【NLP】3000篇搜狐新闻语料数据预处理器的python实现
3000篇搜狐新闻语料数据预处理器的python实现
2017年5月5日17:20:04
摘要: 关于自然语言处理模型训练亦或是数据挖掘、文本处理等等,均离不开数据清洗,数据预处理的工作。这里的数据不仅仅指狭义上的文本数据,当然也包括视频数据、语音数据、图片数据、监控的流数据等等。其中数据预处理也有必要强调下,决然不是简单是分词工具处理后,去去停用词那么简单。即使去停用词,你选择的粒度尺寸也是有影响的,这跟工作性质和精确度要求也有着紧密的联系。其次选择多大的规模以及怎样维度都是有讲究的。本文由于主要针对新闻文本语料处理,经处理后可用于文本分类、文本聚类、特征提取、文本摘要等学习模型的训练。首先本文介绍下新闻语料的文本信息和编码问题;其次,对本实验运行的环境进行简单介绍,以及整个预处理器的框架构造;接着对单文本和批量文本的预处理工作的原理和实现介绍;还有对python如何调用java程序也通过实例进行演示。最后,对jieba分词工具的主要实现进行补充。本人邮箱:datathinks@qq.com,主页:http://www.cnblogs.com/baiboy/(本文原创,转载请标注原文出处:3000篇搜狐新闻语料数据预处理器的python实现 )
1 搜狐新闻语料获取和编码规范
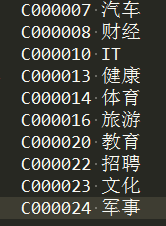
简介:本文训练的新闻语料是从搜狐官网下载的10类3000篇新闻真实语料,具体如下图,其中每类下面是300篇新闻文章。其中:C000007 汽车,C000008 财经,C000010 IT,C000013 健康,C000014 体育,C000016 旅游,C000020 教育,C000022 招聘,C000023 文化,C000024 军事
这个语料开始不能使用,主要是编码问题。如果少量尚可以采用Notepad++进行编码转换,如此的文本量手动就那么费时费力,更不必说更大规模语料了。故而本文采用批量格式转码器进行处理【BatUTF8Conv,读者可以自行下载】。本文的10类3000篇新闻语料共计16.4M,经过编码处理后,读者可以到:【链接: https://pan.baidu.com/s/1jIJrGKu 密码: kksp】下载使用即可
2 开发环境和程序结构介绍
开发环境
本文使用的开发环境是sublime Text +anaconda集成的运行环境,其中(1)如果使用结巴分词,需要下载结巴分词并在本地安装.(2)如果使用hanLp,需要下载jar和hanLP进行安装并配置。
具体配置读者可以参照:【Python开发工具:Anaconda+Sublime】一文进行配置
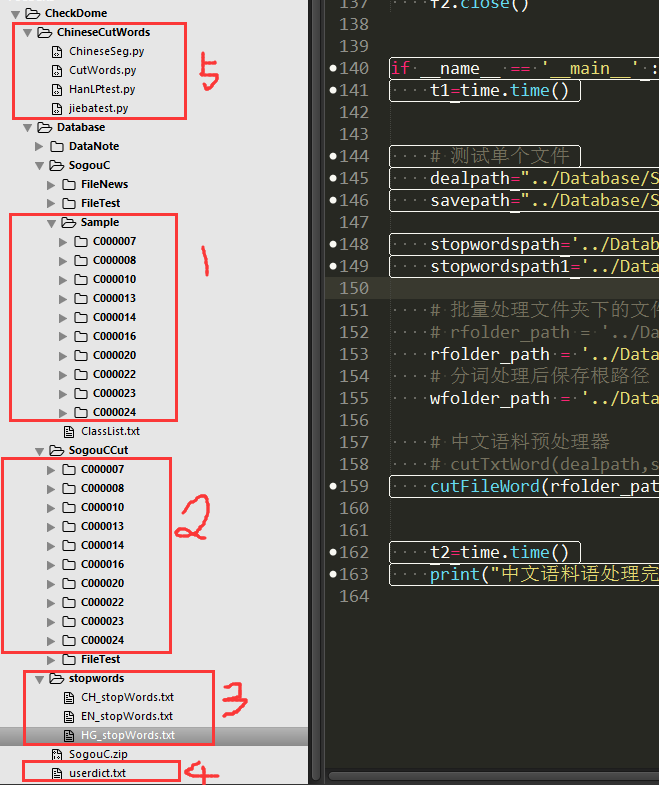
标记1:经过编码处理后的新闻语料数据
标记2:经过分词等预处理后的熟语料数据
标记3:分别是1892字的中文停用词表、891字的英文停用词表、哈工大的767字的中文停用词表(下载链接: https://pan.baidu.com/s/1c1QFpcs 密码: zsek)
标记4:自定义词典
标记5:中文预处理程序和相关分词工具代码展示
3 单个文件的预处理
3.1 测试单个文件原路径和保存路径及停用词路径
1 2 3 4 | # 测试单个文件dealpath="../Database/SogouC/FileTest/1.txt"savepath="../Database/SogouCCut/FileTest/1.txt"stopwordspath='../Database/stopwords/CH_stopWords.txt' |
查看下测试文件如下:
测试处理结果:

3.2 加载自定义结巴词典
1 2 | sys.path.append("../")jieba.load_userdict("../Database/userdict.txt") # 加载自定义分词词典 |
3.3 单文本处理主函数介绍
