


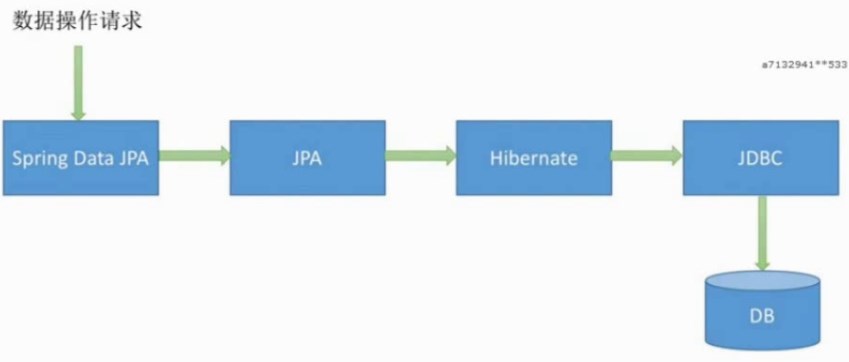
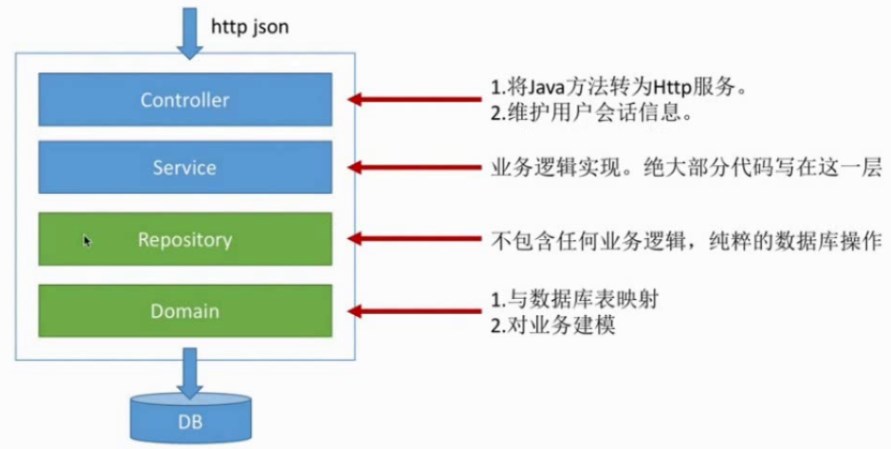
1.spring data jpa的映射关系

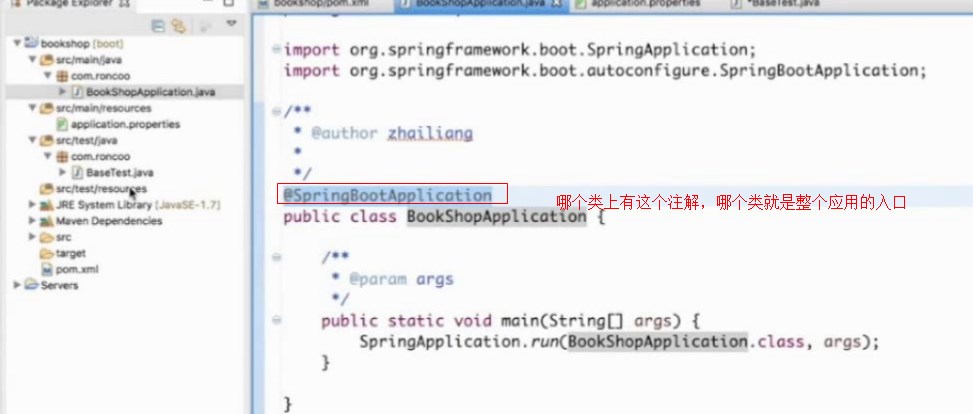
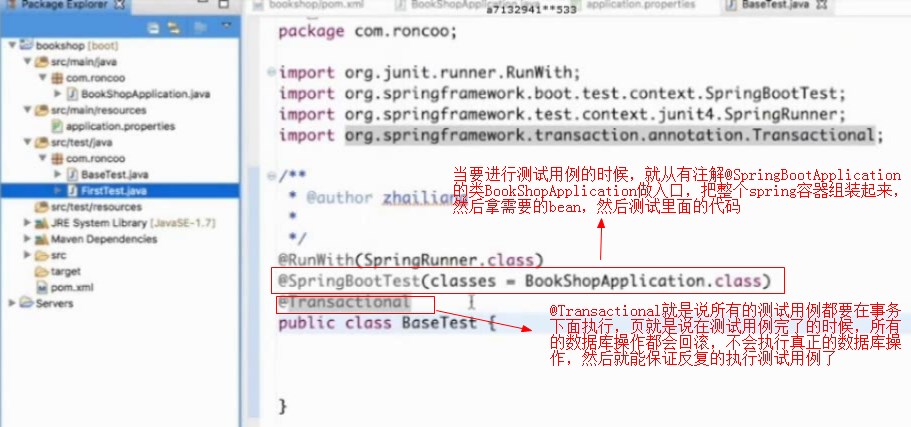
当要进行测试用例的时候,就从有注解@SpringBootApplication的类BookShopApplication做入口,把整个spring容器组装起来,然后拿需要的bean,然后测试里面的代码
@Transactional就是说所有的测试用例都要在事务下面执行,页就是说在测试用例完了的时候,所有的数据库操作都会回滚,不会执行真正的数据库操作,然后就能保证反复的执行测试用例了
