【结巴分词资料汇编】结巴中文分词基本操作(3)
结巴中文分词基本操作(3)
作者:白宁超
2016年11月23日16:49:36
摘要:结巴中文分词的特点如下:支持三种分词模式:(精确模式,试图将句子最精确地切开,适合文本分析;全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。)、支持繁体分词、支持自定义词典、MIT 授权协议。本文系列文章一是对官方文档的介绍,文章二是引用收集网友对结巴分词源码的分析,文章三是对基本操作代码示例演示。(本文原创汇编而成,转载请标明出处:【结巴分词资料汇编】结巴中文分词基本操作(3)
目录:
1 结巴中文分词:几种不同模式的分词设置
安装结巴分词:
- 全自动安装:
easy_install jieba或者pip install jieba/pip3 install jieba - 半自动安装:先下载 http://pypi.python.org/pypi/jieba/ ,解压后运行
python setup.py install - 手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
- 通过
import jieba来引用
本机是win10 64位,已经安装了pip工具,关于pip下载安装(here),然后win+R,输入pip install jieba,效果如下:
结巴几种模式下的分词操作:(以下默认已导入:import jieba)
- 全模式分词:
>>> import jieba
>>> str="我是白宁超来自博客园"
>>> seg_list=jieba.cut(str,cut_all=True)
>>> print("Full Mode: " + "/ ".join(seg_list)) # 全模式
Full Mode: 我/ 是/ 白/ 宁/ 超/ 来自/ 博客/ 博客园
结果分析:显然我的名字:白宁超,没有正确分词,这是因为全模式把句子中所有可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义。
- 精确模式分词
>>> seg_list=jieba.cut(str,cut_all=False)
>>> print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
Default Mode: 我/ 是/ 白宁超/ 来自/ 博客园
>>> seg_list=jieba.cut(str)
>>> print("Default Mode: " + "/ ".join(seg_list)) # 默认模式
Default Mode: 我/ 是/ 白宁超/ 来自/ 博客园
结果分析:首先默认模式就是精确模式,即cut_all=False。这里很好的将“白宁超”划分为一个词。与全模式分词是有区别的。精确模式适合文本分析。
- 默认精确模式分词
>>> seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
>>> print("【新词发现】\t"+", ".join(seg_list))
【新词发现】 他, 来到, 了, 网易, 杭研, 大厦
结果分析:
此处杭研并没有在词典中,但是也被Viterbi算法识别出来了。实际上是基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法可以发现新词。也可以在自定义字典去收集新词。
- 搜索引擎模式分词
>>> seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
>>> print("搜索引擎模式:\t"+", ".join(seg_list))
搜索引擎模式: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, ,, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
结果分析:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- 繁体分词
>>> str='''此開卷第一回也.作者自云:因曾歷過一番夢幻之后,故將真事隱去,
而借"通靈"之說,撰此《石頭記》一書也.故曰"甄士隱"云云.但書中所記
何事何人?自又云:“今風塵碌碌,一事無成,忽念及當日所有之女子,一
一細考較去,覺其行止見識,皆出于我之上.何我堂堂須眉,誠不若彼裙釵
哉?實愧則有余,悔又無益之大無可如何之日也!'''
>>> str=jieba.cut(str)
>>> print('/ '.join(str))
此開卷/ 第一回/ 也/ ./ 作者/ 自云/ :/ 因曾/ 歷過/ 一番/ 夢/ 幻之后/ ,/ 故將/ 真事/ 隱去/ ,/
/ 而/ 借/ "/ 通靈/ "/ 之/ 說/ ,/ 撰此/ 《/ 石頭記/ 》/ 一書/ 也/ ./ 故/ 曰/ "/ 甄士/ 隱/ "/ 云云/ ./ 但書中/ 所記/
/ 何事何/ 人/ ?/ 自又云/ :/ “/ 今風/ 塵碌碌/ ,/ 一事/ 無成/ ,/ 忽念及/ 當日/ 所/ 有/ 之/ 女子/ ,/ 一/
/ 一細/ 考較/ 去/ ,/ 覺其/ 行止/ 見識/ ,/ 皆/ 出于/ 我/ 之/ 上/ ./ 何/ 我堂/ 堂須/ 眉/ ,/ 誠不若/ 彼/ 裙釵/
/ 哉/ ?/ 實愧則/ 有/ 余/ ,/ 悔/ 又/ 無益/ 之/ 大/ 無/ 可/ 如何/ 之/ 日/ 也/ !
