向的对象是相同大小的
例子来自课本:
int **makeArray1(int n, int m)
{
int i;
int **A = (int **)malloc(n * sizeof(int));
for(i = 0; i < n; i++)
A[i] = (int *)malloc(m * sizeof(int));
return A;
}
这里有个明显的错误,就是在第四行程序中,将sizeof(int*) 写成了sizeof(int)。这段代码只有在int和指向int的指针大小相同的机器上不会出错。但在64位的机器上就会出现隐患。
- 错位(Off-by-one)错误
例子来自课本:
int **makeArray2(int n, int m)
{
int i;
int **A = (int **)malloc(n * sizeof(int *));
for(i = 0; i <= n; i++)
A[i] = (int *)malloc(m * sizeof(int));
return A;
}
第4行代码创建了一个n个元素的指针数组,但在第6,7行试图初始化这个数组的n+1个元素,这就会导致覆盖掉A数组后面的某个存储器。
- 错误理解操作符的优先级和结合性
就像数学四则运算当中不知道先加减还是先乘除一样,对指针p指向的整数减一操作错误编写成:
*p--;
正确写法是:
(*p)--;
- 引用不存在的变量
- 引用空闲堆里的数据
就是引用已经被释放了的堆块中的数据。 - 引起存储器泄露
如果对一块内存分配之后,忘记了释放这个已分配的内存块,就是产生内存泄露问题。
教材学习中的问题和解决过程
- 问题1:课本9.9.14提到的分离存储,这个是数据结构——链表的分配管理方法,有两种管理方法:简单分离存储和分离适配,分离适配还有一种称为伙伴系统的特例。伙伴系统就是让各个邻近块的地址之间只有一位不相同。现在我提出一个疑问:既然这个管理方法针对的是链表,那么在三种链表形式——单向链表、双向链表、循环链表,哪种链表更有可能是用此方法管理用时最少的?
- 问题1解决方案:重新翻阅了数据结构课程的课本和PPT,得知三种链表结构上的不同。单向链表就是一条链,每一链节都指向下一链节(除末位);双向链表是每一条链都会指向自己上一节的链节同时又指向自己下一节的链节(除了头尾两节);循环链表和单向链表差不多,就是尾节点会指向头结点。可以看出三种链表结构当中单向链表是最容易建立、添加或删除节点的链表,循环链表次之,双向链表最难建立。所以个人推论:最容易建立的单向链表是分离存储管理用时最少的链表,而双向链表是管理用时最长的。
代码调试中的问题和解决过程
-
问题1:出现自实验四。提供教材的代码经过长时间的敲打,顺利转到虚拟机上。但是在编译过程中,虚拟机频频报错,我不知道问题出在哪里,更不知道怎么处理。
-
