
使用SQL Server Analysis Services数据挖掘的关联规则实现商品推荐功能(一)
假如你有一个购物类的网站,那么你如何给你的客户来推荐产品呢?这个功能在很多电商类网站都有,那么,通过SQL Server Analysis Services的数据挖掘功能,你也可以轻松的来构建类似的功能。
将分为三个部分来演示如何实现这个功能。
- 构建挖掘模型
- 为挖掘模型编写服务接口
- 开发简单的前端应用
此篇介绍如何使用SQL Server Analysis Services基于此问题来构建简单的挖掘模型。
关于数据挖掘,简单的就是说从海量数据中发现信息的一个过程。如果说商业智能分为三个层次:告诉你发生了什么,为什么会发生,将来会发生什么。那么,数据挖掘绝对算是商业智能中最高的一个层次,告诉你将来会发生什么,也就是预测。而预测的基础就是根据海量的历史数据,结合一定的算法,以概率为基础,告诉你一条新数据某条属性的趋势。
数据挖掘的模型很多,贝叶斯,时间序列,关联规则等都是常用的模型,根据不同的问题特征可以套用不同的模型算法。比如此篇提到的商品推荐,就是典型的适合用关联规则来解决。在数据挖掘中典型的啤酒和尿布的问题,大体上就是基于这个方法。
创建挖掘模型项目
笔者注:如果你是一个c#或者相关的应用程序开发人员,以下的内容看起来可能会有些陌生,笔者建议此部分跟着文章中介绍的步骤来做就可以,相关细节我会尽量以开发人员的角度去解释。后面有适合开发人员逻辑的一些介绍可以帮助你更好的理解数据挖掘项目。
打开SQL Server Data Tools,点击File->New->Project
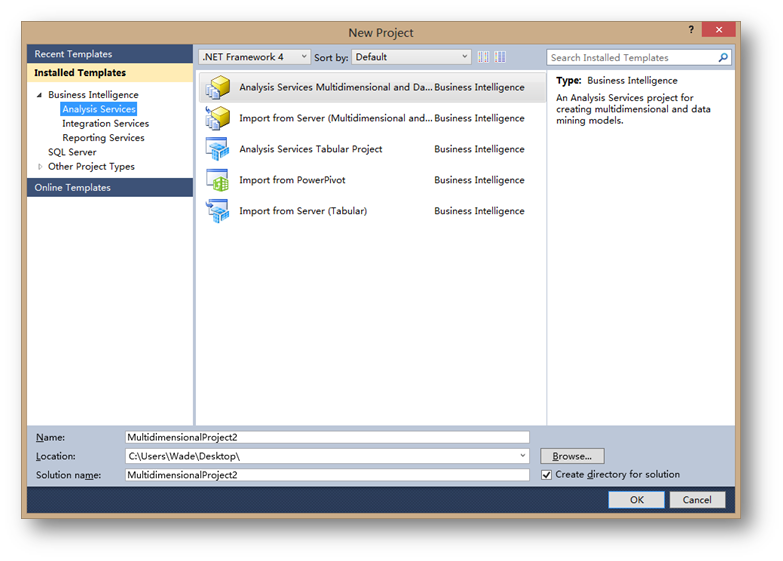
选择项目类型:
Analysis Services Multidimensional and Data Mining Models
为项目添加数据源。
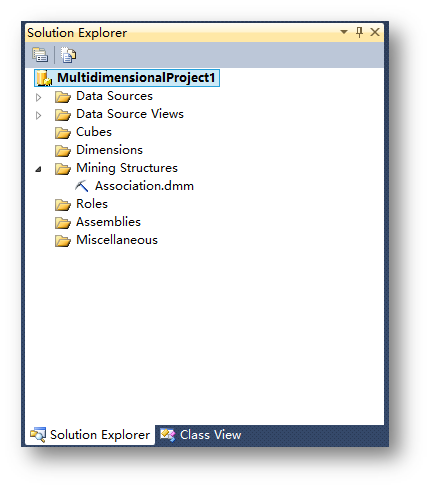
如图,在Solution Explorer中,右键单击Data Sources,选择New Data Source:

