
Linux进程管理 (2)CFS调度器
关键词:
目录:
根据进程的特性可以将进程划分为:交互式进程、批处理进程、实时进程。
O(N)调度器从就绪队列中比较所有进程的优先级,然后选择一个最高优先级的进程作为下一个调度进程。每个进程都一个固定时间片,当进程时间片用完之后,调度器会选择下一个调度进程,当所有进程都运行一遍后再重新分配时间片。调度器选择下一个调度进程前需要遍历整个就绪队列,花费O(N)时间。
O(1)调度器优化了选择下一个进程的时间,它为每个CPU维护一组进程优先级队列,每个优先级一个队列,这样在选择下一个进程时,只需查询优先级队列相应的位图即可知道哪个队列中有酒须进程,查询时间为常数O(1)。
Linux定义了5种调度器类,分别对应stop、deadline、realtime、cfs、idle,他们通过next串联起来。
const struct sched_class stop_sched_class = { .next = &dl_sched_class, ... }; const struct sched_class dl_sched_class = { .next = &rt_sched_class, ... }; const struct sched_class rt_sched_class = { .next = &fair_sched_class, ... }; const struct sched_class fair_sched_class = { .next = &idle_sched_class, ... } const struct sched_class idle_sched_class = { /* .next is NULL */ ... }; /* * Scheduling policies */ #define SCHED_NORMAL 0 #define SCHED_FIFO 1 #define SCHED_RR 2 #define SCHED_BATCH 3 /* SCHED_ISO: reserved but not implemented yet */ #define SCHED_IDLE 5 #define SCHED_DEADLINE 6
同时定义了6中调度策略,3中调度实体,他们之间的关系如下表。
| 调度器类 | 调度策略 | 调度实体 | 优先级 |
| stop_sched_class | |||
| dl_sched_class | SCHED_DEADLINE | sched_dl_entity | (, 0) |
| rt_sched_class |
SCHED_FIFO SCHED_RR |
sched_rt_entity | [0, 100) |
| fair_sched_class |
SCHED_NORMAL SCHED_BATCH |
sched_entity | [100, ) |
| idle_sched_class | SCHED_IDLE |
实时调度类相关参考《实时调度类分析,以及FIFO和RR对比实验》。
1. 权重计算
1.1 计算优先级
计算优先级之前,首先要明白struct task_struct中各个关于优先级成员的含义。
struct task_struct { ... int prio, static_prio, normal_prio; unsigned int rt_priority; ... unsigned int policy; ... };
prio:保存进程动态优先级,系统根据prio选择调度类,有些情况需要暂时提高进程优先级。
static_prio:静态优先级,在进程启动时分配。内核不保存nice值,通过PRIO_TO_NICE根据task_struct->static_prio计算得到。这个值可以通过nice/renice或者setpriority()修改。
normal_prio:是基于static_prio和调度策略计算出来的优先级,在创建进程时会继承父进程normal_prio。对普通进程来说,normal_prio等于static_prio;对实时进程,会根据rt_priority重新计算normal_prio。
rt_priority:实时进程的优先级,和进程设置参数sched_param.sched_priority等价。
nice/renice系统调用可以改变static_prio值。
rt_priority在普通进程中等于0,实时进程中范围是1~99。
normal_prio在普通进程中等于static_prio;在实时进程中normal_prio=99-rt_priority。
获取normal_prio的函数是normal_prio()
static inline int __normal_prio(struct task_struct *p) { return p->static_prio; } static inline int normal_prio(struct task_struct *p) { int prio; if (task_has_dl_policy(p)) prio = MAX_DL_PRIO-1;-----------------------------------对于DEADLINE类进程来说固定值为-1。 else if (task_has_rt_policy(p)) prio = MAX_RT_PRIO-1 - p->rt_priority;------------------对于实时进程来说,normal_prio=100-1-rt_priority else prio = __normal_prio(p);--------------------------------对普通进程来说normal_prio=static_prio return prio; }
prio在普通进程中和static_prio相等;在实时进程中prio和rt_priority存在prio+rt_priority=99关系。
获取prio的函数是effective_prio()。
