【Python五篇慢慢弹(5)】类的继承案例解析,python相关知识延伸
类的继承案例解析,python相关知识延伸
作者:白宁超
2016年10月10日22:36:57
摘要:继<快速上手学python>一文之后,笔者又将python官方文档认真学习下。官方给出的pythondoc入门资料包含了基本要点。本文是对文档常用核心要点进行梳理,简单冗余知识不再介绍,作者假使你用c/java/c#/c++任一种语言基础。本系列文章属于入门内容,老鸟可以略看也可以略过,新鸟可以从篇一<快速上手学python>先接触下python怎样安装与运行,以及pycharm编辑器的使用和配置;篇二<数据结构看python>介绍python语言中控制语句、列表、字典、元组、循环等基本操作;篇三<函数修行知python>细解python语言函数的范畴与内容;篇四<模块异常谈python>采用登录的案例详解模块来龙去脉;篇五<‘类’过依然继续前行,直至ending再出发>介绍类的基本操作,扩展虚拟环境、标准类库和下个系列预告。(本文原创,转载注明出处:类的继承案例解析,python相关知识延伸)
目录:
【Python五篇慢慢弹(1)】快速上手学python
【Python五篇慢慢弹(2)】数据结构看python
【Python五篇慢慢弹(3)】函数修行知python
【Python五篇慢慢弹(4)】模块异常谈python
【Python五篇慢慢弹(5)】‘类’过依然继续前行,直至ending再出发
1 类的相关介绍
【小记】本文中所有代码经过测试均可正常运行,python有个问题就是复制后会破坏原有格式。所以读者复制运行时报如下错误:SyntaxError: expected an indented block,是因为空格问题,可以预留4个空格,或者采用tab键空格,本篇也是系列文章的结束,除了类的相关介绍,后面扩展一些独立的知识点,下一个系列将是python自然语言处理系列文章,敬请期待......
命名空间 :从命名到对象的映射。当前命名空间主要是通过 Python 字典实现的.Python 中任何一个“.”之后的命名可以理解为属性 --例如,表达式 z.real 中的 real 是对象 z 的一个属性。如:
表达式 modname.funcname 中,modname 是一个模块对象,funcname 是它的一个属性
因此,模块的属性和模块中的全局命名有直接的映射关系:它们共享同一命名空间,作用域 是一个 Python 程序可以直接访问命名空间的正文区域。至少有三个命名空间可以直接访问的作用域嵌套在一起,包含局部命名的使用域在最里面,首先被搜索;其次搜索的是中层的作用域,这里包含了同级的函数;最后搜索最外面的作用域,它包含内置命名。global 语句用以指明某个特定的变量为全局作用域,并重新绑定它。nonlocal 语句用以指明某个特定的变量为封闭作用域,并重新绑定它。
作用域和命名空间示例
def scope_test():
def do_local():
spam = "local spam"
def do_nonlocal():
nonlocal spam
spam = "nonlocal spam"
def do_global():
global spam
spam = "global spam"
spam = "test spam"
do_local()
print("After local assignment:", spam)
do_nonlocal()
print("After nonlocal assignment:", spam)
do_global()
print("After global assignment:", spam)
scope_test()
print("In global scope:", spam)
运行结果:
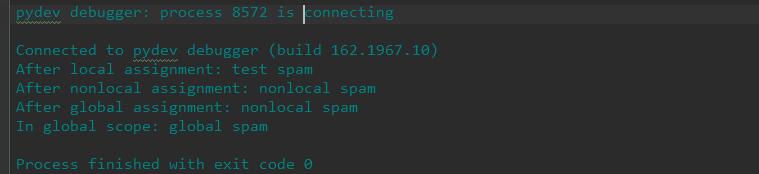
解析:
local 赋值语句是无法改变 scope_test 的 spam 绑定。nonlocal 赋值语句改变了 scope_test 的 spam 绑定,并且 global 赋值语句从模块级改变了 spam 绑定。
类的正确设计应该使用一个实例变量
class Dog:
def __init__(self, name):
self.name = name
self.tricks = [] # creates a new empty list for each dog
def add_trick(self, trick):
self.tricks.append(trick)
d = Dog('Fido')