>>>
- jieba.lcut全模式、精准模式、搜索引擎模式
>>> seg_list=jieba.lcut(str,cut_all=True,HMM=True)
>>> type(seg_list)
<class 'list'>
>>> seg_list
['我', '是', '白', '宁', '超', '来自', '博客', '博客园']
>>> print("Full Mode: " + "/ ".join(seg_list)) # 全模式隐马
Full Mode: 我/ 是/ 白/ 宁/ 超/ 来自/ 博客/ 博客园
>>> type("/ ".join(seg_list))
<class 'str'>
结果分析:显然调用jieba.lcut返回list类型,"/ ".join(seg_list)是将list转化为string类型
- 自定义分词器
#encoding=utf-8
from __future__ import print_function, unicode_literals
import sys
sys.path.append("../")
import jieba
jieba.load_userdict("userdict.txt")
import jieba.posseg as pseg
jieba.add_word('凱特琳')
jieba.del_word('自定义词')
test_sent = (
"李小福和李铁军是创新办主任也是云计算方面的专家; 什么是八一双鹿\n"
"例如我输入一个带“韩玉赏鉴”的标题,在自定义词库中也增加了此词为N类\n"
"「台中」正確應該不會被切開。mac上可分出「石墨烯」;此時又可以分出來凱特琳了。"
)
words = jieba.cut(test_sent)
print('/'.join(words))
print("="*40)
result = pseg.cut(test_sent)
for w in result:
print(w.word, "/", w.flag, ", ", end=' ')
print("\n" + "="*40)
terms = jieba.cut('easy_install is great')
print('/'.join(terms))
terms = jieba.cut('python 的正则表达式是好用的')
print('/'.join(terms))
print("="*40)
# test frequency tune
testlist = [
('今天天气不错', ('今天', '天气')),
('如果放到post中将出错。', ('中', '将')),
('我们中出了一个叛徒', ('中', '出')),
]
for sent, seg in testlist:
print('/'.join(jieba.cut(sent, HMM=False)))
word = ''.join(seg)
print('%s Before: %s, After: %s' % (word, jieba.get_FREQ(word), jieba.suggest_freq(seg, True)))
print('/'.join(jieba.cut(sent, HMM=False)))
print("-"*40)
运行结果:
==== RESTART: C:\Users\cuitbnc\Desktop\jieba-master\test\test_userdict.py ====
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\cuitbnc\AppData\Local\Temp\jieba.cache
Loading model cost 1.098 seconds.
Prefix dict has been built succesfully.
李小福/和/李铁/军是/创新办/主任/也/是/云计算/方面/的/专家/;/ /什么/是/八一双鹿/
/例如/我/输入/一个/带/“/韩玉赏鉴/”/的/标题/,/在/自定义词/库中/也/增加/了/此/词为/N/类/
/「/台中/」/正確/應該/不會/被/切開/。/mac/上/可/分出/「/石墨/烯/」/;/此時/又/可以/分出/來/凱特琳/了/。
========================================
李小福 / nr , 和 / c , 李铁 / nr , 军 / n , 是 / v , 创新办 / i , 主任 / b , 也 / d , 是 / v , 云计算 / x , 方面 / n , 的 / uj , 专家 / n , ; / x , / x , 什么 / r , 是 / v , 八一双鹿 / nz ,
/ x , 例如 / v , 我 / r , 输入 / v , 一个 / m , 带 / v , “ / x , 韩玉赏鉴 / nz , ” / x , 的 / uj , 标题 / n , , / x , 在 / p , 自定义词 / n , 库中 / nrt , 也 / d , 增加 / v , 了 / ul , 此 / r , 词 / n , 为 / p , N / eng , 类 / q ,
/ x , 「 / x , 台中 / s , 」 / x , 正確 / ad , 應該 / v , 不 / d , 會 / v , 被 / p , 切開 / ad , 。 / x , mac / eng , 上 / f , 可 / v , 分出 / v , 「 / x , 石墨 / n , 烯 / x , 」 / x , ; / x , 此時 / c , 又 / d , 可以 / c , 分出 / v , 來 / zg , 凱特琳 / x , 了 / ul , 。 / x ,
========================================
easy_install/ /is/ /great
python/ /的/正则表达式/是/好用/的
========================================
今天天气/不错
今天天气 Before: 3, After: 0
今天天气/不错
----------------------------------------
如果/放到/post/中将/出错/。
中将 Before: 763, After: 494
如果/放到/post/中/将/出错/。
----------------------------------------
我们/中/出/了/一个/叛徒
中出 Before: 3, After: 3
我们/中/出/了/一个/叛徒
----------------------------------------
>>>
结果分析:
1 首先对一段话分词处理:
test_sent = (
"李小福和李铁军是创新办主任也是云计算方面的专家; 什么是八一双鹿\n"
"例如我输入一个带“韩玉赏鉴”的标题,在自定义词库中也增加了此词为N类\n"
