【原创】机器学习之PageRank算法应用与C#实现(2)球队排名应用与C#代码
 在上一篇文章:机器学习之PageRank算法应用与C#实现(1)算法介绍 中,对PageRank算法的原理和过程进行了详细的介绍,并通过一个很简单的例子对过程进行了讲解。从上一篇文章可以很快的了解PageRank的基础知识。相比其他一些文献的介绍,上一篇文章的介绍非常简洁明了。当然文章主要引用的是[1].上述引用“赵国,宋建成.Google搜索引擎的数学模型及其应用,西南民族大学学报自然科学版.2010,vol(36),3”这篇学术论文。鉴于文献中本身提供了一个案例,所以本文就使用文章的案例和思路,并使用C#进行编程实现,测试。论文中的案例其实是来源于1993年全国大学生数学建模竞赛的B题—足球队排名问题。
在上一篇文章:机器学习之PageRank算法应用与C#实现(1)算法介绍 中,对PageRank算法的原理和过程进行了详细的介绍,并通过一个很简单的例子对过程进行了讲解。从上一篇文章可以很快的了解PageRank的基础知识。相比其他一些文献的介绍,上一篇文章的介绍非常简洁明了。当然文章主要引用的是[1].上述引用“赵国,宋建成.Google搜索引擎的数学模型及其应用,西南民族大学学报自然科学版.2010,vol(36),3”这篇学术论文。鉴于文献中本身提供了一个案例,所以本文就使用文章的案例和思路,并使用C#进行编程实现,测试。论文中的案例其实是来源于1993年全国大学生数学建模竞赛的B题—足球队排名问题。
在上一篇文章:机器学习之PageRank算法应用与C#实现(1)算法介绍 中,对PageRank算法的原理和过程进行了详细的介绍,并通过一个很简单的例子对过程进行了讲解。从上一篇文章可以很快的了解PageRank的基础知识。相比其他一些文献的介绍,上一篇文章的介绍非常简洁明了。说明:本文的主要内容都是来自“赵国,宋建成.Google搜索引擎的数学模型及其应用,西南民族大学学报自然科学版.2010,vol(36),3”这篇学术论文。鉴于文献中本身提供了一个非常简单容易理解和入门的案例,所以本文就使用文章的案例和思路来说明PageRank的应用,文章中的文字也大部分是复制该篇论文,个人研究是对文章的理解,以及最后一篇的使用C#实现该算法的过程,可以让读者更好的理解如何用程序来解决问题。所以特意对作者表示感谢。如果有认为侵权,请及时联系我,将及时删除处理。
论文中的案例其实是来源于1993年全国大学生数学建模竞赛的B题—足球队排名问题。
本文原文链接:【原创】机器学习之PageRank算法应用与C#实现(2)球队排名应用与C#代码
1.足球队排名问题
1993年的全国大学生数学建模竞赛B题就出了这道题目,不过当时PageRank算法还没有问世,所以现在用PageRank来求解也只能算马后炮,不过可以借鉴一下思路,顺便可以加深对算法的理解,并可以观察算法实际的效果怎么样。顺便说一下,全国大学生数学建模竞赛的确非常有用,我在大学期间,连续参加过2004和2005年的比赛,虽然只拿了一个省二等奖,但是这个过程对我的影响非常大。包括我现在的编程,解决问题的思路都是从建模培训开始的。希望在校大学生珍惜这些机会,如果能入选校队,参加集训,努力学习,对以后的学习,工作都非常有帮助。下面看看这个题目的具体问题:
具体数据由于篇幅较大,已经上传为图片,需要看的,点击链接:数据链接

2.利用PageRank算法的思路
2.1 问题分析
足球队排名次问题要求我们建立一个客观的评估方法,只依据过去一段时间(几个赛季或几年)内每个球队的战绩给出各个球队的名次,具有很强的实际背景.通过分析题中12支足球队在联赛中的成绩,不难发现表中的数据残缺不全,队与队之间的比赛场数相差很大,直接根据比赛成绩来排名次比较困难。
下面我们利用PageRank算法的随机冲浪模型来求解.类比PageRank算法,我们可以综合考虑各队的比赛成绩为每支球队计算相应的等级分(Rank),然后根据各队的等级分高低来确定名次,直观上看,给定球队的等级分应该由它所战胜和战平的球队的数量以及被战胜或战平的球队的实力共同决定.具体来说,确定球队Z的等级分的依据应为:一是看它战胜和战平了多少支球队;二要看它所战胜或战平球队的等级分的高低.这两条就是我们确定排名的基本原理.在实际中,若出现等级分相同的情况,可以进一步根据净胜球的多少来确定排名.由于表中包含的数据量庞大,我们先在不计平局,只考虑获胜局的情形下计算出各队的等级分,以说明算法原理。然后我们综合考虑获胜局和平局,加权后得到各队的等级分,并据此进行排名。考虑到竞技比赛的结果的不确定性,我们最后建立了等级分的随机冲浪模型,分析表明等级分排名结果具有良好的参数稳定性。
2.2 获取转移概率矩阵
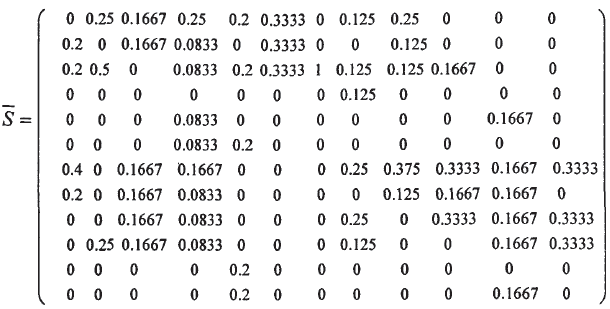
首先利用有向赋权图的权重矩阵来表达出各队之间的胜负关系.用图的顶点表示相应球队,用连接两个顶点的有向边表示两队的比赛结果。同时给边赋权重,表明占胜的次数。所以,可以得到数据表中给出的12支球队所对应的权重矩阵,这是计算转义概率矩阵的必要步骤,这里直接对论文中的截图进行引用:



2.3 关于加权等级分
上述权重不够科学,在论文中,作者提出了加权等级分,就是考虑平局的影响,对2个矩阵进行加权得到权重矩阵,从而得到转移概率矩阵。这里由于篇幅比较大,但是思路比较简单,不再详细说明,如果需要详细了解,可以看论文。本文还是集中在C#的实现过程。