d.add_trick('roll over')
print(d.tricks)
R运行结果:
E:\Python\python.exe E:/sourceCode/pydata/AddPro/MothedDome.py
['roll over']
Process finished with exit code 0
命名空间:
①大写方法名称的首字母,使用一个唯一的小字符串(也许只是一个下划线)作为数据属性名称的前缀,或者方法使用动词而数据属性使用名词。
②类不能用来实现③数据类型。
③一般,方法的第一个参数被命名为 self。这仅仅是一个约定:对 Python 而言,名称 self 绝对没有任何特殊含义。
④函数定义代码不一定非得定义在类中:也可以将一个函数对象赋值给类中的一个局部变量。例如:
通过 self 参数的方法属性,方法可以调用其它的方法:
class Bag:
def __init__(self):
self.data = []
def add(self, x):
self.data.append(x)
def addtwice(self, x):
self.add(x)
self.add(x)
2、类继承实例解析
实例分析:在python中类继承案例,要求如下:
① 创建一个BaseSubDome.py文件,编写类继承文件
② 父类是动物类,有初始化函数,且有动物讲话的方法
③ 子类是一个狗类,继承父类所有属性,并扩展自己方法
④ 调用子类讲话方法,并直接调用父类讲话方法
类继承实例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
__title__ = ''
__author__ = 'cuitbnc'
__mtime__ = '2016/10/9'
# 欢迎进入我的主页:http://www.cnblogs.com/baiboy/.
"""
class BaseAnimal:
def __init__(self,name,age):
self.name=name
self.age=age
print("this is 【 %s 】 and is BaseClass." %(self.name))
def speak(self):
print("my name is【 %s 】,age is 【 %d 】" %(self.name,self.age))
class SubDog(BaseAnimal):
def __init__(self,name,age,say):
BaseAnimal.__init__(self,name,age)
self.say=say
print("this SubClass is 【 %s 】."%(self.name))
print('_'*20+'调用子函数方法'+'_'*20)
def talk(self):
BaseAnimal.speak(self)
print("my name is 【 %s 】,today I 【 %d 】 years,I want say 【 %s 】" %(self.name,self.age,self.say))
ani=SubDog('dog',12,'汪汪...')
print(ani.talk())
print('_'*20+'直接调用父函数方法'+'_'*20)
BaseAnimal('tom',13).speak()
运行结果:

解析:
__init__方法(双下划线):__init__方法在类的一个对象被建立时,马上运行。这个方法可以用来对你的对象初始化 。注意,这个名称的开始和结尾都是双下划线。
我们把__init__方法定义为取一个参数name(以及普通的参数self)。在__init__方法里,我们只是创建一个新的域,也称为name。注意它们是两个不同的变量,尽管它们有相同的名字。点号使我们能够区分它们。最重要的是,在创建一个类的新实例的时候,把参数包括在圆括号内跟在类名后面,从而传递给__init__方法。这是这种方法的重要之处。现在,我们能够在我们的方法中使用self.name域。给C++/Java/C#程序员的注释__init__方法类似于C++、C#和Java中的constructor 。
3、python相关技术知识点扩展
python里面的私有变量与众不同
在c/c#/Java中设置私有变量均为 private 标示。而python里面以一个下划线开头的命名(例如 _spam )会被处理为 API 的非公开部分(无论它是一个函数、方法或数据成员)。
它会被视为一个实现细节,无需公开。
迭代器工作原理
还记得这个for循环语句?
