
使用SQL Server Analysis Services Tabular Model建立分析模型
微软在最新版本的SQL Server中加入了Tabular Model,目的在于降低数据分析的门槛,使各个业务部门的人员通过简单的IT培训,制作出符合自己需要的分析模型。
由于其降低了操作门槛,所以各个部门的业务人员可以不用等IT部门的长时间响应就可以制作出简单的分析模型。
本文根据微软提供的官方示例以及教程,简单介绍Tabular Model的建立过程,为了简便省略了官方教程中部分内容,并加入了自己的理解和评论,这些内容只代表本人(哥本哈士奇,代号aspnetx,英文名Wade)的观点,不代表微软公司以及本人所在的公司的观点。
一些跟文章不相关的内容:

年前年后一忙,体重虽然没涨,但人真的变了憔悴好多,最近也刚刚把书本拿起来看。此篇分两个时间点编写,中间隔了一周多。作为新东西,接触起来好困难,毕竟微软设计它的定位就不一样,不过还是硬着头皮看了下来,也算是跟先前一个朋友的约定有个交代。
下面进入正文。
在进行实例的操作之,前需要检查SSAS的Tabular Model是否有被安装。需要注意的是,跟SQL Server 2012之前的版本不同,这个实例是单独的一个分析服务实例,需要单独安装。
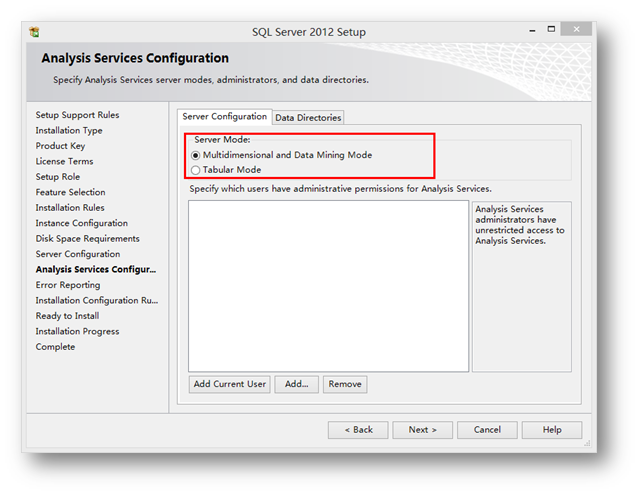
如图,在SQL Server的分析服务安装过程中,会多出来这样一个分析服务类型的选择界面,选择第二个Tabular Mode就可以。如果你的机器中已经安装过默认的分析服务实例,那么这个服务只能以新实例的方式存在。
安装完成之后,就可以在服务列表中看到被安装的服务。
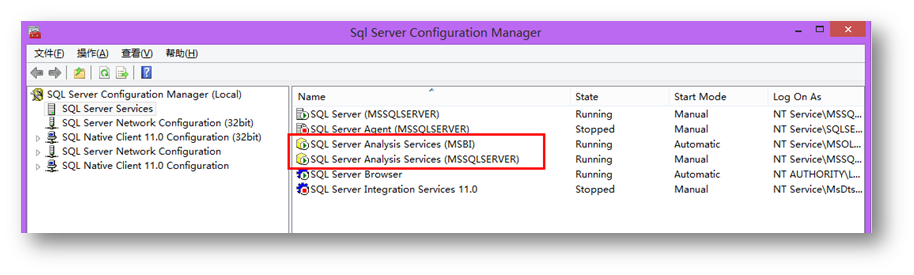
比如图中,我有两个分析服务的实例,一个是默认的MSSQLSERVER,运行多维和数据挖掘模式,一个MSBI实例,运行Tabular Mode模式。两个模式是不能存在于同一个分析服务实例当中的,只能放到不同的实例当中去。
确认好实例已经被安装之后,打开SQL Server Data Tools。跟前几个版本一样,这个工具实际上还是Visual Studio 2010的一个shell。但是跟以前的版本不同,这个版本不再以VS命名了,而是直接Data Tools来命名。而且如果你在用Windows 8,那么在小块块中找到SSDT确实很费劲,比较好的方法是点下开始按钮出现Metro界面后直接在键盘上敲data,在过滤出来的应用程序列表中,通常第一个就是。

