
使用SQL Server分析服务定位目标用户
如何定位目标用户,在任何一个业务单元中都是一个很重要的话题,尤其在预算有限的情况下,如何获得活动的最大收益,目标用户的定位都是很重要的手段。
本文将介绍如何通过SQL Server分析服务(SSAS)中的数据挖掘功能根据历史记录信息来定位目标用户。
微软的SQL Server为数据平台提供了一套完整的解决方案,他不只是一个数据引擎,也提供了很多数据工具和服务,借助其中的分析服务,结合业务系统中的海量历史数据信息,SQL SERVER就可以帮助我们发现其中的模式和规律,从而对目标数据做预测分析。
在实际中,不同的挖掘模型适用于不同的问题场景,同一个问题模式下可能有多个模型都适合解决这个问题,这样对于问题的解决来说就多了很多可对比性,从而我们可以根据每个模型预测的准确程度选择一个最优的模型。
在本文的目标用户定位的问题上,采用三种挖掘模型进行比较,分别是决策树,贝叶斯和聚类算法。
本文使用的SQL SERVER版本是2012,示例数据库是Adventure Works的数据仓库,关于如何获取以及部署这个示例数据仓库,可以参考我的这篇随笔:
http://www.cnblogs.com/aspnetx/archive/2013/01/30/2883831.html
首先,建立数据挖掘项目,打开SQL DATA TOOLS,也就是Visual Studio 2010的那个Shell。
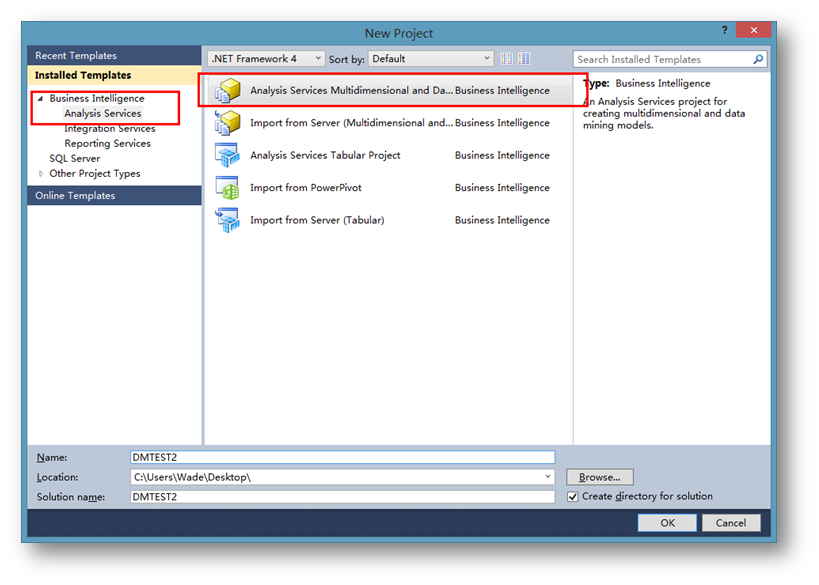
新建一个多维和数据挖掘的分析服务项目。
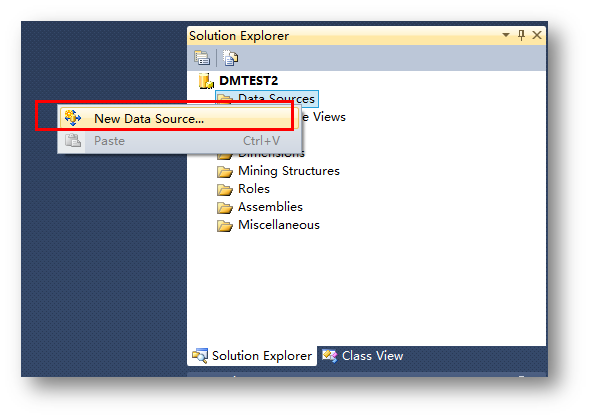
项目建立完毕后,新建数据源连接。
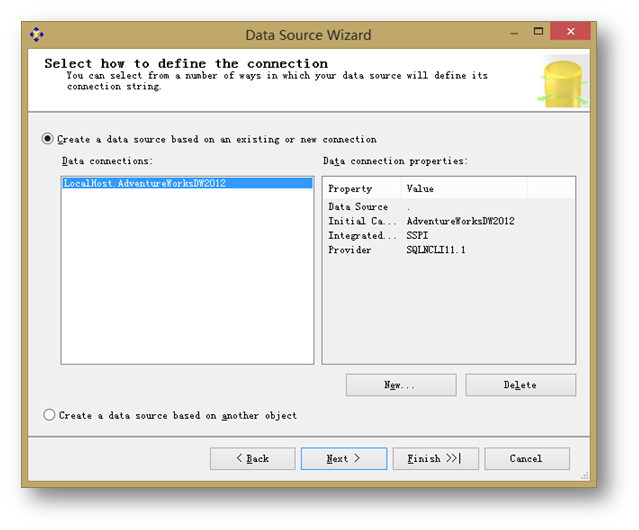
选择部署好的Adventure Works DW连接。
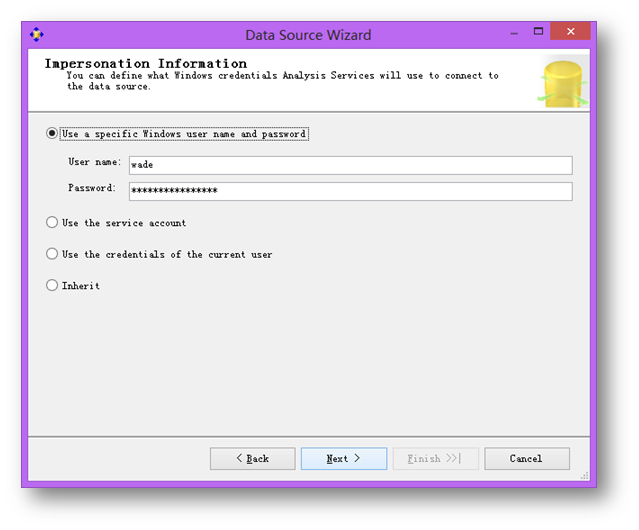
输入模拟身份信息,本演示用为了简便直接使用本地管理员账户(当然生产环境中是不建议这么做的)。
为数据源连接起名。
新建数据源视图。
选择刚才建立的数据源连接。
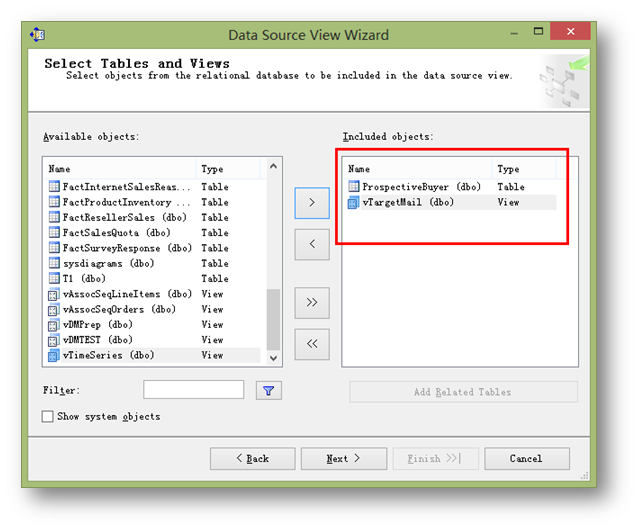
从左边可选对象列表中选取两个对象,一个是表ProspectiveBuyer,一个是视图vTargetMail。