"「台中」正確應該不會被切開。mac上可分出「石墨烯」;此時又可以分出來凱特琳了。"
)
words = jieba.cut(test_sent)
print('/'.join(words))
李小福/和/李铁/军是/创新办/主任/也/是/云计算/方面/的/专家/;/ /什么/是/八一双鹿/
/例如/我/输入/一个/带/“/韩玉赏鉴/”/的/标题/,/在/自定义词/库中/也/增加/了/此/词为/N/类/
/「/台中/」/正確/應該/不會/被/切開/。/mac/上/可/分出/「/石墨/烯/」/;/此時/又/可以/分出/來/凱特琳/了/。
此处“李小福“和“李铁军”都是人名,结果却分词“李小福”和“李铁”,而“军是”当做一个词处理,显然不对。我们可以将“李铁军”当着一个词加入自定义文本中:
import sys
sys.path.append("../")
import jieba
jieba.load_userdict("userdict.txt")
jieba.add_word('李铁军')
test_sent = (
"李小福和李铁军是创新办主任也是云计算方面的专家; 什么是八一双鹿\n"
"例如我输入一个带“韩玉赏鉴”的标题,在自定义词库中也增加了此词为N类\n"
"「台中」正確應該不會被切開。mac上可分出「石墨烯」;此時又可以分出來凱特琳了。"
)
words = jieba.cut(test_sent)
print('/'.join(words))
李小福/和/李铁军/是/创新办/主任/也/是/云计算/方面/的/专家/;/ /什么/是/八一双鹿/
/例如/我/输入/一个/带/“/韩玉赏鉴/”/的/标题/,/在/自定义词/库中/也/增加/了/此/词为/N/类/
/「/台中/」/正確/應該/不會/被/切開/。/mac/上/可/分出/「/石墨/烯/」/;/此時/又/可以/分出/來/凱特琳/了/。
结果显然经过自定义分词有所好转。而石墨/烯分词错误
李小福/和/李铁军/是/创新办/主任/也/是/云计算/方面/的/专家/;/ /什么/是/八一双鹿/
/例如/我/输入/一个/带/“/韩玉赏鉴/”/的/标题/,/在/自定义词/库中/也/增加/了/此/词为/N/类/
/「/台中/」/正確/應該/不會/被/切開/。/mac/上/可/分出/「/石墨烯/」/;/此時/又/可以/分出/來/凱特琳/了/。
- 词性标注:
print("="*40)
result = pseg.cut(test_sent)
for w in result:
print(w.word, "/", w.flag, ", ", end=' ')
print("\n" + "="*40)
terms = jieba.cut('easy_install is great')
print('/'.join(terms))
terms = jieba.cut('python 的正则表达式是好用的')
print('/'.join(terms))
print("="*40)
========================================
李小福 / nr , 和 / c , 李铁军 / x , 是 / v , 创新办 / i , 主任 / b , 也 / d , 是 / v , 云计算 / x , 方面 / n , 的 / uj , 专家 / n , ; / x , / x , 什么 / r , 是 / v , 八一双鹿 / nz ,
/ x , 例如 / v , 我 / r , 输入 / v , 一个 / m , 带 / v , “ / x , 韩玉赏鉴 / nz , ” / x , 的 / uj , 标题 / n , , / x , 在 / p , 自定义词 / n , 库中 / nrt , 也 / d , 增加 / v , 了 / ul , 此 / r , 词 / n , 为 / p , N / eng , 类 / q ,
/ x , 「 / x , 台中 / s , 」 / x , 正確 / ad , 應該 / v , 不 / d , 會 / v , 被 / p , 切開 / ad , 。 / x , mac / eng , 上 / f , 可 / v , 分出 / v , 「 / x , 石墨烯 / x , 」 / x , ; / x , 此時 / c , 又 / d , 可以 / c , 分出 / v , 來 / zg , 凱特琳 / x , 了 / ul , 。 / x ,
========================================
easy_install/ /is/ /great
python/ /的/正则表达式/是/好用/的
========================================
结果分析:李小福 / nr , 李铁军 / x 都是名字,属于名词,而李铁军 / x显然词性不对,这是由于刚刚jieba.add_word('李铁军')时候,没有进行词性参数输入,我们看看jieba.add_word('李铁军')源码:
def add_word(self, word, freq=None, tag=None)
jieba.add_word('李铁军',tag='nr')修改后结果:
========================================
李小福 / nr , 和 / c , 李铁军 / nr , 是 / v , 创新办 / i , 主任 / b , 也 / d , 是 / v , 云计算 / x , 方面 / n , 的 / uj , 专家 / n , ; / x , / x , 什么 / r , 是 / v , 八一双鹿 / nz ,
/ x , 例如 / v , 我 / r , 输入 / v , 一个 / m , 带 / v , “ / x , 韩玉赏鉴 / nz , ” / x , 的 / uj , 标题 / n , , / x , 在 / p , 自定义词 / n , 库中 / nrt , 也 / d , 增加 / v , 了 / ul , 此 / r , 词 / n , 为 / p , N / eng , 类 / q ,
/ x , 「 / x , 台中 / s , 」 / x , 正確 / ad , 應該 / v , 不 / d , 會 / v , 被 / p , 切開 / ad , 。 / x , mac / eng , 上 / f , 可 / v , 分出 / v , 「 / x , 石墨烯 / x , 」 / x , ; / x , 此時 / c , 又 / d , 可以 / c , 分出 / v , 來 / zg , 凱特琳 / x , 了 / ul , 。 / x ,
========================================
- 自定义调整词典
# test frequency tune
testlist = [
('今天天气不错', ('今天', '天气')),
('如果放到post中将出错。', ('中', '将')),
('我们中出了一个叛徒', ('一', '个')),
