

003_python中key为中文的处理
由于统计域名资产信息时,部门名称是中文的,但是还需要用这个部门名称进行字符的匹配运算,但不进行转换处理的话,它会报以下的错误:
解决方法如下:
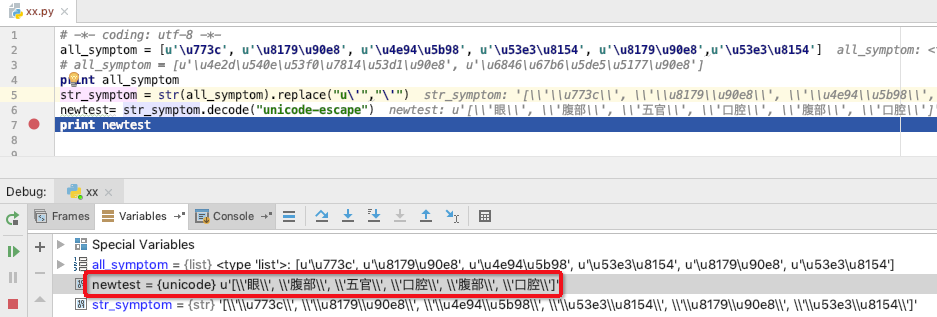
# -*- coding: utf-8 -*-
all_symptom = [u'\u773c', u'\u8179\u90e8', u'\u4e94\u5b98', u'\u53e3\u8154', u'\u8179\u90e8',u'\u53e3\u8154']
# all_symptom = [u'\u4e2d\u540e\u53f0\u7814\u53d1\u90e8', u'\u6846\u67b6\u5de5\u5177\u90e8']
print all_symptom
str_symptom = str(all_symptom).replace("u\'","\'")
newtest= str_symptom.decode("unicode-escape")
print newtest
如下图所所示:需要把转换的坐下双反斜杠的处理.
Reference: https://segmentfault.com/a/1190000002447836
