
神经网络 误差逆传播算法推导 BP算法
误差逆传播算法是迄今最成功的神经网络学习算法,现实任务中使用神经网络时,大多使用BP算法进行训练。
给定训练集\(D={(x_1,y_1),(x_2,y_2),......(x_m,y_m)},x_i \in R^d,y_i \in R^l\),即输入示例由\(d\)个属性描述,输出\(l\)个结果。如图所示,是一个典型的单隐层前馈网络,它拥有\(d\)个输入神经元、\(l\)个输出神经元、\(q\)个隐层神经元,其中,\(\theta_j\)表示第\(j\)个神经元的阈值,\(\gamma_h\)表示隐层第\(h\)个神经元的阈值,输入层第\(i\)个神经元与隐层第\(h\)个神经元连接的权值是\(v_{ih}\),隐层第\(h\)个神经元与输出层第\(j\)个神经元连接的权值是\(w_{hj}\)。
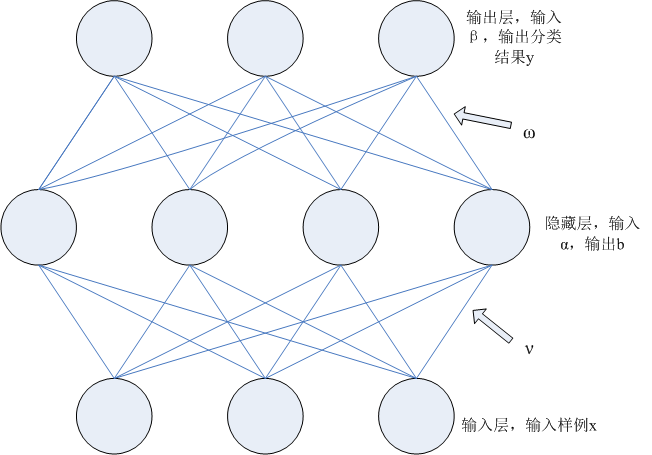
于是,按照神经网络的传输法则,隐层第\(h\)个神经元接收到的输入\(\alpha_h=\sum_{i=1}^dv_{ih}x_i\),输出\(b_h=f(\alpha_h-\gamma_h)\),输出层\(j\)第个神经元的输入\(\beta_j=\sum_{h=1}^qw_{hj}b_h\),输出\(\widehat{y}_j^k=f(\beta_j-\theta_j)\),其中\(f\)函数是“激活函数”,\(\gamma_h\)和\(\theta_j\)分别是隐藏层和输出层的阈值,选择Sigmoid函数\(f(x)=\frac{1}{1+e^{-x}}\)作为激活函数。
对训练样例\((x_k,y_k)\),通过神经网络后的输出是\(\widehat{y}_k=(\widehat{y}_1^k,\widehat{y}_2^k,......,\widehat{y}_l^k)\),则其均方误差为
为了使输出的均方误差最小,我们以均方误差对权值的负梯度方向进行调整,给定学习率\(\eta\),
这里为什么是取负梯度方向呢?因为我们是要是均方误差最小,而
\(w\)的更新估计式为
如果,\(\frac{\partial E_k}{\partial w_{ij}}>0\),则表明减小\(w\)才能减小均方误差,所以\(\Delta w\)应该小于零,反之,如果\(\frac{\partial E_k}{\partial w_{ij}}<0\),则表明增大\(w\)的值可以减小均方误差,所以所以\(\Delta w\)应该大于零,所以在这里取负的偏导,以保证权值的改变是朝着减小均方误差的方向进行。
在这个神经网络中,\(E_k\)是有关\(\widehat{y}_j^k\)的函数,\(\widehat{y}_j^k\)是有关\(\beta_j\)的函数,而\(\beta_j\)是有关\(w_{ij}\)的函数,所以有
显然,
而对Sigmoid函数有
所以
将式(7)代入式(3)和式(4),就得到BP算法中关于\(\Delta w_{ij}\)的更新公式
类似可得,
其中,式(10)和式(11)中
至此,误差逆传播算法的推导已经完成,我们可以回过头看看,该算法为什么被称为误差逆传播算法呢?误差逆传播,顾名思义是让误差沿着神经网络反向传播,根据上面的推导, \(\Delta w_{ij}=-\eta(\widehat{y}^k_j-y^k_j).\frac{\partial \widehat{y}_j^k}{\partial \beta_j}.b_h=\eta g_jb_h\),其中,\((\widehat{y}^k_j-y^k_j)\)是输出误差,\(\frac{\partial \widehat{y}_j^k}{\partial \beta_j}\) 是输出层节点的输出\(y\)对于输入\(\beta\)的偏导数,可以看做是误差的调节因子,我们称\(g_j\)为“被梯度调节后的误差”;而\(\Delta v_{ih}=\eta e_hx_i\),\(e_h=b_h(1-b_h)\sum_{j=1}^lw_{hj}g_j=\frac{\partial b_h}{\partial \alpha_h}\sum_{j=1}^lw_{hj}g_j\),所以\(e_h\)可以看做是“调节后的误差”\(g_j\)通过神经网络后并经过调节的误差,并且我们可以看出:权值的调节量=学习率x调节后的误差x上层节点的输出,算是对于误差逆向传播法表面上的通俗理解,有助于记忆。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号