Scrapy-redis 分布式爬虫
Scrapy-redis 分布式爬虫
Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件。scrapy-redis 的解决是把这个Scrapy queue换成redis数据库(也是指redis队列),从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取。
Scrapy-Redis分布式策略:
- Master端(核心服务器) :搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储;
- Slaver端(爬虫程序执行端) :负责执行爬虫程序,运行过程中提交新的Request给Master
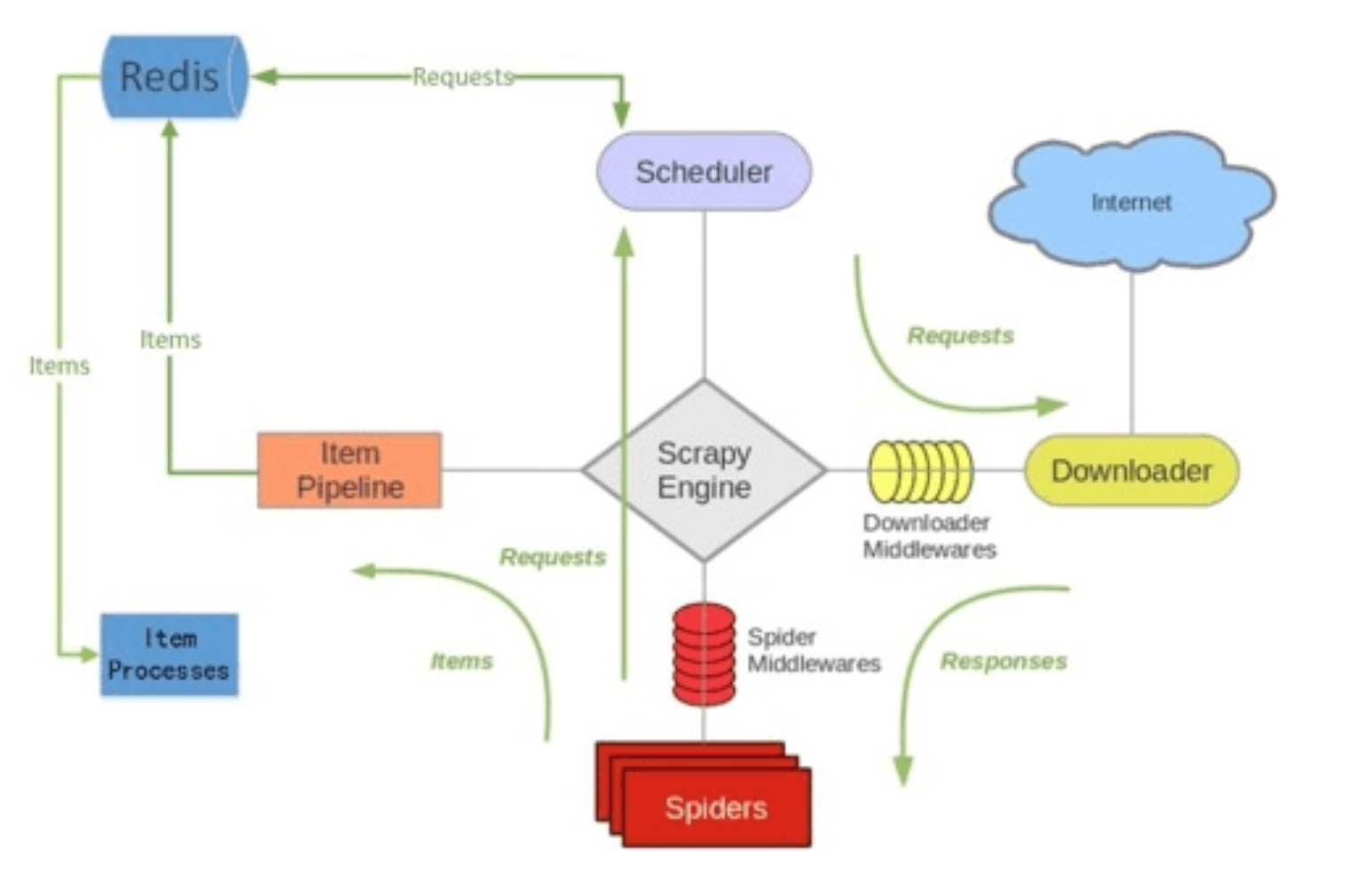
首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
Master 安装Redis
1.下载及安装
wget http://download.redis.io/releases/redis-3.2.6.tar.gz
tar xzf redis-3.2.6.tar.gz
cd redis-3.2.6
make
2.配置修改redis.conf
# 允许远程连接
# bind 127.0.0.1
# 改为yes 作为守护进程在后端执行
daemonize yes
# 禁用敏感命令
# 删除库
rename-command FLUSHDB ""
# 删除所有
rename-command FLUSHALL ""
3.启动redis服务
# 启动redis 服务
[root@baolin src]# /usr/local/redis-3.2.6/src/redis-server /usr/local/redis-3.2.6/redis.conf
4.通过远程连接
[root@baolin src]# ./redis-cli -h 192.8.21.100
5.通过 Redis Desktop Manager IDE连接
Slaver端安装scrapy-redis模块
1.Linux端安装:
pip3.6 install scrapy-redis
应用官方GitHub案例
1.源码地址
https://github.com/rmax/scrapy-redis
2.下载源码地址
# clone github scrapy-redis源码文件
git clone https://github.com/rmax/scrapy-redis.git