例如:
>>> for element in ['bnc','Tom','jack']: print(element) bnc Tom jack
工作原理解析:采用迭代器机制。在后台,for 语句在容器对象中调用 iter() 。返回一个定义了 __next__() 方法的迭代器对象,它在容器中逐一访问元素。没有后续的元素时,__next__() 抛出一个 StopIteration 异常通知 for 语句循环结束。以下是其工作原理的示例:
>>> elements=['bnc','Tom','jack'] >>> it=iter(elements) >>> it <list_iterator object at 0x03C06E90> >>> next(it) 'bnc' >>> next(it) 'Tom' >>> next(it) 'jack' >>> next(it) Traceback (most recent call last): File "<pyshell#11>", line 1, in <module> next(it) StopIteration >>>
生成器工作原理
Generator 是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,需要返回数据的时候使用 yield 语句。
def reverse(data):
for index in range(len(data)-1, -1, -1):
yield data[index]
>>> for char in reverse('golf'):
... print(char)
...
f
l
o
g
前一节中描述了基于类的迭代器,它能作的每一件事生成器也能作到。因为自动创建了 __iter__() 和 __next__() 方法,生成器显得如此简洁。另一个关键的功能在于两次执行之间,局部变量和执行状态都自动的保存下来。这使函数很容易写,而且比使用 self.index 和 self.data 之类的方式更清晰。除了创建和保存程序状态的自动方法,当发生器终结时,还会自动抛出 StopIteration 异常。综上所述,这些功能使得编写一个正规函数成为创建迭代器的最简单方法。
虚拟环境和包
Python 应用程序经常会使用一些不属于标准库的包和模块。应用程序有时候需要某个特定版本的库,意味着可能无法安装一个 Python 来满足每个应用程序的要求。如果应用程序 A 需要一个特定模块的 1.0 版本,但是应用程序 B 需要该模块的 2.0 版本,这两个应用程序的要求是冲突的,安装版本 1.0 或者版本 2.0 将会导致其中一个应用程序不能运行。这个问题的解决方案就是创建一个 虚拟环境 (通常简称为 “virtualenv”),包含一个特定版本的 Python,以及一些附加的包的独立的目录树。不同的应用程序可以使用不同的虚拟环境。为了解决前面例子中的冲突,应用程序 A 可以有自己的虚拟环境,其中安装了特定模块的 1.0 版本。而应用程序 B 拥有另外一个安装了特定模块 2.0 版本的虚拟环境。如果应用程序 B 需求一个库升级到 3.0 的话,这也不会影响到应用程序 A 的环境。
创建虚拟环境
用于创建和管理虚拟环境的脚本叫做 pyvenv。要创建一个 virtualenv,首先决定一个你想要存放的目录接着运行 pyvenv 后面携带着目录名:
pyvenv tutorial-env
如果目录不存在的话,这将会创建一个 tutorial-env 目录,并且也在目录里面创建一个包含 Python 解释器,标准库,以及各种配套文件的 Python “副本”。一旦你已经创建了一个虚拟环境,你必须激活它。
在 Windows 上,运行:
tutorial-env/Scripts/activate
在 Unix 或者 MacOS 上,运行:
source tutorial-env/bin/activate
激活了虚拟环境会改变你的 shell 提示符,显示你正在使用的虚拟环境,并且修改了环境以致运行 python 将会让你得到了特定的 Python 版本。例如:
-> source ~/envs/tutorial-env/bin/activate (tutorial-env) -> python Python 3.5.2+ (3.4:c7b9645a6f35+, May 22 2015, 09:31:25) ... >>> import sys >>> sys.path ['', '/usr/local/lib/python35.zip', ..., '~/envs/tutorial-env/lib/python3.5/site-packages'] >>>
使用 pip 管理包
一旦你激活了一个虚拟环境,可以使用一个叫做 pip 程序来安装,升级以及删除包。默认情况下 pip 将会从 Python Package Index,<https://pypi.python.org/pypi>, 中安装包。
你可以通过 web 浏览器浏览它们,或者你也能使用 pip 有限的搜索功能:
(tutorial-env) -> pip search astronomy skyfield - Elegant astronomy for Python gary - Galactic astronomy and gravitational dynamics. novas - The United States Naval Observatory NOVAS astronomy library astroobs - Provides astronomy ephemeris to plan telescope observations PyAstronomy - A collection of astronomy related tools for Python.