打开SQLServer Data Tools之后,选择File->New Project新建SSAS Tabular Model项目。
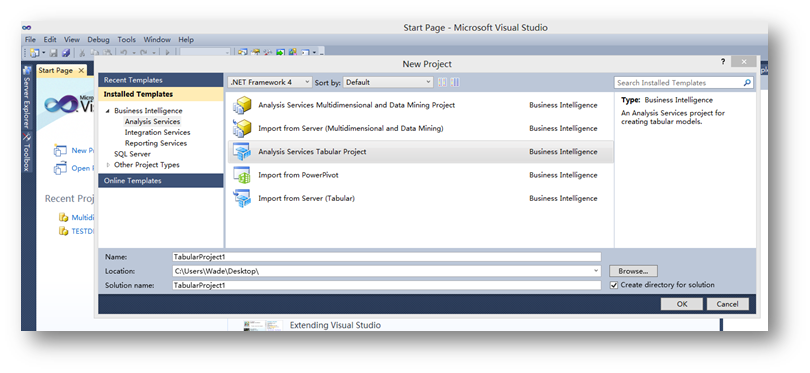
在VS Shell下可以看到新建项目下除了以往的SSAS项目之外又多了一个Analysis Services Tabular Project,就是这个。
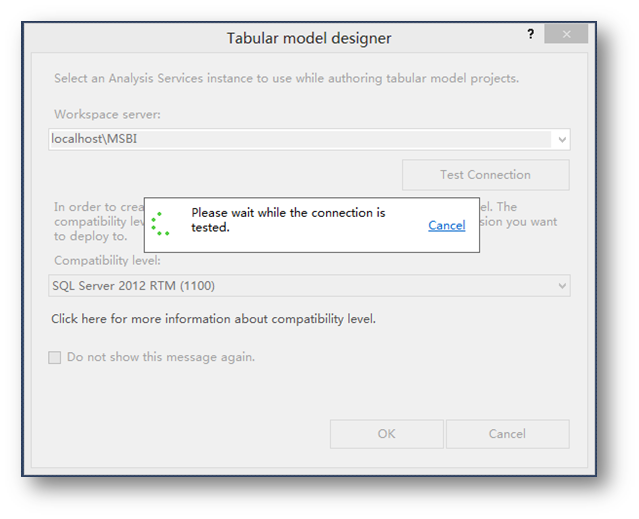
然后会弹出一个窗体让你选择一个分析服务实例,这里要选择安装了Tabular Model的分析服务实例。Compatibility Level根据已经部署好的实例版本选择就可以。
,
如果Compatibility Level和服务器的版本不匹配,会出现错误提示:
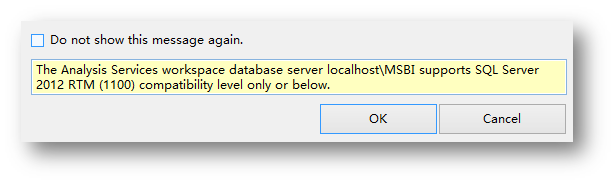
确认好之后,会看到解决方案管理器中的项目结构。
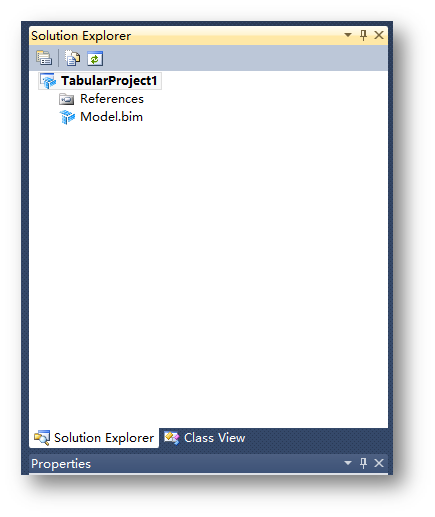
这个结构真的要比传统的分析服务简单好多,只有一个bim文件,不想传统的多维模式一样,会单独把数据远视图,CUBE,维度等都单独区分开。也许IT开发人员会觉得这样就一个bim文件很别扭,但这个工具终究是定位给业务人员使用的,毕竟要遵从业务人员使用Excel和Access的大多数习惯。
双击打开项目中自动建立好的Model.bim文件,会看到VS Shell中的菜单中多出一个Model项,点击它,选择Import From Data Source…
然后会看到项目支持的数据源类型:

这里需要留意的是,根据Tabular Mode模式的不同,所支持的数据源类型也会不同。在In Memory模式下,相对支持的数据源要多一些。而在Direct Query中,只支持微软自家的数据源。
这里选择默认的Microsoft SQL Server,然后下一步。
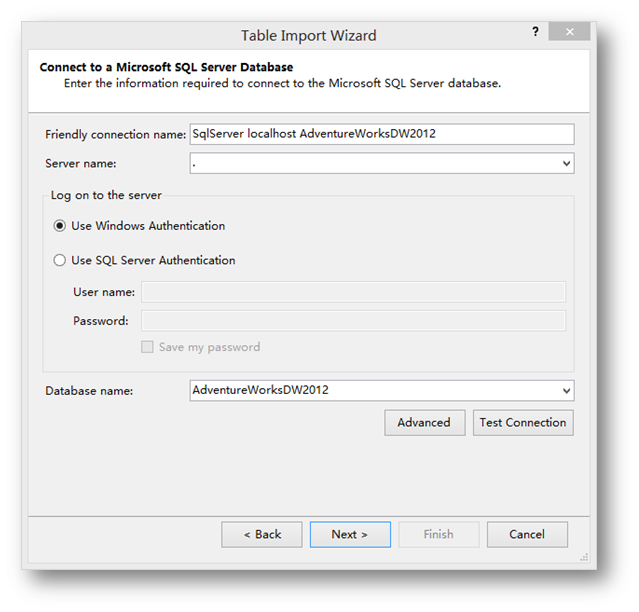
