数据结构
【数据结构】
1 堆栈的区别
内存中几个区的理解:
栈区:由编译器自动分配和释放,存放函数的参数值、局部变量值等,类似数据结构的栈。
堆区:由程序员分配和释放,若程序员不释放,程序结束时可能系统自动回收。类似数据结构中的链表
全局区(静态区):全局变量和静态变量存储在一起,初始化全局变量和静态变量在一块区域,未初始化的全局变量和静态变量在一块临近区域。程序结束由系统释放。
文字常量区:常量字符串就放在这里,程序结束由系统释放
程序代码区:存放函数体的二进制码
栈:先进先出
申请方式:系统分配
申请后系统响应:栈的剩余空间大于所申请空间,系统将为程序提供内存,否则报错栈溢出
申请大小限制:连续内存区域,栈的大小2M,能从栈获取的空间比较小
申请效率:系统自动分配,速度快,程序员无法控制
堆:先进后出
申请方式:自己申请并指明大小
申请后系统响应:系统收到程序请求,遍历链表,寻找第一个空间大于所申请空间的堆节点,系统自动释放多余的空闲链表
申请大小限制:不连续内存区域,堆大小受计算机虚拟内存影响,堆获取比较灵活,区域较大
申请效率:new分配,速度较慢,容易产生碎片,用起来方便
2 二叉树的遍历
遍历即将树的所有结点访问且仅访问一次。按照根节点位置的不同分为前序遍历,中序遍历,后序遍历。
前序遍历:根节点->左子树->右子树
中序遍历:左子树->根节点->右子树
后序遍历:左子树->右子树->根节点
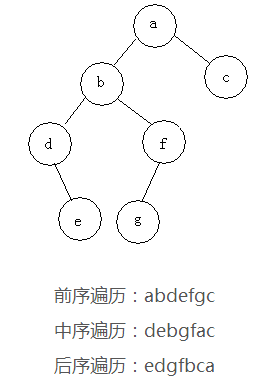
满二叉树一定是完全二叉树,但是反过来就不一定。
树的深度:树的最大层次就是深度,比如上图,深度是4。很容易得出,深度为k的树,拥有的最大结点数是2的k次方减1。
1)已知前序、中序遍历,求后序遍历
前序遍历: GDAFEMHZ
中序遍历: ADEFGHMZ
画图:
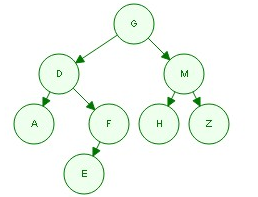
后序遍历顺序为:AEFDHZMG
2)已知中序和后序遍历,求前序遍历
中序遍历: ADEFGHMZ
后序遍历: AEFDHZMG
画图
前序遍历:GDAFEMHZ
3)已知前序和后序遍历,不能求中序遍历
4)前序遍历abcdefg,下面不可能中序是:
A abcdefg B gfedcba C bcdefga D bceadfg
选D,因为a为根,a左边必在右侧左边,唯D中bce 在dfg左边与题干不符
5)二叉搜索树:左树的所有关键字都小于根关键字,右侧的都大于根关键字
6)有向图拓扑排序:特点,有向无环图才有拓扑排序
(1)从有向图中选取一个没有前驱(即入度为0)的顶点,并输出之;
(2)从有向图中删去此顶点以及所有以它为尾的弧; 重复上述两步,直至图空,或者图不空但找不到无前驱的顶点为止。
7)哈夫曼编码
abcdabaa,最少需要多长二进制字符串解码回原来字符
解答:abcdabaa有4个a、2个b、1个c、1个d。构造哈弗曼树。a编码0(1位),b编码10(2位)c编码110(三位)d编码111(三位),长度为:1*4+2*2+1*3+3*1=14
【操作系统】
操作系统面试主要包括进程、线程、内存管理、垃圾回收、缓存诸多方面
1 进程
作业:用户在一次解题或一个事务处理过程中要求计算机系统所做工作的集合。它包括用户程序,所需要的数据及控制命令等,作业是有一系列有序的步骤组成。
进程:一个程序在一个集合上的一次执行的过程。
线程:线程是进程的一个实体,是被系统独立调度和执行的基本单位
管程:定义了一个数据结构和该数据结构上的能为并发进程所执行的一组操作,这组操作能够同步进程和改变管程中的数据。
进程间的通信:所谓进程通信就是不同进程之间的一些接触,即传递一些信息,常用包括信号、信号量、消息队列、共享内存。
Windows编程中互斥器(mutex)的作用和临界区(citical section):互斥器是进程之间互斥,临界区是线程之间互斥。
可剥夺式处理机调度问题:本质是短作业优先,最短剩余时间作业优先。
死锁问题:
处理死锁的两种方法:一是防止其发生,二是发生后进行处理。避免死锁的著名算法是银行家算法
产生死锁的4个必要条件:(只要系统发生死锁以下4种条件必然成立)