pip 有许多子命令:“搜索”,“安装”,“卸载”,“freeze”(译者注:这个词语暂时没有合适的词语来翻译),等等。(请参考 installing-index 指南获取 pip 更多完整的文档。)
交互模式:
①错误处理
当错误发生时,解释器打印一个错误信息和堆栈跟踪。在交互模式下,它返回主提示符;当输入来自文件的时候,在打印堆栈跟踪后以非零退出(a nonzero exit)状态退出。有些错误是非常致命的会导致一个非零状态的退出;这也适用于内部错误以及某些情况的内存耗尽。所有的错误信息都写入到标准错误流;来自执行的命令的普通输出写入到标准输出。输入中断符(通常是 Control-C 或者 DEL)到主或者从提示符中会取消输入并且返回到主提示。 当命令执行中输入中断符会引起 KeyboardInterrupt 异常,这个异常能够被一个 try 声明处理。
②可执行 Python 脚本
在 BSD’ish Unix 系统上,Python 脚本可直接执行,像 shell 脚本一样,只需要把下面内容加入到#!/usr/bin/env python3.5(假设 python 解释器在用户的 PATH 中)脚本的开头,并给予该文件的可执行模式。#! 必须是文件的头两个字符。在一些系统上,第一行必须以 Unix-style 的行结束符('\n')结束,不能以 Windows 的行结束符('\r\n')。 注意 '#' 在 Python 中是用于注释的。使用 chmod 命令能够给予脚本执行模式或者权限。
$ chmod +x myscript.py在 Windows 系统上,没有一个 “可执行模式” 的概念。Python 安装器会自动地把 .py 文件和 python.exe 关联起来,因此双击 Python 将会把它当成一个脚本运行。文件扩展名也可以是 .pyw,在这种情况下,运行时不会出现控制台窗口。
③交互式启动文件
当你使用交互式 Python 的时候,它常常很方便地执行一些命令在每次解释器启动时。你可以这样做:设置一个名为 PYTHONSTARTUP 的环境变量为包含你的启动命令的文件名。这跟 Unix shells 的 .profile 特点有些类似。这个文件在交互式会话中是只读的,在当 Python 从脚本中读取命令,以及在当 /dev/tty 被作为明确的命令源的时候不只是可读的。该文件在交互式命令被执行的时候在相同的命名空间中能够被执行,因此在交互式会话中定义或者导入的对象能够无需授权就能使用。你也能在文件中更改提示 sys.ps1 和 sys.ps2。如果你想要从当前目录中读取一个附加的启动文件,你可以在全局启动文件中编写代码像这样:if os.path.isfile('.pythonrc.py'): exec(open('.pythonrc.py').read())。如果你想要在脚本中使用启动文件的话,你必须在脚本中明确要这么做:
import os
filename = os.environ.get('PYTHONSTARTUP')
if filename and os.path.isfile(filename):
with open(filename) as fobj:
startup_file = fobj.read()
exec(startup_file)
定制模块
Python 提供两个钩子为了让你们定制 sitecustomize 和 usercustomize。为了看看它的工作机制的话,你必须首先找到你的用户 site-packages 目录的位置。
启动 Python 并且运行这段代码:
>>> import site >>> site.getusersitepackages() '/home/user/.local/lib/python3.4/site-packages'
现在你可以创建一个名为 usercustomize.py 的文件在你的用户 site-packages 目录,并且在里面放置你想要的任何内容。它会影响 Python 的每一次调用,
除非它以 -s (禁用自动导入)选项启动。sitecustomize 以同样地方式工作,但是通常由是机器的管理员创建在全局的 site-packages 目录中,并且是在 usercustomize 之前导入。请参阅 site 模块获取更多信息。
4、Python 标准库概览
操作系统接口
os 模块提供了很多与操作系统交互的函数,我们先看几个,然后help(os),等到哪天需要使用os开发再去深入研究方法的作用。os.getcwd() 查看当前工作路径:
>>> import os >>> os.getcwd() 'E:\\Python'
针对日常的文件和目录管理任务,shutil 模块,需要import shutil
help(os)查看下

文件通配符
glob 模块提供了一个函数用于从目录通配符搜索中生成文件列表:
>>> import glob
>>> glob.glob('*.py')
['primes.py', 'random.py', 'quote.py']