这里选择微软官方的Data Warehouse for Adventure Works数据库。这些示例的数据库的下载和安装方法请参考我先前关于如何获取和安装微软SQL Server官方示例库的文章,里面有详细的介绍,你可以通过在本文下面的文章引用列表中找到。

然后会看到模拟信息对话框,由于这里是练习,为了实验顺利进行,所以敲一个本地的管理员身份账号进去就可以了。当然实际的生产环境中建议为其配置单独的账户来维护数据源的权限访问信息。
输入好之后点下一步。

这里会让你指定如何导入数据,是通过选择表或者视图的方式还是通过查询的方式。这里默认选择第一个,点下一步。
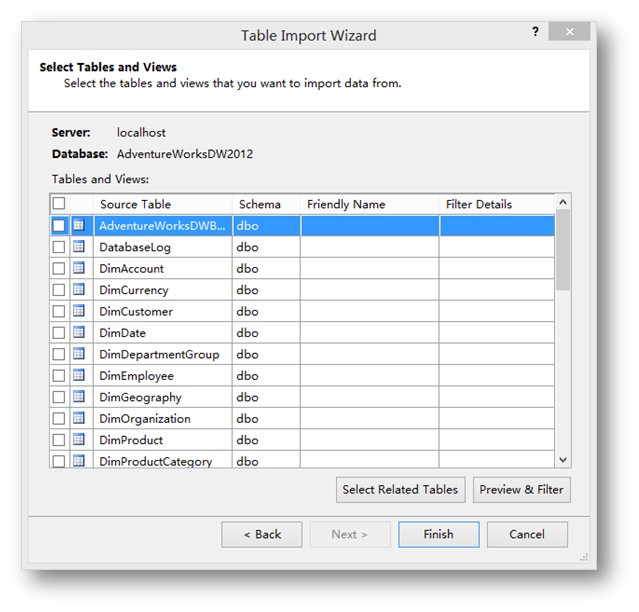
之后会列出刚才指定数据库下的所有表,这里我们只选择其中的几张表,并且为它们重新定义一个友好一点的名称。
|
Source name |
Friendly Name |
|
DimCustomer |
Customer |
|
DimDate |
Date |
|
DimGeography |
Geography |
|
DimProduct |
Product |
|
DimProductCategory |
Product Category |
|
DimProductSubcategory |
Product Subcategory |
|
FactInternetSales |
Internet Sales |
选择好需要用哪些表之后,因为一个表里不一定所有的字段都是分析时要用到的,所以还要再对表里的字段进行过滤。
首先过滤Customer表,选中这张表后,点击Preview & Filter。
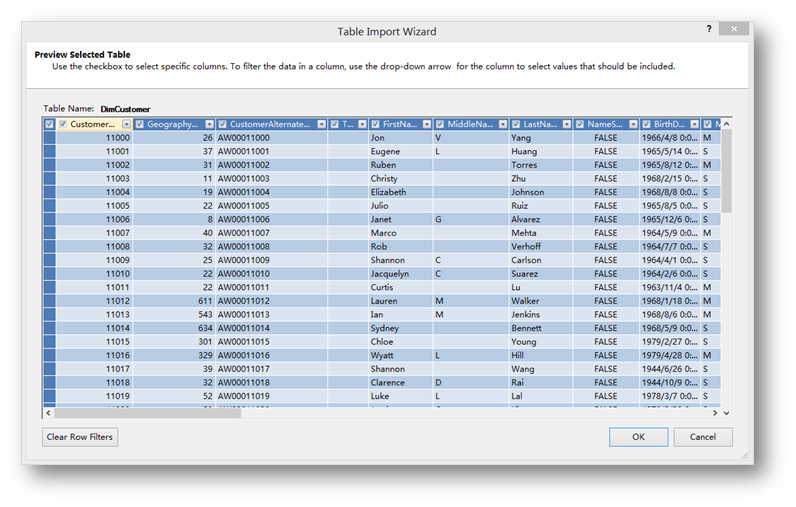
这里通过反勾选列上面的CheckBox过滤掉不需要的字段。在Customer中需要过滤掉的字段(注:是反选下列各表中提及的字段,以达到把相应列从表模型中剔除出去的目的):
|
Customer |
|
SpanishEducation |
|
FrenchEducation |
|
SpanishOccupation |
|
FrenchOccupation |
过滤完成后,可以看到已经被过滤的表已经打好了标记:
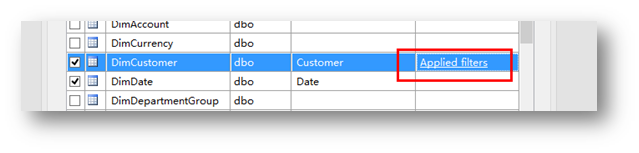
然后,再按照如下表中的定义,把相应的字段过滤掉。
|
Date |
|
DateKey |
|