为数据源视图取名。
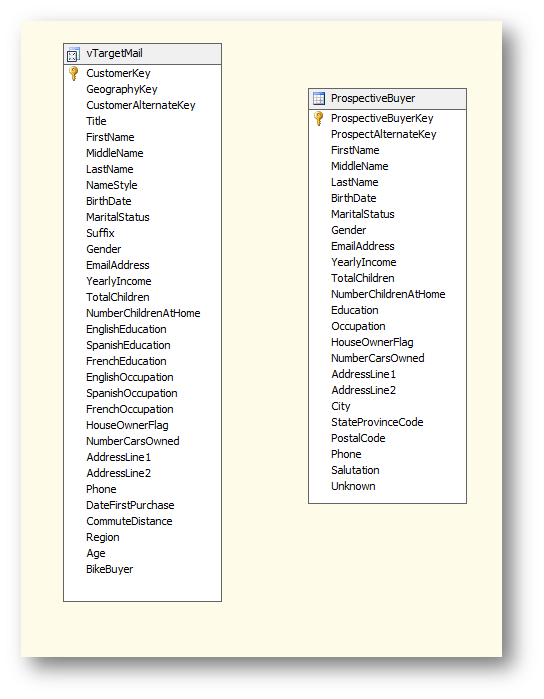
可以在数据源视图中看到添加进来的两个表。
其中左面的表是在数据仓库经过整合的一批数据,用来训练和验证模型。右面的表是待预测的表,将在模型生成完毕后对这个表里的数据进行预测。

新建挖掘结构。

同时为挖掘结构指定一个挖掘模型,这里选择决策树模型。需要留意的是,一个挖掘结构可以有很多挖掘模型,不过在通过工具创建一个挖掘结构的时候需要指定一个挖掘模型。

选择刚才建立的数据源视图。
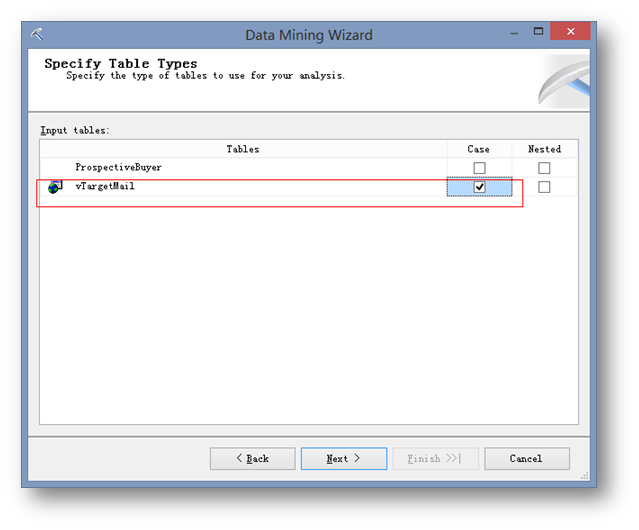
选取事例表vTargetMail。ProspectiveBuyer是后续要用来进行预测的,所以这里先忽略这个表。
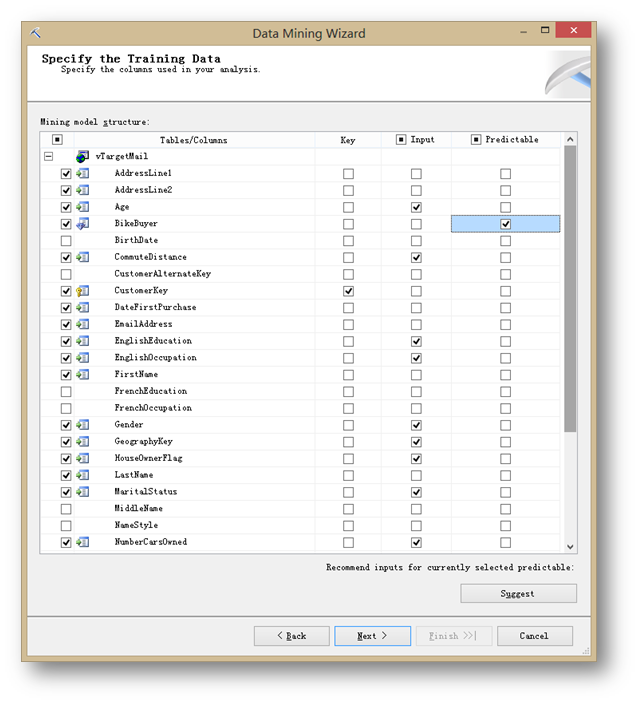
首先,在Key列一栏选择CustomerKey,用来指定键列。
然后选择输入列:
Age
CommuteDistance
EnglishEducation
EnglishOccupation
Gender
GeographyKey
HouseOwnerFlag
MaritalStatus
NumberCarsOwned
NumberChildrenAtHome
Region
TotalChildren
YearlyIncome
最后,选中以下列表左侧需要选择的列。这些列不作为模型的考虑元素,但是会用在模型的钻取结果上。
AddressLine1
AddressLine2
DateFirstPurchase
EmailAddress
FirstName
LastName