问题1解决方案:我使用的虚拟机不是老师给的配置好的虚拟机,而是一直使用的虚拟机。我将代码转到正确的虚拟机上后,代码能够正常运行,能出结果。不过在合作项目上,我们的虚拟机还是不能和实验箱ping通,这下我真不知道该怎么解决问题。
-
问题2:来自打开虚拟机过程。昨日经过下午大约两小时的更新,我的电脑终于可以使用了。但是在打开虚拟机的时候,虚拟机提示我不能打开虚拟机。
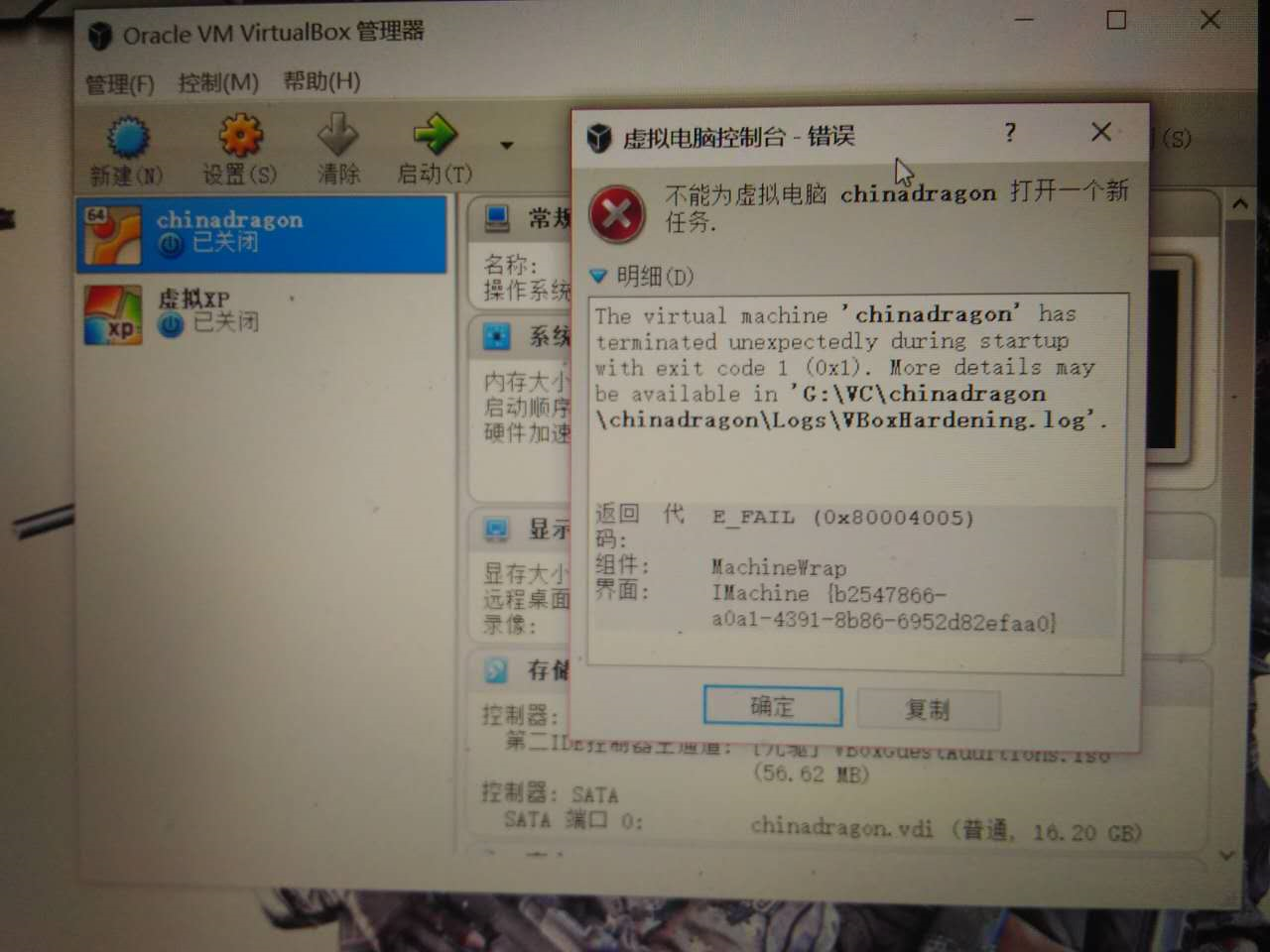
-
问题2解决方案:根据查找来的资料提示,我新下载了最新版本的VB虚拟机,删除旧的版本,现在虚拟机能用了。个人猜测,旧的虚拟机不能用是因为Win10在更新过程中,将C盘内存储与虚拟机相关的信息修改了,旧虚拟机没有办法找到执行路径,因此就不能打开安装有的虚拟机。安装新版本的虚拟机之后,新的虚拟机知道原来的虚拟机文件的位置,能执行。
代码托管
上周考试错题总结
- 错题6
下面代码的步长是()

A 1
B. N
C. NN
D NN*N
正确答案是C,而我选D,因为我认为步长和循环个数有关。但是这个想法和课本描述相悖。 - 错题12
下面()是I/O总线
A. USB
B .PCI
C .网卡
D .图形卡
正确答案: B 我的答案: C
网卡是工作在链路层的网络组件,不和CPU和主存直接相连,不属于I/O设备。
结对及互评
本周结对学习情况
- [20155207](http://www.cnblogs.com/lnaswxc/p/7967349.html)
- 结对学习内容
- 实验四合作部分
- 第九章第7、8节
其他(感悟、思考等,可选)
本章课程提到了数据结构堆和链表,还有数据结构图和树没有出现。我现在就很好奇,计算机系统当中哪一部分是会用到图结构,哪一部分会用到树结构。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 31/31 | 1/1 | 20/20 | |
| 第三周 | 24/55 | 2/3 | 24/44 | 知道浮点数怎么储存的 |
| 第四周 | 177/328 | 2/5 | 17/61 | 现在我的C语言程序也会在Linux命令行下使用了:*) |
| 第五周 | 54/382 | 2/7 | 18/79 | 复习一遍汇编语言 |
| 第七周 | 2360/2722 | 1/8 | 12/91 | |
| 第八周 | 624/3344 | 2/10 | 19/110 | 了解多线程和多进程 |
| 第九周 | 1112/4456 | 3/13 | 15/125 | 学习怎么实现pwd命令 |
| 第十一周 | 157/4613 | 2/15 | 10/135 | 在紧急情况下恢复不可使用的虚拟机 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:12小时
-
实际学习时间:10小时
-
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)