SpanishDayNameOfWeek |
|
FrenchDayNameOfWeek |
|
SpanishMonthName |
|
FrenchMonthName |
|
DateTimeAlternateKey |
|
Geography |
|
SpanishCountryRegionName |
|
FrenchCountryRegionName |
|
IpAddressLocator |
|
Product |
|
SpanishProductName |
|
FrenchProductName |
|
FrenchDescription |
|
ChineseDescription |
|
ArabicDescription |
|
HebrewDescription |
|
ThaiDescription |
|
GermanDescription |
|
JapaneseDescription |
|
Product Category |
|
SpanishProductCategoryName |
|
FrenchProductCategoryName |
|
Product Subcategory |
|
SpanishProductSubcategoryName |
|
FrenchProductSubcategoryName |
|
Internet Sales |
|
OrderDateKey |
|
DueDateKey |
|
ShipDateKey |
过滤完毕后,点击完成,结束数据的导入设置,之后开始导入数据。

导入完成后点击Close,然后在VS Shell中看到被导入的数据。
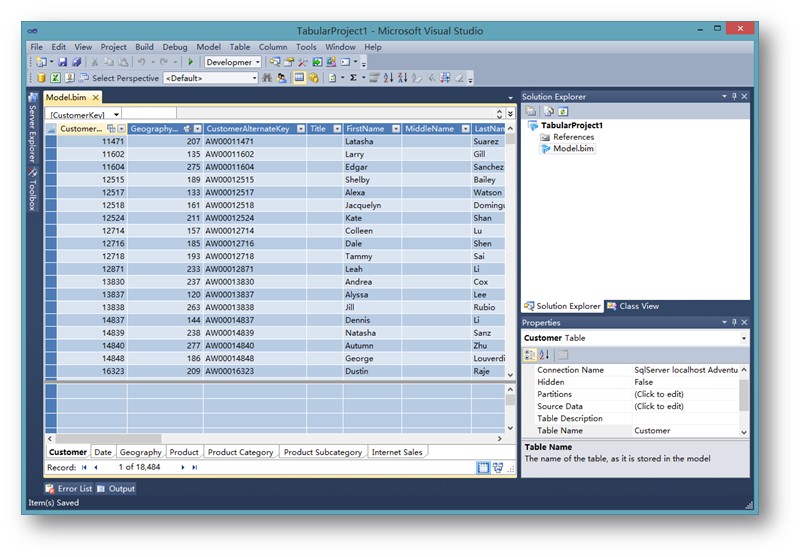
然后,标识时间表。选择导入的Date表,选择菜单栏的Table项,Date下面的Mark As Date Table。
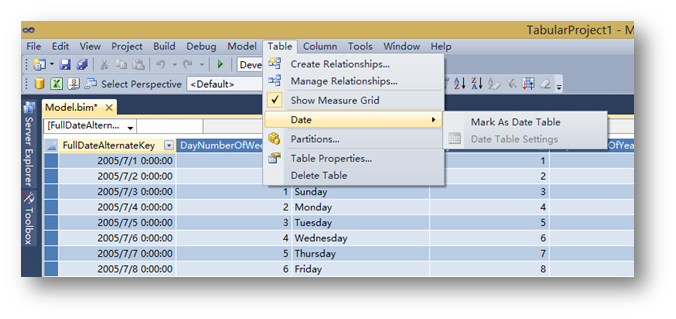
只有当一个时间维度的表被这样标识过之后,一些基于时间的智能函数才会起作用。
接下来定义表之间的关系。
选择菜单栏下的Model->Model View->Diagram View。
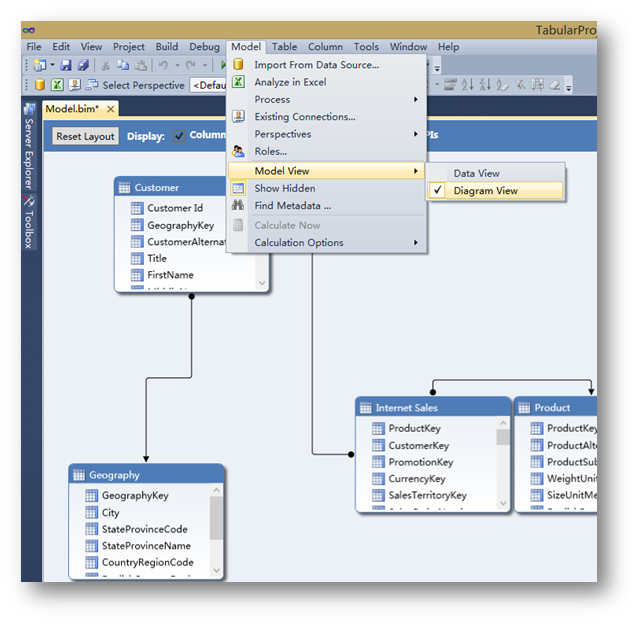
这里可以看到在Data Warehouse中定义的关系已经被自动导入了进来。这里只需要确认下就可以。