- 互斥条件:一个资源每次只能被一个进程使用。(不可剥夺的)
- 请求与保持条件:一个进程因请求资源而堵塞时,对已获得的资源保持不变
- 不剥夺条件:进程已获得的资源,在未使用完之前,不能强行剥夺。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
防止死锁的方法:
- 采用资源静态分配策略,破坏部分分配条件即破坏请求与保持条件
- 破坏不可剥夺条件
- 破坏循环等待条件
死锁后处理方法:杀死某个激活死锁进程
fork函数:进程分叉生成父子进程,子进程拷贝父进程绝大部分栈缓冲区等,系统为子进程创建一个新的进程,进程id与父进程不一样,两者是独立的进程,涉及写数据时,子进程有自己的数据空间,其他情况都是共享空间,在数据修改时,系统为子进程申请新的页面。
进程的三种基本状态:
- 就绪状态:当进程分配到除CPU以外的所有必要资源,只要获得处理机便可执行
- 执行状态:程序在处理机上执行的情况
- 阻塞状态:正在执行的进程,由于某个事件发生而无法执行时,便放弃处理机。引起阻塞原因有I/O完成,申请缓冲区不满足,等待信号
2 线程
进程和线程的区别:
- 进程是一次性执行,线程可以理解进程执行体的一个程序片段
- 进程间是独立的,线程运行在进程空间内,同一进程产生的线程共享同一内存空间
- 同一进程的两段代码不能同时进行,除非引入线程
- 线程属于进程,结束进程即结束该进程下所有线程
- 线程占用的资源少于进程占用的资源
- 进程和线程都有优先级,进程可以通信,线程不可以
PE文件(可执行文件):EXE,DLL,OCX,SYS,COM
Windows搜索DLL的顺序:内存,KnownDLLs,清单与local,应用程序目录,当前工作目录,系统目录,路径变量
动态链接库(import Libary)和静态链接库:
静态链接库:包含实际的执行代码,地址符号等,参与编译,生成可执行文件包含全部指令,
动态链接库:作为共享函数库的可行性文件,只包含地址符号,不参与编译,节省内存,减少交换操作,节省磁盘空间,易于升级,支持多语言等
3 内存管理
Windows内存管理的几种方式和优缺点:页式管理、段式管理,段页式管理
页式管理:基本原理是将进程的虚拟空间划分为若干长度相等的页,把内存按照页的大小分片或者页面,然后把虚拟地址和内存地址建议一一对应的页表。优点是没有外碎片,每个内碎片不超过页,缺点是增加系统开销。
段式管理:按照内容或过程函数分成段,每段有自己的名字,然后通过地址影射把段式地址转换为实际内存物理地址,优点可以分别编译和编写,不同类型的段采取不同的保护,按段单位进行共享,缺点是产生碎片
段页式管理:综合页式管理和段式管理的优点
内存抖动(Thrashing):一般是内存分配算法不好,内存太小或者程序算法不佳引起的页面频繁从内存调入/调出的行为。
虚拟存储器:基本思想是程序、数据、堆栈总的大小可以超过物理存储器的大小,操作系统把当前使用的部分保留内存中,其他部分保存在磁盘上。
某虚拟内存采用页式管理,使用LRU页面管理算法,下面页面访问地址流一共几次页面失败
1,8,1,7,8,2,7,2,1,8,3
分析:LRU算法:本质是很久没有使用的页面,很有可能在未来较长一段时间内不会用到
1,不在内存中,1次页面失效,内存中页面是1
8,不在内存中,1次页面失效,内存中页面是1,8
1,在内存中
7,不在内存中,1次页面失效,内存中页面是1,8,7
8,在内存中
2,不在内存中,1次页面失效,内存中页面是1,8,7,2
7,在内存中
2,在内存中
1,在内存中
8,在内存中
3,不在内存中,1次页面失效,内存中页面是1,8,3,2根据LRU页面管理算法页面7最久没有使用,将其换了
【网络原理】
网络原理面试主要考察局域网、广域网、IP管理等诸方面
1 网络结构
OSI参考模型有七层,分别是物理层、数据链路层、网络层、传输层、会话层、表示层,应用层
物理层:涉及信道上传输的原始比特流
数据链路层:主要任务是加强物理层的传输原始比特流的功能,使之对应的网络层显现为无错线路,发送包把输入数据封装在数据帧,按照顺序传出去并处理接收方回送的确认帧。
