【NLP】蓦然回首:谈谈学习模型的评估系列文章(二)
基于Data Mining角度的模型评估与选择
作者:白宁超
2016年7月19日10:24:24
摘要:写本文的初衷源于基于HMM模型序列标注的一个实验,实验完成之后,迫切想知道采用的序列标注模型的好坏,有哪些指标可以度量。于是,就产生了对这一专题进度学习总结,这样也便于其他人参考,节约大家的时间。本文依旧旨在简明扼要梳理出模型评估核心指标,重点达到实用。本文布局如下:第一章采用统计学习角度介绍什么是学习模型以及如何选择,因为现今的自然语言处理方面大都采用概率统计完成的,事实证明这也比规则的方法好。第二章采用基于数据挖掘的角度探讨模型评估指标和选择。第三章采用统计自然语言处理的方法看看模型评价方法。第四章以R语言为实例,进行实战操作,更深入了解模型的相关问题。(本文原创,转载请注明出处:基于Data Mining角度的模型评估与选择。)
目录
【自然语言处理:谈谈学习模型的评估(一)】:统计角度窥视模型概念
【自然语言处理:谈谈学习模型的评估(二)】:基于Data Mining角度的模型评估与选择
【自然语言处理:谈谈学习模型的评估(三)】:基于NLP角度的模型评价方法
【自然语言处理:谈谈学习模型的评估(四)】:基于R语言的模型案例实战
1 模型评估的概念介绍?
评估准确率的常用技术:保持和随机子抽样、K-折交叉验证、自助方法
统计显著性检验:评估模型准确率
ROC曲线:接收者操作特征曲线比较分类器效果好坏
2 评估分类器模型性能的度量
混淆矩阵:正元组和负元组的合计
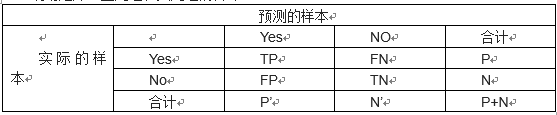
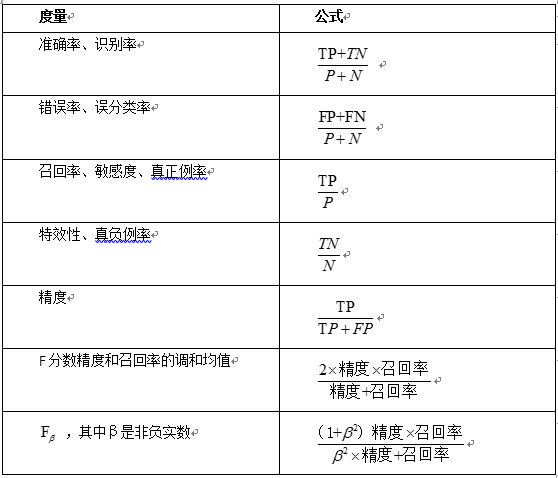
评估度量:(其中P:正样本数 N:负样本数 TP:真正例 TN:真负例 FP:假正例 FN:假负例)
注意:学习器的准确率最好在检验集上估计,检验集的由训练集模型时未使用的含有标记的元组组成数据。
各参数描述如下:
TP(真正例/真阳性):是指被学习器正确学习的正元组,令TP为真正例的个数。
TN(真负例/真阴性):是指被学习器正确学习的负元组,令TN为真负例的个数。
FP(假正例/假阳性):是被错误的标记为正元组的负元组。令FP为假正例的个数。
FN(假负例/假阴性):是被错误的标记为负元组的正元组。令FN为假负例的个数。
高准确率的学习模型:大部分元组应该在混合矩阵的对角线上,而其他为0或者接近0,即FP和FN为0.其本质上是一个对角矩阵时准确率最高。
准确率:正确识别的元组所占的比例。又叫做识别率,公式如下:
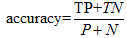
3 实例分析:词性标注为例

错误率:错误识别元组所占的比例,又叫误识别率,公式如下:
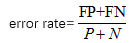 或者1-accuracy(M)
或者1-accuracy(M)
检验时,应采用检验集未加入训练集的数据,当采用训练集估计模型时,为再带入误差,这种称为乐观估计。准确率可以度量正确标注的百分比,但是不能正确度量错误率。诸如样本不平衡时,即负样本是稀疏却是感兴趣的。比如:欺诈、癌症等。这种情况下应使用灵敏性特效性度量。
灵敏度又叫真正识别率:正确识别的正元组的百分比,公式如下:
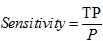
特效性又叫真负例率:正确识别的正元组的百分比,公式如下:
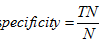
准确率的灵敏度和特效性的函数关系:
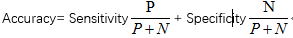
精度:精确性的度量即标记为正元组实际为正元组的百分比,公式如下:
、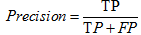
召回率:完全性的度量即正元组标记为正的百分比,公式如下:
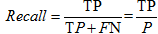
精度和召回率之间趋向于逆关系,有可能以降低一个指标提升另一个指标。此刻两个指标预想达到综合引出了F度量值
F度量(又叫F分数):用精度和召回率的方法把他们组合到一个度量中。公式如下:


比较:F度量是精度和召回率的调和均值,赋予精度和召回率相等的权重, 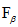 度量是精度和召回率加权度量,它赋予召回率权重是精度的β倍,诸如中文词汇中,常用词的权重比生僻词的权重大是一样的道理,也符合实际应用。
度量是精度和召回率加权度量,它赋予召回率权重是精度的β倍,诸如中文词汇中,常用词的权重比生僻词的权重大是一样的道理,也符合实际应用。
注意:当元组属于多个类时,不适合使用准确率。当数据均衡分布即正负元组基本相当时,准确率效果最好,而召回率、特效性、精度、F和 更适合于样本分布不均的情况。
4 模型评估的几种方法介绍
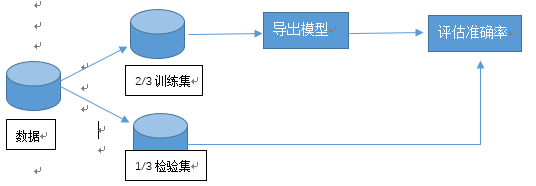
1)随机二次抽样评估准确率:是保持方法的一种变形,将保持方法重复K次,总准确率估计是每次迭代准确率的平均值
2)K-折交叉验证评估准确率:(建议10折)
K-折交叉验证:将初始的数据随机分为大小大致相同的K份,训练和检验进行K次,如第1次迭代第一份数据作为检查集,其余K-1份作为训练集,第2次迭代。第二份数据作为检验集,其余K-1份作为训练集,以此类推直到第K份数据作为检验集为止。此方法每份样本用于训练的次数一致且每份样本只作为一次检验集。准确率是K次迭代正确元组总数除以初始数据元组总数。一般建议采用10-折交叉验证估计准确率,因为它的偏移和方差较低。
3)自助法评估准确率:
自助法有放回的均匀抽样,常用632自助法。即63.2%原数据将出现在自助样本中。而其余38.8%元数据形成检验集。
5 学习器模型的比较:ROC曲线
成本效益(风险增益):如错误的预测癌症患者没有患病比将没有患病的病人归类癌症的代价大等等事件,据此给于不同的权重。
ROC曲线又叫接受者操作特征曲线,比较两个学习器模型的可视化工具,横坐标参数假正例率,纵坐标参数是真正例率。以此汇聚成的曲线,越靠近对角线(随机猜测线)模型越不好。
真正例率(召回率):
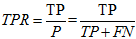
假正例率:
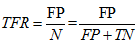
实例解析:以10个检验元组的概率分类器为例绘制ROC曲线
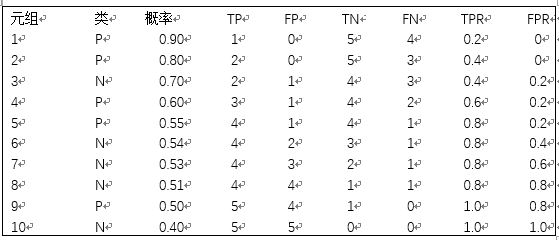
由以上数据绘制ROC曲线(左图)和两个分类器模型M1、M2的ROC曲线
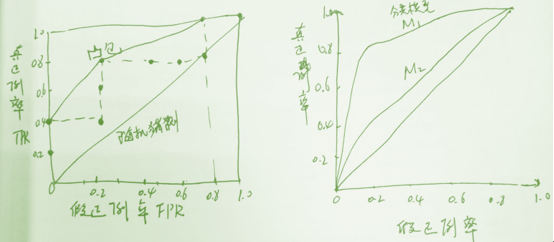
由此可知,对角线为随机猜测线,模型的ROC曲线越靠近对角线,模型的准确率越低。如果很好的模型,真正比例比较多,曲线应是陡峭的从0开始上升,后来遇到真正比例越来越少,假正比例元组越来越多,曲线平缓变的更加水平。完全正确的模型面积为1。
4 参考文献
【1】 数据挖掘概念与技术(364--386) 韩家炜
【2】 数据挖掘:R语言实战(274--292) 黄文、王正林
【3】 统计自然语言处理基础 (166—169) 宛春法等译
【4】 统计学习方法(10---13) 李航
5 自然语言相关系列文章
【自然语言处理:马尔可夫模型(一)】:初识马尔可夫和马尔可夫链
【自然语言处理:马尔可夫模型(二)】:马尔可夫模型与隐马尔可夫模型
【自然语言处理:马尔可夫模型(三)】:向前算法解决隐马尔可夫模型似然度问题
【自然语言处理:马尔可夫模型(四)】:维特比算法解决隐马尔可夫模型解码问题(中文句法标注)
【自然语言处理:马尔可夫模型(五)】:向前向后算法解决隐马尔可夫模型机器学习问题
声明:关于此文各个篇章,本人采取梳理扼要,顺畅通明的写作手法。系统阅读相关书目和资料总结梳理而成,旨在技术分享,知识沉淀。在此感谢原著无私的将其汇聚成书,才得以引荐学习之用。其次,本人水平有限,权作知识理解积累之用,难免主观理解不当,造成读者不便,基于此类情况,望读者留言反馈,便于及时更正。本文原创,转载请注明出处:基于Data Mining角度的模型评估与选择。
作者:白宁超,工学硕士,现工作于四川省计算机研究院,研究方向是自然语言处理和机器学习。曾参与国家自然基金项目和四川省科技支撑计划等多个省级项目。著有《自然语言处理理论与实战》一书。 自然语言处理与机器学习技术交流群号:436303759 。
出处:http://www.cnblogs.com/baiboy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