很多实际的项目当中,开发人员往往不愿意使用外键来关系表里的数据,而是在传统的多维模型项目中,靠维度用法来指定关系。如果是这种情况那么在这里,表间的关系是一定要指定的,否则系统将无法根据这些关系来"算"数据。

然后需要手动设置Internet Sales和Date之间的关系。在表Internet Sales中,Order Date, Due Date和Ship Date跟Date表中的FullDateAlternateKey关联。设置的方法跟以往的工具一样,比如,拖拽表Internet Sales的字段Order Date到表Date中FullDateAlternateKey字段就可以。
关系创建好之后,再继续计算列的添加。计算列也可以叫派生列,也就是一个新的列,这个列的值是由其它数据计算而来的。
首先,切换回表格模式,选择Model->Model View->Data View。
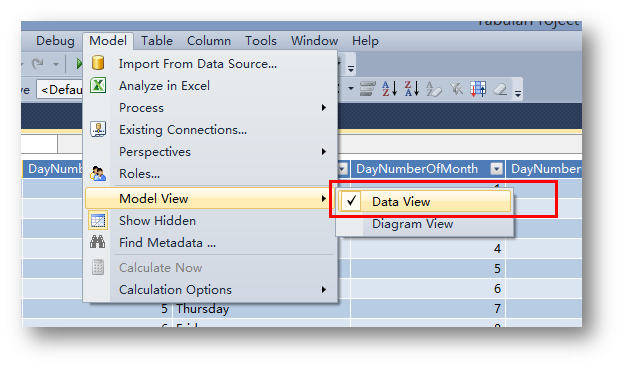
选择Date表,可以看到表的最右边有一个Add Column。
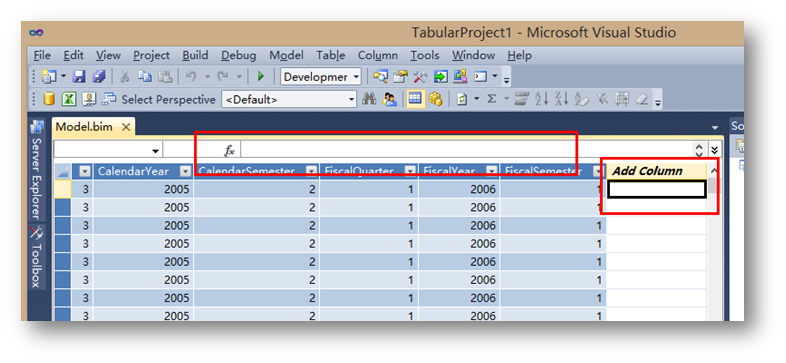
选中下面任意一行,然后在fx里输入公式:
=RIGHT(" " & FORMAT([MonthNumberOfYear],"#0"), 2) & " - " & [EnglishMonthName]
值得一提的是,公式编辑区的智能感知功能很赞。还有,这里不是MDX表达式,而是DAX,跟Excel的公式很像。
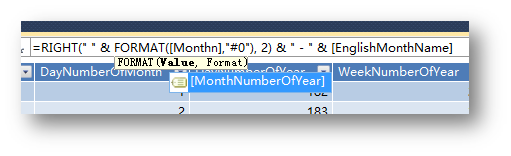
公式输入完成后,按回车,可以看到这一列右下角的更新进度条。
更新完毕后,可以看到根据公式计算好的数据,最后为其重新命名,右键新加的这一列,选择Rename Column。

然后再为Product表创建度量。(此步不建议忽略,后面创建层次的时候要用到)
新列名:Product Subcategory Name
公式:=RELATED('Product Subcategory'[EnglishProductSubcategoryName])
新列名:Product Name
公式:=RELATED('Product Category'[EnglishProductCategoryName])