这里用到的数据源是微软官方示例库Adventure Works DW 2012,是Data Warehouse的示例库。
关于如何获取并且部署这些示例库,可以参考此篇下面的文章列表。
然后,添加数据源视图,在Solution Explorer中右键Data Source Views,选择New Data Source View。
在Relational data source中,选择刚才建立的数据源名称:
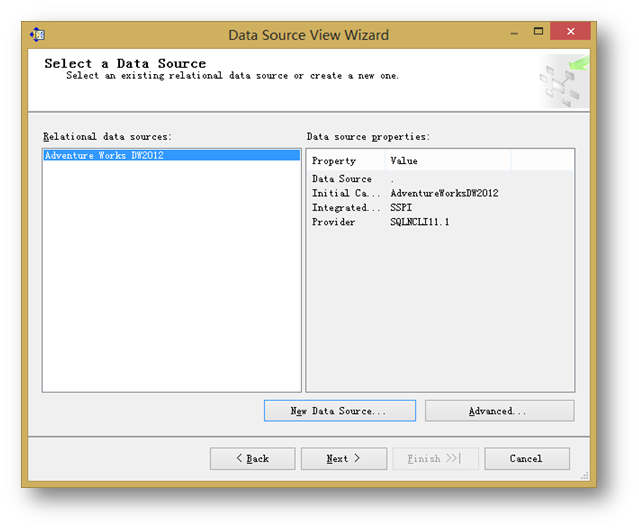
点击下一步。
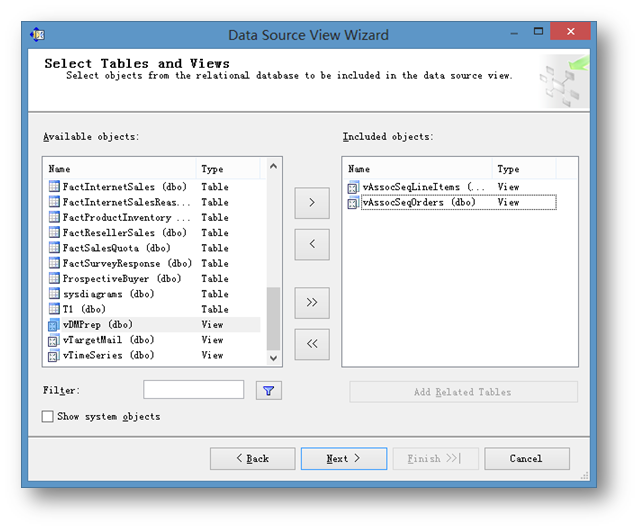
这个界面中选择用到的表。根据微软官方教程以及示例数据,只选择vAssocSeqLineItems和vAssocSeqOrders两个视图就可以。
如果要用关联规则来解决问题,那么你的数据就要符合一定的结构。而具体的结构要求就可以参考这两个视图。
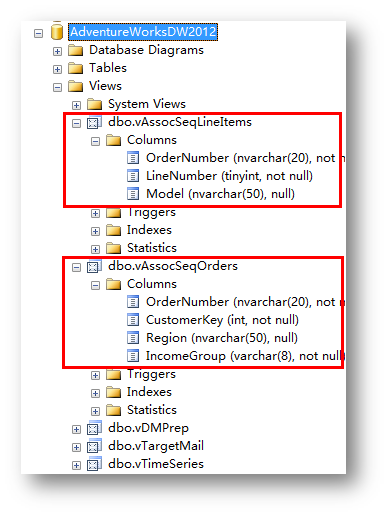
vAssocSeqOrders是订单主表,里面记录了基本的订单信息,一条订单一行记录。
vAssocSeqLineItems是订单相信信息表,里面记录了每条订单里都包含了哪些商品。
两张表逻辑上通过OrderNumber关联,我们关注的字段是Model,这里面记录了商品名称。
选择好用到的表之后,可以直接点击完成结束数据源视图的设置。
这两个视图是没有逻辑关系的,但这里需要指定一下。
方法就是在数据源视图里,拖拽vAssocSeqLineItems里的OrderNumber字段到vAssocSeqOrders的OrderNumber字段。完成后可以看到一个从vAssocSeqLineItems视图指向vAssocSeqOrders的箭头。
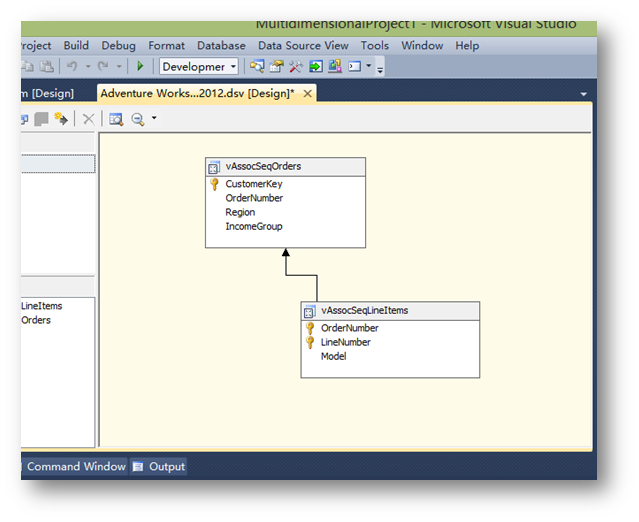
到这里数据源视图设置完毕。
下面建立基于关联规则的挖掘模型。在Solution Explorer中,右键单击Mining Structures,选择New Mining Structure。

第一个界面,使用已经存在的关系数据库或者数据仓库,所以直接下一步。
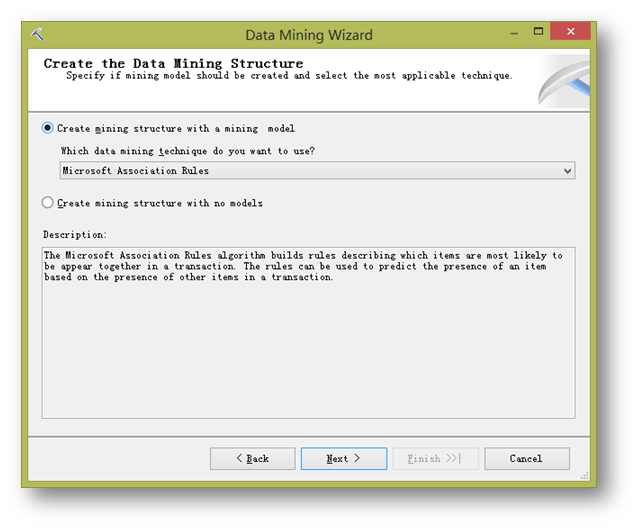