static int effective_prio(struct task_struct *p) { p->normal_prio = normal_prio(p); /* * If we are RT tasks or we were boosted to RT priority, * keep the priority unchanged. Otherwise, update priority * to the normal priority: */ if (!rt_prio(p->prio))-------------------即prio大于99的情况,此时为普通进程,prio=normal_prio=static_prio。 return p->normal_prio; return p->prio; }
普通进程:static_prio=prio=normal_prio;rt_priority=0。
实时进程:prio=normal_prio=99-rt_priority;rt_priority=sched_param.sched_priority,rt_priority=[1, 99];static_prio保持默认值不改变。
static_prio和nice之间的关系
内核使用0~139数值表示优先级,数值越低优先级越高。其中0~99给实时进程使用,100~139给普通进程(SCHED_NORMAL/SCHED_BATCH)使用。
用户空间nice传递的变量映射到普通进程优先级,即100~139。
关于nice和prio之间的转换,内核提供NICE_TO_PRIO和PRIO_TO_NICE两个宏。

#define MAX_USER_RT_PRIO 100 #define MAX_RT_PRIO MAX_USER_RT_PRIO #define MAX_PRIO (MAX_RT_PRIO + NICE_WIDTH) #define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2) /* * Convert user-nice values [ -20 ... 0 ... 19 ] * to static priority [ MAX_RT_PRIO..MAX_PRIO-1 ], * and back. */ #define NICE_TO_PRIO(nice) ((nice) + DEFAULT_PRIO) #define PRIO_TO_NICE(prio) ((prio) - DEFAULT_PRIO) /* * 'User priority' is the nice value converted to something we * can work with better when scaling various scheduler parameters, * it's a [ 0 ... 39 ] range. */ #define USER_PRIO(p) ((p)-MAX_RT_PRIO) #define TASK_USER_PRIO(p) USER_PRIO((p)->static_prio) #define MAX_USER_PRIO (USER_PRIO(MAX_PRIO))
1.2 计算权重
内核中使用struct load_weight数据结构来记录调度实体的权重信息。
权重信息是根据优先级来计算的,通过task_struct->se.load来获取进程的权重信息。
因为权重仅适用于普通进程,普通进程的nice对应范围是-20~19。
struct task_struct { ... struct sched_entity se; ... };
struct sched_entity { struct load_weight load; /* for load-balancing */ ... }; struct load_weight { unsigned long weight;----------------调度实体的权重 u32 inv_weight;----------------------inverse weight,是全中一个中间计算结果。 };
set_load_weight()设置进程的权重值,通过task_struct->static_prio从prio_to_weight[]和prio_to_wmult[]获取。
static void set_load_weight(struct task_struct *p) { int prio = p->static_prio - MAX_RT_PRIO;---------------------权重值取决于static_prio,减去100而不是120,对应了下面数组下标。 struct load_weight *load = &p->se.load; /* * SCHED_IDLE tasks get minimal weight: */ if (p->policy == SCHED_IDLE) { load->weight = scale_load(WEIGHT_IDLEPRIO);-------------IDLE调度策略进程使用固定优先级权重,取最低普通优先级权重的1/5。 load->inv_weight = WMULT_IDLEPRIO;----------------------取最低普通优先级反转权重的5倍。 return; } load->weight = scale_load(prio_to_weight[prio]); load->inv_weight = prio_to_wmult[prio]; }
nice从-20~19,共40个等级,nice值越高优先级越低。
进程每提高一个优先级,则增加10%CPU时间,同时另一个进程减少10%时间,他们之间的关系从原来的1:1变成了1.1:0.9=1.22。
因此相同优先级之间的关系使用系统1.25来表示。
假设A和B进程nice都为0,权重都是1024.