然后,为模型添加度量。
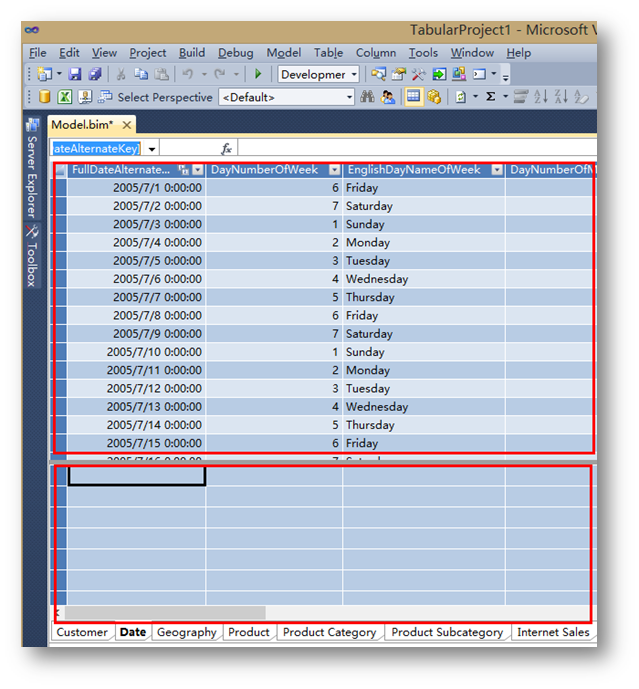
如上图,在每个表界面中,分为上下两个部分,上部分为导入的表,下部分为模型中包含的度量。
如果看不到下面的度量列表,可以点击菜单中的Table->Show Measure Grid。
标注:如果你熟悉以前的多维模式,那么你可以理解为上面是数据源视图,下面为Cube设计视图。
在Tabular Mode模式添加度量的方法是单击度量视图左上角。然后在公式区域输入公式:
=COUNTROWS( DATESQTD( 'Date'[FullDateAlternateKey]))
待度量更新后,可以看到系统自动为这个度量起了个名字:

然后将这个度量重新命名,方法是在公式区域直接选中Measure 1然后将其修改成想要的名字即可。这里将其修改成:
Days Current Quarter to Date
也可以在公式区域中输入完整的格式,也就是度量值名称+公式的格式,比如再建立一个度量值,公式区域中直接输入:
Days in Current Quarter:=COUNTROWS( DATESBETWEEN( 'Date'[FullDateAlternateKey], STARTOFQUARTER( LASTDATE('Date'[FullDateAlternateKey])), ENDOFQUARTER('Date'[FullDateAlternateKey])))
可以看到名称为Days in Current Quarter的度量已经被建立。
最后,在事实表Internet Sales表中添加度量。相对前面的方法直接敲公式,这里的方法相对更简单一些。
切换到Internet Sales表,选中列SalesOrderNumber,然后单击工具栏中的公式图标。
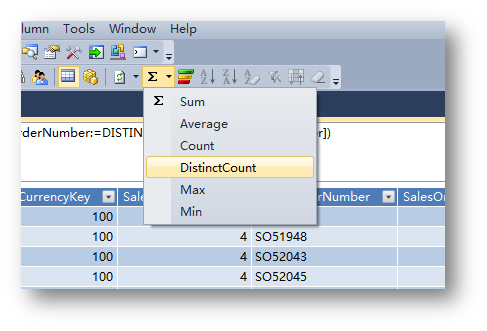
然后就可以看到一个以Distinct Count汇总方式计算的度量。

至此,一个基于事实表的度量值列添加完成。
接下来继续添加维度层次关系。这里创建一个产品分类的层次结构,其中根据数据包含产品的一级分类和二级分类。
切换到Diagram模式,右键Product表,点击Create Hierarchy。

可以看到在表的下面一个层次关系已经被建立。