然后在这个界面中指定挖掘结构要采用的挖掘模型。点击下拉框,选择Microsoft Association Rules,也就是关联规则。点下一步。
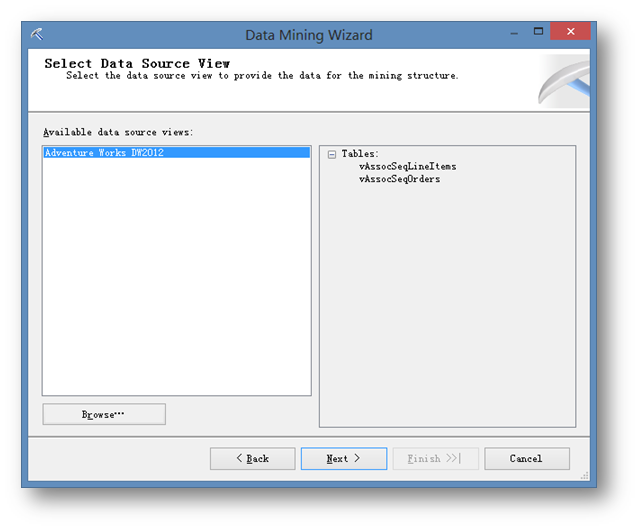
这里指定数据源视图,默认选择刚才建立的就可以,直接点击下一步。
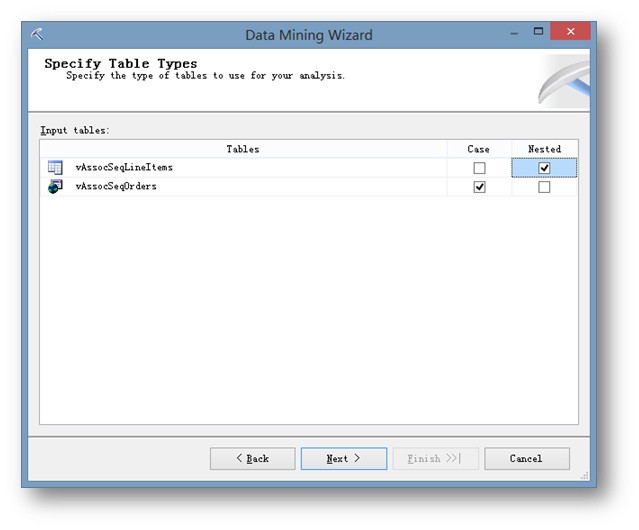
这一步比较关键,理解起来也比较绕。这里主要是要指定事例表和嵌套表。在这里,记录订单基本信息的是事例表,而记录订单里有哪些产品的表为嵌套表。
在这个模型当中,我们要清楚的是,我们的事例单位,是一条条订单,而不是订单里的一个个产品。如果每次在建立模型的过程中无法区分哪个应该是事例表哪个应该是嵌套表的话,那么可以回头来先想下这个问题。
指定完毕事例表和嵌套表,点击下一步。
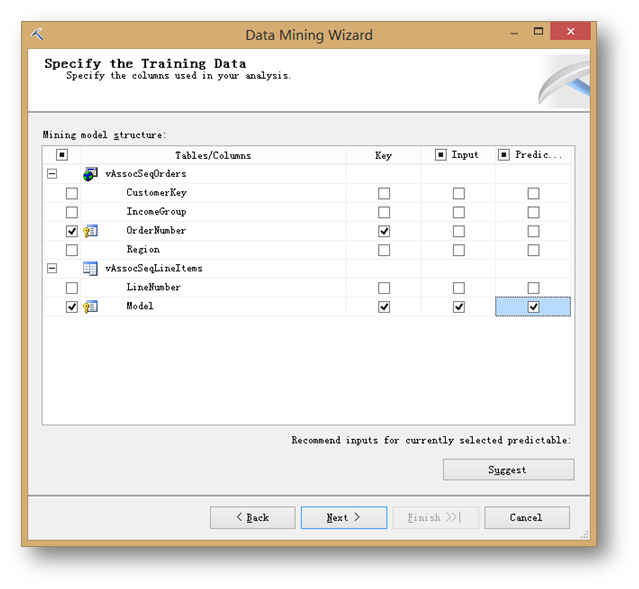
这里指定在分析模型中如何使用这些列。首先指定键列为OrderNumber和Model,然后再把Model列指定为输入列和可预测列。因为这里就是要根据已经选择的商品来预测客户将会购买什么商品。
按如图所示的方法指定完毕后,点击下一步。
选择列的类型,这里根据系统自动判断的类型选择就可以,直接点击下一步。
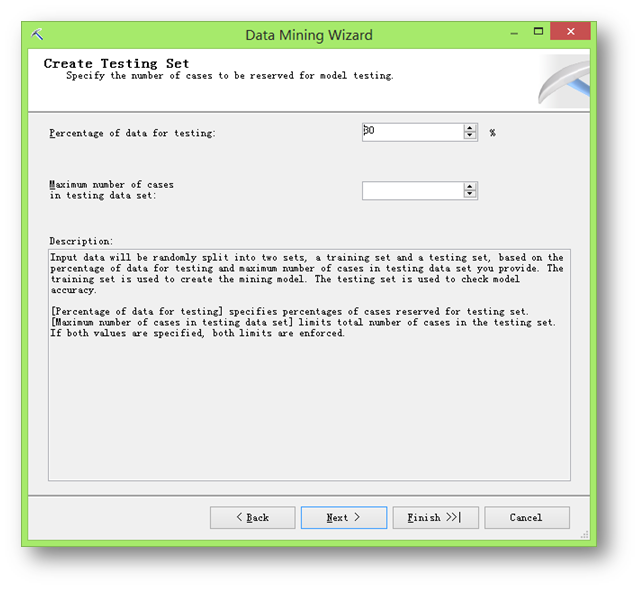
然后这个界面中主要是用来指定测试数据集的多少。默认是30%,也就是在数据中,保留30%的数据来验证建立好的挖掘模型的正确性。此篇不对其做过详细的介绍,所以先设置成0,然后直接点击Finish完成模型设置向导。

可以看到建立好的挖掘结构。
模型建立好了之后,需要将其部署到一个分析服务的实例上去,然后将其处理。
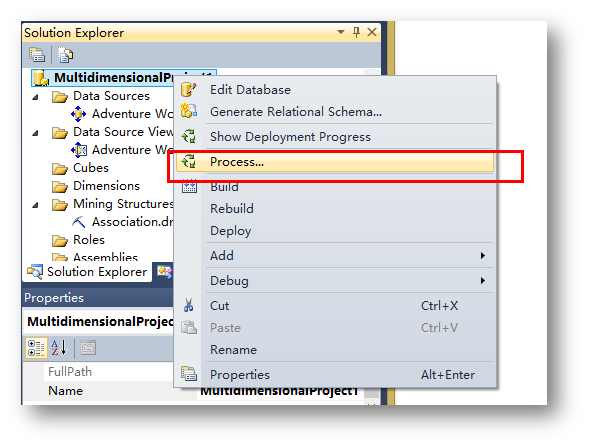
这里直接右键点击Solution Explorer根目录的项目名称,然后右键菜单中选择Process。
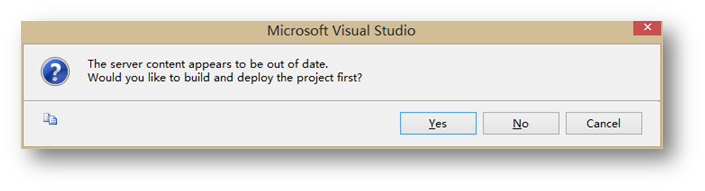