A的nice变为1,B不变。那么B获得55%运行时间,A获得45%运行时间。A的权重就变成了A/(A+1024)=9/(9+11),A=1024*9/11=838。
但是Linux并不是严格按照1.22系数来计算的,而是近似1.25。
A的权重值就变成了1024/1.25≈820。
prio_to_weight[]以nice-0为基准权重1024,然后将nice从-20~19预先计算出。set_load_weight()就可以通过优先级得到进程对应的权重。
prio_to_wmult[]为了方便计算vruntime而预先计算结果。
inv_weight=232/weight
static const int prio_to_weight[40] = { /* -20 */ 88761, 71755, 56483, 46273, 36291, /* -15 */ 29154, 23254, 18705, 14949, 11916, /* -10 */ 9548, 7620, 6100, 4904, 3906, /* -5 */ 3121, 2501, 1991, 1586, 1277, /* 0 */ 1024, 820, 655, 526, 423, /* 5 */ 335, 272, 215, 172, 137, /* 10 */ 110, 87, 70, 56, 45, /* 15 */ 36, 29, 23, 18, 15, }; static const u32 prio_to_wmult[40] = { /* -20 */ 48388, 59856, 76040, 92818, 118348, /* -15 */ 147320, 184698, 229616, 287308, 360437, /* -10 */ 449829, 563644, 704093, 875809, 1099582, /* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326, /* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587, /* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126, /* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717, /* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153, };
1.2.1 优先级和权重关系实验
下面设计一下CPU intensive的进程,然后设置不同优先级,再使用top查看他们实际得到的CPU执行事件。
这样就可以验证他们的优先级和权重关系。
首先需要将这些进程固定到一个CPU上,然后调整优先级。
#define _GNU_SOURCE #include <stdio.h> #include <sched.h> #include <stdlib.h> #include <unistd.h> #include <sys/resource.h> int main(void) { int i, pid; cpu_set_t mask; //Set CPU affinity. CPU_ZERO(&mask); CPU_SET(0, &mask); if(sched_setaffinity(0, sizeof(cpu_set_t), &mask) == -1) { exit(EXIT_FAILURE); } pid = getpid(); setpriority(PRIO_PROCESS, pid, -20); while(1) { } return 0; }
1.2.1.1 -20和-19关系
理论上-20和-19的CPU占比应该是88761:71755=1.24:1=55.3/44.7。
来看一下实际执行效果,符合预期。

通过kernelshark查看一下他们之间的关系,两个进程之间是有规律的。
-20执行了2+3tick,-19执行了2+2tick,两者之间的比例也接近1.25。符合预期。
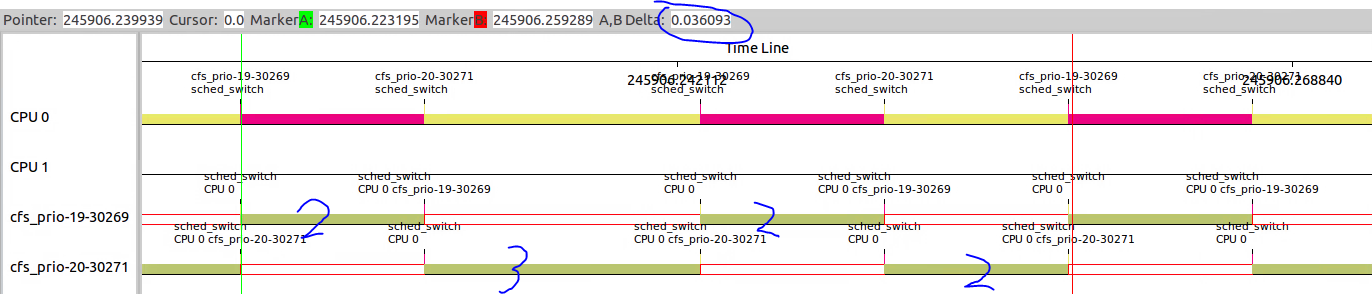
1.2.1.2 -20、-19、-18三者关系呢?
这三者之间的比例关系应该是88761:71755:56483=1.57:1.27:1。
实际结果是41.2:32.9:25.9=1.59:1.27:1,符合预期。

1.2.1.3 -20、-19、-18、0四者关系呢?