]
for sent, seg in testlist:
print('/'.join(jieba.cut(sent, HMM=False)))
word = ''.join(seg)
print('%s Before: %s, After: %s' % (word, jieba.get_FREQ(word), jieba.suggest_freq(seg, True)))
print('/'.join(jieba.cut(sent, HMM=False)))
print("-"*40)
========================================
今天天气/不错
今天天气 Before: 3, After: 0
今天天气/不错
----------------------------------------
如果/放到/post/中将/出错/。
中将 Before: 763, After: 494
如果/放到/post/中/将/出错/。
----------------------------------------
我们/中/出/了/一个/叛徒
一个 Before: 142747, After: 454
我们/中/出/了/一/个/叛徒
----------------------------------------
结果分析:列表中的每一条数据如('今天天气不错', ('今天', '天气')),其中('今天', '天气')调整分词颗粒精度的。如第三句正常分词:我们/中/出/了/一个/叛徒。我们假设某些情况下一和个分别分词,可以做如上处理。
- 使用
add_word(word, freq=None, tag=None)和del_word(word)可在程序中动态修改词典。 -
使用
suggest_freq(segment, tune=True)可调节单个词语的词频,使其能(或不能)被分出来。 -
注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
- 自定义调节词典解决歧义分词问题:
>>> import jieba
>>> print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\cuitbnc\AppData\Local\Temp\jieba.cache
Loading model cost 1.069 seconds.
Prefix dict has been built succesfully.
如果/放到/post/中将/出错/。
>>> jieba.suggest_freq(('中', '将'), True)
494
>>> print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
如果/放到/post/中/将/出错/。
>>> print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
「/台/中/」/正确/应该/不会/被/切开
>>> jieba.suggest_freq('台中', True)
69
>>> print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
「/台中/」/正确/应该/不会/被/切开
>>>
总结:jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型。jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode)。
2 关键词提取
import jieba.analyse
- jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本
- topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight 为是否一并返回关键词权重值,默认值为 False
- allowPOS 仅包括指定词性的词,默认值为空,即不筛选
- jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
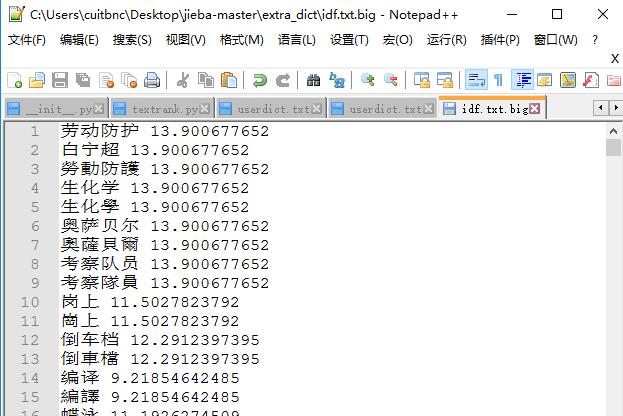
关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
- 用法: jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
- 自定义语料库示例:https://github.com/fxsjy/jieba/blob/master/extra_dict/idf.txt.big
import sys
sys.path.append('../')
import jieba
import jieba.analyse
from optparse import OptionParser
USAGE = "usage: 白宁超 python extract_tags_idfpath.py [file name] -k [top k]"
parser = OptionParser(USAGE)
parser.add_option("-k", dest="topK")
opt, args = parser.parse_args()
if len(args) < 1:
print(USAGE)
sys.exit(1)
file_name = args[0]
if opt.topK is None:
topK = 10
else:
topK = int(opt.topK)
content = open(file_name, 'rb').read()
jieba.analyse.set_idf_path("../extra_dict/idf.txt.big");
tags = jieba.analyse.extract_tags(content, topK=topK)
print(",".join(tags))
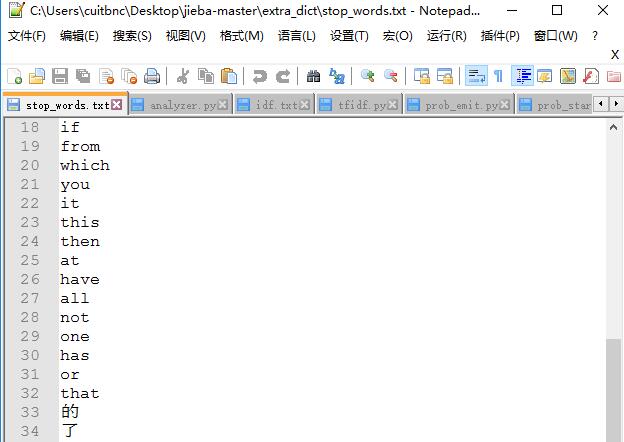
关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径
- 用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
- 自定义语料库示例:https://github.com/fxsjy/jieba/blob/master/extra_dict/stop_words.txt
import sys
sys.path.append('../')
import jieba
import jieba.analyse
from optparse import OptionParser
USAGE = "usage: python extract_tags_stop_words.py [file name] -k [top k]"