注意:所有的测试用例都应该是:public void (即:没有返回值)


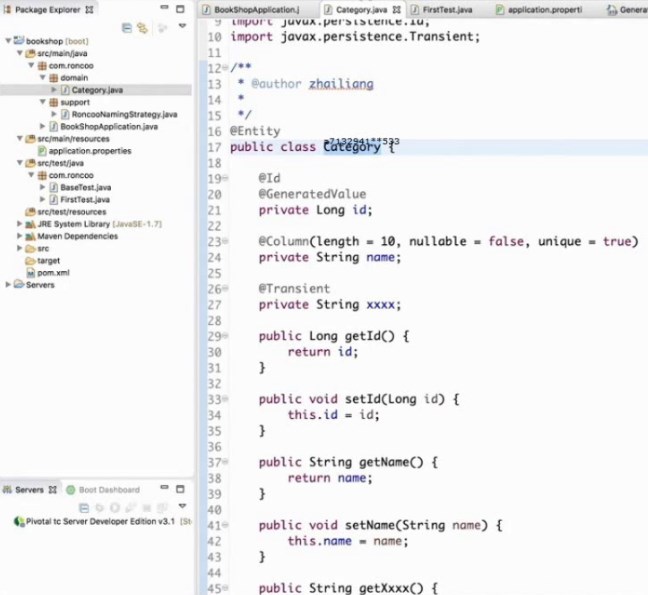
@Entity就是把这个bean映射到数据库中去
@id是不敖明这个属性是主键
@GeneratedValue指定当前主键的生成策略
@table(name="roncoo_category")是将实体类映射到数据库中后命名表名为roncoo_category
意思是将name映射到数据库中的字段名命名为roncoo
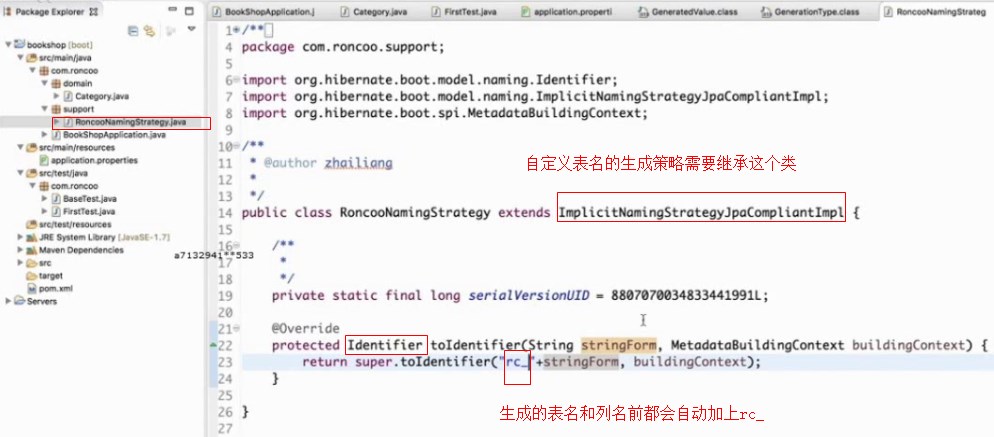
新建一个命名策略
用来生成表名和字段名的前缀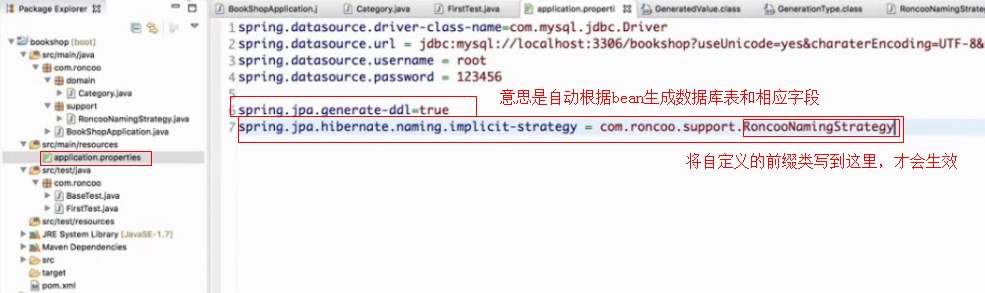