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | '''分词.词性标注以及去停用词stopwordspath: 停用词路径dealpath:中文数据预处理文件的路径savepath:中文数据预处理结果的保存路径'''def cutTxtWord(dealpath,savepath,stopwordspath): stopwords = {}.fromkeys([ line.rstrip() for line in open(stopwordspath,"r",encoding='utf-8')]) # 停用词表 with open(dealpath,"r",encoding='utf-8') as f: txtlist=f.read() # 读取待处理的文本 words =pseg.cut(txtlist) # 带词性标注的分词结果 cutresult=""# 获取去除停用词后的分词结果 for word, flag in words: if word not in stopwords: cutresult += word+"/"+flag+" " #去停用词 getFlag(cutresult,savepath) # |
4 批量文件的预处理
语料预处理器的核心:目的是通过用户传输预处理文本文件夹即可,其后面的所有子文件夹自动处理,且将处理结果单独按照原语料结构格式进行归一化保存。这里面涉及几个问题:(1)支持停用词的处理;(2)采用结巴分词,支持自定义词典和词语合并拆分功能;(3)支持词性筛选;(4)支持标准化规约化语料集的形成
随机查看批量预处理中C000024 军事的0.txt文件

处理后的结果:
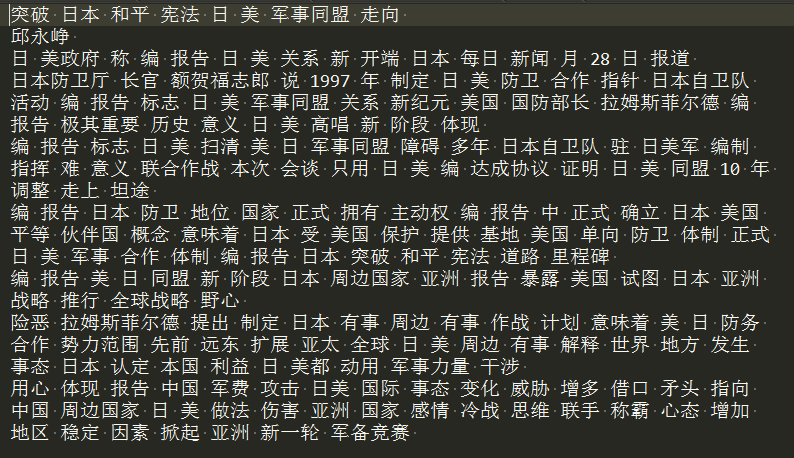
4.1 批量处理文件路径
1 2 3 4 5 6 7 8 9 10 11 12 13 | if __name__ == '__main__' : t1=time.time() stopwordspath='../Database/stopwords/CH_stopWords.txt' # 批量处理文件夹下的文件 rfolder_path = '../Database/SogouC/FileNews/' # 分词处理后保存根路径 wfolder_path = '../Database/SogouCCut/' # 中文语料预处理器 cutFileWord(rfolder_path,wfolder_path,stopwordspath) # 多文本预处理器 t2=time.time() print("中文语料语处理完成,耗时:"+str(t2-t1)+"秒。") #反馈结果 |
4.2 分词.词性标注以及去停用词
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | '''分词.词性标注以及去停用词stopwordspath: 停用词路径read_folder_path :中文数据预处理文件的路径write_folder_path :中文数据预处理结果的保存路径filescount=300 #设置文件夹下文件最多多少个'''def cutFileWord(read_folder_path,write_folder_path,stopwordspath): # 停用词表 stopwords = {}.fromkeys([ line.rstrip() for line in open(stopwordspath,"r",encoding='utf-8')]) # 获取待处理根目录下的所有类别 folder_list = os.listdir(read_folder_path) # 类间循环 for folder in folder_list: #某类下的路径 new_folder_path = os.path.join(read_folder_path, folder) # 创建保存文件目录 path=write_folder_path+folder #保存文件的子文件 isExists=os.path.exists(path) if not isExists: os.makedirs(path) print(path+' 创建成功') else: pass save_folder_path = os.path.join(write_folder_path, folder)#某类下的保存路径 print('--> 请稍等,正在处理中...') # 类内循环 files = os.listdir(new_folder_path) j = 1 for file in files: if j > len(files): break dealpath = os.path.join(new_folder_path, file) #处理单个文件的路径 with open(dealpath,"r",encoding='utf-8') as f: txtlist=f.read() # python 过滤中文、英文标点特殊符号 # txtlist1 = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "",txtlist) words =pseg.cut(txtlist) # 带词性标注的分词结果 cutresult="" # 单个文本:分词后经停用词处理后的结果 for word, flag in words: if word not in stopwords: cutresult += word+"/"+flag+" " #去停用词 savepath = os.path.join(save_folder_path,file) getFlag(cutresult,savepath) j += 1 |
其中:
1) # 停用词表: stopwords = {}.fromkeys([ line.rstrip() for line in open(stopwordspath,"r",encoding='utf-8')])
此格式将文本列表进行字典化处理,具体查看fromkeys()方法的使用
2)# 获取根目录下的子文件夹集合: folder_list = os.listdir(read_folder_path)
3)#某类(子文件夹)下的所有文件:new_folder_path = os.path.join(read_folder_path, folder)
4)#创建文件:
1 2 3 4 5 6 7 | # 创建保存文件目录 path=write_folder_path+folder #保存文件的子文件 isExists=os.path.exists(path) if not isExists: os.makedirs(path) print(path+' 创建成功') else: pass |
5) # python 过滤中文、英文标点特殊符号: txtlist1 = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "",txtlist)
6)过滤停用词:
1 2 3 | for word, flag in words: if word not in stopwords: cutresult += word+"/"+flag+" " #去停用词 |
4.3 词性筛选
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | '''做词性筛选cutresult:str类型,初切分的结果savepath: 保存文件路径'''def getFlag(cutresult,savepath): txtlist=[] #过滤掉的词性后的结果 #词列表为自己定义要过滤掉的词性 cixing=["/x","/zg","/uj","/ul","/e","/d","/uz","/y"] for line in cutresult.split('\n'): line_list2=re.split('[ ]', line) line_list2.append("\n") # 保持原段落格式存在 line_list=line_list2[:] for segs in line_list2: for K in cixing: if K in segs: line_list.remove(segs) break else: pass txtlist.extend(line_list) # 去除词性标签 resultlist=txtlist[:] flagresult="" for v in txtlist: if "/" in v: slope=v.index("/") letter=v[0:slope]+" " flagresult+= letter else: flagresult+= v standdata(flagresult,savepath) |
其中:词性问题参加结巴分词官网文档
4.4 标准化处理
1 2 3 4 5 6 7 8 9 10 11 12 13 | '''标准化处理,去除空行,空白字符等。flagresult:筛选过的结果'''def standdata(flagresult,savepath): f2=open(savepath,"w",encoding='utf-8') for line in flagresult.split('\n'): if len(line)>=2: line_clean="/ ".join(line.split()) lines=line_clean+" "+"\n" f2.write(lines) else: pass f2.close() |
