【NLP】前戏:一起走进条件随机场(一)
前戏:一起走进条件随机场
作者:白宁超
2016年8月2日13:59:46
【摘要】:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果。在中文分词、中文人名识别和歧义消解等任务中都有应用。本文源于笔者做语句识别序列标注过程中,对条件随机场的了解,逐步研究基于自然语言处理方面的应用。成文主要源于自然语言处理、机器学习、统计学习方法和部分网上资料对CRF介绍的相关的相关,最后进行大量研究整理汇总成体系知识。文章布局如下:第一节介绍CRF相关的基础统计知识;第二节介绍基于自然语言角度的CRF介绍;第三节基于机器学习角度对CRF介绍,第四节基于统计学习角度对相关知识介绍;第五节对统计学习深度介绍CRF,可以作为了解内容。(本文原创,转载请注明出处:漫步条件随机场系列文章。)
目录
【自然语言处理:漫步条件随机场系列文章(一)】:前戏:一起走进条件随机场
【自然语言处理:漫步条件随机场系列文章(二)】:基于自然语言处理角度谈谈CRF
【自然语言处理:漫步条件随机场系列文章(三)】:基于机器学习角度谈谈CRF
【自然语言处理:漫步条件随机场系列文章(四)】:基于统计学习角度谈谈CRF
【自然语言处理:漫步条件随机场系列文章(五)】:条件随机场知识扩展
1 机器学习中的生产模型与判别模型
生产式模型与判别式模型简述,条件随机场是哪种模型?
有监督机器学习方法可以分为生成方法和判别方法:
1)生产式模型:直接对联合分布进行建模,如:混合高斯模型、隐马尔科夫模型、马尔科夫随机场等
2)判别式模型:对条件分布进行建模,如:条件随机场、支持向量机、逻辑回归等。
生成模型优缺点介绍:
优点:
1)生成给出的是联合分布,不仅能够由联合分布计算条件分布(反之则不行),还可以给出其他信息。如果一个输入样本的边缘分布很小的话,那么可以认为学习出的这个模型可能不太适合对这个样本进行分类,分类效果可能会不好。
2)生成模型收敛速度比较快,即当样本数量较多时,生成模型能更快地收敛于真实模型。
3)生成模型能够应付存在隐变量的情况,比如混合高斯模型就是含有隐变量的生成方法。
缺点:
1)天下没有免费午餐,联合分布是能提供更多的信息,但也需要更多的样本和更多计算,尤其是为了更准确估计类别条件分布,需要增加样本的数目,而且类别条件概率的许多信息是我们做分类用不到,因而如果我们只需要做分类任务,就浪费了计算资源。
2)另外,实践中多数情况下判别模型效果更好。
判别模型优缺点介绍:
优点:
1)与生成模型缺点对应,首先是节省计算资源,另外,需要的样本数量也少于生成模型。
2)准确率往往较生成模型高。
3)由于直接学习,而不需要求解类别条件概率,所以允许我们对输入进行抽象(比如降维、构造等),从而能够简化学习问题。
缺点:
1)是没有生成模型的上述优点。
2 简单易懂的解释条件随机场
线性链的条件随机场跟线性链的隐马尔科夫模型一样,一般推断用的都是维特比算法。这个算法是一个最简单的动态规划。
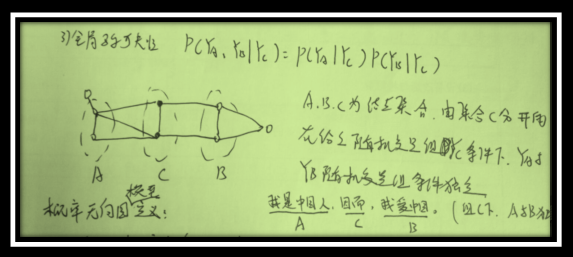
首先我们推断的目标是给定一个X,找到使P(Y|X)最大的那个Y嘛。然后这个Z(X),一个X就对应一个Z,所以X固定的话这个项是常量,优化跟他没关系(Y的取值不影响Z)。然后exp也是单调递增的,也不带他,直接优化exp里面。所以最后优化目标就变成了里面那个线性和的形式,就是对每个位置的每个特征加权求和。比如说两个状态的话,它对应的概率就是从开始转移到第一个状态的概率加上从第一个转移到第二个状态的概率,这里概率是只exp里面的加权和。那么这种关系下就可以用维特比了,首先你算出第一个状态取每个标签的概率,然后你再计算到第二个状态取每个标签得概率的最大值,这个最大值是指从状态一哪个标签转移到这个标签的概率最大,值是多 少,并且记住这个转移(也就是上一个标签是啥)。然后你再计算第三个取哪个标签概率最大,取最大的话上一个标签应该是哪个。以此类推。整条链计算完之后, 你就知道最后一个词去哪个标签最可能,以及去这个标签的话上一个状态的标签是什么、取上一个标签的话上上个状态的标签是什么,酱。这里我说的概率都是 exp里面的加权和,因为两个概率相乘其实就对应着两个加权和相加,其他部分都没有变。
学习
这是一个典型的无条件优化问题,基本上所有我知道的优化方法都是优化似然函数。典型的就是梯度下降及其升级版(牛顿、拟牛顿、BFGS、L-BFGS),这里版本最高的就是L-BFGS了吧,所以一般都用L-BFGS。除此之外EM算法也可以优化这个问题。
3 概率无向图与马尔科夫随机场前世今生
概率无向图模型又称为马尔科夫随机场,是一个可以由无向图表示的联合概率分布。
图是由结点和连接结点的边组成的集合,(这部分知识学过数据结构或者算法的同学都比较了解,不作为深入讲解。)
注意:无向图是指边上没有方向的图,既然边没有方向,其权值是有方向的,诸如转移概率中,“我”到“爱”的转移概率0.5.
概率图模型是由图表示的概率分布,没有联合概率分布P(Y),Y∈{y}是一组随机变量由无向图G=<V,E>表示概率分布P(Y),即在图G中,结点v∈V表示一个随机变量  ;边e∈E表示随机变量之间的概率依赖关系,这点在第一章有详细介绍。
;边e∈E表示随机变量之间的概率依赖关系,这点在第一章有详细介绍。
给定一个联合概率分布P(Y)和表示它的无向图G,无向图表示的随机变量之间的成对马尔科夫性,局部马尔科夫性,全局马尔科夫性的如何区别?
1) 成对马尔科夫性表示