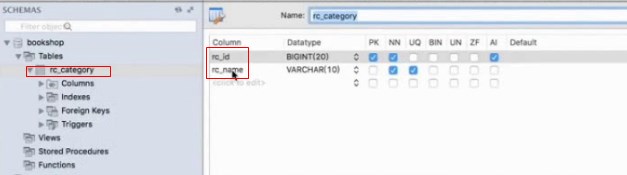
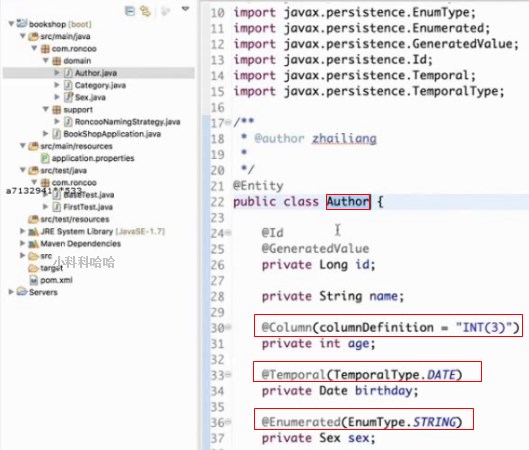
发现bean中的string类型属性的会自动在数据库中转化成varchar类型的字段
long类型会自动转成bigint
date类型会自动转成datetime
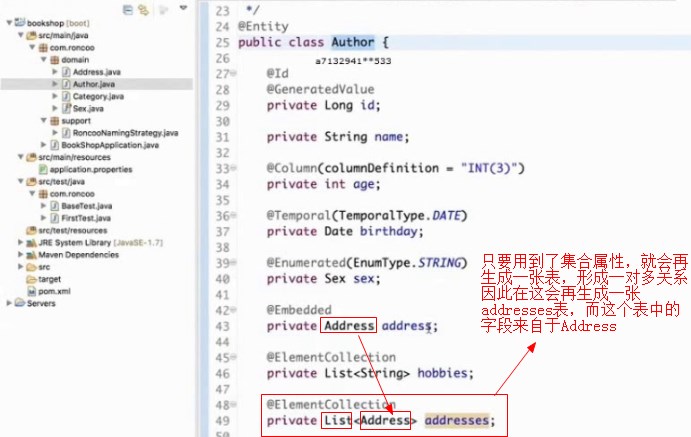
内嵌对象的映射
@Embeddable意思是说这是一个可嵌入的对象(可注入)
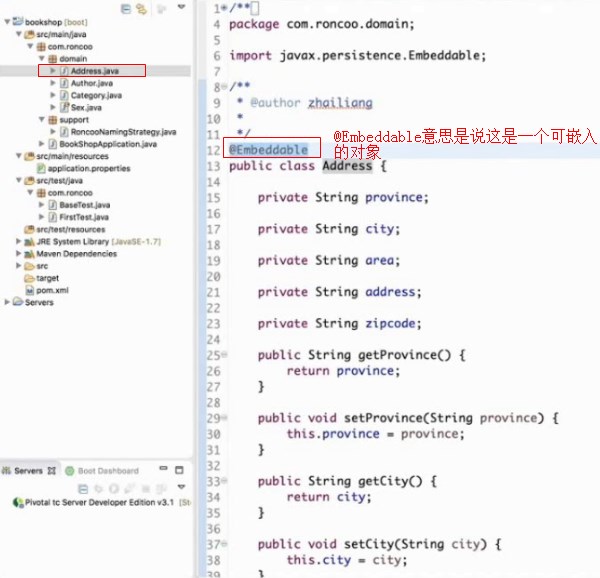
(可被注入)
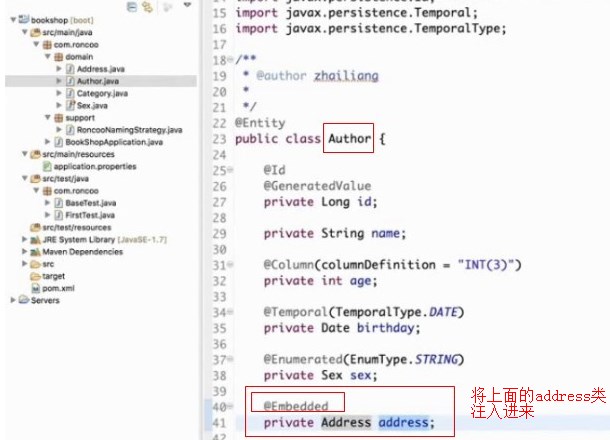

这个就叫做内嵌对象的映射,我们可以在任何一个需要地址信息的类中嵌入address,
集合映射
如何映射集合?
