白话贝叶斯理论及在足球比赛结果预测中的应用和C#实现
离去年“马尔可夫链进行彩票预测”已经一年了,同时我也计划了一个彩票数据框架的搭建,分析和预测的框架,会在今年逐步发表,拟定了一个目录,大家有什么样的意见和和问题,可以看看,留言我会在后面的文章中逐步改善:彩票数据框架与分析预测总目录。同时这篇文章也是“【彩票】彩票预测算法(一):离散型马尔可夫链模型C#实现”的兄弟篇。所以这篇文章还有一个标题,应该是:【彩票】彩票预测算法(二):朴素贝叶斯分类器在足球胜平负预测中的应用及C#实现 。
以前了解比较多的是SVM,RF,特征选择和聚类分析,实际也做过一些分类预测的任务。在近1年多的时间中,开始接触足球赛事的预测,刚开始也想使用SVM,Rf来进行预测,一方面效果太差,二是其理论也的确不满足我自己想法的要求。所以也一直在看很多机器学习,数据挖掘的文章。直到看到了贝叶斯的相关文章,在这2个多月的研究中,也积累了很多经验,同时也在使用C#来完成自己的想法,在这个过程中,夹杂很多的知识要点,我自己也很乱,所以趁假期总结一下,由于写太多的公式大家也不一定能耐心看,也不易于理解,所以我把这篇文章叫做“大话贝叶斯”,目的就是尽量通过自己的简单语言和描述(当然如果确实需要学习贝叶斯来解决问题,有些基本概念,如条件概率,边缘分布,分布函数等等还是需要自己搞清楚)让大家更容易的懂得和理解贝叶斯相关理论及其应用。同时我通过实际的C#代码来进行演示,如何来用程序和贝叶斯理论来解决生活中的一些预测问题。在接触所谓的贝叶斯理论和公式之前,先简单了解一下 贝叶斯。
预告,下一篇文章将是本站第100篇正式文章,将与近期发布一个.NET平台机器学习资源汇总的随笔,信息量很大,敬请关注,机不可失失不再来。。。。
1.贝叶斯及其相关的理论
1.1 贝叶斯
1.2 贝叶斯方法的来源
“假设袋子里面有M个白色球,N个黑色球,如果伸手进去摸出一个球,那么摸出白色球的概率是多大?”。从这个问题,贝叶斯自然而然想到了“逆向概率”的问题:“假设我们事先并不知道袋子里面黑白球的个数,而是先闭着眼睛摸出一个(或好几个)球,然后观察这些取出来的球的颜色之后,那么根据取出的球的信息,对袋子里面的黑白球的比例作出什么样的推测”。
1.3 贝叶斯公式与定理
贝叶斯定理是概率论中的一个结论,它跟随机变量的条件概率以及边缘概率分布有关。贝叶斯定理能够告知我们如何利用新证据修改已有的看法。作为一个普遍的原理,贝叶斯定理对于所有概率的解释是有效的;通常,事件A在事件B(发生)的条件下的概率,与事件B在事件A的条件下的概率是不一样的;然而,这两者是有确定的关系,贝叶斯定理就是这种关系的陈述。
设P(A|B)表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。下面就是贝叶斯公式:
![]()
其中的符号定义为:
- P(A)是事件A的先验概率或边缘概率,它不考虑任何B方面的因素。
- P(A|B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A的后验概率。
- P(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。
- P(B)是事件B的先验概率或边缘概率,也作标准化常量(normalizing constant)。
按这些术语,贝叶斯定理可表述为:后验概率 = (相似度*先验概率)/标准化常量。简单的讲,贝叶斯定理是基于假设的先验概率,给定假设条件下,观察到不同数据的概率,提供一种计算后验概率的方法。
贝叶斯决策就是在不完全的信息下面,对部分未知的状态用主观概率来进行估计,然后用贝叶斯公式对发生概率进行修正,最后再利用期望值和修正概率做出最优决策。贝叶斯决策理论方法是统计模型决策中的一个基本方法,其基本思想是:1、已知类条件概率密度参数表达式和先验概率。
2、利用贝叶斯公式转换成后验概率。
3、根据后验概率大小进行决策分类。