网络层:关系到子网的运行控制,其中一个关键问题是确认从源端到目的端如何选择路由
传输层:从会话层接受数据而且把其分成较小单位传给网络层
会话层:允许不同机器上用户建立回话关系
表示层:完成某些特定功能
应用层:包含大量人们普遍需要的协议
TCP和UDP区别:
举例说明二者区别:
TCP连接就像打电话,两者之间必须有一条不间断的通路,数据不到达对方,对方则一直等待,除非对方挂断电话,显著特点是先说的话先到,后说的话后到,是有顺序的。
UDP就像寄信一样,发现者只管发不管到,但是你的信封必须写明对方地址。信发的时间可能过了很久才到,也可能根本没有收到。
区别:
TCP是传输控制协议,提供面向连接的可靠的字节流服务,当客户机和服务器之间交换数据前,必须先在双方之间建立一个TCP连接,之后才可以传输数据。TCP提供超时重发、丢弃重复数据、检验数据、流量控制能功能,保证数据能从一端到另一端。
UDP是用户数据协议,是一个简单面向数据的运输层协议,UDP不可靠,它只把应用程序传给IP层的数据报发送出去,但是不保证到达目的地。由于UDP在传输数据包前不需要在客户机和服务器之间建立一个连接,且没有超时重发机制,所以传输速度很快。
2 网络协议问题
主网划分:让主网分成两段,子网掩码分别是0xff 0xff 0x80 0x00 和 0xff 0xff 0x00 0x00 如:40.15.0.0可以划分40.15.0.0/17和 40.15.128.0/17
- 大量发出IP请求,肯定很多不可达,返回不可达错误
- 包未到达终点不可能重组,但可以分散成碎片
- 网络堵塞问题,堵塞导致丢包
如何编写Socket套接字?
分析:Socket相当于进行网络两端的插座,只有对方的Socket和自己的Socket有通信连接,双方就可以发送和接收数据,具体如下:
服务器端程序编写:
- 调用ServerSocket(int port)创建一个服务器端套接字,并绑定到指定端口
- 调用accept(),监听连接请求,则接收连接,返回通信套接字
- 调用Socket类的getOutStream()和getInputStream()获取输出流和输入流,开始网络数据的发送和接收。
- 关闭通信套接字Socket.close()
客户端程序编写:
- 调用Socket()创建一个流套接字,并连接到服务器上
- 调用Socket类的getOutStream()和getInputStream()获取输出流和输入流,开始网络数据的发送和接收。
- 关闭通信套接字Socket.close()
与10.110.12.29 Mask 255.255.255.224属于同一网段的主机IP地址是:10.110.12.30 因为10.110.12.0-10.110.12.31网络号0,广播地址31,可用地址1~30
3 网络安全问题
入侵和防火墙有什么不同?各有什么优缺点?
防火墙:增强机构内部网络安全性,对内网的攻击无能为力
入侵检测:扫描当前网络的活动,监视和记录网络流量,根据定义好的规则来过滤从主机网卡到线上的流量,提供实时报警。
综述,防火墙和入侵检测的优劣,防火墙相当于大楼的门卫系统,入侵检测相当于大楼内的监视系统,两者缺一不可,应两者结合较好。
端口:
ftp:21 SMTP(邮件传输协议):25 HTTP:80 RPC(远程调用):135
4 网络其他问题
常见协议:
DACP:动态主机配置协议
VoIP:语音传输协议
P2P:点对点(我为人人,人人为我)
IPX:互联网数据包交换协议
SPX:序列分组交换协议
SNMP:简单网络管理协议
TCP:传输控制协议
IP:网络之间互联协议
三次握手和四次挥手:
TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接,如图1所示。
(1)第一次握手:建立连接时,客户端A发送SYN包(SYN=j)到服务器B,并进入SYN_SEND状态,等待服务器B确认。
(2)第二次握手:服务器B收到SYN包,必须确认客户A的SYN(ACK=j+1),同时自己也发送一个SYN包(SYN=k),即SYN+ACK包,此时服务器B进入SYN_RECV状态。