88761:71755:56483:1024=1.57:1.27:1:0.018
实际结果是40.8:33.0:25.8:0.4=1.58:1.28:1:0.016,基本符合预期。
为什么不以nice-0为基准呢?首先在-20、-19、-18存在的情况下,nice-0的误差显得特别大,另一个系统还存在其它很多nice-0的进程。

1.3 计算vrtime
CFS中所谓的Fair是vrtime的,而不是实际时间的平等。
CFS调度器抛弃以前固定时间片和固定调度周期的算法,而采用进程权重值的比重来量化和计算实际运行时间。
引入虚拟时钟概念,每个进程虚拟时间是实际运行时间相对Nice值为0的权重比例值。
Nice值小的进程,优先级高且权重大,其虚拟时钟比真实时钟跑得慢,所以可以获得更多的实际运行时间。
反之,Nice值大的进程,优先级低权重小,获得的实际运行时间也更少。
CFS选择虚拟时钟跑得慢的进程,而不是实际运行时间运行的少的进程。
vruntime=delta_exec*nice_0_weight/weight
vruntime表示进程的虚拟运行时间,delta_exec表示进程实际运行时间,nice_0_weight表示nice为0权重值,weight表示该进程的权重值,可以通过prio_to_weight[]获取。
vruntime=delta_exec*nice_0_weight*232/weight>>32
其中232/weight可以用inv_weight来表示,其中inv_weight可以从prio_to_wmult[]中获取。
vruntime=delta_exec*nice_0_weight*inv_weight>>32
calc_delta_fair()是计算虚拟时间的函数,其返回值是虚拟时间。
__calc_delta()是计算vruntime的核心,delta_exec是进程实际运行时间,weight是nice_0_weight,lw是对应进程的load_weight,里面包含了其inv_weight值。
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se) { if (unlikely(se->load.weight != NICE_0_LOAD))----如果当前进程权重是NICE_0_WEIGHT,虚拟时间就是delta,不需要__calc_delta()计算。 delta = __calc_delta(delta, NICE_0_LOAD, &se->load); return delta; } static u64 __calc_delta(u64 delta_exec, unsigned long weight, struct load_weight *lw) { u64 fact = scale_load_down(weight);--------------fact等于weight。 int shift = WMULT_SHIFT;-------------------------WMULT_SHIFT等于32 __update_inv_weight(lw);-------------------------更新load_weight->inv_weight,一般情况下已经设置,不需要进行操作。 if (unlikely(fact >> 32)) {----------------------一般fact>>32为0,所以跳过 while (fact >> 32) { fact >>= 1; shift--; } } /* hint to use a 32x32->64 mul */ fact = (u64)(u32)fact * lw->inv_weight;----------此处相当于nice_0_weight*inv_weight while (fact >> 32) { fact >>= 1; shift--; } return mul_u64_u32_shr(delta_exec, fact, shift);----此处相当于delta_exec*(nice_0_weight*inv_weight)>>32。 }
优先级越低的进程inv_weight值越大,其它nice_0_weight和位置都是一样的。
所以相同的delta_exec情况下,优先级越低vruntime越大。
cfs总是在红黑树中选择vrunime最小的进程进行调度,优先级高的进程在相同实际运行时间的情况下vruntime最小,所以总会被优先选择。但是随着vruntime的增长,优先级低的进程也有机会运行。
1.4 负载计算
内核中计算CPU负载的方法是PELT(Per-Entity Load Tracing),不仅考虑进程权重,而且跟踪每个调度实体的负载情况。
sched_entity结构中有一个struct sched_avg用于描述进程的负载。
runnable_sum:表示该调度实体在就绪队列里(sched_entity->on_rq==1)可运行状态的总时间。包括两部分,一是正在运行的时间,即running时间;二是在就绪队列中等待的时间。进程进入就绪队列时(调用enqueue_entity()),on_rq被置为1,但该进程因为睡眠等原因退出就绪队列时(调用dequeue_entity()),on_rq会被清0,因此runnable_sum就是统计进程在就绪队列的时间。