系统会提示服务器内容已过期,VS的判断是只要你的Source Code比目标服务器的版本新,那么都会报这个out of date错误,即使目标服务器上根本没有这个库。所以这里选择Yes。
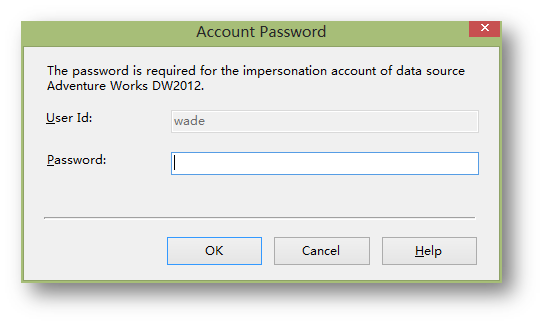
第一次 部署可能会弹出这个提示框让你指定可以方位数据源链接的账户,这里通常直接敲本地管理员的账户就 ok。
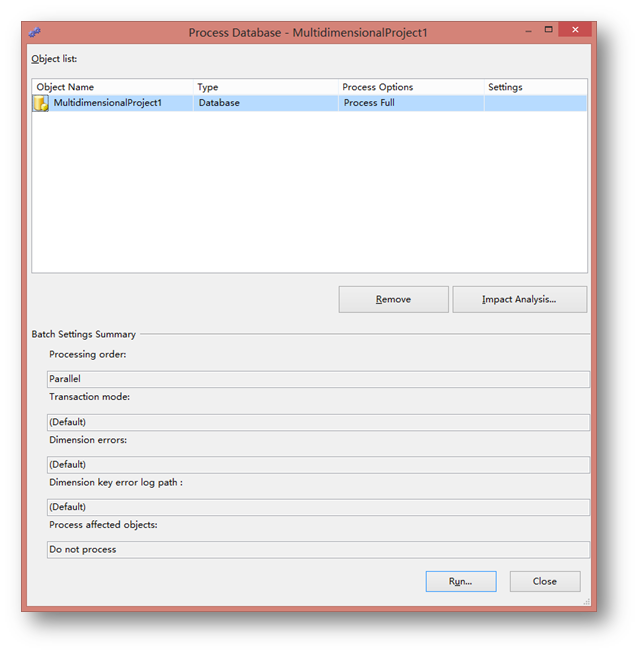
出现这个界面,直接点击Run处理挖掘模型。
然后系统会自动去做很多工作,这里的细节你可以不去关心。(当然在其不报Error的情况下)
处理完成之后,挖掘模型就建立好了。后续的实现商品推荐的功能,就是基于此模型来实现的。
这里再介绍一个概念,叫DMX,也许你从没听说过,但你一定知道SQL,简单的来说SQL就是用来查表得,那么DMX就是用来查数据挖掘模型的。
它跟SQL一样,也是SELECT FROM的结构。具体的语法信息大家有兴趣的可以去参考微软的SQL Server联机数据库。在此篇中,下面会给出一个简单的DMX查询,大家只要基本知道它是干什么的就可以了。
DAX示例查询:
SELECT FLATTENED
PredictAssociation([Association].[v Assoc Seq Line Items],INCLUDE_STATISTICS,3)
FROM
[Association]
NATURAL PREDICTION JOIN
(SELECT (SELECT 'Touring Tire' AS [Model]
) AS [v Assoc Seq Line Items]) AS t
这个语句的大体意思就是,购买了产品Touring Tire的用户当中,根据历史信息,还有可能会购买哪些产品。
那么我们来看查询结果:
|
Model |
SUPPORT |
PROBABILITY |
ADJUSTEDPROBABILITY |
|
Touring Tire Tube |
1397 |
0.860385925 |
0.783460119 |
|
Sport-100 |
6171 |
0.267877412 |
0.489939538 |
|
Patch kit |
3010 |
0.244040863 |