(3)第三次握手:客户端A收到服务器B的SYN+ACK包,向服务器B发送确认包ACK(ACK=k+1),此包发送完毕,客户端A和服务器B进入ESTABLISHED状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据。
CP的连接的拆除需要发送四个包,因此称为四次挥手(four-way handshake)。客户端或服务器均可主动发起挥手动作,在socket编程中,任何一方执行close()操作即可产生挥手操作。
(1)客户端A发送一个FIN,用来关闭客户A到服务器B的数据传送。
(2)服务器B收到这个FIN,它发回一个ACK,确认序号为收到的序号加1。和SYN一样,一个FIN将占用一个序号。
(3)服务器B关闭与客户端A的连接,发送一个FIN给客户端A。
(4)客户端A发回ACK报文确认,并将确认序号设置为收到序号加1。
【数据库和SQL语言】
1 数据库理论:
数据库四大范式:
1NF:属性值不可分割,每列一个值
2NF:完全依赖主键不能部分依赖
3NF:非主属性不依赖其他属性
BCNF :如果关系模式R是第一范式,且每个属性都不传递依赖于R的主键,称R为BCNF的模式。
4NF:D是R上的多值依赖集合。 如果D中成立非平凡多值依赖X→Y时,X必是R的超键,那么称R是第四范式的模式。
存储过程和函数的区别 :
存储过程:用户定义的一系列SQL语句的集合,涉及特定表或其他对象的任务,用户可以调用存储过程。
函数:是数据库已定义的方法,它接收参数并返回某种类型的值,并且不涉及特定用户表。
数据库事务:指作为单个逻辑工作单元执行的一系列操作,这些操作要么全做要么全不做,是一个不可分割的工作单位。
事务的开始与结束可以由用户显式控制。 如果用户没有显式地定义事务,则由DBMS按默认规定自动划分事务。 事务具有原子性、 一致性、 独立性及持久性等特点。
- 原子性:指一个事务要么全部执行,要么不执行。
- 一致性:指事务的运行并不改变数据库中数据的一致性。
- 独立性:指两个以上的事务不会出现交错执行的状态。 因为这样可能会导致数据不一致。
- 持久性: 事务运行成功以后,就系统的更新是永久的。 不会无缘无故的回滚。
游标的作用
定位结果集的行。 通过判断全局变量@@FETCH_ STATUS可以判断其是否到了最后。 通常此变量不等于0表示出错或到了最后。
触发器事前触发和事后触发区别,语句级触发和行级触发区别
事前触发器:运行于触发事件发生之前,而事后触发器运行于触发事件发生之后。语句级触发器可以在语句执行前或后执行,而行级触发在触发器所影响的每一行触发一次。
SQL注入式攻击防范
- 所谓SQL注入式攻击,就是攻击者把SQL命令插入到Web表单的输入域或页面请求的查询字符串中,欺骗服务器执行恶意的SQL命令。 在某些表单中,用户输入的内容直接用来构造动态SQL命令,
- 或作为存储过程的输入参数,这类表单特别容易受到SQL注入式攻击。
- 防范SQL注入式攻击闯入只要在利用表单输入的内容构造SQL命令之前,把所有输入内容过滤一番就可以了。 过滤输入内容可以按多种方式进行。
- 替换单引号,即把所有单独出现的单引号改成两个单引号,防止攻击者修改SQL命令的含义。
- 删除用户输入内容中的所有连字符,防止攻击者顺利获得访问权限。
- 对于用来执行查询的数据库账户,限制其权限。 用不同的用户账户执行查询、 插入、 更新、 删除操作。
- 用存储过程来执行所有的查询。 SQL参数的传递方式将防止攻击者利用单引号和连字符实施攻击。
- 检查用户输入的合法性,确信输入的内容只包含合法的数据。
- 将用户登录名称、 密码等数据加密保存。
- 检查提取数据的查询所返回的记录数量。 如果程序只要求返回一个记录,但实际返回的记录却超过一行,那就当做出错处理。
解释聚集索引和非聚集索引之间的区别
聚集索引:聚集索引的顺序就是数据的物理存储顺序
非聚集索引:索引顺序与数据物理排列顺序无关。 正是因为如此,所以一个表最多只能有一个聚集索引。
2 SQL语言
找出表ppp里面num最小的数,不能使用min函数。