5 python调用java实现的HanLP工具
1 安装jar包,并通过查看其是否安装配置成功。(此处环境变量配置省略)
java命令
javac命令
2 在c盘下创建hanlp文件下,并将下面的hanlp.jar包下载复制到hanlp文件夹下:
链接: https://pan.baidu.com/s/1qYmB0XQ 密码: hz9v
3) 启动java虚拟机
1 | startJVM(getDefaultJVMPath(), "-Djava.class.path=C:\hanlp\hanlp-1.3.2.jar;C:\hanlp", "-Xms1g", "-Xmx1g") # 启动JVM,Linux需替换分号;为冒号: |
4)具体代码和执行结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 | # -*- coding:utf-8 -*-# Filename: main.pyfrom jpype import *startJVM(getDefaultJVMPath(), "-Djava.class.path=C:\hanlp\hanlp-1.3.2.jar;C:\hanlp", "-Xms1g", "-Xmx1g") # 启动JVM,Linux需替换分号;为冒号:print("="*30+"HanLP分词"+"="*30)HanLP = JClass('com.hankcs.hanlp.HanLP')# 中文分词print(HanLP.segment('你好,欢迎在Python中调用HanLP的API'))print("-"*70)print("="*30+"标准分词"+"="*30)StandardTokenizer = JClass('com.hankcs.hanlp.tokenizer.StandardTokenizer')print(StandardTokenizer.segment('你好,欢迎在Python中调用HanLP的API'))print("-"*70)# NLP分词NLPTokenizer会执行全部命名实体识别和词性标注print("="*30+"NLP分词"+"="*30)NLPTokenizer = JClass('com.hankcs.hanlp.tokenizer.NLPTokenizer')print(NLPTokenizer.segment('中国科学院计算技术研究所的宗成庆教授正在教授自然语言处理课程'))print("-"*70)print("="*30+"索引分词"+"="*30)IndexTokenizer = JClass('com.hankcs.hanlp.tokenizer.IndexTokenizer')termList= IndexTokenizer.segment("主副食品");for term in termList : print(str(term) + " [" + str(term.offset) + ":" + str(term.offset + len(term.word)) + "]")print("-"*70)print("="*30+" N-最短路径分词"+"="*30)# CRFSegment = JClass('com.hankcs.hanlp.seg.CRF.CRFSegment')# segment=CRFSegment()# testCase ="今天,刘志军案的关键人物,山西女商人丁书苗在市二中院出庭受审。"# print(segment.seg("你看过穆赫兰道吗"))print("-"*70)print("="*30+" CRF分词"+"="*30)print("-"*70)print("="*30+" 极速词典分词"+"="*30)SpeedTokenizer = JClass('com.hankcs.hanlp.tokenizer.SpeedTokenizer')print(NLPTokenizer.segment('江西鄱阳湖干枯,中国最大淡水湖变成大草原'))print("-"*70)print("="*30+" 自定义分词"+"="*30)CustomDictionary = JClass('com.hankcs.hanlp.dictionary.CustomDictionary')CustomDictionary.add('攻城狮')CustomDictionary.add('单身狗')HanLP = JClass('com.hankcs.hanlp.HanLP')print(HanLP.segment('攻城狮逆袭单身狗,迎娶白富美,走上人生巅峰'))print("-"*70)print("="*20+"命名实体识别与词性标注"+"="*30)NLPTokenizer = JClass('com.hankcs.hanlp.tokenizer.NLPTokenizer')print(NLPTokenizer.segment('中国科学院计算技术研究所的宗成庆教授正在教授自然语言处理课程'))print("-"*70)document = "水利部水资源司司长陈明忠9月29日在国务院新闻办举行的新闻发布会上透露," \ "根据刚刚完成了水资源管理制度的考核,有部分省接近了红线的指标," \ "有部分省超过红线的指标。对一些超过红线的地方,陈明忠表示,对一些取用水项目进行区域的限批," \ "严格地进行水资源论证和取水许可的批准。"print("="*30+"关键词提取"+"="*30)print(HanLP.extractKeyword(document, 8))print("-"*70)print("="*30+"自动摘要"+"="*30)print(HanLP.extractSummary(document, 3))print("-"*70)# print("="*30+"地名识别"+"="*30)# HanLP = JClass('com.hankcs.hanlp.HanLP')# segment = HanLP.newSegment().enablePlaceRecognize(true)# testCase=["武胜县新学乡政府大楼门前锣鼓喧天",# "蓝翔给宁夏固原市彭阳县红河镇黑牛沟村捐赠了挖掘机"]# for sentence in testCase :# print(HanLP.segment(sentence))# print("-"*70)# print("="*30+"依存句法分析"+"="*30)# print(HanLP.parseDependency("徐先生还具体帮助他确定了把画雄鹰、松鼠和麻雀作为主攻目标。"))# print("-"*70)text =r"算法工程师\n 算法(Algorithm)是一系列解决问题的清晰指令,也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。不同的算法可能用不同的时间、空间或效率来完成同样的任务。一个算法的优劣可以用空间复杂度与时间复杂度来衡量。算法工程师就是利用算法处理事物的人。\n \n 1职位简介\n 算法工程师是一个非常高端的职位;\n 专业要求:计算机、电子、通信、数学等相关专业;\n 学历要求:本科及其以上的学历,大多数是硕士学历及其以上;\n 语言要求:英语要求是熟练,基本上能阅读国外专业书刊;\n 必须掌握计算机相关知识,熟练使用仿真工具MATLAB等,必须会一门编程语言。\n\n2研究方向\n 视频算法工程师、图像处理算法工程师、音频算法工程师 通信基带算法工程师\n \n 3目前国内外状况\n 目前国内从事算法研究的工程师不少,但是高级算法工程师却很少,是一个非常紧缺的专业工程师。算法工程师根据研究领域来分主要有音频/视频算法处理、图像技术方面的二维信息算法处理和通信物理层、雷达信号处理、生物医学信号处理等领域的一维信息算法处理。\n 在计算机音视频和图形图像技术等二维信息算法处理方面目前比较先进的视频处理算法:机器视觉成为此类算法研究的核心;另外还有2D转3D算法(2D-to-3D conversion),去隔行算法(de-interlacing),运动估计运动补偿算法(Motion estimation/Motion Compensation),去噪算法(Noise Reduction),缩放算法(scaling),锐化处理算法(Sharpness),超分辨率算法(Super Resolution),手势识别(gesture recognition),人脸识别(face recognition)。\n 在通信物理层等一维信息领域目前常用的算法:无线领域的RRM、RTT,传送领域的调制解调、信道均衡、信号检测、网络优化、信号分解等。\n 另外数据挖掘、互联网搜索算法也成为当今的热门方向。\n"print("="*30+"短语提取"+"="*30)print(HanLP.extractPhrase(text, 10))print("-"*70)shutdownJVM() |
执行结果:
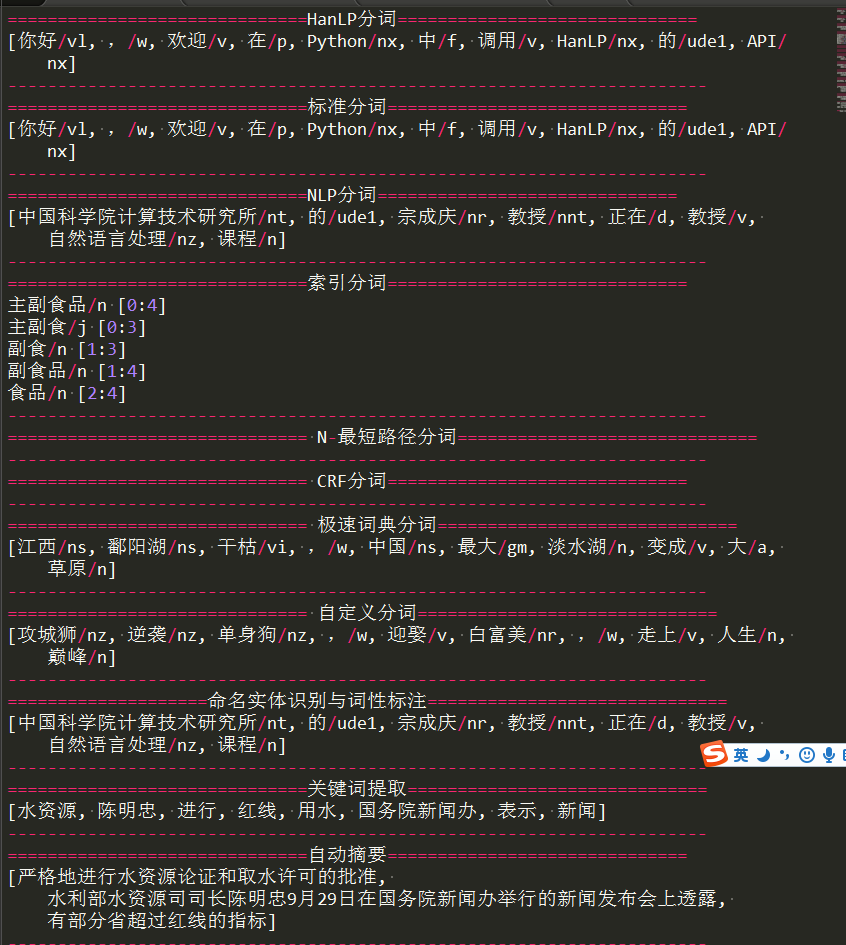
6 总结