确认内容类型,这里有两处需要更改,一处是Geography Key改为Discrete离散型的,以及BikeBuyer改为discrete离散型的。
关于内容类型的参考:
http://technet.microsoft.com/zh-cn/library/ms174572
关于数据类型的参考:
http://technet.microsoft.com/zh-cn/library/ms174796
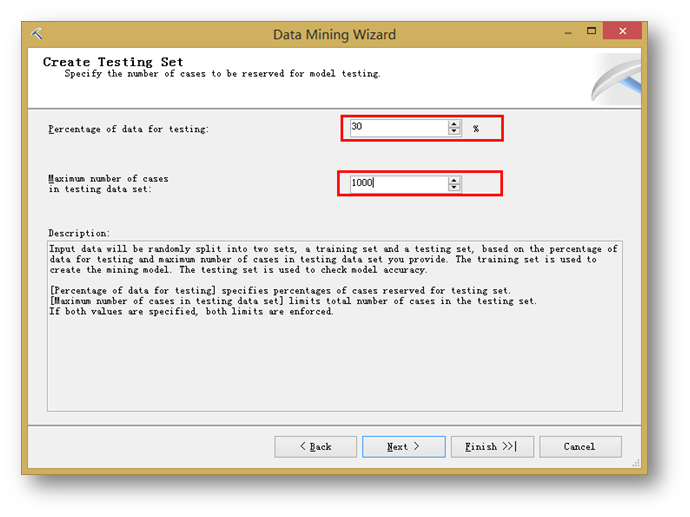
设定测试数据的比例。也就是说,在所有的历史数据中,这里将决定,有多少数据用来训练模型,有多少数据用来对模型进行准确度测试。
这里可以指定百分比或者最大测试事例数,当两个都有配置的时候,系统会取最小测试事例集合的配置。

为挖掘结构和挖掘模型取名,并且选中允许钻取的选项。
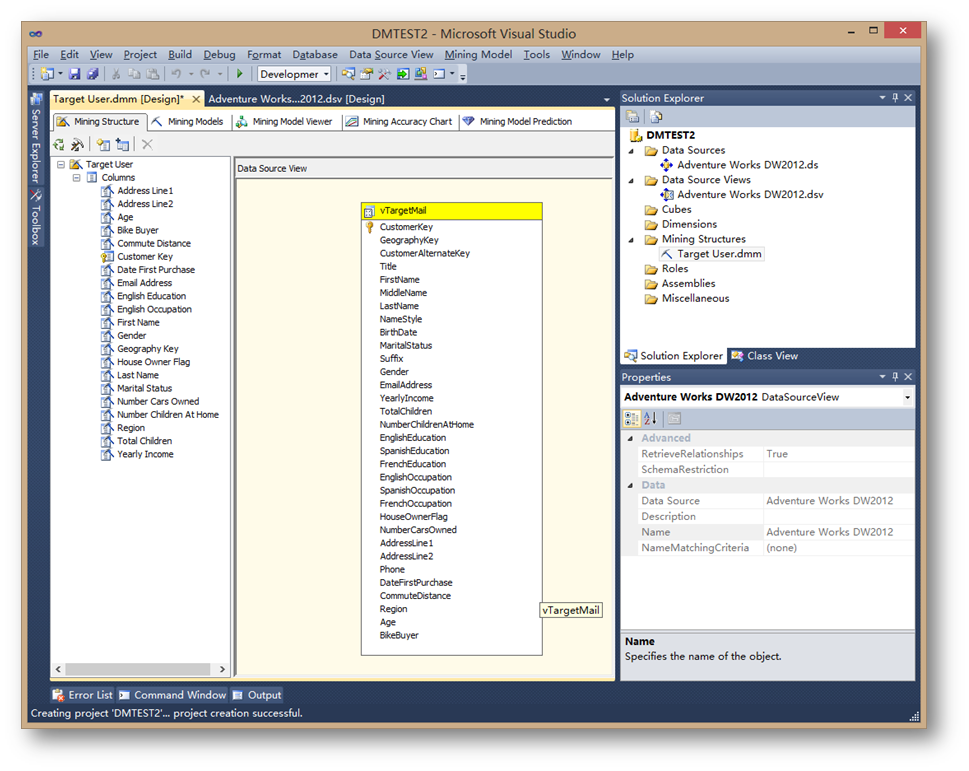
至此一个决策树模型生成完毕。
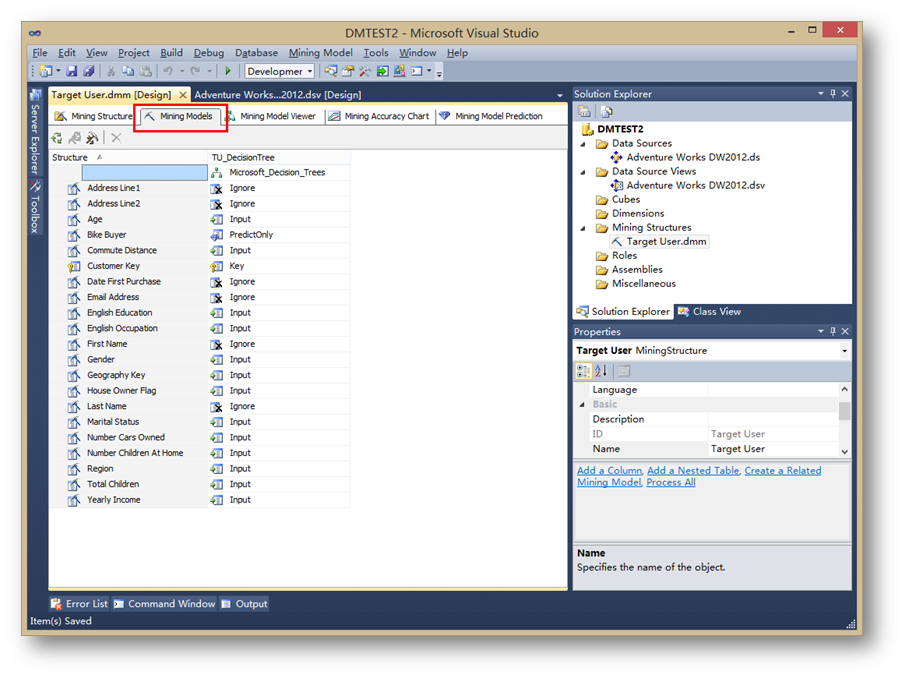
点击挖掘模型标签,可以更直观的看到挖掘结构和挖掘模型的结构。
接下来根据已经创建好的挖掘结构,创建其它挖掘模型。
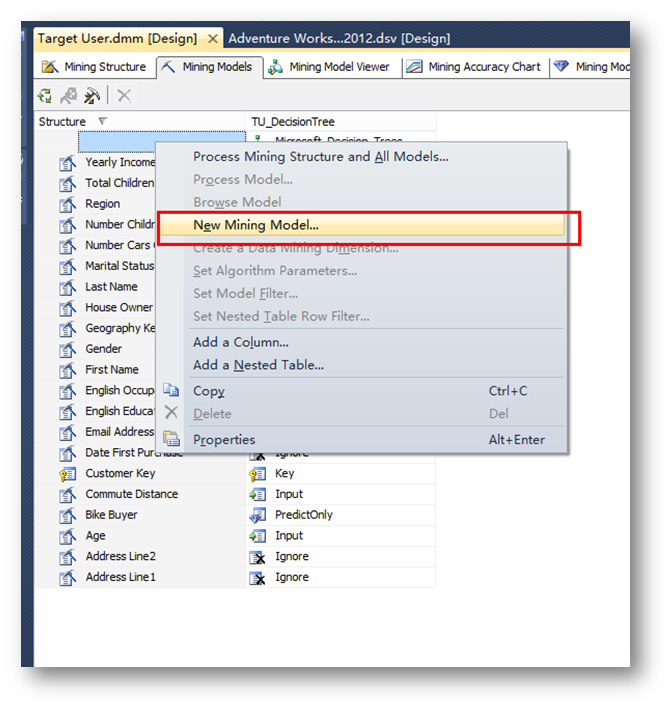
右键点击挖掘结构,选择新建挖掘模型,为挖掘结构添加另外几个模型用于对预测结果进行比对。
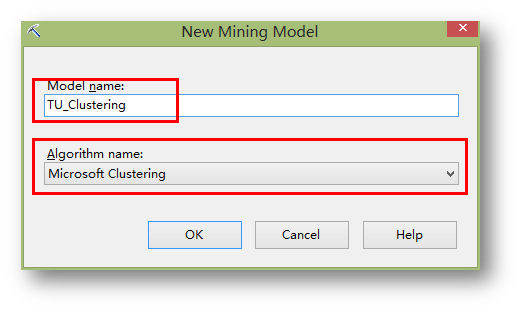
为挖掘模型取名,并在算法中选择聚类算法。