贝叶斯的这种基本思想可以在大量的实际案例中得到使用,因为很多现实社会中,积累了很多历史先验数据,想进行一些决策推理,也可以说是预测,就可以按照上面的步骤进行,当然贝叶斯理论的发展中,出现了很多新的推理算法,更加复杂,和面向不同的领域。一般来说,使用贝叶斯推理就是,预测某个事件下一次出现的概率,或者属于某些类别的概率,使用贝叶斯来进行分类的应用应该是最广泛的,很多实际的推理问题也可以转换为分类问题。下面将介绍一些贝叶斯理论的应用例子。
1.4.贝叶斯的类型和应用
在人工智能领域,贝叶斯方法是一种非常有代表性的不确定性知识表示和推理方法。目前贝叶斯的应用非常广泛,如文本分类,问题分类,反垃圾邮件等等,根据问题特征因素的独立性可以分为:朴素贝叶斯和贝叶斯网络。
1.朴素贝叶斯的核心在于它假设向量的所有分量之间是独立的。(这一点在很多复杂的实际情况中都不太容易达到,各个因素直接可能都有一定的关联);
2.贝叶斯网络又叫概率因果网络或者知识图,是相对于朴素贝叶斯而言的。它是一种有方向的无环关系图;贝叶斯网络用图形来表示变量之间的连接个概率关系;它是为了解决不确定性问题和不完整性问题而提出的,在如文字处理,图像处理,决策支持等很多领域都得到广泛的应用。
相关的学术研究进展,主要集中在贝叶斯网络的研究中:
2.朴素贝叶斯分类及例子
贝叶斯分类的基础是概率推理,就是在各种条件的存在不确定,仅知其出现概率的情况下,如何完成推理和决策任务。概率推理是与确定性推理相对应的。而朴素贝叶斯分类器是基于独立假设的,即假设样本每个特征与其他特征都不相关。举个例子,如果一种水果其具有红,圆,直径大概4英寸等特征,该水果可以被判定为是苹果。尽管这些特征相互依赖或者有些特征由其他特征决定,然而朴素贝叶斯分类器认为这些属性在判定该水果是否为苹果的概率分布上独立的。朴素贝叶斯分类器依靠精确的自然概率模型,在有监督学习的样本集中能获取得非常好的分类效果。在许多实际应用中,朴素贝叶斯模型参数估计使用最大似然估计方法,换而言之朴素贝叶斯模型能工作并没有用到贝叶斯概率或者任何贝叶斯模型。尽管是带着这些朴素思想和过于简单化的假设,但朴素贝叶斯分类器在很多复杂的现实情形中仍能够取得相当好的效果。我们先看看一个简单的例子,这里要特别感谢博客园网友:leoo2sk,因为这一节的内容和例子基本都来自他的这篇关于朴素贝叶斯分类器的简单介绍的文章:文章链接,只不过我整理了一下,鉴于文章编辑不方便,我在word中编辑好了,截图上来:
2.1 朴素贝叶斯分类的定义


注意:上述的推导有2个地方比较难懂,1个是把分母p(x)去掉了,应该好理解,分母都一样,比较的时候,直接比较分子就可以了。另外一个是为什么这个公式是成立的:
P(x|yi) = P(a1|yi)*P(a2|yi)*...*P(aj|yi)
这个公式的成立是因为各个属性a1,a2,..,aj都是独立的,才能成立。
根据上述原理,朴素贝叶斯分类主要分为三个阶段:
1.准备阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
2.分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算。
3.应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
至于贝叶斯的其他问题如 估计类别下特殊属性划分的条件概率,以及分类器的评价问题,我认为对于初学者可以暂时跳过,等把基本流程理顺了,懂了,越到更多的问题后再回过头来反思后,按需学习。
2.2 朴素贝叶斯分类实例:检测不真实账号
这个例子完全取自于博客园网友:leoo2sk,的文章“算法杂货铺——分类算法之朴素贝叶斯分类”,因为这个例子很短,而且有现成数据,手动计算量很小,所以我认为非常适合在这里使用。所以冒昧借用一下,同时3.3节中,我会介绍一个更加复杂的朴素贝叶斯分类器的代码。这个例子适合入门,而且最好是动手拿笔在纸上画一画,这样更容易理解,光看公式和数据虽然简单,但未必能了解整个过程,要想自己写出类似的代码,这个过程还是要清楚的,至少我是这么过来的。看看SNS社区不真实帐号问题