如下例子
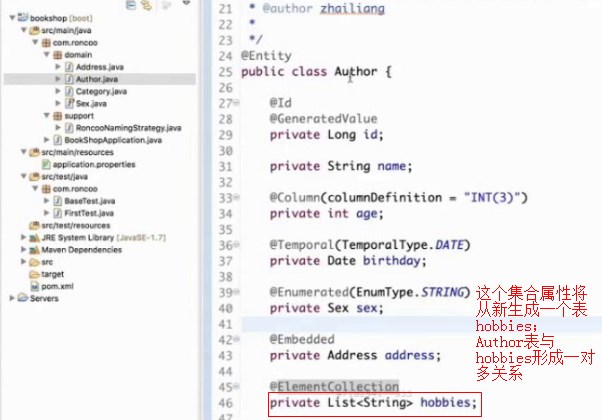
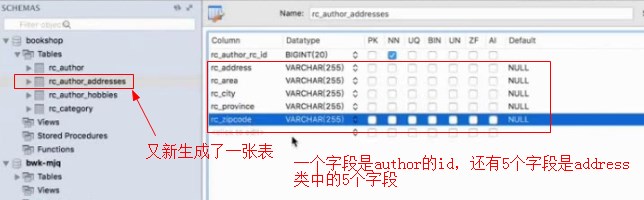
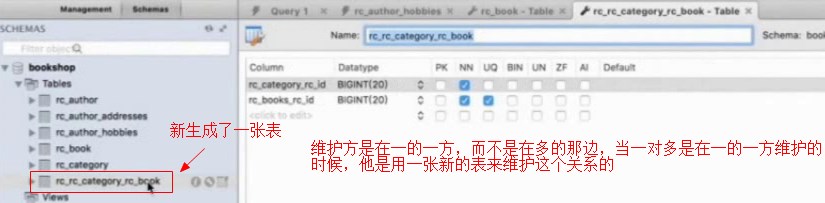
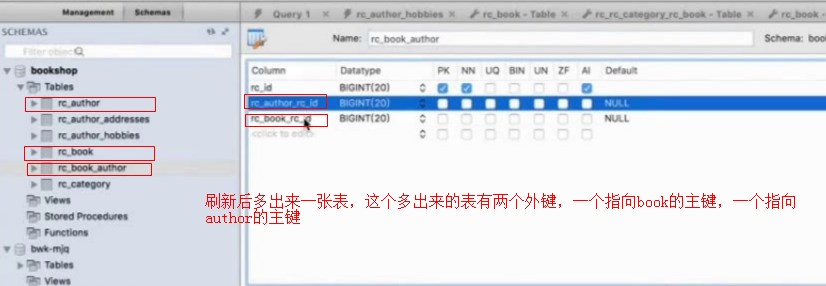
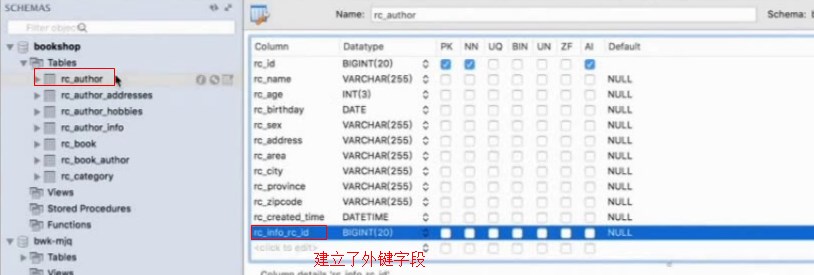
,执行后,发现多出来一张表
 这两个表形成了一对多的关系,而生成的hobbies表中有两个字段,一个是Author的id,还有一个是hobbies字段
这两个表形成了一对多的关系,而生成的hobbies表中有两个字段,一个是Author的id,还有一个是hobbies字段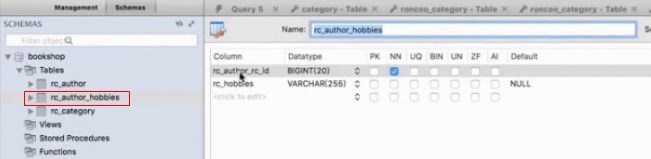
单向多对一映射
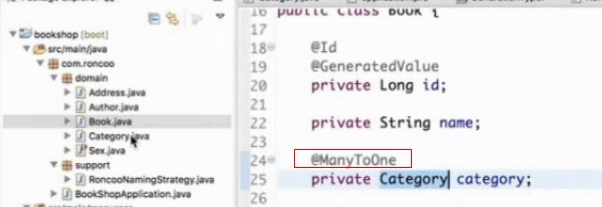
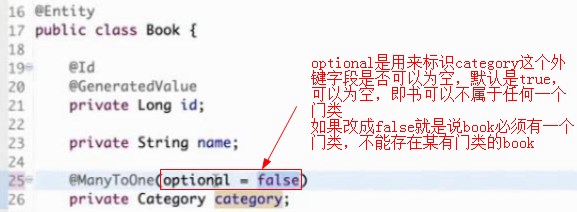
图书和category是多对一的关系,多本书可以属于一个门类,所以用@manyToOne这本书是属于哪个门类的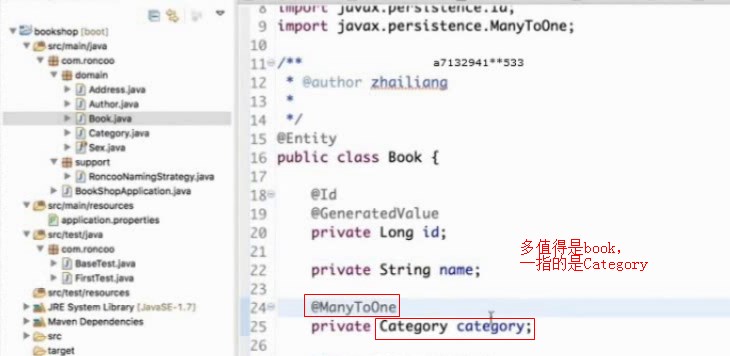
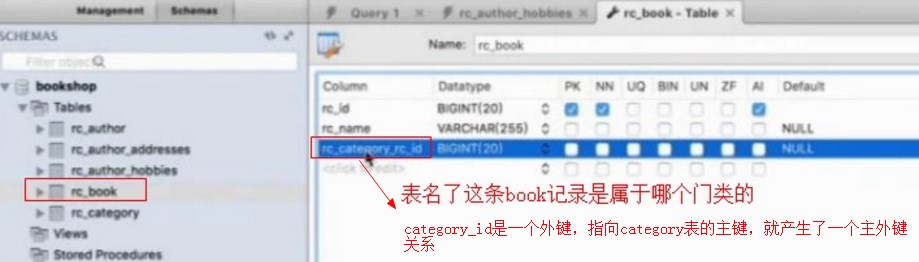
category_id是一个外键,指向category表的主键,就产生了一个主外键关系
因为是单向的,所以只能通过book访问到category,而不能通过category门类访问到门类下面有哪些book的,这个叫做单向多对一的关系
单向一对多的关系
这个是要建立在Category里面的,Category和book是一对多的关系,一个门类里面可以有多个book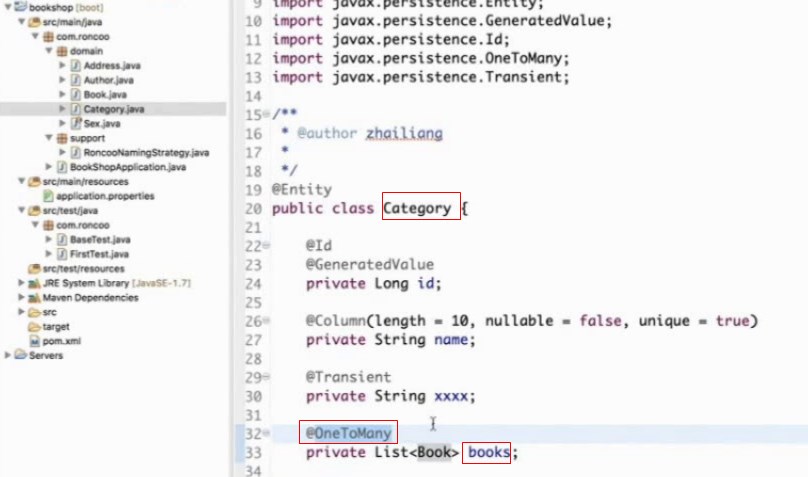