按照同样的方法,再创建一个贝叶斯模型。
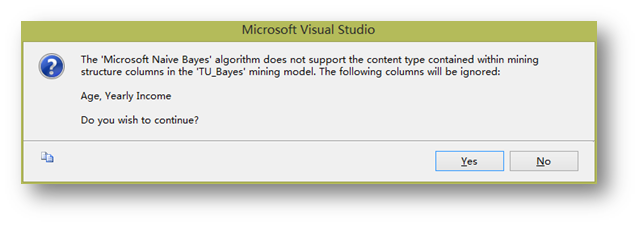
由于贝叶斯模型不支持连续变量,所以这里会出现提示。继续即可。

可以看到创建好的三个模型,并且每个模型中各个字段的用法。
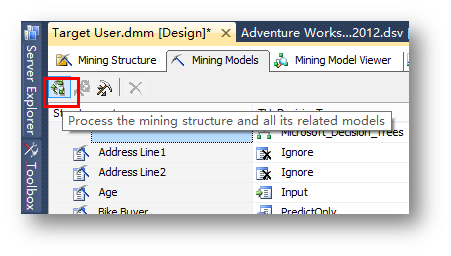
点击工具栏上的处理按钮,对模型进行部署和处理。
第一次部署或者项目有过修改都会出现这样一个提示,点Yes。
处理界面,直接点击Run开始处理。
处理过程中,处理的时间取决于训练数据的大小以及机器的硬件性能。当然对于Adventure Works的这个示例来说,通常就是10多秒的事。
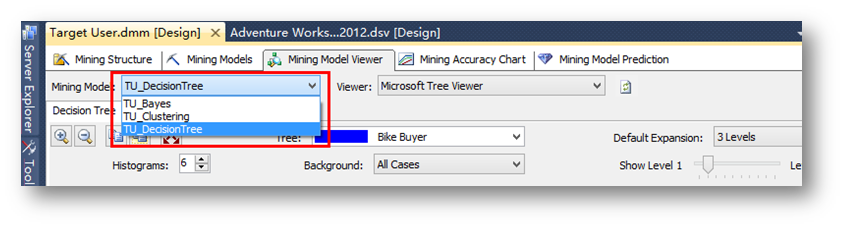
挖掘结构处理完毕后,下面来简单浏览一下各个挖掘模型。点击挖掘模型浏览器标签。然后在Mining Mode中选定TU_DecisonTree决策树模型。
可以看到,Microsoft 决策树算法通过在树中创建一系列拆分来生成数据挖掘模型。 这些拆分以"节点"来表示。 每当发现输入列与可预测列密切相关时,该算法便会向该模型中添加一个节点。 离根节点距离越近的属性,说明这个属性的变化对预测列的影响变化更大。
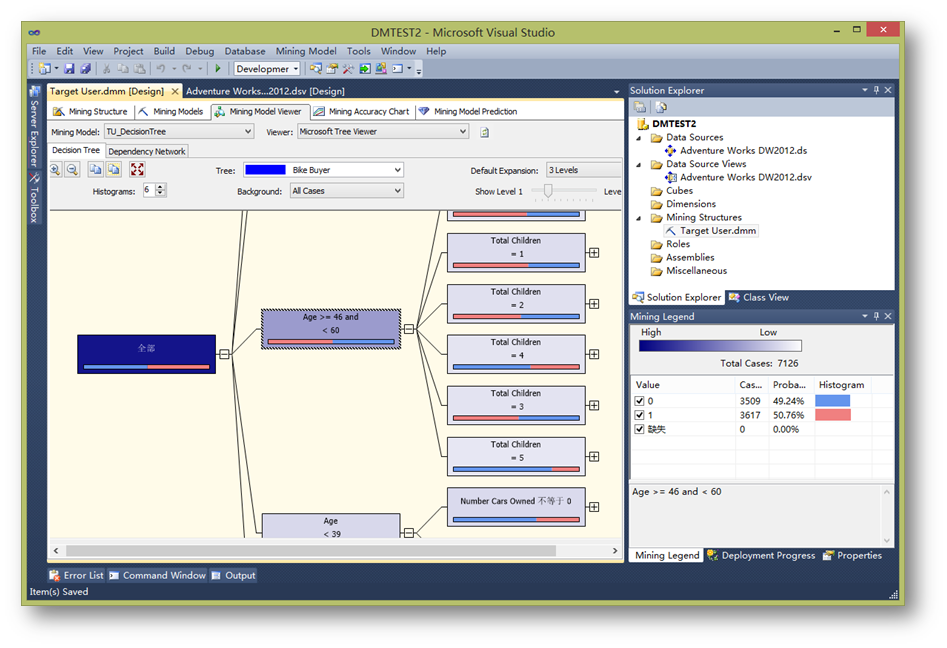
右键每一个节点,可以钻取到详细信息。