2.4 随机冲浪模型

3.C#编程实现过程
下面我们将使用C#实现论文中的上述过程,注意,2.3和2.2的思想是类似的,只不过是多了一个加权的过程,对程序来说还是很简单的。下面还是按照步骤一个一个来,很多人看到问题写程序很难下手,其实习惯就好了,按照算法的步骤来,一个一个实现,总之要先动手,不要老是想,想来想去没有结果,浪费时间。只有实际行动起来,才能知道实际的问题,一个一个解决,持之以恒,思路会越来越清晰。
3.1 计算权重矩阵
权重矩阵要根据测试数据,球队和每2个球队直接的比分来获取,所以我们使用一个字典来存储原始数据,将每个节点,2个队伍的比赛结果比分都写成数组的形式,来根据胜平负的场次计算积分,得到边的权重,看代码吧:

1 /// <summary>根据比赛成绩,直接根据积分来构造权重矩阵,根据i,对j比赛获取的分数</summary> 2 /// <param name="data">key为2个对的边名称,value是比分列表,分别为主客进球数</param> 3 /// <param name="teamInfo">球队的编号列表</param> 4 /// <returns>权重矩阵</returns> 5 public static double[,] CalcLevelTotalScore(Dictionary<String, Int32[][]> data, List<Int32> teamInfo) 6 { 7 Int32 N = teamInfo.Count; 8 double[,] result = new double[N, N]; 9 10 #region 利用对称性,只计算一半 11 for (int i = 1; i < N; i++) 12 { 13 for (int j = i + 1; j <= N; j++) 14 { 15 #region 循环计算 16 String key = String.Format("{0}-{1}", teamInfo[i - 1], teamInfo[j - 1]); 17 //不存在比赛成绩 18 if (!data.ContainsKey(key)) 19 { 20 result[i - 1, j - 1] = result[j - 1, i - 1] = 0; 21 continue; 22 } 23 //计算i,j直接的互胜场次 24 var scores = data[key];//i,j直接的比分列表 25 var Si3 = scores.Where(n => n[0] > n[1]).ToList();//i胜场次 26 var S1 = scores.Where(n => n[0] == n[1]).ToList();//i平场次 27 var Si0 = scores.Where(n => n[0] < n[1]).ToList();//i负场次 28 result[i - 1, j - 1] = Si3.Count*3 + S1.Count ; 29 result[j - 1, i - 1] = Si0.Count *3 + S1.Count ; 30 #endregion 31 } 32 } 33 #endregion 34 //按照列向量进行归一化 35 return GetNormalizedByColumn(result); 36 }
上面最后返回调用了归一化的函数,比较简单,直接代码贴出来,折叠一下:


1 /// <summary>按照列向量进行归一化</summary> 2 /// <param name="data"></param> 3 /// <returns></returns> 4 public static double[,] GetNormalizedByColumn(double[,] data) 5 { 6 int N = data.GetLength(0); 7 double[,] result = new double[N, N]; 8 #region 各个列向量归一化 9 for (int i = 0; i < N; i++) //列 10 { 11 double sum = 0; 12 //行 13 for (int j = 0; j < N; j++) sum += data[j, i]; 14 for (int j = 0; j < N; j++) 15 { 16 if (sum != 0) result[j, i] = data[j, i] / (double)sum;//归一化,每列除以和值 17 else result[j, i] = data[j, i]; 18 } 19 } 20 #endregion 21 22 return result; 23 }
3.2 计算最大特征值及特征向量
计算特征值和特征向量是一个数学问题,我们采用了Math.NET数学计算组件,可以直接计算很方便。详细的使用可以参考下面代码,组件的其他信息可以参考本站导航栏上的专题目录,有大量的使用文章。看代码吧。