parser = OptionParser(USAGE)
parser.add_option("-k", dest="topK")
opt, args = parser.parse_args()
if len(args) < 1:
print(USAGE)
sys.exit(1)
file_name = args[0]
if opt.topK is None:
topK = 10
else:
topK = int(opt.topK)
content = open(file_name, 'rb').read()
jieba.analyse.set_stop_words("../extra_dict/stop_words.txt")
jieba.analyse.set_idf_path("../extra_dict/idf.txt.big");
tags = jieba.analyse.extract_tags(content, topK=topK)
print(",".join(tags))
关键词一并返回关键词权重值示例
import sys
sys.path.append('../')
import jieba
import jieba.analyse
from optparse import OptionParser
USAGE = "usage: python extract_tags_with_weight.py [file name] -k [top k] -w [with weight=1 or 0]"
parser = OptionParser(USAGE)
parser.add_option("-k", dest="topK")
parser.add_option("-w", dest="withWeight")
opt, args = parser.parse_args()
if len(args) < 1:
print(USAGE)
sys.exit(1)
file_name = args[0]
if opt.topK is None:
topK = 10
else:
topK = int(opt.topK)
if opt.withWeight is None:
withWeight = False
else:
if int(opt.withWeight) is 1:
withWeight = True
else:
withWeight = False
content = open(file_name, 'rb').read()
tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=withWeight)
if withWeight is True:
for tag in tags:
print("tag: %s\t\t weight: %f" % (tag[0],tag[1]))
else:
print(",".join(tags))
基于 TextRank 算法的关键词抽取
- jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')) 直接使用,接口相同,注意默认过滤词性。
- jieba.analyse.TextRank() 新建自定义 TextRank 实例
算法论文: TextRank: Bringing Order into Texts
基本思想:
- 将待抽取关键词的文本进行分词
- 以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
- 计算图中节点的PageRank,注意是无向带权图
#encoding=utf-8
from __future__ import unicode_literals
import sys
sys.path.append("../")
import jieba
import jieba.posseg
import jieba.analyse
print('='*40)
print('1. 分词')
print('-'*40)
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 默认模式
seg_list = jieba.cut("他来到了网易杭研大厦")
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
print('='*40)
print('2. 添加自定义词典/调整词典')
print('-'*40)
print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
#如果/放到/post/中将/出错/。
print(jieba.suggest_freq(('中', '将'), True))
#494
print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
#如果/放到/post/中/将/出错/。
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
#「/台/中/」/正确/应该/不会/被/切开
print(jieba.suggest_freq('台中', True))
#69
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
#「/台中/」/正确/应该/不会/被/切开
print('='*40)
print('3. 关键词提取')
print('-'*40)
print(' TF-IDF')
print('-'*40)
s = "此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。"
for x, w in jieba.analyse.extract_tags(s, withWeight=True):
print('%s %s' % (x, w))
print('-'*40)
print(' TextRank')
print('-'*40)
for x, w in jieba.analyse.textrank(s, withWeight=True):
print('%s %s' % (x, w))
运行结果:
======== RESTART: C:\Users\cuitbnc\Desktop\jieba-master\test\demo.py ========
========================================
1. 分词
----------------------------------------
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\cuitbnc\AppData\Local\Temp\jieba.cache
Loading model cost 1.103 seconds.