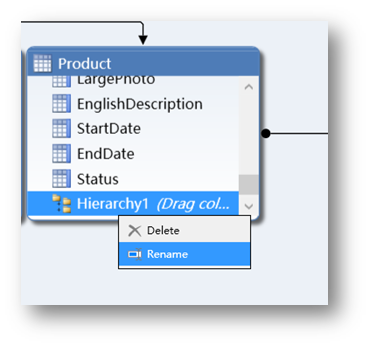
右键单击新建的层次,选择Rename将其重命名为Category。
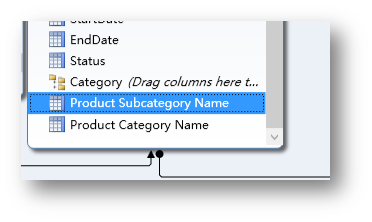
在表中找到Product Category Name和Product Subcategory Name两列,依次拖拽到层次Category下。(注,这两列是先前在Product表里创建的)
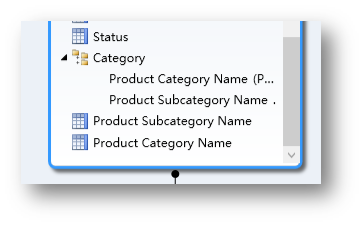
然后,将Category下的两个层次分别命名成Category和SubCategory。
至此,Product的层次创建完成。
再演示下给Date表加一个时间层次。这个层次将包含从年到月再到天的时间导航。(根据需要你也可以加入半年合季度等层次)
首先还是根据前面的方法一样,右键Date表选择Create Hierarchy,创建好一个层次后再将其重命名为Calendar,然后将表中的CalendarYear,MonthNumberOfYear和DayNumberOfMonth一次拖拽到层次下。
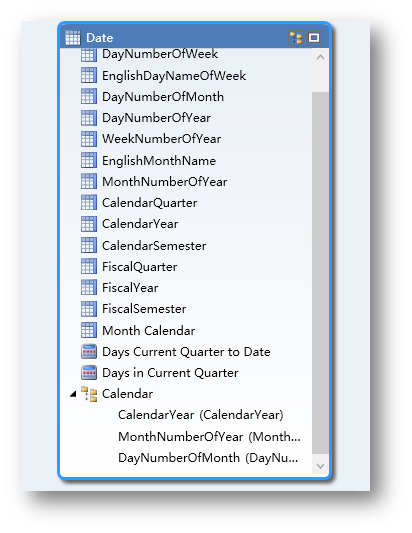
然后再将这三个层次分别命名为Year, Month和Day。
这样,一个Calendar层次结构创建完成,此外,还可以根据这个表创建财务日期层次等多个层次。具体方法参考Calendar的创建即可。
到这里,这个Tabular Mode的分析模型创建好了,可以在Excel里查看下这个分析模型。
方法是在工具栏中点击Analyze in Excel。

然后弹出对话框让你指定用哪个用户来浏览数据。
根据本篇的内容这里直接选择OK就可以。
每次出现这个界面可能很烦,但在实际开发中它还是很方便的,因为我们配置好权限后,通过这里可以很好的去验证下配置的权限是否生效。
点击OK后,熟悉的Excel界面被打开。
可以看懂啊这就是一个透视表。从这里也可以看到,Tabular Mode最终暴露给的用户接口实际上和传统的多维模式一样,只不过底层的数据存储方案不一样。相对中小规模的数据来说,Tabular Mode的In Memory缓存更有优势,而对于比较大比较复杂的业务分析来说用传统的多维方式更具有优势。当然,我们更愿意看到未来的版本中,会出现两个方案的"中间方案"结合两边的优点。