1 /// <summary>求最大特征值下的特征向量</summary> 2 /// <param name="data"></param> 3 /// <returns></returns> 4 public static double[] GetEigenVectors(double[,] data) 5 { 6 var formatProvider = (CultureInfo)CultureInfo.InvariantCulture.Clone(); 7 formatProvider.TextInfo.ListSeparator = " "; 8 9 int N = data.GetLength(0); 10 Matrix<double> A = DenseMatrix.OfArray(data); 11 var evd = A.Evd(); 12 var vector = evd.EigenVectors;//特征向量 13 var ev = evd.EigenValues;//特征值,复数形式发 14 15 if (ev[0].Imaginary > 0) throw new Exception("第一个特征值为复数"); 16 //取 vector 第一列为最大特征向量 17 var result = new double[N]; 18 for (int i = 0; i < N; i++) 19 { 20 result[i] =Math.Abs(vector[i, 0]);//第一列,取绝对值 21 } 22 return result; 23 }
3.3 随机冲浪模型的实现
随机冲浪模型主要是有一个比例,设置之后可以直接求解,也比较简单,函数如下:
1 /// <summary>获取随机冲浪模型的 转移矩阵: 2 /// 作用很明显,结果有明显的改善 3 /// </summary> 4 /// <returns></returns> 5 public static double[,] GetRandomModeVector(double[,] data ,double d = 0.35) 6 { 7 int N = data.GetLength(0); 8 double k = (1.0 - d) / (double)N; 9 double[,] result = new double[N, N]; 10 for (int i = 0; i < N; i++) 11 { 12 for (int j = 0; j < N; j++) result[i, j] = data[i, j] * d + k; 13 } 14 return result; 15 }
3.4 其他
其他问题就是数据组合的过程,这里太多,不详细讲解。主要是构建测试数据以及排序后结果的处理,很简单。贴一个球队排序的函数,根据特征向量:
1 /// <summary>排序,输出球队编号</summary> 2 /// <param name="w"></param> 3 /// <param name="teamInfo"></param> 4 /// <returns></returns> 5 public static Int32[] TeamOrder(double[] w, List<Int32> teamInfo) 6 { 7 Dictionary<int, double> dic = new Dictionary<int, double>(); 8 for (int i = 1; i <= w.Length; i++) dic.Add(i , w[i-1]); 9 return dic.OrderByDescending(n => n.Value).Select(n => n.Key).ToArray(); 10 }
4.算法测试
我们使用问题1中的数据,进行测试,首先构建测试集合,代码如下,太长,折叠一下,主要是问题1的原始数据:
1 /// <summary> 2 /// 获取测试的数据集,key=对1-对2,value = int[,] 为比分 3 /// </summary> 4 public static Dictionary<String, Int32[][]> GetTestData() 5 { 6 Dictionary<String, Int32[][]> data = new Dictionary<string, int[][]>(); 7 #region 依次添加数据 8 #region T1 9 data.Add("1-2", new Int32[][]{ new Int32[] { 0, 1 }, new Int32[] { 1, 0 }, new Int32[] { 0, 0 } }); 10 data.Add("1-3", new Int32[][] { new Int32[] { 2, 2 }, new Int32[] { 1, 0 }, new Int32[] { 0, 2 } }); 11 data.Add("1-4", new Int32[][] { new Int32[] { 2, 0 }, new Int32[] { 3, 1 }, new Int32[] { 1, 0 } }); 12 data.Add("1-5", new Int32[][] { new Int32[] { 3, 1 } }); 13 data.Add("1-6", new