选择第一项,查看模型包含的列:
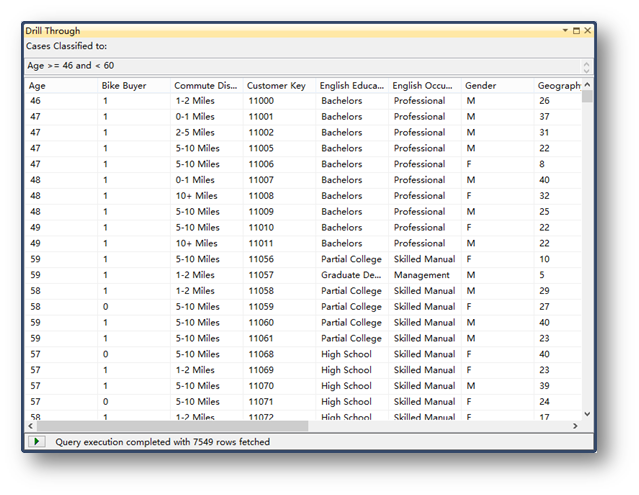
也可以选择钻取模型和挖掘结构模型的信息,这样前面在左侧定义的列就会显示出来,方便定位详细信息。

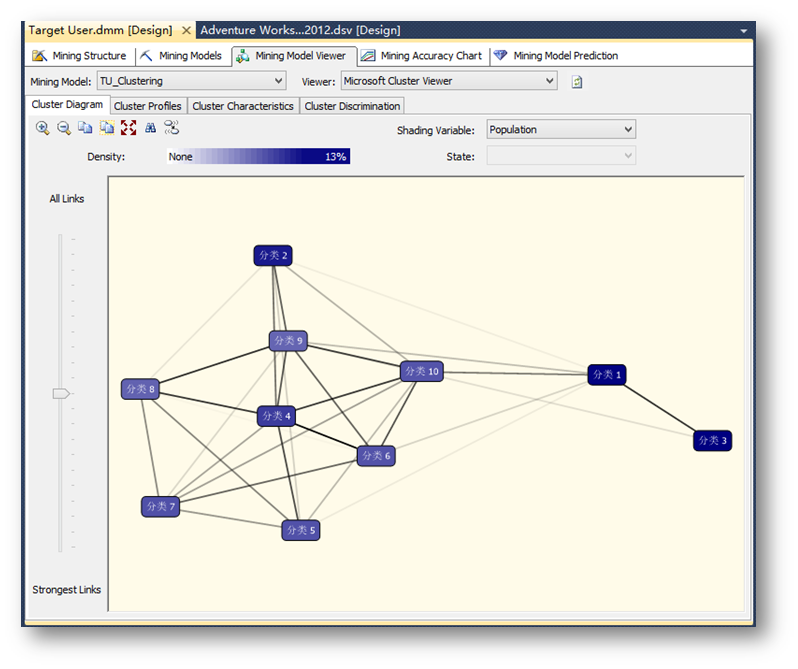
浏览聚类分析模型,这里可以看到各个分类之间的关系,通过拖动左面的滑块可以看到相互之间关系的强弱。
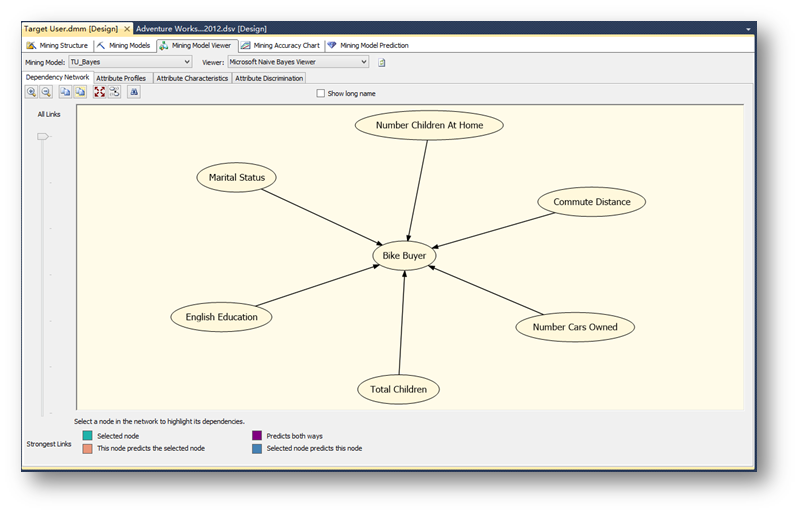
浏览贝叶斯模型,在途中可以看到是否是目标客户,模型分析出的几个关键因素,也可以通过左边的话快查看这些因素有强到弱的关系。
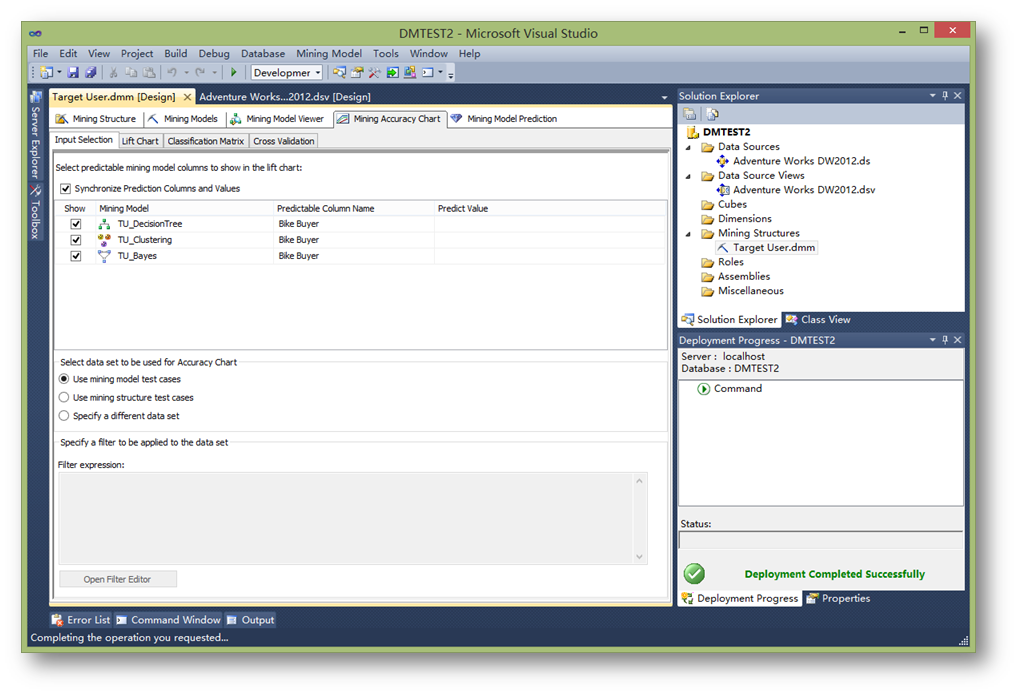
接下来,将对各个模型进行测试。虽然对于一个问题可以应用很多模型来解决,但往往只有一个才是最优的,效率最高的。对模型的测试主要是用到提升图。
首先,点击Mining Accuracy Chart选项卡,确定用于提升图的数据是Use mining model test cases。
然后点击Lift Chart标签,系统会显示根据测试数据生成的提升图。
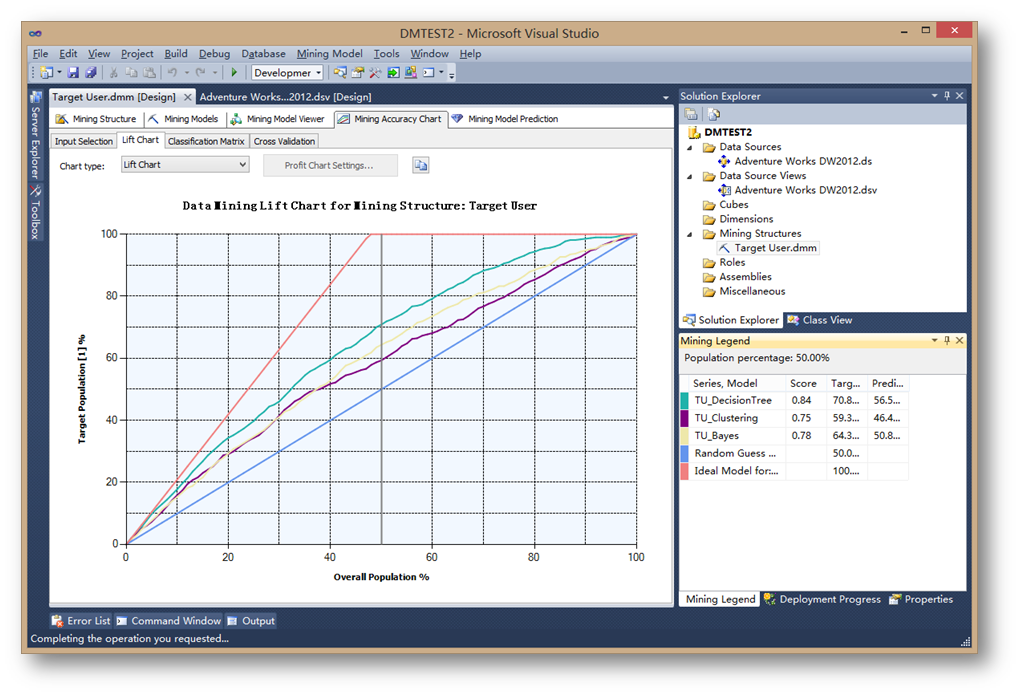
从提升图的结果来看,决策树的预测性能明显高于其它模型。