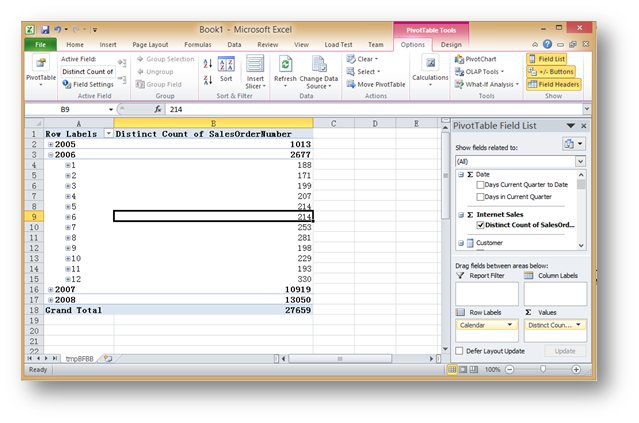
透视表对于业务部门来说是最熟悉不过的工具,如何 操作属于Excel部分的内容,这里不再做具体的讲解。
到这里,一个简单的基于Tabular Mode的分析模型构建完成了。
总结:
整个操作过程下来,根绝Tabular Mode项目的操作模式跟传统的多维模式区别很大,有些地方甚至很难去适应,想找的东西往往需要很久才可以找的到,甚至根本找不到,比如在线打开一个Tabular Mode。不过微软这样设计也并不是没有道理,传统的多维模型定位是给IT人员的,我们已经适应了那种模式,而Tabular Mode是定位给业务部门来操作的,确实很多操作都跟Excel和Access很像。所以有这样的区别也是可以理解的。
另外有一点需要注意的是,Tabular Mode中的查询语言用的是DAX而不是传统的MDX,DAX的写法也许更像Excel,相对来说对于业务部门的人员来说更容易读懂。
总之,Tabular Model的提出降低了分析模型的开发难度,使具有基本IT技能的各个业务部门可以根据已有的数据仓库开发出符合自己需要的简单数据分析模型,而无需每次向IT提需求然后等待长时间的响应之后才可以继续工作。另外它的内存缓存模式确实也很具有吸引力,简单的数据分析模型可以在上面得到快速的响应。
但在一定意义上来说,Tabular Model不会取代传统的多维分析模型,更不会替代整个BI的架构。首先它是分析服务,在整个BI框架中它只是其中的一层,底层的数据仓库还需要做很多的ETL工作。而它对于传统的多维模型,由于彼此的数据存储形式不同,所以它们还是会长时间的对立存在,表模式的更适合业务人员来操作,多维模型更适合复杂结构并且有IT部门来完成的情况,更何况后者还有数据挖掘的部分。未来即使有整合,我个人预测也是在多位模型中加入In Memory Cache的功能,其它不会有太大的改变。
---------------------------------------------------------------
aspnetx的BI笔记系列索引:
使用SQL Server Analysis Services数据挖掘的关联规则实现商品推荐功能
---------------------------------------------------------------
