【NLP】基于自然语言处理角度谈谈CRF(二)
基于自然语言处理角度谈谈CRF
作者:白宁超
2016年8月2日21:25:35
【摘要】:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果。在中文分词、中文人名识别和歧义消解等任务中都有应用。本文源于笔者做语句识别序列标注过程中,对条件随机场的了解,逐步研究基于自然语言处理方面的应用。成文主要源于自然语言处理、机器学习、统计学习方法和部分网上资料对CRF介绍的相关的相关,最后进行大量研究整理汇总成体系知识。文章布局如下:第一节介绍CRF相关的基础统计知识;第二节介绍基于自然语言角度的CRF介绍;第三节基于机器学习角度对CRF介绍,第四节基于统计学习角度对相关知识介绍;第五节对统计学习深度介绍CRF,可以作为了解内容。(本文原创,转载请注明出处:基于自然语言处理角度谈谈CRF。)
目录
【自然语言处理:漫步条件随机场系列文章(一)】:前戏:一起走进条件随机场
【自然语言处理:漫步条件随机场系列文章(二)】:基于自然语言处理角度谈谈CRF
【自然语言处理:漫步条件随机场系列文章(三)】:基于机器学习角度谈谈CRF
【自然语言处理:漫步条件随机场系列文章(四)】:基于统计学习角度谈谈CRF
【自然语言处理:漫步条件随机场系列文章(五)】:条件随机场知识扩展
1 条件随机场(Condition Random Fields),简称CRFs
条件随机场概念:条件随机场就是对给定的输出标识序列Y和观察序列X,条件随机场通过定义条件概率P(X|Y),而不是联合概率分布P(X,Y)来描述模型。
概念解析:
标注一篇文章中的句子,即语句标注,使用标注方法BIO标注,B代表句子的开始,I代表句子中间,O代表句子结束。则观察序列X就是一个语料库(此处假设一篇文章,x代表文章中的每一句,X是x的集合),标识序列Y是BIO,即对应X序列的识别,从而可以根据条件概率P(标注|句子),推测出正确的句子标注,显然,这里针对的是序列状态,即CRF是用来标注或划分序列结构数据的概率化结构模型,其在自然语言处理和图像处理领域得到广泛的应用,CRF可以看作无向图模型或者马尔科夫随机场。
2 条件随机场的形式化表示
设G=(V,E)为一个无向图,V为结点的集合,E为无向边的集合, ,即V中的每个结点对应一个随机变量Yv,其取值范围为可能的标记集合{Y}.如果观察序列X为条件,每一个随机变量 都满足以下马尔科夫特性:
,即V中的每个结点对应一个随机变量Yv,其取值范围为可能的标记集合{Y}.如果观察序列X为条件,每一个随机变量 都满足以下马尔科夫特性: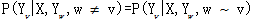 ,其中,w – v表示两个结点在图G中是邻近结点,那么,(X,Y)为条件随机变量。
,其中,w – v表示两个结点在图G中是邻近结点,那么,(X,Y)为条件随机变量。
以语句识别的案例理解条件随机场的形式化表示。
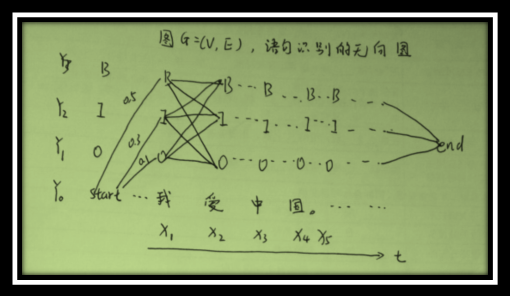
G=(V,E表示识别语句:【我爱中国】的标注是一个无向图,X我观察序列,Y为标注序列,V是每个标注状态的结点,E的无向边,边上的权值为概率值。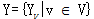 表示每个X的Y的标注,如:X1:我,y1:O,y2:I,y3:B;取值范围
表示每个X的Y的标注,如:X1:我,y1:O,y2:I,y3:B;取值范围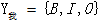 ,而
,而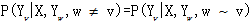 中w—v表示我与爱是相邻的结点,这样的(X,Y)为一个条件随机场,真正的标注再采用Viterbi算法,如:
中w—v表示我与爱是相邻的结点,这样的(X,Y)为一个条件随机场,真正的标注再采用Viterbi算法,如:
寻求最大概率即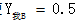 ,记录下我的标注路径,同理可知:
,记录下我的标注路径,同理可知:

如上便是对条件随机场与Viterbi算法的综合运用,其中Viterbi标注问题本质是隐马尔科夫模型三大问题之解码问题算法模型,具体参考(揭秘马尔科夫模型系列文章)
3 深度理解条件随机场
理论上标记序列描述一定条件的独立性,G图结构任意的,对序列进行建模可形成最简单,最普通的链式结构图,结点对应标记序列X中元素,CRF链式图如下:
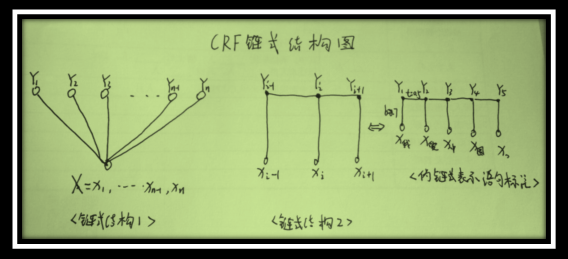