关于提升图,首先,对角线是随机概率的结果,最上面的线是最佳理想的预测结果,所以实际的模型预测效率都是介于这两条线之间。
关于提升图的更多信息可以参考微软的这篇文档:
http://technet.microsoft.com/zh-cn/library/ms175428
在已经确定决策树模型是最优模型之后,如果还希望根据性别的不同分析购买风格的差异,可以创建筛选模型。
首先,回到Mining Models选项卡,右键单击创建好的决策树模型,选择新建模型。
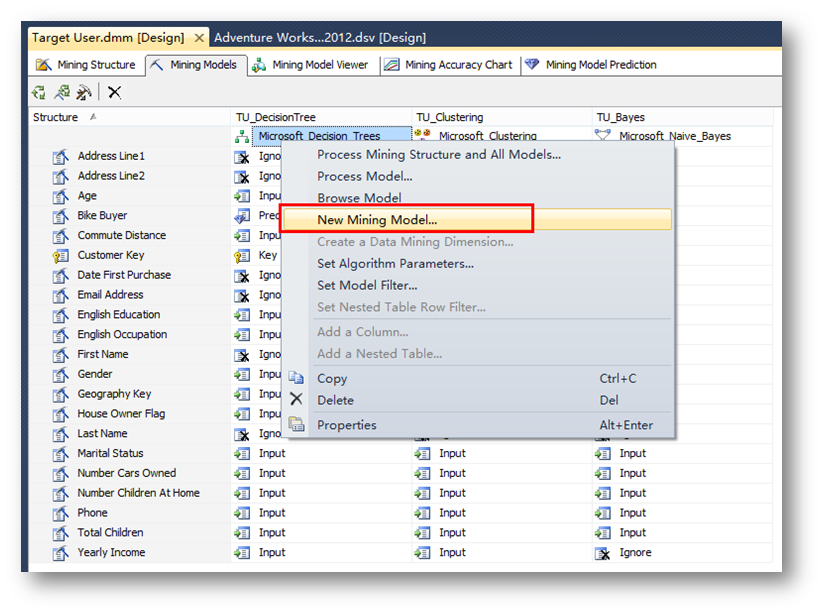
在弹出的界面中,给新模型取一个名:TU_DecisionTree_Male,算法选择Microsoft 决策树。
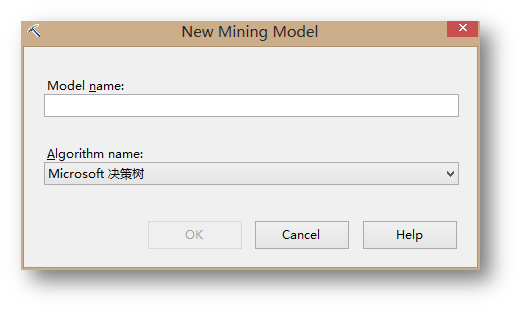
点击OK完成后,右键点击新建的模型,选择Set Model Filter…
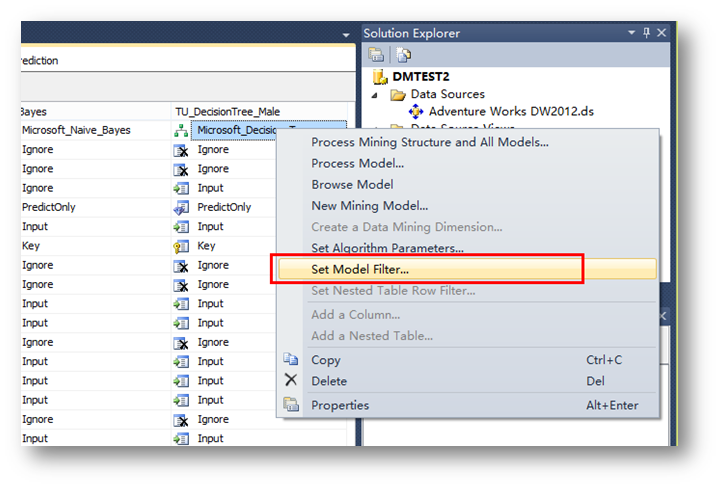
在Conditions中选择Gender = M。
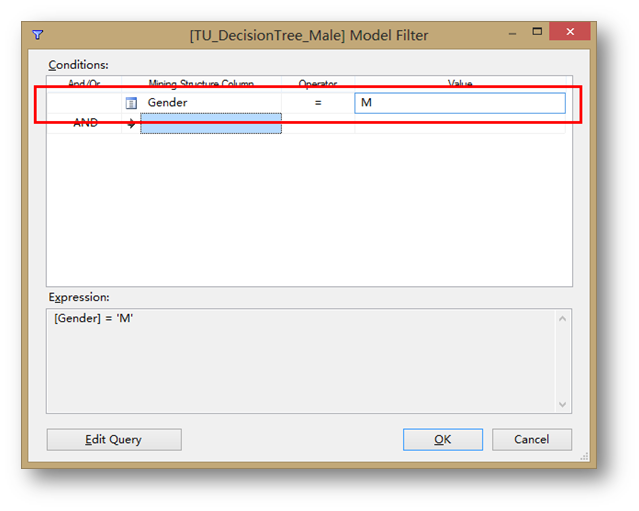
按照同样的方法,建立另外一个TU_DecisionTree_Female,Model Filter中 Conditions选择Gender = F。