对于SNS社区来说,不真实账号(使用虚假身份或用户的小号)是一个普遍存在的问题,作为SNS社区的运营商,希望可以检测出这些不真实账号,从而在一些运营分析报告中避免这些账号的干扰,亦可以加强对SNS社区的了解与监管。如果通过纯人工检测,需要耗费大量的人力,效率也十分低下,如能引入自动检测机制,必将大大提升工作效率。这个问题说白了,就是要将社区中所有账号在真实账号和不真实账号两个类别上进行分类。
下面我们一步一步的使用朴素贝叶斯实现这个过程。
2.2.1 准备阶段:特征属性及划分
1.首先设C=0表示真实账号,C=1表示不真实账号。其他例子中不一定只有2类,也可以是N个类别,只不过计算更复杂,要借助计算机和程序了。
2.找出可以区分真实与不真实账号的特征属性,实际应用中,特征属性的数量可能很多,划分也会更细致。作为例子,这里只用少量的特征属性以及较粗的划分,并对数据做了修改。同时我们也假设这3个属性是独立的,这是使用朴素贝叶斯的基本要求。
选择三个特征属性,在SNS社区中这三项是可以直接从数据库里得到的。粗略划分如下几个区间:
a1:日志数量/注册天数,划分:{a1<=0.05, 0.05<a1<0.2, a1>=0.2}
a2:好友数量/注册天数,划分:{a2<=0.1, 0.1<a2<0.8, a2>=0.8}
a3:是否使用真实头像。 划分:{a3=0(不是),a3=1(是)}
2.2.2 训练阶段:训练样本数据
这里并没有提供实际的数据,而是直接提供了相关整理后的数据,实际例子中,也应该是这样,这些基础数据是可以获取得到的。
使用1万个人工检测过的账号作为训练样本。我们根据上面特征属性的划分计算每个类别的频率以及各个类别在各个条件下的条件概率,以供后面的预测需要。
计算类别频率
P(C=0) = 0.89; 也就说这1万个人工检测过的帐号中,有89%是真实的
P(C=1) = 0.11;人工检测的帐号中,有11%是不真实的
计算条件概率
1)计算已知C=0的条件下,a1属性属于不同划分类别的条件概率
P( a1<=0.05| C=0) = 0.3 ; 在帐号真实的情况下,日志数量/注册天数的值<=0.05的比例有30%
p(0.05<a1<0.2 | C=0) = 0.5 ;
P( a1 >=0.2 | C=0) = 0.2 ;
2)计算已知C=1的条件下,a1属性属于不同划分类别的条件概率
P( a1<=0.05| C=1) = 0.8 ; 在帐号不真实的情况下,日志数量/注册天数的值<=0.05的比例有80%
p(0.05<a1<0.2 | C=1) = 0.1 ;
P( a1 >=0.2 | C=1) = 0.1 ;
3)计算已知C=0的条件下,a2属性属于不同划分类别的条件概率
P( a2 <= 0.1 | C=0) = 0.1 ;
P( 0.1<a2<0.8| C=0) = 0.7 ;在帐号真实条件下,好友数量/注册天数在0.1-0.8范围的比例是70%
P( a2 >= 0.8 | C=0) = 0.2 ;
4)计算已知C=1的条件下,a2属性属于不同划分类别的条件概率
P( a2 <= 0.1 | C=1) = 0.7 ;不真实条件下的帐号,好友数量在这个范围是非常多的
P( 0.1<a2<0.8| C=1) = 0.2 ;
P( a2 >= 0.8 | C=1) = 0.1 ;
5)计算已知C=0的条件下,a3属性属于不同划分类别的条件概率
P(a3 = 0 | C=0) = 0.2 ;
P(a3 = 1 | C=0) = 0.8 ;真实帐号中,使用真实图像的比例是80%
6)计算已知C=1的条件下,a3属性属于不同划分类别的条件概率
P(a3 = 0 | C=1) = 0.9 ;不真实帐号中,使用不真实图像的比例是90%
P(a3 = 1 | C=1) = 0.1 ;
上面这些数据从样本中可以直接统计得到。我也手动对几个条件概率进行了解释,我们假设还是比较符合真实情况的,虽然这个数据是原作者修正过的。
2.2.3 应用阶段:获取分类概率
根据上面贝叶斯公式得到的相关条件概率数据,那么如何来进行一个实际的预测分类。假设我们有一个如下的预测需求:
某帐号使用非真实头像,日志数量与注册天数的比率为0.1,好友数与注册天数的比率为0.2。这些数据是从该数据库直接获取的。
那么这个人的账户是真实账户 还是 不真实账户呢?相应的概率又有多少呢?