或者:

找出表ppp里面最小的数,可以使用min函数

选择表ppp2中num重复的记录

写出复制表、 拷贝表和四表联查的SQL语句。
复制表(只复制结构,源表名:A,新表名:B):

拷贝表(拷贝数据,源表名:A,新表名:B):

四表联查:
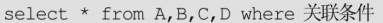
在SQL Server中如何用SQL语句建立一张临时表,注意,临时表要在表名前面加“#”
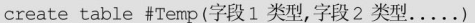
有数据表A,有一个字段LASTUPDATETIME,是最后更新的时间,如果要查最新更新过的记录,如何写SQL语句

有一个数据库,只有一个表,包含着1000个记录,你能想出一种解决方案来把第5到第7行的记录取出来么?不要使用航标和索引。
建立数据库:
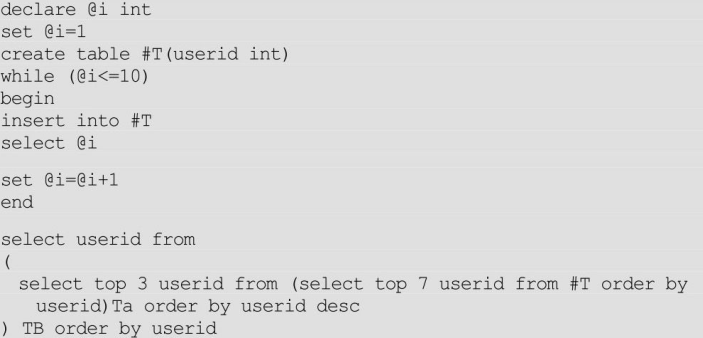
删除数据库:

提取数据:

或者:

或者:

要查数据表中第30到40条记录,有字段ID,但是ID并不连续。 如何写SQL语句
SQL语句如下:

3 SQL主观题
一个表(表a),里面有10条数据,这10条数据都是相同的,现要删除其中9条。请问怎么写SQL语句?

我想把当前正在运行着的MS SQL Server中的一个数据库改名,请问应执行什么命令?(不能删除数据库)
sp_renamedb命令可以更改数据库的名称。
语法如下:

参数:
是数据库的当前名称。 old_name为sysname类型,无默认值。
是数据库的新名称。 new_name必须遵循标识符规则。 new_name为sysname类型,无默认值。
返回代码值:0(成功)或非零数字(失败)
作者:白宁超,工学硕士,现工作于四川省计算机研究院,研究方向是自然语言处理和机器学习。曾参与国家自然基金项目和四川省科技支撑计划等多个省级项目。著有《自然语言处理理论与实战》一书。 自然语言处理与机器学习技术交流群号:436303759 。
出处:http://www.cnblogs.com/baiboy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2015-10-27 java之文件基本操作