Prefix dict has been built succesfully.
Full Mode: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
Default Mode: 我/ 来到/ 北京/ 清华大学
他, 来到, 了, 网易, 杭研, 大厦
小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, ,, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
========================================
2. 添加自定义词典/调整词典
----------------------------------------
如果/放到/post/中将/出错/。
494
如果/放到/post/中/将/出错/。
「/台/中/」/正确/应该/不会/被/切开
69
「/台中/」/正确/应该/不会/被/切开
========================================
3. 关键词提取
----------------------------------------
TF-IDF
----------------------------------------
欧亚 0.7300142700289363
吉林 0.659038184373617
置业 0.4887134522112766
万元 0.3392722481859574
增资 0.33582401985234045
2013 0.25435675538085106
7000 0.25435675538085106
4.3 0.25435675538085106
139.13 0.25435675538085106
实现 0.19900979900382978
综合体 0.19480309624702127
经营范围 0.19389757253595744
亿元 0.1914421623587234
在建 0.17541884768425534
全资 0.17180164988510638
注册资本 0.1712441526
百货 0.16734460041382979
零售 0.1475057117057447
子公司 0.14596045237787234
营业 0.13920178509021275
----------------------------------------
TextRank
----------------------------------------
吉林 1.0
欧亚 0.9966893354178173
置业 0.6434360313092778
实现 0.5898606692859627
收入 0.43677859947991465
增资 0.4099900531283276
子公司 0.356782959476728
城市 0.34971383667403666
商业 0.3481722071602695
业务 0.30922309926198394
在建 0.30779291640330886
营业 0.3035777049319589
全资 0.3035409810534751
综合体 0.2958086917239483
注册资本 0.29000519464085056
有限公司 0.28078307985765744
零售 0.27883620861218156
百货 0.2781657628445477
开发 0.26934887792958523
经营范围 0.26427621735583173
========================================
4. 词性标注
----------------------------------------
我 r
爱 v
北京 ns
天安门 ns
========================================
6. Tokenize: 返回词语在原文的起止位置
----------------------------------------
默认模式
----------------------------------------
word 永和 start: 0 end:2
word 服装 start: 2 end:4
word 饰品 start: 4 end:6
word 有限公司 start: 6 end:10
----------------------------------------
搜索模式
----------------------------------------
word 永和 start: 0 end:2
word 服装 start: 2 end:4
word 饰品 start: 4 end:6
word 有限 start: 6 end:8
word 公司 start: 8 end:10
word 有限公司 start: 6 end:10
>>>
结果分析:
以关键词抽取为例子:核心句(代码已标红): jieba.analyse.extract_tags(s, withWeight=True)我们看看源码如何实现的:
def extract_tags(self, sentence, topK=20, withWeight=False, allowPOS=(), withFlag=False):
"""
Extract keywords from sentence using TF-IDF algorithm.
Parameter:
- topK: return how many top keywords. `None` for all possible words.
- withWeight: if True, return a list of (word, weight);
if False, return a list of words.
- allowPOS: the allowed POS list eg. ['ns', 'n', 'vn', 'v','nr'].
if the POS of w is not in this list,it will be filtered.
- withFlag: only work with allowPOS is not empty.
if True, return a list of pair(word, weight) like posseg.cut
if False, return a list of words
"""
if allowPOS:
allowPOS = frozenset(allowPOS)
words = self.postokenizer.cut(sentence)
else:
words = self.tokenizer.cut(sentence)
freq = {}
for w in words:
if allowPOS:
if w.flag not in allowPOS:
continue
elif not withFlag:
w = w.word
wc = w.word if allowPOS and withFlag else w
if len(wc.strip()) < 2 or wc.lower() in self.stop_words:
continue
freq[w] = freq.get(w, 0.0) + 1.0
total = sum(freq.values())
for k in freq:
kw = k.word if allowPOS and withFlag else k
freq[k] *= self.idf_freq.get(kw, self.median_idf) / total
if withWeight:
tags = sorted(freq.items(), key=itemgetter(1), reverse=True)
else:
tags = sorted(freq, key=freq.__getitem__, reverse=True)
if topK:
return tags[:topK]
else:
return tags
关于词频抽取的源码也类型,不再展示
3. 词性标注
jieba.posseg.POSTokenizer(tokenizer=None)新建自定义分词器,tokenizer参数可指定内部使用的jieba.Tokenizer分词器。jieba.posseg.dt为默认词性标注分词器。- 标注句子分词后每个词的词性,采用和 ictclas 兼容的标记法。
- 用法示例
>>> import jieba.posseg as pseg
>>> words = pseg.cut("我爱北京天安门")
>>> for word, flag in words:
... print('%s %s' % (word, flag))
...