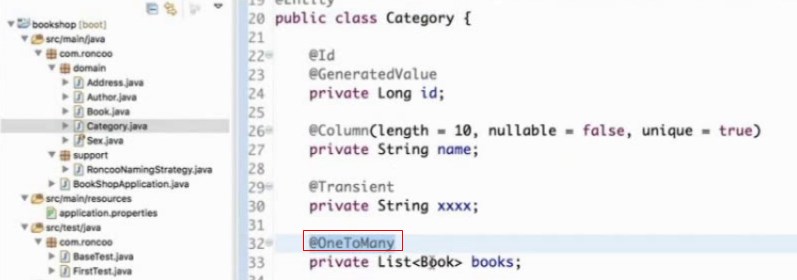






这个因为是单向一对多,通过门类可以访问门类下的book,但是从图书book是访问不到Category门类的
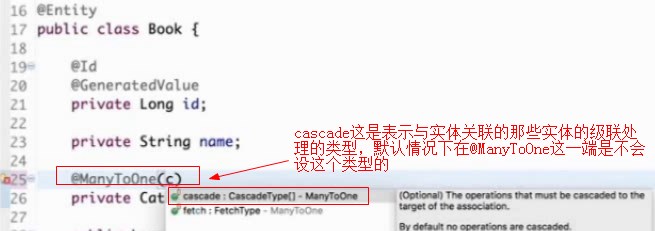
维护方是在一的一方,而不是在多的那边,当一对多是在一的一方维护的时候,他是用一张新的表来维护这个关系的;
而在维护一对多,是在多的一方维护的话,就会在多的一方产生一个外键来指向一个一方的主键
所以标准的应该是:在维护一对多,在多的一方用产生外键来维护,而不是在一的一方用产生一张新表的方式来维护,
一般情况下是不太建议使用单向一对多关系,但是如果非要建立单向一对多关系,应该在多的一方使用@ManyToOne,而不是在一的一方使用@OneToMany
但是最佳实践是建立一个双向关系
在多的一方使用@ManyToOne,并且在一的一方使用@OneToMany,
当拿到book对象的时候,能通过book中的category的getCategory()拿取到一的一方category的门类的信息
当拿到门类信息category的时候,通过getBooks()拿到门类下的所有图书book的信息
当有一对多或多对一的关系的时候比如:在数据库中查出一个book对象来的时候,他会用一个select语句从book表中查出一条记录来把他转成一个book对象,当在调book对象的getCategory()方法的时候,他会立刻执行一条sql,把相应的门类信息查出来,放到这
同样的,当查Category,掉Category对象的getBook()方法,也会执行一条SQL,把门类下的所有book读出来,放到 的
的 中
中
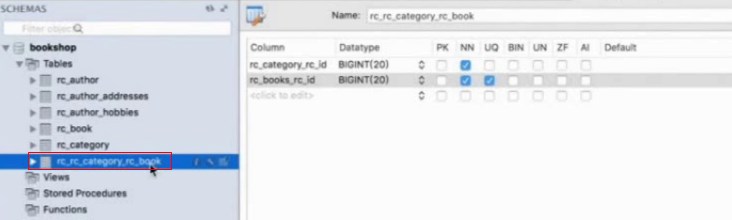
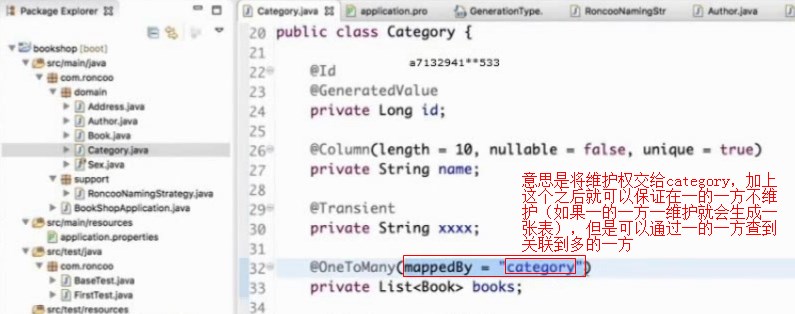