命令行参数
通用工具脚本经常调用命令行参数。这些命令行参数以链表形式存储于 sys 模块的 argv 变量。例如在命令行中执行 python demo.py one two three 后可以得到以下输出结果:
>>> import sys >>> print(sys.argv) ['demo.py', 'one', 'two', 'three']
错误输出重定向和程序终止
sys 还有 stdin, stdout 和 stderr 属性,即使在 stdout 被重定向时,后者也可以用于显示警告和错误信息:
>>> sys.stderr.write('Warning, log file not found starting a new one\n')
Warning, log file not found starting a new one
大多脚本的定向终止都使用 sys.exit()。
字符串正则匹配
re 模块为高级字符串处理提供了正则表达式工具。对于复杂的匹配和处理,正则表达式提供了简洁、优化的解决方案:
>>> import re >>> re.findall(r'\bf[a-z]*', 'which foot or hand fell fastest') ['foot', 'fell', 'fastest'] >>> re.sub(r'(\b[a-z]+) \1', r'\1', 'cat in the the hat') 'cat in the hat'
只需简单的操作时,字符串方法最好用,因为它们易读,又容易调试:
>>> 'tea for too'.replace('too', 'two')
'tea for two'
数学
math 模块为浮点运算提供了对底层C函数库的访问:
>>> import math >>> math.cos(math.pi / 4.0) 0.70710678118654757 >>> math.log(1024, 2) 10.0
random 提供了生成随机数的工具:
>>> import random >>> random.choice(['apple', 'pear', 'banana']) 'apple' >>> random.sample(range(100), 10) # sampling without replacement [30, 83, 16, 4, 8, 81, 41, 50, 18, 33] >>> random.random() # random float 0.17970987693706186 >>> random.randrange(6) # random integer chosen from range(6) 4
SciPy <http://scipy.org> 项目提供了许多数值计算的模块。
互联网访问
有几个模块用于访问互联网以及处理网络通信协议。其中最简单的两个是用于处理从 urls 接收的数据的 urllib.request 以及用于发送电子邮件的 smtplib:
>>> from urllib.request import urlopen
>>> for line in urlopen('http://tycho.usno.navy.mil/cgi-bin/timer.pl'):
... line = line.decode('utf-8') # Decoding the binary data to text.
... if 'EST' in line or 'EDT' in line: # look for Eastern Time
... print(line)
<BR>Nov. 25, 09:43:32 PM EST
>>> import smtplib
>>> server = smtplib.SMTP('localhost')
>>> server.sendmail('soothsayer@example.org', 'jcaesar@example.org',
... """To: jcaesar@example.org
... From: soothsayer@example.org
...
... Beware the Ides of March.
日期和时间
datetime 支持日期和时间算法的同时,实现的重点放在更有效的处理和格式化输出。该模块还支持时区处理。
>>> # dates are easily constructed and formatted
>>> from datetime import date
>>> now = date.today()
>>> now
datetime.date(2003, 12, 2)
>>> now.strftime("%m-%d-%y. %d %b %Y is a %A on the %d day of %B.")
'12-02-03. 02 Dec 2003 is a Tuesday on the 02 day of December.'