0.567612365 |
然后我们来简单解释下相关列的信息:
SUPPORT-支持度,所处行的项支持度,这里跟传统的支持度有些不同,这里,比如第一行,指的是有多少个订单中包含了产品Touring Tire Tube。
在数据仓库中,我们可以用SQL语句来验证下这个结果
SELECT COUNT(1)
FROM [AdventureWorksDW2012].[dbo].[vAssocSeqLineItems]
WHERE [Model]='Touring Tire Tube'
返回的结果就是1397。
PROBABILITY-概率
购买Touring Tire的订单中又包含Touring Tire Tube的个数。再简单点说就是概率中的P(A|B)的问题了。
那么我们还是来验证下第一行的计算结果,同时购买Touring Tire Tube和Touring Tire的订单数量:
SELECT T1.[OrderNumber]
FROM [AdventureWorksDW2012].[dbo].[vAssocSeqLineItems] T1
INNER JOIN
(
SELECT T2.[OrderNumber]
FROM [AdventureWorksDW2012].[dbo].[vAssocSeqLineItems] T2
WHERE T2.[Model]='Touring Tire Tube'
) TZ ON T1.OrderNumber=TZ.OrderNumber
WHERE T1.[Model]='Touring Tire'
我们可以看到查询返回的结果数量是758行。
然后再计算下订单中只包含Touring Tire的数量:
SELECT [OrderNumber]
FROM [AdventureWorksDW2012].[dbo].[vAssocSeqLineItems]
WHERE [Model]='Touring Tire'
返回的记录行数是881行。
用758除以881,得到的数字正好是0.860385925。
这个概率正好反映了这样一个事实,就是购买Touring Tire的客户会有很大的可能性购买Touring Tire Tube,所以当客户购买Touring Tire之后系统自动的向其推荐Touring Tire Tube准没错。