如上图两种表示是一致的,其中图链式句子标注是图链式2的实例化,读者可能问为什么上面图是这种而不是广义的图,这是因为观察序列X的元素之间并不存在图结构,没有做独立性假设,这点也非常容易理解,诸如图中,我爱中国,其中b表示反射概率而t是转移概率,线上的数值表示权值即概率值。如图3,我的发射概率0.7,我到爱的转移概率0.5,通俗讲,我和爱两个字是有关联的,并非独立的。
4 公式化表示条件随机场
在给定的观察序列X时,某个待定标记序列Y的概率可以定义为
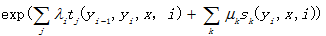
其中 是转移概率,
是转移概率,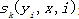 是状态函数,表示观察序列X其中i的位置的标记概率,
是状态函数,表示观察序列X其中i的位置的标记概率,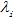 和
和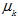 分别是t和s的权重,需要从训练样本中估计出来。
分别是t和s的权重,需要从训练样本中估计出来。
实例解析:
我爱中国,其中x2是爱字,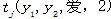 表示在观察状态2中,我到爱的转移概率,其中j∈{B,I,O},可知
表示在观察状态2中,我到爱的转移概率,其中j∈{B,I,O},可知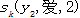 的生成概率或者发射概率的特征函数.观察序列{0,1}二值特征b(x,i)来表示训练样本中某些分布特征,其中采用{0,1}二值特征即符合条件标为1,反之为0;
的生成概率或者发射概率的特征函数.观察序列{0,1}二值特征b(x,i)来表示训练样本中某些分布特征,其中采用{0,1}二值特征即符合条件标为1,反之为0;

为了便于描述,可以将状态函数书写以下形式:
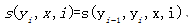
特征函数:
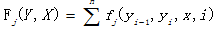
其中每个局部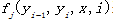 特征表示状态特征,
特征表示状态特征,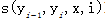 或者专业函数
或者专业函数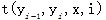 ,由此条件随机场的定义条件概率如下:
,由此条件随机场的定义条件概率如下:
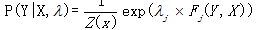 ,
,
其中分母为归一化因子:
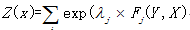
5 本节总结
条件随机场模型也需要解决三个基本问题:特征的选择,参数训练和解码。其中参数训练过程在训练数据集上基于对数似然函数最大化进行。
CRF优点:相对于HMM,CRF主要优点是它的条件随机性,只需要考虑当前出现的观察状态的特性,没有独立性严格要求,CRF具有MEMM一切优点。
CRF与MEMM区别:
MEMM:使用每一个状态的指数模型来计算给定前一个状态下当前状态的条件概率。
CRF:用单个指数模型计算给定观察序列与整个标记序列联合概率。
《统计自然语言处理》P128页有关于随机场模型的实现工具。
6 参考文献
【1】 数学之美 吴军 著
【2】 机器学习 周志华 著
【3】 统计自然语言处理 宗成庆 著(第二版)
【4】 统计学习方法(191---208) 李航
【5】 知乎 网络资源
7 自然语言相关系列文章
【自然语言处理】:【NLP】揭秘马尔可夫模型神秘面纱系列文章
【自然语言处理】:【NLP】大数据之行,始于足下:谈谈语料库知多少
【自然语言处理】:【NLP】蓦然回首:谈谈学习模型的评估系列文章
【自然语言处理】:【NLP】快速了解什么是自然语言处理
【自然语言处理】:【NLP】自然语言处理在现实生活中运用
声明:关于此文各个篇章,本人采取梳理扼要,顺畅通明的写作手法。系统阅读相关书目和资料总结梳理而成,旨在技术分享,知识沉淀。在此感谢原著无私的将其汇聚成书,才得以引荐学习之用。其次,本人水平有限,权作知识理解积累之用,难免主观理解不当,造成读者不便,基于此类情况,望读者留言反馈,便于及时更正。本文原创,转载请注明出处:基于自然语言处理角度谈谈CRF。
作者:白宁超,工学硕士,现工作于四川省计算机研究院,研究方向是自然语言处理和机器学习。曾参与国家自然基金项目和四川省科技支撑计划等多个省级项目。著有《自然语言处理理论与实战》一书。 自然语言处理与机器学习技术交流群号:436303759 。
出处:http://www.cnblogs.com/baiboy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号