2)局部马尔科夫性表示

3)全局马尔科夫性表示
概率无向图模型的定义
设有联合概率分布P(Y),由无向图G=<V,E>表示,在图G中,结点表示随机变量,边表示随机变量之间关系(加权概率),如果联合概率分布P(Y)满足成对/局部/全局马尔科夫性,就称此联合为概率无向图模型或者马尔科夫随机场。
4 计算联合概率分布:概率无向图模型的因子分解
对给定概率无向图模型下,本质就是要求联合概率可以将其改变成若干子联合概率乘积的形式,也就是将联合概率进行因子分解。首先介绍两个概念:团与最大团。
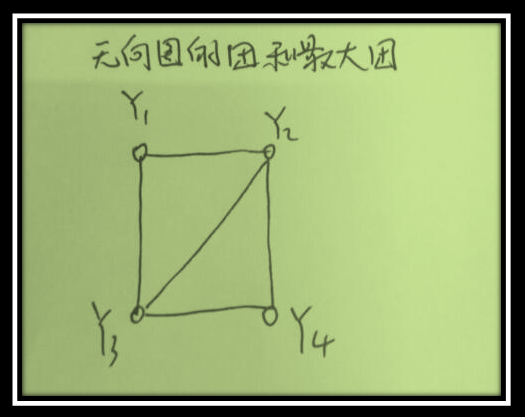
团:无向图G中任何两个结点均有边连接的节点子集成为团。
最大团:若C是无向图G的一个团,并且不能再加进任何一个G的节点使其成为一个更大的团,则称此C为最大团。
注意:{y1,y2,y3,y4}不是一个团,因为y1与y4无边相连
概率无向图模型的因子分解:
将概率无向图模型的联合概率分布表示,其最大团上的随机变量的函数的乘积形式的操作,即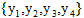 的联合概率是
的联合概率是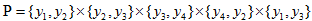 这样不免太复杂,倘若
这样不免太复杂,倘若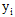 为10000个结点以上呢?(每个结点是一个汉字,假设最大团以是篇章,本书假设10章,则是十个最大团之积。)
为10000个结点以上呢?(每个结点是一个汉字,假设最大团以是篇章,本书假设10章,则是十个最大团之积。)
概率无向图模型的联合概率分布P(Y)的公式化表示:
给定概率无向图模型,设其无向图为G,C为G上的最大团,YC表示C对应的随机变量。那么概率无向图模型的联合概率分布P(Y)可写作图中所有最大团C上的函数ΨC(YC)的乘积形式,即:
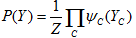
其中, 为势函数,C为最大团,Z是规范化因子

规范化因子保证P(Y)构成一个概率分布。
因为要求势函数ΨC(YC)是严格正的,于是通常定义为指数函数:
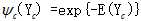
5 参考文献
【1】 数学之美 吴军 著
【2】 机器学习 周志华 著
【3】 统计自然语言处理 宗成庆 著(第二版)
【4】 统计学习方法(191---208) 李航
【5】 知乎 网络资源
6 自然语言相关系列文章
【自然语言处理】:【NLP】揭秘马尔可夫模型神秘面纱系列文章
【自然语言处理】:【NLP】大数据之行,始于足下:谈谈语料库知多少
【自然语言处理】:【NLP】蓦然回首:谈谈学习模型的评估系列文章
【自然语言处理】:【NLP】快速了解什么是自然语言处理
【自然语言处理】:【NLP】自然语言处理在现实生活中运用
声明:关于此文各个篇章,本人采取梳理扼要,顺畅通明的写作手法。系统阅读相关书目和资料总结梳理而成,旨在技术分享,知识沉淀。在此感谢原著无私的将其汇聚成书,才得以引荐学习之用。其次,本人水平有限,权作知识理解积累之用,难免主观理解不当,造成读者不便,基于此类情况,望读者留言反馈,便于及时更正。本文原创,转载请注明出处:前戏:一起走进条件随机场。
作者:白宁超,工学硕士,现工作于四川省计算机研究院,研究方向是自然语言处理和机器学习。曾参与国家自然基金项目和四川省科技支撑计划等多个省级项目。著有《自然语言处理理论与实战》一书。 自然语言处理与机器学习技术交流群号:436303759 。
出处:http://www.cnblogs.com/baiboy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架