Int32[][] { new Int32[] { 1, 0 } }); 14 data.Add("1-7", new Int32[][] { new Int32[] { 0, 1 }, new Int32[] { 1, 3 } }); 15 data.Add("1-8", new Int32[][] { new Int32[] { 0, 2 }, new Int32[] { 2, 1 } }); 16 data.Add("1-9", new Int32[][]{ new Int32[] { 1, 0 }, new Int32[] { 4, 0 } }); 17 data.Add("1-10", new Int32[][]{ new Int32[] { 1, 1 }, new Int32[] { 1, 1 } }); 18 #endregion 19 20 #region T2 21 data.Add("2-3", new Int32[][] { new Int32[] { 2, 0 }, new Int32[] { 0, 1 }, new Int32[] { 1, 3 } }); 22 data.Add("2-4", new Int32[][] { new Int32[] { 0, 0 }, new Int32[] { 2, 0 }, new Int32[] { 0, 0 } }); 23 data.Add("2-5", new Int32[][] { new Int32[] { 1, 1 } }); 24 data.Add("2-6", new Int32[][] { new Int32[] { 2, 1 } }); 25 data.Add("2-7", new Int32[][] { new Int32[] { 1, 1 }, new Int32[] { 1, 1 } }); 26 data.Add("2-8", new Int32[][] { new Int32[] { 0, 0 }, new Int32[] { 0, 0 } }); 27 data.Add("2-9", new Int32[][] { new Int32[] { 2, 0 }, new Int32[] { 1, 1 } }); 28 data.Add("2-10", new Int32[][] { new Int32[] { 0, 2 }, new Int32[] { 0, 0 } }); 29 #endregion 30 31 #region T3 32 data.Add("3-4", new Int32[][] { new Int32[] { 4, 2 }, new Int32[] { 1, 1 }, new Int32[] { 0, 0 } }); 33 data.Add("3-5", new Int32[][] { new Int32[] { 2, 1 } }); 34 data.Add("3-6", new Int32[][] { new Int32[] { 3, 0 } }); 35 data.Add("3-7", new Int32[][] { new Int32[] { 1, 0 }, new Int32[] { 1, 4 } }); 36 data.Add("3-8", new Int32[][] { new Int32[] { 0, 1 }, new Int32[] { 3, 1 } }); 37 data.Add("3-9", new Int32[][] { new Int32[] { 1, 0 }, new Int32[] { 2, 3 } }); 38 data.Add("3-10", new Int32[][] { new Int32[] { 0, 1 }, new Int32[] { 2, 0 } }); 39 #endregion 40 41 #region T4 42 data.Add("4-5", new Int32[][] { new Int32[] { 2, 3 } }); 43 data.Add("4-6", new Int32[][] { new Int32[] { 0, 1 } }); 44 data.Add("4-7", new Int32[][] { new Int32[] { 0, 5 }, new Int32[] { 2, 3 } }); 45 data.Add("4-8", new Int32[][] { new Int32[] { 2, 1 }, new Int32[] { 1, 3 } }); 46 data.Add("4-9", new Int32[][] { new Int32[] { 0, 1 }, new Int32[] { 0, 0 } }); 47 data.Add("4-10", new Int32[][] { new Int32[] { 0, 1 }, new Int32[] { 1, 1 } }); 48 #endregion 49 50 #region T5 51 data.Add("5-6", new Int32[][] { new Int32[] { 0, 1 } }); 52 data.Add("5-11", new Int32[][] { new Int32[] { 1, 0 }, new Int32[] { 1, 2 } }); 53 data.Add("5-12", new Int32[][] { new Int32[] { 0, 1 }, new Int32[] { 1, 1 } }); 54 #endregion 55 56 #region T7 57 data.Add("7-8", new Int32[][] { new Int32[] { 1, 0 }, new Int32[] { 2, 0 }, new Int32[] { 0, 0 } }); 58 data.Add("7-9", new Int32[][] { new Int32[] { 2, 1 }, new Int32[] { 3, 0 }, new Int32[] { 1, 0 } }); 59 data.Add("7-10", new Int32[][] { new Int32[] { 3, 1 }, new Int32[] { 3, 0 }, new Int32[] { 2, 2 } }); 60 data.Add("7-11", new Int32[][] { new Int32[] { 3, 1 } }); 61 data.Add("7-12", new Int32[][] { new Int32[] { 2, 0 } }); 62 #endregion 63 64 #region T8 65 data.Add("8-9", new Int32[][] { new Int32[] { 0, 1 }, new Int32[] { 1, 2 }, new Int32[] { 2, 0 } }); 66 data.Add("8-10", new Int32[][] { new Int32[] { 1, 1 }, new Int32[] { 1, 0 }, new Int32[] { 0, 1 } }); 67 data.Add("8-11", new Int32[][] { new Int32[] { 3, 1 } }); 68 data.Add("8-12", new Int32[][] { new Int32[] { 0, 0 } }); 69 #endregion 70 71 #region T9 72 data.Add("9-10", new Int32[][] { new Int32[] { 3, 0 }, new Int32[] { 1, 0 }, new Int32[] { 0, 0 } }); 73 data.Add("9-11", new Int32[][] { new Int32[] { 1, 0 } }); 74 data.Add("9-12", new Int32[][] { new Int32[] { 1, 0 } }); 75 #endregion 76 77 #region T10 78 data.Add("10-11", new Int32[][] { new Int32[] { 1, 0 } }); 79 data.Add("10-12", new Int32[][] { new Int32[] { 2, 0 } }); 80 #endregion 81 82 #region T11 83 data.Add("11-12", new Int32[][] { new Int32[] { 1, 1 }, new Int32[] { 1, 2 }, new Int32[] { 1, 1 } }); 84 #endregion 85 #endregion 86 return data; 87 }
测试的主要方法是:
1 var team = new List<Int32>(){1,2,3,4,5,6,7,8,9,10,11,12}; 2 var data = GetTestData(); 3 var k3 = CalcLevelScore3(data,team); 4 var w3 = GetEigenVectors(k3); 5 6 var teamOrder = TeamOrder(w3,team); 7 Console.WriteLine(teamOrder.ArrayToString());
排序结果如下:
7,3,1,9,8,2,10,4,6,5,12,11
结果和论文差不多,差别在前面2个,队伍7和3的位置有点问题。具体应该是计算精度的关系如果前面的计算有一些精度损失的话,对后面的计算有一点点影响。
PageRank的一个基本应用今天就到此为止,接下来如果大家感兴趣,我将继续介绍PageRank在球队排名和比赛预测结果中的应用情况。看时间安排,大概思路和本文类似,只不过在细节上要处理一下。
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利。
.NET数据挖掘与机器学习,作者博客: http://www.cnblogs.com/asxinyu
E-mail:1287263703@qq.com

 吾生于甲子年七月,乃荆楚蒲圻(今湖北赤壁)人氏。热衷数学建模与IT技术,虽相貌平平,但勤学苦练,亦收获颇丰!
吾生于甲子年七月,乃荆楚蒲圻(今湖北赤壁)人氏。热衷数学建模与IT技术,虽相貌平平,但勤学苦练,亦收获颇丰!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?