我 r
爱 v
北京 ns
天安门 ns
4. 并行分词
- 原理:将目标文本按行分隔后,把各行文本分配到多个 Python 进程并行分词,然后归并结果,从而获得分词速度的可观提升
- 基于 python 自带的 multiprocessing 模块,目前暂不支持 Windows
-
用法:
jieba.enable_parallel(4)# 开启并行分词模式,参数为并行进程数jieba.disable_parallel()# 关闭并行分词模式
-
例子:https://github.com/fxsjy/jieba/blob/master/test/parallel/test_file.py
import time
import sys
sys.path.append("../")
import jieba
jieba.initialize()
url = sys.argv[1]
content = open(url,"rb").read()
t1 = time.time()
words = "/ ".join(jieba.cut(content))
t2 = time.time()
tm_cost = t2-t1
log_f = open("1.log","wb")
log_f.write(words.encode('utf-8'))
log_f.close()
print('cost ' + str(tm_cost))
print('speed %s bytes/second' % (len(content)/tm_cost))
-
实验结果:在 4 核 3.4GHz Linux 机器上,对金庸全集进行精确分词,获得了 1MB/s 的速度,是单进程版的 3.3 倍。
-
注意:并行分词仅支持默认分词器
jieba.dt和jieba.posseg.dt。
5. Tokenize:返回词语在原文的起止位置
- 注意,输入参数只接受 unicode
- 默认模式
result = jieba.tokenize(u'永和服装饰品有限公司')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
运行结果:
word 永和 start: 0 end:2 word 服装 start: 2 end:4 word 饰品 start: 4 end:6 word 有限公司 start: 6 end:10
- 搜索模式
result = jieba.tokenize(u'永和服装饰品有限公司', mode='search')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
运行结果:
word 永和 start: 0 end:2
word 服装 start: 2 end:4
word 饰品 start: 4 end:6
word 有限 start: 6 end:8
word 公司 start: 8 end:10
word 有限公司 start: 6 end:10
6. ChineseAnalyzer for Whoosh 搜索引擎
- 引用:
from jieba.analyse import ChineseAnalyzer -
用法示例:https://github.com/fxsjy/jieba/blob/master/test/test_whoosh.py
# -*- coding: UTF-8 -*-
from __future__ import unicode_literals
import sys
import os
sys.path.append("../")
from whoosh.index import create_in
from whoosh.fields import *
from whoosh.qparser import QueryParser
from jieba.analyse import ChineseAnalyzer
analyzer = ChineseAnalyzer()
schema = Schema(title=TEXT(stored=True), path=ID(stored=True), content=TEXT(stored=True, analyzer=analyzer))
if not os.path.exists("tmp"):
os.mkdir("tmp")
ix = create_in("tmp", schema)
writer = ix.writer()
file_name = sys.argv[1]
with open(file_name,"rb") as inf:
i=0
for line in inf:
i+=1
writer.add_document(
title="line"+str(i),
path="/a",
content=line.decode('gbk','ignore')
)
writer.commit()
searcher = ix.searcher()
parser = QueryParser("content", schema=ix.schema)
for keyword in ("水果小姐","你","first","中文","交换机","交换"):
print("result of " + keyword)
q = parser.parse(keyword)
results = searcher.search(q)
for hit in results:
print(hit.highlights("content"))
print("="*10)
注:笔者运行官方dome,windows总是报错如下:
===== RESTART: C:\Users\cuitbnc\Desktop\jieba-master\test\test_whoosh.py =====
Traceback (most recent call last):
File "C:\Users\cuitbnc\Desktop\jieba-master\test\test_whoosh.py", line 3, in <module>
from jieba.analyse import ChineseAnalyzer
ImportError: cannot import name 'ChineseAnalyzer'