创建完两个新筛选模型后,点击提升图。将Predict Value设置成1,以验证目标客户预测的性能。

点击Lift Chart查看提升图。
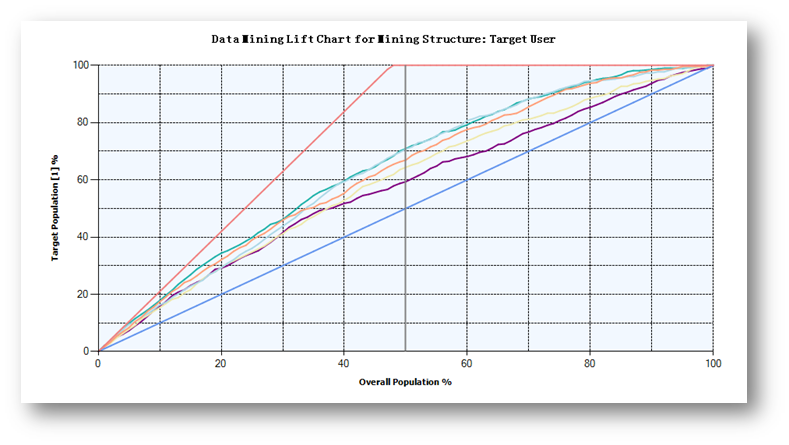
可以看到,三个决策树模型的预测性能都是高于其它模型的。
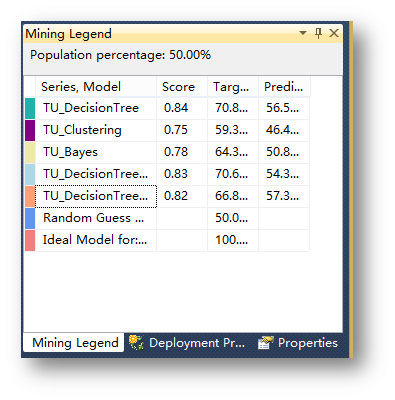
模型测试完毕,可以判断决策树是基于定位目标用户最佳的预测模型。接下来是用决策树模型对一个表中的数据进行预测。
首先,选择Mining Model Prediction选项卡。
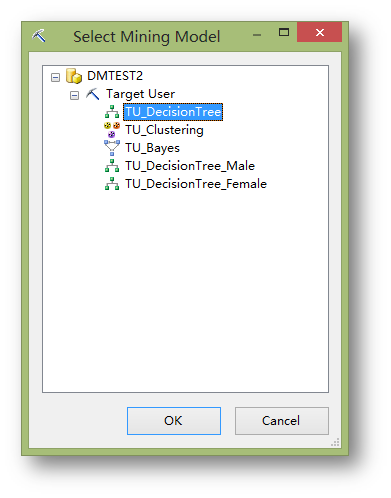
点击Select Model…选择前面建立的TU_DecisionTree模型。
然后点击Select Case Table…选择实例表ProspectiveBuyer。
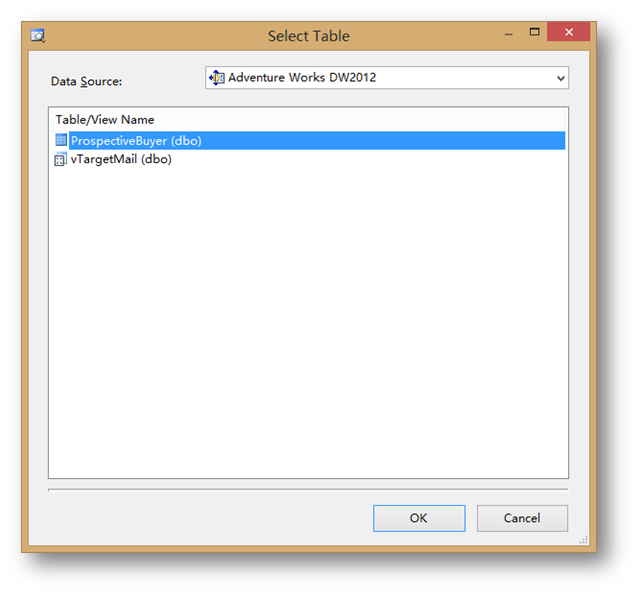
点击OK后,可以看到在表ProspectiveBuyer中并没有对应的Age列,而这一列是在预测过程中需要参考的一个重要列,所以回到数据源视图,在ProspectiveBuyer表里加入一个计算列。
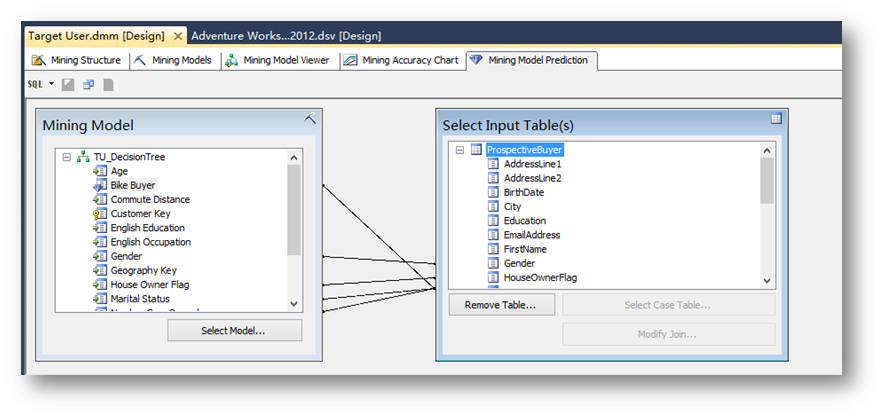
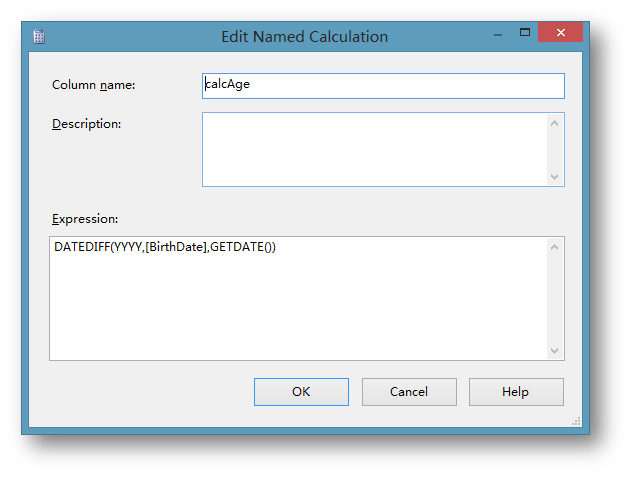
右键单击表ProspectiveBuyer点击New Named Calculation…