新闻语料数据预处理器的python源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 | #coding=utf-8import osimport jiebaimport sysimport reimport timeimport jieba.posseg as psegsys.path.append("../")jieba.load_userdict("../Database/userdict.txt") # 加载自定义分词词典'''title:利用结巴分词进行文本语料处理:单文本处理器、批量文件处理器 1 首先对文本进行遍历查找 2 创建原始文本的保存结构 3 对原文本进行结巴分词和停用词处理 4 对预处理结果进行标准化格式,并保存原文件结构路径author:白宁超myblog:http://www.cnblogs.com/baiboy/time:2017年4月28日10:03:09''''''分词.词性标注以及去停用词stopwordspath: 停用词路径dealpath:中文数据预处理文件的路径savepath:中文数据预处理结果的保存路径'''def cutTxtWord(dealpath,savepath,stopwordspath): stopwords = {}.fromkeys([ line.rstrip() for line in open(stopwordspath,"r",encoding='utf-8')]) # 停用词表 with open(dealpath,"r",encoding='utf-8') as f: txtlist=f.read() # 读取待处理的文本 words =pseg.cut(txtlist) # 带词性标注的分词结果 cutresult=""# 获取去除停用词后的分词结果 for word, flag in words: if word not in stopwords: cutresult += word+"/"+flag+" " #去停用词 getFlag(cutresult,savepath) #'''分词.词性标注以及去停用词stopwordspath: 停用词路径read_folder_path :中文数据预处理文件的路径write_folder_path :中文数据预处理结果的保存路径filescount=300 #设置文件夹下文件最多多少个'''def cutFileWord(read_folder_path,write_folder_path,stopwordspath): # 停用词表 stopwords = {}.fromkeys([ line.rstrip() for line in open(stopwordspath,"r",encoding='utf-8')]) # 获取待处理根目录下的所有类别 folder_list = os.listdir(read_folder_path) # 类间循环 for folder in folder_list: #某类下的路径 new_folder_path = os.path.join(read_folder_path, folder) # 创建保存文件目录 path=write_folder_path+folder #保存文件的子文件 isExists=os.path.exists(path) if not isExists: os.makedirs(path) print(path+' 创建成功') else: pass save_folder_path = os.path.join(write_folder_path, folder)#某类下的保存路径 print('--> 请稍等,正在处理中...') # 类内循环 files = os.listdir(new_folder_path) j = 1 for file in files: if j > len(files): break dealpath = os.path.join(new_folder_path, file) #处理单个文件的路径 with open(dealpath,"r",encoding='utf-8') as f: txtlist=f.read() # python 过滤中文、英文标点特殊符号 # txtlist1 = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "",txtlist) words =pseg.cut(txtlist) # 带词性标注的分词结果 