错因分析:
1 咱不支持windows操作,由于官方文档没有明显提示,很大可能不成立,即支持windows的
2 缺少lucene或者其他搜索引擎插件,很有可能
3 由于笔者暂时不做这方面业务,扩展下就是,暂时没有去花时间去解决
7 延迟加载机制
jieba 采用延迟加载,import jieba 和 jieba.Tokenizer() 不会立即触发词典的加载,一旦有必要才开始加载词典构建前缀字典。如果你想手工初始 jieba,也可以手动初始化。
import jieba
jieba.initialize() # 手动初始化(可选)
在 0.28 之前的版本是不能指定主词典的路径的,有了延迟加载机制后,你可以改变主词典的路径:jieba.set_dictionary('data/dict.txt.big')
例子: https://github.com/fxsjy/jieba/blob/master/test/test_change_dictpath.py
#encoding=utf-8
from __future__ import print_function
import sys
sys.path.append("../")
import jieba
def cuttest(test_sent):
result = jieba.cut(test_sent)
print(" ".join(result))
def testcase():
cuttest("这是一个伸手不见五指的黑夜。我叫孙悟空,我爱北京,我爱Python和C++。")
cuttest("我不喜欢日本和服。")
cuttest("雷猴回归人间。")
cuttest("工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作")
cuttest("我需要廉租房")
cuttest("永和服装饰品有限公司")
cuttest("我爱北京天安门")
cuttest("abc")
cuttest("隐马尔可夫")
cuttest("雷猴是个好网站")
if __name__ == "__main__":
testcase()
jieba.set_dictionary("foobar.txt")
print("================================")
testcase()
运行结果
这是 一个 伸手 不见 五指 的 黑夜 。 我 叫 孙悟空 , 我 爱北京 , 我 爱 Python 和 C ++ 。
我 不 喜欢 日本 和 服 。
雷猴 回归人间 。
工信 处女 干事 每 月 经过 下 属 科室 都 要 亲口 交代 24 口交换机 等 技术性 器件 的 安装 工作
我 需要 廉租房
永和服 装饰品 有 限公司
我 爱北京 天安门
abc
隐马尔 可夫
雷猴 是 个 好 网站
8 其他词典
-
占用内存较小的词典文件 https://github.com/fxsjy/jieba/raw/master/extra_dict/dict.txt.small
-
支持繁体分词更好的词典文件 https://github.com/fxsjy/jieba/raw/master/extra_dict/dict.txt.big
下载你所需要的词典,然后覆盖 jieba/dict.txt 即可;或者用 jieba.set_dictionary('data/dict.txt.big')
9 常见问题
1 结巴分词模型的数据是如何生成的
来源主要有两个,一个是网上能下载到的1998人民日报的切分语料还有一个msr的切分语料。另一个是我自己收集的一些txt小说,用ictclas把他们切分(可能有一定误差)。 然后用python脚本统计词频。要统计的主要有三个概率表:1)位置转换概率,即B(开头),M(中间),E(结尾),S(独立成词)四种状态的转移概率;2)位置到单字的发射概率,比如P("和"|M)表示一个词的中间出现”和"这个字的概率;3) 词语以某种状态开头的概率,其实只有两种,要么是B,要么是S。比如finalseg/prob_trans.py这个文件:
{'B': {'E': 0.8518218565181658, 'M': 0.14817814348183422},
'E': {'B': 0.5544853051164425, 'S': 0.44551469488355755},
'M': {'E': 0.7164487459986911, 'M': 0.2835512540013088},
'S': {'B': 0.48617017333894563, 'S': 0.5138298266610544}}
P(E|B) = 0.851, P(M|B) = 0.149,说明当我们处于一个词的开头时,下一个字是结尾的概率要远高于下一个字是中间字的概率,符合我们的直觉,因为二个字的词比多个字的词更常见
2
2. “台中”总是被切成“台 中”?(以及类似情况)
P(台中) < P(台)×P(中),“台中”词频不够导致其成词概率较低
解决方法:强制调高词频
jieba.add_word('台中') 或者 jieba.suggest_freq('台中', True)
3. “今天天气 不错”应该被切成“今天 天气 不错”?(以及类似情况)
解决方法:强制调低词频
jieba.suggest_freq(('今天', '天气'), True)
或者直接删除该词 jieba.del_word('今天天气')
解决方法:关闭新词发现
jieba.cut('丰田太省了', HMM=False) jieba.cut('我们中出了一个叛徒', HMM=False)
更多结巴分词问题请点击:https://github.com/fxsjy/jieba/issues?sort=updated&state=closed
10 参考文献:
作者:白宁超,工学硕士,现工作于四川省计算机研究院,研究方向是自然语言处理和机器学习。曾参与国家自然基金项目和四川省科技支撑计划等多个省级项目。著有《自然语言处理理论与实战》一书。 自然语言处理与机器学习技术交流群号:436303759 。
出处:http://www.cnblogs.com/baiboy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号