的中因为加了@ManyToOne和@OneToMany,所以两边都在维护这个关系,在@OneToMany这边维护的时候,还是建了多余的这张表,现在的需求就是希望在多的一方book对象中通过产生外键来维护,一的一方仍然声明@OneToMany,通过Category可以访问下面的books,希望是一个双向关联
一对多的关系不由一的这一端来维护,而交给多的那一端,也就是book里面的Category属性来维护,即@ManyToOne生成外键的属性,做了这个设置之后Category就放弃了一对多的这样一个管理,不会再生成那张多余的表,只是有多的这端,也就是Book这端生成一个外键来维护这个关系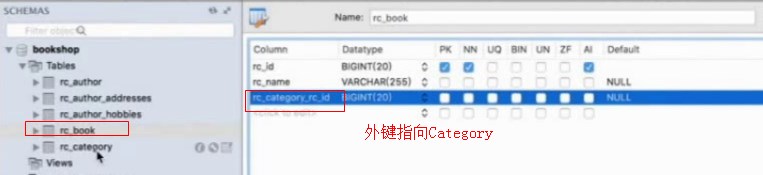
@OneToMany(@mappedBy="category")的意思是放弃去管理一对多的关系(即:不多生成一张表,只提供能从一的一方查到多的一方这种能力),只在多的一端去管理
下面介绍几个@ManyToOne常用的属性:
fetch是实体的加载方式,有两个值,一个是eager,还有一个是lazy,
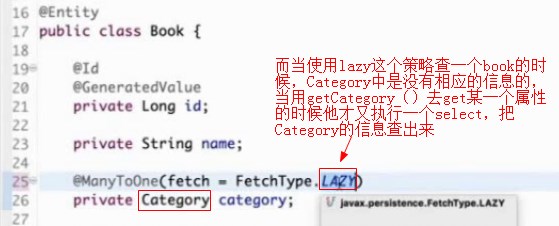
lazy就是在读取book信息的时候,不执行一个关联查询,不去查门类Category信息;
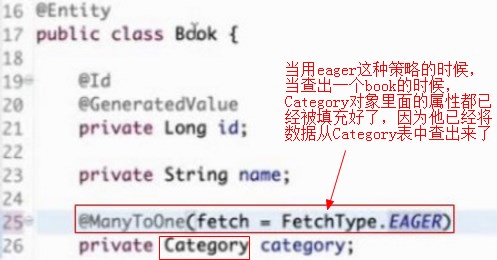
eager是读取book信息的时候(读取book的SQL是一个关联查询,会关联到Category表上去),同时把门类的信息查出来
不关联到另一个表查询的是lazy,关联到另一个表查的是eager
当用eager这种策略的时候,当查出一个book的时候,Category对象里面的属性都已经被填充好了,因为他已经将数据从category表中查出来了
而当使用lazy这个策略查一个book的时候,Category中是没有相应的信息的,当用getCategory()去get某一个属性的时候他才又执行一个select,把Category的信息查出来