直接使用3.1节中的公式,我们计算在当前数据x发生的情况下,属于不同类别的概率,这里有2类,所以要计算一下2个东西:
要计算 P(C=0|x) 和 P(C=1|x)的概率,然后比较大小,取最大值所在的类别就是我们分类的类别。当然我们不一定非要分类,而是可以将求出的概率提供给客户,作为一个参考值等等。而根据3.1节的推导,上述2个值的计算完整公式应该是下面这样的:
P(C=0|x) = P(x|C=0)*P(C=0)
= P(a1|C=0)*P(a2|C=0)*P(a3|C=0)*P(C=0) 根据x的属性范围选择对应的概率
= P(0.05<a1<0.2|C=0) * P(0.1<a2<0.8|C=0)*P(a3=0|C=0) *P(C=0)
= 0.5 * 0.7 * 0.2 * 0.89 = 0.0623
同理:
P(C=1|x) = P(0.05<a1<0.2|C=1) * P(0.1<a2<0.8|C=1)*P(a3=0|C=1) *P(C=1)
= 0.1 * 0.2 * 0.9 * 0.11 = 0.00198
所以根据属性结果和计算,当事件X发生时,属于C=0的概率要高得多,是C=1的30倍。因此我们有理由将这个帐号划分为真实帐号的范畴。
当然实际中的情况可能更加复杂,计算量也更加大,朴素贝叶斯不一定能很好的完成复杂的任务。但有些时候,我们将文件简化为朴素贝叶斯也能收获一些意外的东西。下面我们就来看将贝叶斯分类应用到足球彩票胜平负结果的预测中的情况。纯C#代码。欢迎支持。
3.足球彩票的贝叶斯预测与C#实现
关于足球彩票预测的几点说明:
1.本文分析的足球胜平负比赛的结果预测,采集的数据有近10年的全世界主要联赛;
2.足球彩票的预测方法各种各样,八仙过海各显神通,我这里也只是初步的测试,还有很多工作待完成,有没有完善的地方大家也不要急。
3.足球比赛的结果不仅与球队实力,状态,伤病,彩票,天气,还与场上的重大随机因素有关,因此想完成预测100%准确是一个不可能的任务,我们只是想在欧赔的概率基础上有少部分(5-10%)的提高,这样才可以做很多有意义的事情。
4.准确的说,足球比赛的很多因素都是有关联的,我也只是处于好奇,先使用了朴素贝叶斯来进行了一些工作,同时也在着手开始研究贝叶斯网络的预测方法,比较复杂,还在学习与堆码中。
5.1场足球比赛的基本要点有:主队,客队,比分,结果,至于辅助的因素有很多,如赛前的主客队积分,进球率,失球率,净胜球等等。
6.本文使用的是数据库ORM组件XCode,相关数据查询及操作如果看不懂,可以参考本文博客的文章,点击菜单导航栏的:“X组件”进入目录即可。
我们还是按照前面的步骤来逐步构造一个贝叶斯分类器,在这个过程中,也会讲解相关细节,对于懂足球彩票的朋友,应该好懂,对于不懂,只是想了解的朋友,可以看看思路,了解初步过程,没必要了解细节。
3.1 选择属性与获取训练数据
为了简单起见,我暂时只选取2个属性:主客队总积分的差;主队主场积分与客队客场积分的差;结果有胜平负3种类别,分别记为(3,1,0)。属性集的划分我们在程序中动态获取,这样可以计算各种不同划分的准确率,更加方便,这和上面的例子是不一样的。当然上面的例子也可以这样做,只是一个小的技巧而已。
在这个测试过程中,我们是选取前N轮的比赛场次数据,然后对后M轮的结果进行预测。所有首先要从数据库获取贝叶斯的训练数据,看代码:

/// <summary>获取指定赛季,指定轮之间的比赛数据作为贝叶斯分类的训练集合</summary> /// <param name="seasonId">赛季编号</param> /// <param name="roundIdL">起始轮号</param> /// <param name="roundIdH">截至轮号</param> /// <returns>返回贝叶斯需要的数据格式类型(自定义的)</returns> static List<BayesDS> GetDataBySeason(Int32 seasonId,Int32 roundIdL,Int32 roundIdH) { var season = SeasonInfoDc.FindBySeasonId(seasonId); GameScreenDc.SetDbConnName(season.EventName); EventRanking.SetDbConnName(season.EventName); //获取所有场次 var games = GameScreenDc.FindAll(GameScreenDc._.SeasonId == seasonId & GameScreenDc._.RoundId >= roundIdL & GameScreenDc._.RoundId <= roundIdH, GameScreenDc._.RoundId.Asc(), null, 0, 0); //循环每场进行查找,组合 List<BayesDS> res = new List<BayesDS>(); foreach (var item in games) { //查找当前主客球队,上一轮后的积分对象 var home = EventRanking.Find(EventRanking._.SeasonId == seasonId & EventRanking._.TeamId == item.HomeId & EventRanking._.RoundId == item.RoundId -1); var visit = EventRanking.Find(EventRanking._.SeasonId == seasonId & EventRanking._.TeamId == item.VisiteId & EventRanking._.RoundId == item.RoundId -1); double[] temp = new double[]{(double)(home.TotalScore - visit.TotalScore)/*总积分差*/, (double)(home.HomeScore - visit.VisitScore)/*主队主场积分-客队客场积分*/,
item.Result};
res.Add(BayesDS.Create(item,temp));
}
return res;
}
虽然只有2个参数,也需要进行划分,由于积分都是正整数,而且一般球队的积分差距不是特别大,为了测试不同划分的情况,我们选择手动输入划分点,进行属性的划分,下面是函数,根据输入的点,自动确定划分区间的:
1 /// <summary>获取属性分割的区间,根据断点确定 ,data应该是从小到大的点排列</summary> 2 /// <returns></returns> 3 static double[][] GetRulesByPoint(List<double> data) 4 { 5 double[][] res = new double[data.Count +1][]; 6 res[0] = new double[] {-1000,data[0] };//下限-1000,不可能达到 7 for (int i = 0; i < data.Count-1; i++) 8 { 9 res[i + 1] = new double[] { data[i], data[i +1] }; 10 } 11 res[data.Count ] = new double[] {data[data.Count-1],1000 };//上限足够大,不可能达到 12 return res; 13 }
3.2 建立贝叶斯分类预测模型
有了数据和思路后,下一步就是要在C#中建立一个贝叶斯分类器,传递数据,和划分集然后才能进行预测。模型的定义如要有以下几点:
1.几个基本的属性。注意字典存储条件概率,直接全部计算,对数据量大的情况,可能会吃不消,应该按需计算比较好。不过这里是测试,无所谓了。先看看效果才行。
1 #region 属性 2 /// <summary>测试数据:分别为属性值,最后1个为结果类别</summary> 3 public List<double[]> data { get; set; } 4 /// <summary>对应的属性划分集合</summary> 5 public List<double[][]> rules { get; set; } 6 /// <summary>所有的类别</summary> 7 public List<Int32> C { get; set; } 8 /// <summary>类别的比例字典</summary> 9 public Dictionary<Int32,double> C_Ratio { get; set; } 10 /// <summary>条件概率字典</summary> 11 public Dictionary<String, double> ConRatio { get; set; } 12 #endregion
2.模型构造函数,主要是模型的初始化。这里我直接写好了,在初始化的时候就把数据和划分方式给模型,进行相关条件概率的计算,相关的注释已经在代码里面了,有几个注意的地方:条件概率在字典中的key是有格式的,后续也是根据这个来访问。
1 #region 构造函数,初始化 2 public BayesianClassifier(List<double[]> data, List<double[][]> rules, List<Int32> C) 3 { 4 this.data = data; 5 this.rules = rules; 6 this.C = C; 7 Int32 N = data[0].Length - 1;//属性个数 8 if (N != rules.Count) throw new Exception("属性划分集与属性个数对应错误"); 9 10 //先计算样本中各类别的比例,保存在dic中 11 C_Ratio = C.ToDictionary(n => n, n => (double)data.Where(k => n == k[N ]).Count() / (double)data.Count); 12 13 //计算特征属性划分概率,存储在字典中 14 ConRatio = new Dictionary<String, double>(); 