在弹出的界面中为计算成员取名并填写计算公式:
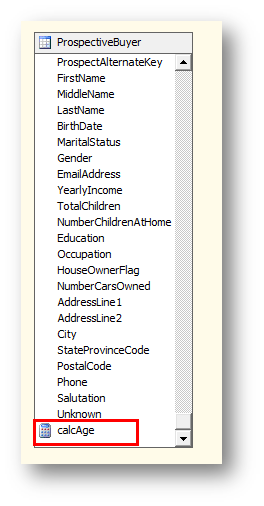
可以看到新建的列已经添加到字段列表的末尾。在数据源视图中添加的列可以理解为在物理视图和表上,在项目里建立的视图,所以实际上并没有对实际的表或者视图的结构进行更改。
然后回到预测界面,将Mining Model中的Age列拖拽到Select Input Table(s)中刚建立好的CalAge列。
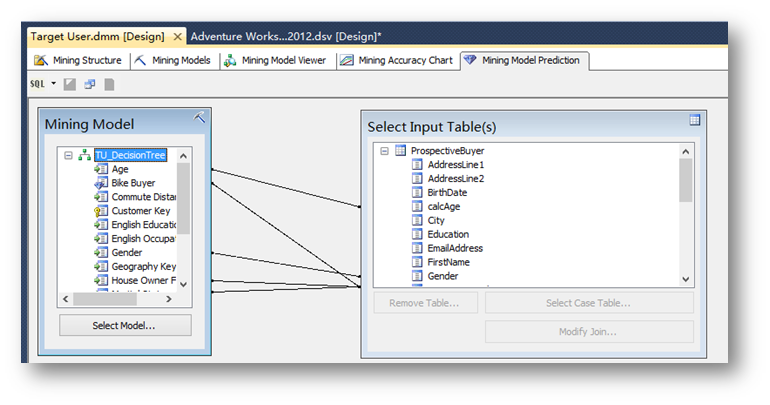
点击界面左上角的小图标,切换到Design设计模式。
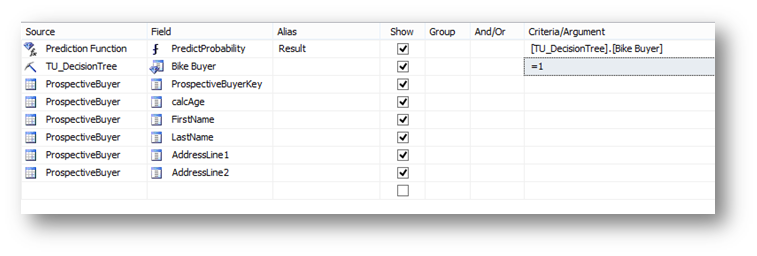
在下方的网格列表中,Source选择Prediction Function。

指定一个别名Result,然后在Criteria/Argument中,把Bike Buyer字段从上方的Mining Model中拖拽过来。

然后在下方的网格列表中,Source选择TM_DecisionTree,Filed选择Bike Buyer。最后在下面几行中Source指定ProsepectiveBuyer然后Filed中依次指定calAge, FirstName, LastName和AddressLine1以及AddressLine2。
点击工具图标切换到Result结果视图。
可以看到目标数据的预测结果。

另外,也可以切换到Query模式查看系统生成的DMX语句。
至此,通过建立数据挖掘模型,并且选择最优模型之后,对目标用户列表里的数据进行了预测,从而帮助用户更有效率的确定了目标潜在用户。这样的预测在某些场景下是非常有用的,比如企业最近要做一个活动推广,但是费用成本不足以给所有的客户进行推广,所以这个时候决定给哪些客户来推送推广服务就可以有效的降低推广活动的成本并且获取最高的推广收益。
以上,如何使用SQL Server分析服务来定位目标用户介绍完毕。关于如何将这个数据挖掘的功能加入到现有的项目中,可以参考我写的另外一篇关于购物篮推荐的系列随笔,里面会有介绍如何构建Web服务以及编写简单的应用访问这个服务从而使用数据挖掘的功能。
http://www.cnblogs.com/aspnetx/archive/2013/02/25/2931603.html
关于分析服务更多内容,欢迎访问我的博客http://aspnetx.cnblogs.com
微软文档中关于本文中提到的模型算法的参考:
决策树模型:http://technet.microsoft.com/zh-cn/library/ms175312.aspx
贝叶斯模型:http://technet.microsoft.com/zh-cn/library/ms174806.aspx
聚类分析模型:http://technet.microsoft.com/zh-cn/library/ms174879.aspx
如果您有任何问题,欢迎在此篇回帖或者给我留言。
---------------------------------------------------------------
aspnetx的BI笔记系列索引:
使用SQL Server Analysis Services数据挖掘的关联规则实现商品推荐功能
---------------------------------------------------------------

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,携手博客园推出1Panel与Halo联合会员
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步