注意在@ManyToOne中默认的抓取策略是eager,不写的时候,查book默认的是把Category的信息也带出来
可以控制相关策略的抓取控制
optional是用来标识category这个外键字段是否可以为空,默认是true,可以为空,即书可以不属于任何一个门类
如果改成false就是说book必须有一个门类,不能存在某有门类的book
cascade这是表示与实体关联的那些实体的级联处理的类型,默认情况下在@ManyToOne这一端是不会设这个类型的
下面介绍几个@OneToMany常用的属性
其中也有fetch=fetchType.lazy和fetch=fetchType.eager属性外,还多出了orphanRemoval属性
orphanRemoval:
orphanRemoval用来表示当前指定集合中的一个元素被从集合中移除后是否从数据库中删除,即:假如book中有5本书,然后用list的remove方法(例如:books.remove(1)),把一本书挪出去了,只是把他从集合中去掉了,从集合中去掉以后这个Book就不属于任何一个门类了,那么是不是把这本书删掉,就是由orphanRemoval控制的,当等于orphanRemoval=true时,当把那本书从集合中移除掉,这本书会自动被删掉,默认的是false
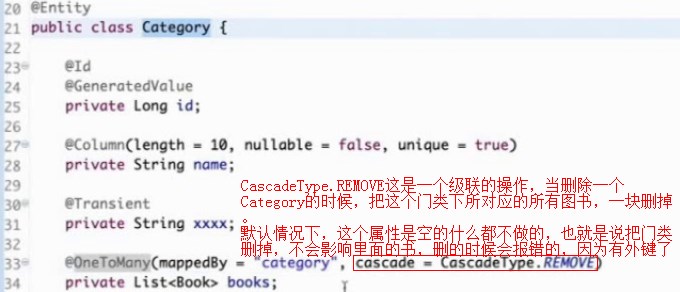
cascade=CascadeType.REMOVE这是一个级联的操作,当删除一个Category的时候,把这个门类下所对应的所有图书,一块删掉。
默认情况下,这个属性是空的什么都不做的,也就是说把门类删掉,不会影响里面的书,删的时候会报错的,因为有外键了
多对多关系的映射
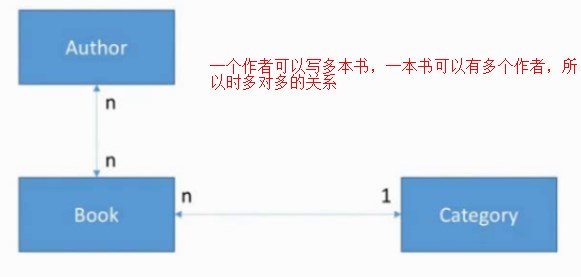