cutresult="" # 单个文本:分词后经停用词处理后的结果 for word, flag in words: if word not in stopwords: cutresult += word+"/"+flag+" " #去停用词 savepath = os.path.join(save_folder_path,file) getFlag(cutresult,savepath) j += 1'''做词性筛选cutresult:str类型,初切分的结果savepath: 保存文件路径'''def getFlag(cutresult,savepath): txtlist=[] #过滤掉的词性后的结果 #词列表为自己定义要过滤掉的词性 cixing=["/x","/zg","/uj","/ul","/e","/d","/uz","/y"] for line in cutresult.split('\n'): line_list2=re.split('[ ]', line) line_list2.append("\n") # 保持原段落格式存在 line_list=line_list2[:] for segs in line_list2: for K in cixing: if K in segs: line_list.remove(segs) break else: pass txtlist.extend(line_list) # 去除词性标签 resultlist=txtlist[:] flagresult="" for v in txtlist: if "/" in v: slope=v.index("/") letter=v[0:slope]+" " flagresult+= letter else: flagresult+= v standdata(flagresult,savepath)'''标准化处理,去除空行,空白字符等。flagresult:筛选过的结果'''def standdata(flagresult,savepath): f2=open(savepath,"w",encoding='utf-8') for line in flagresult.split('\n'): if len(line)>=2: line_clean="/ ".join(line.split()) lines=line_clean+" "+"\n" f2.write(lines) else: pass f2.close()if __name__ == '__main__' : t1=time.time() # 测试单个文件 dealpath="../Database/SogouC/FileTest/1.txt" savepath="../Database/SogouCCut/FileTest/1.txt" stopwordspath='../Database/stopwords/CH_stopWords.txt' stopwordspath1='../Database/stopwords/HG_stopWords.txt' # 哈工大停用词表 # 批量处理文件夹下的文件 # rfolder_path = '../Database/SogouC/Sample/' rfolder_path = '../Database/SogouC/FileNews/' # 分词处理后保存根路径 wfolder_path = '../Database/SogouCCut/' # 中文语料预处理器 # cutTxtWord(dealpath,savepath,stopwordspath) # 单文本预处理器 cutFileWord(rfolder_path,wfolder_path,stopwordspath) # 多文本预处理器 t2=time.time() print("中文语料语处理完成,耗时:"+str(t2-t1)+"秒。") #反馈结果 |
本文核心代码如上所示,直接调用源程序就可完成基本的数据清洗工作操作,重用性较高,可以自定义扩展分词,也可以自定义过滤词性。
作者:白宁超,工学硕士,现工作于四川省计算机研究院,研究方向是自然语言处理和机器学习。曾参与国家自然基金项目和四川省科技支撑计划等多个省级项目。著有《自然语言处理理论与实战》一书。 自然语言处理与机器学习技术交流群号:436303759 。
出处:http://www.cnblogs.com/baiboy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架