>>> # dates support calendar arithmetic
>>> birthday = date(1964, 7, 31)
>>> age = now - birthday
>>> age.days
14368
数据压缩
以下模块直接支持通用的数据打包和压缩格式:zlib, gzip, bz2, lzma, zipfile 以及 tarfile。
>>> import zlib >>> s = b'witch which has which witches wrist watch' >>> len(s) 41 >>> t = zlib.compress(s) >>> len(t) 37 >>> zlib.decompress(t) b'witch which has which witches wrist watch' >>> zlib.crc32(s) 226805979
性能度量
解决同一问题的不同方法之间的性能差异。Python 提供了一个度量工具,为这些问题提供了直接答案。例如,使用元组封装和拆封来交换元素看起来要比使用传统的方法要诱人的多。timeit 证明了后者更快一些:
>>> from timeit import Timer
>>> Timer('t=a; a=b; b=t', 'a=1; b=2').timeit()
0.056634688316198646
>>> Timer('a,b = b,a', 'a=1; b=2').timeit()
0.029404588209626326
相对于 timeit 的细粒度,profile 和 pstats 模块提供了针对更大代码块的时间度量工具。
瑞士军刀
Python 展现了“瑞士军刀”的哲学。这可以通过它更大的包的高级和健壮的功能来得到最好的展现。列如:
①xmlrpc.client 和 xmlrpc.server 模块让远程过程调用变得轻而易举。尽管模块有这样的名字,用户无需拥有 XML 的知识或处理 XML。
②email 包是一个管理邮件信息的库,包括MIME和其它基于 RFC2822 的信息文档。
不同于实际发送和接收信息的 smtplib 和 poplib 模块,email 包包含一个构造或解析复杂消息结构(包括附件)及实现互联网编码和头协议的完整工具集。
③xml.dom 和 xml.sax 包为流行的信息交换格式提供了强大的支持。同样, csv 模块支持在通用数据库格式中直接读写。综合起来,这些模块和包大大简化了 Python 应用程序和其它工具之间的数据交换。
④国际化由 gettext, locale 和 codecs 包支持。
线程
线程是一个分离无顺序依赖关系任务的技术。在某些任务运行于后台的时候应用程序会变得迟缓,线程可以提升其速度。一个有关的用途是在 I/O 的同时其它线程可以并行计算。下面的代码显示了高级模块 threading 如何在主程序运行的同时运行任务:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
__title__ = ''
__author__ = 'cuitbnc'
__mtime__ = '2016/10/9'
# 欢迎进入我的主页:http://www.cnblogs.com/baiboy/.
"""
import threading, zipfile
class AsyncZip(threading.Thread):
def __init__(self, infile, outfile):
threading.Thread.__init__(self)
self.infile = infile
self.outfile = outfile
def run(self):
f = zipfile.ZipFile(self.outfile, 'w', zipfile.ZIP_DEFLATED)
f.write(self.infile)
f.close()
print('Finished background zip of:', self.infile)
background = AsyncZip(r'C:\Users\cuitbnc\Desktop\testfile.txt', 'myarchive.zip')
background.start()
print('The main program continues to run in foreground.')
background.join() # Wait for the background task to finish
print('Main program waited until background was done.')
运行结果:

6、参考文献和推荐资料
- Python 官方网站 :包含代码、文档和 Web 上与 Python 有关的页面链接该网站镜像于全世界的几处其它问题,类似欧洲、日本和澳大利亚。镜像可能会比主站快,这取决于你的地理位置
- 快速访问 Python 的文档
- Python 包索引 :索引了可供下载的,用户创建的 Python 模块。如果你发布了代码,可以注册到这里,这样别人可以找到它
- The Scientific Python : 项目包括数组快速计算和处理模块,和大量线性代数、傅里叶变换、非线性solvers、随机数分布,统计分析以及类似的包
- 官方python学习文档
- 简明Python教程
- 廖雪峰:python教程
- Python官网文档
- 【51cto学院,入门课程】Python零基础入门学习视频教程
- 【个人博客:案例】GitHub数据提取与分析
- 【csdn】python知识库
- 【社区】python中文学习大本营
- 【个人博客】老王python
-
【51cto学院】如何用python开发跨平台的记事本视频课程
-
【51cto学院,网站开发】台湾辅仁大学:Python Django基础视频课程
-
【51cto学院,网站开发】用Python Django快速做出高大上的BBS论坛网站
作者:白宁超,工学硕士,现工作于四川省计算机研究院,研究方向是自然语言处理和机器学习。曾参与国家自然基金项目和四川省科技支撑计划等多个省级项目。著有《自然语言处理理论与实战》一书。 自然语言处理与机器学习技术交流群号:436303759 。
出处:http://www.cnblogs.com/baiboy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号