在这个案例里面,图书和作者是多对多关系,一个作者可以写多本书,一本书可以有多个作者
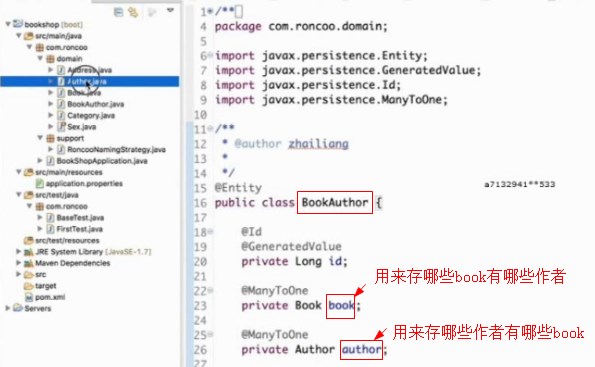
创建了一个中间对象BookAuthor,用来保存多对多关系,在这个对象中有一个指向book的引用,还有一个指向作者author的引用
想要知道这个作者写了哪些书,不是直接指向book的(直接指向book就变成了,一对多关系了),
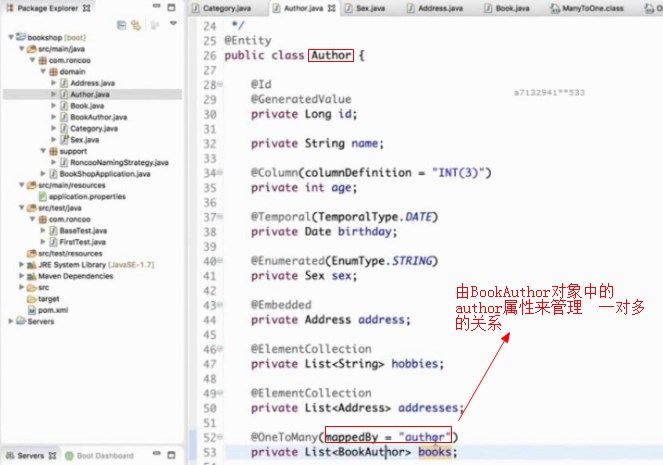
而要指向的这个中间对象BookAuthor,由BookAuthor对象中的author属性来管理 一对多的关系
同样在book中也要写上面的这个属性
意思是说这个book是由哪些作者写成的,同样也指向BookAuthor这个中间对象,告诉book对象,是靠BookAuthor中的
book属性来维护这个一对多关系的
在bookauthor对象中存了多对多的关系
在多对多关系中,为什么不用@ManyToMany呢,因为spring官方建议将多对多关系最好拆成两个一对多关系
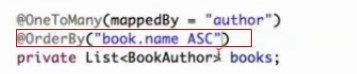
注意:
这个注解的作用是,当通过作者的一个getbooks方法拿取作者写额所有的书的时候,这些书就会按照书名升序排列
一对一关系的映射
比如说用户表可能有30个字段,但是这些字段中只有10个字段是比较常用的,有些就不常用,如果把这所有的字段放到一个表中去,然后每次查表都会查许多字段,所以一般就会将一张表拆成两张表,一个表放常用的,另一个表放不常用的
authorInfo不去管理一对一的关系,而将管理权交到Author这个对象的Info属性上(即交到会去建外键的属性上),但是可以由authorInfo表查到author表这一方
注意:在一对多的关系中,一的一方维护权是用建表的方式完成的(是不建议的),
多的一方的维护权是通过生成外键的方式完成的(建议)。