15 for (int i = 0; i < C.Count; i++)//循环类别属性 16 { 17 var temp1 = data.Where(n => n[N ] == C[i]);//当前类别的情况 18 //循环属性 19 for (int j = 0; j < N; j++) 20 { 21 // 循环该属性的所有划分集 22 for (int k = 0; k < rules[j].Length; k++) 23 { 24 String key = String.Format("{0}{1}{2}", j,k,C[i] );//属性位置-划分位置-类别 25 //计算当前的条件概率,判断data第j个属性,在等于C[k]的结果中,满足当前属性划分上下限的比例 26 var temp2 = temp1.Where(n => n[j].IsInRange(rules[j][k][0], rules[j][k][1])); 27 double value = (double)temp2.Count() / (double)temp1.Count(); 28 ConRatio.Add(key, value); 29 } 30 } 31 } 32 } 33 #endregion
3.足球比赛场次胜平负结果的分类预测
预测的过程也和第2节的例子一样,只不过是程序化了。预测的方法是每次一条记录的数据,并计算属于每一类的概率,所以返回的是一个字典,key为类别,value为概率。具体方法如下所示:
1 /// <summary>分类:key为类别,value为概率</summary> 2 public Dictionary<Int32, double> ClassificationForDic(double[] data) 3 { 4 //先要计算每个当前属性的划分集合的顺序,找出每个属性所属于的区间 5 List<Int32> attIdList = new List<int>(); 6 for (int i = 0; i < data.Length -1; i++) 7 { 8 for (int j = 0; j < rules[i].Length ; j++) 9 { 10 if (data[i].IsInRange(rules[i][j][0], rules[i][j][1])) attIdList.Add(j); 11 } 12 } 13 14 Dictionary<Int32, double> res = C_Ratio.ToDictionary(n=>n.Key,n => 15 { 16 double multip = n.Value; 17 for (int i = 0; i < data.Length -1; i++) 18 { 19 for (int j = 0; j < attIdList.Count; j++) 20 { //属性位置-划分位置-类别 21 String key = String.Format("{0}{1}{2}",i,attIdList[j],n.Key); 22 if (!ConRatio.ContainsKey(key)) multip = 0 ; 23 else multip *= ConRatio[key]; 24 } 25 } 26 return multip; 27 }); 28 return res; 29 }
返回这个字典后,要计算概率最大的结果也非常容易,直接对字典进行排序就可以了。具体代码看总的cs文件。
3.3 贝叶斯预测算法的测试
基本过程和代码完成了,我们采集5大联赛(西甲,德甲,英超,意甲,法甲)的数据进行测试,看看贝叶斯预测算法的准确性如何。测试的核心代码如下:
1 public static void TestBySeason() 2 { 3 //五大联赛的赛季编号 4 List<Int32> seasonList = new List<int>() {6000,4866 };//4865,16136,4863,4861,5994 5 //先初始化联赛排名 6 seasonList.ForEach(n => EventRanking.UpdateHisSeason(n)); 7 int trainRoundL = 8;int trainRoundH = 25;//训练集的起至轮数 8 int testRoundL = 26; int testRoundH = 35;//测试集的起至轮数 9 List<double[]> trainData = new List<double[]>();//训练集 10 foreach (var item in seasonList) 11 { 12 var temp = GetDataBySeason(item,trainRoundL,trainRoundH).Select(n=>n.Data).ToList(); 13 trainData.AddRange(temp); 14 } 15 //然后采集测试集的数据,标签用于对比,测试时是不用的,只是最后对比使用 16 List<BayesDS> testData = new List<BayesDS>();//训练集 17 foreach (var item in seasonList) 18 { 19 var temp = GetDataBySeason(item, testRoundL, testRoundH); 20 testData.AddRange(temp); 21 } 22 while (true)//循环根据不同属性划分进行测试 23 { 24 Console.Write("总积分差 属性分割集(参考:-8, -2, +5, 10):"); 25 var t1 = Console.ReadLine().StringToDoubleArray().ToList(); 26 Console.Write("主客积分差 属性分割集(参考:-5, -1, +5):"); 27 var t2 = Console.ReadLine().StringToDoubleArray().ToList(); 28 List<double[][]> rules = new List<double[][]>(); 29 rules.Add(GetRulesByPoint(t1));//总积分差 参考:{ -8, -2, +5, 10 }) 30 rules.Add(GetRulesByPoint(t2));//主客积分差 参考:{ -5, -1, +5 }) 31 //初始化模型 32 BayesianClassifier bayesMode = new BayesianClassifier(trainData, rules, new List<int>() { 3, 1, 0 }); 33 var testResuult = testData.Select(n => 34 { 35 var res = bayesMode.Classification(n.Data);//预测结果 36 }).ToList(); 37 } 38 }
1.数据集采用2013-2014赛季,欧洲5大联赛的比赛,我们选取前8-25轮的场次作为训练集,26-35轮的比赛作为测试集合(考虑到联赛初期和末期的不稳定性)。

我们可以看到,针对不同的划分集,指数1的准确率都超过了57%,比正常的欧赔指数45-50%,高出了5-10%。结果还是比较可观的。但是我们也看到指数3的比例都有22%,说明对于一些特别冷门的场次,算法还是做不到,这些特殊情况不是简单2个因素就可以左右的,因此还有待对模型更深一步的研究,找出这些特别冷门场次的一些共同因素,从而进行一定程度的防范,减少指数3的比例,从而提高指数1,2的比例。
2.同时,我们对上一步的测试方法进行了一定的更改,将预测结果和欧赔bet 365指数1结果一致的比赛拿出来进行统计;将预测结果和欧赔bet 365指数1,2结果一致的比赛进行统计:
同样是上述481场比赛进行筛选和属性划分,我们对实际的准确率进行比较:
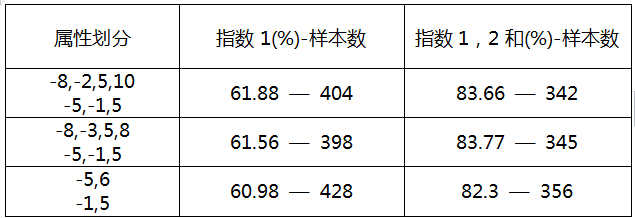
通过结合欧赔指数,进行一定的过滤后,预测的整理准确率有了一定的提高。这个结果还是很理想的,懂的人应该知道里面的含义。所以贝叶斯理论的确是非常强大,当然这里只采用了2个因素,而且本身是关联的,但实际中没有考虑关联性,看成了朴素贝叶斯,必定会对问题结果产生一定的影响。这和我解决问题的思路有关系,先简单,后复杂,逐步过渡,延伸。。
4.参考文献与资料
博客园很多网友多对伪原创网站抓取文章做出过防范对策,我也发现这个问题,所以也想出了2个办法。
1.在博客正文加上本文的链接,当然部分网站会无良的把所有链接给去掉,但可以防范部分,另外水印这些也有点用,只是比较麻烦,懒得搞
2.也是我的必杀技,资料不直接开放下载,而是在文章发表后的12-24小时后再把链接发出来,或者通过邮箱发送。因为网站抓取一般都是对首页文章进行抓取,在发表12-24小时后,在进行抓取的频率就少多了。鉴于此,本文的资源将在发表后的24小时公开百度网盘的下载链接,所以大家可以关注博客,或者留下邮箱,在24小时后,统一邮箱发送。打包的资料文章有:
上述论文由于涉及到版权,已经取消下载取消下载,如需要请留言或者邮件索取。
请到原始网页:http://www.cnblogs.com/asxinyu/p/4394156.html 进行下载。
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利。
.NET数据挖掘与机器学习,作者博客: http://www.cnblogs.com/asxinyu
E-mail:1287263703@qq.com

 吾生于甲子年七月,乃荆楚蒲圻(今湖北赤壁)人氏。热衷数学建模与IT技术,虽相貌平平,但勤学苦练,亦收获颇丰!
吾生于甲子年七月,乃荆楚蒲圻(今湖北赤壁)人氏。热衷数学建模与IT技术,虽相貌平平,但勤学苦练,亦收获颇丰!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· 展开说说关于C#中ORM框架的用法!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?