也许你已经看出了那条DMX语句的一些门道,当然,有些关键字你暂时可以不用去关心,必要的时候可以参考微软的文档。那么扩展一下,比如,客户买了指定的两样产品,那么我根据这两样已选的产品应该推荐给客户什么呢?
SELECT FLATTENED
PredictAssociation([Association].[v Assoc Seq Line Items],INCLUDE_STATISTICS,3)
FROM
[Association]
NATURAL PREDICTION JOIN
(SELECT (SELECT 'Touring Tire' AS [Model]
UNION SELECT 'Touring Tire Tube' AS [Model]
) AS [v Assoc Seq Line Items]) AS t
看到熟悉的UNION语句了吧,好吧,相信你不懂DMX的话你也看出这条语句的规律了,这些就够了,后续文章中将会在c#逻辑代码中根据这条基本的语句来动态的来拼DMX语句。
以上数据挖掘模型的建立部分到此完毕,这是通常一个商业智能项目中底层架构的基本部分。
后续我再写两篇在挖掘模型之上的文章,其中一个是基于这个模型开发service服务接口的,这个接口将方便各个客户端应用,winform, asp.net或者silverlight等调用。最后一篇将选用一个客户端程序,构建简单的界面,调用这个services来实现预测查询。
---------------------------------------------------------------
aspnetx的BI笔记系列索引:
使用SQL Server Analysis Services数据挖掘的关联规则实现商品推荐功能
---------------------------------------------------------------


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2006-02-24 完全放弃dreamweaver设计方法的几个理由