runnable_period:可以理解为该调度实体在系统中的总时间,period是指一个周期period为1024us。当一个进程fork出来后,无论是否在就绪队列中,runnable_period一直在递增。
runnable_avg_sum:考虑历史数据对负载的影响,采用衰减系统来计算平均复杂,调度实体在就绪队列里可运行状态下总的衰减累加时间。
runnable_avg_period:调度实体在系统中总的衰减累加时间。
last_runnable_update:最近更新load的时间点,用于计算时间间隔。
load_avg_contrib:进程平均负载的贡献度。
struct sched_avg { /* * These sums represent an infinite geometric series and so are bound * above by 1024/(1-y). Thus we only need a u32 to store them for all * choices of y < 1-2^(-32)*1024. */ u32 runnable_avg_sum, runnable_avg_period; u64 last_runnable_update; s64 decay_count; unsigned long load_avg_contrib; }; struct sched_entity { ... #ifdef CONFIG_SMP /* Per entity load average tracking */ struct sched_avg avg; #endif }
1.4.1 衰减因子
将1024us时间跨度算成一个周期,period简称PI。
一个PI周期内对系统负载的贡献除了权重外,还有PI周期内可运行的时间,包括运行时间或等待CPU时间。
一个理想的计算方式是:统计多个实际的PI周期,并使用一个衰减系数来计算过去的PI周期对付贼的贡献。
Li是一个调度实体在第i个周期内的负载贡献。那么一个调度实体负载综合计算公式如下:
L=L0+L1*y+L2*y2+L3*y3...+L32*y32+...
调度实体的负载需要考虑时间因素,不能只考虑当前负载,还要考虑其在过去一段时间表现。
一般认为过去第32个周期的负载减半,所以y32=0.5,得出衰减因子y=0.978左右。
同时内核不需要数组来存放过去PI个周期负载贡献,只需要用过去周期贡献总和乘以衰减系数y,并加上当前时间点的负载L0即可。
下表对衰减因子乘以232,计算完成后再右移32位。如下,就将原来衰减因子的浮点元算转换成乘法和移位操作。
L*yn = (L*yn*232)>>32 = (L*(0.978)n*232)>>32 = L*runnable_avg_yN_inv[n]>>32
runnable_avg_yN_inv[n]是计算第n个周期的衰减值,在实际使用中需要计算n个周期的负载累积贡献值。
runnable_avg_yN_sum[n] = 1024*(y + y2 + y3 + ... + yn)
取1024是因为一个周期是1024微秒。
下面两个数组虽然都是计算负载累计,但是runnable_avg_yN_inv[]使计算某一个周期的贡献值,runnable_avg_yN_sum[n]是计算n个周期的贡献值。
runnable_avg_yN_inv[]共32个成员,runnable_avg_yN_sum[]共33个成员。
static const u32 runnable_avg_yN_inv[] = { 0xffffffff, 0xfa83b2da, 0xf5257d14, 0xefe4b99a, 0xeac0c6e6, 0xe5b906e6, 0xe0ccdeeb, 0xdbfbb796, 0xd744fcc9, 0xd2a81d91, 0xce248c14, 0xc9b9bd85, 0xc5672a10, 0xc12c4cc9, 0xbd08a39e, 0xb8fbaf46, 0xb504f333, 0xb123f581, 0xad583ee9, 0xa9a15ab4, 0xa5fed6a9, 0xa2704302, 0x9ef5325f, 0x9b8d39b9, 0x9837f050, 0x94f4efa8, 0x91c3d373, 0x8ea4398a, 0x8b95c1e3, 0x88980e80, 0x85aac367, 0x82cd8698, }; static const u32 runnable_avg_yN_sum[] = { 0, 1002, 1982, 2941, 3880, 4798, 5697, 6576, 7437, 8279, 9103, 9909,10698,11470,12226,12966,13690,14398,15091,15769,16433,17082, 17718,18340,18949,19545,20128,20698,21256,21802,22336,22859,23371, };
这两个参数分别对应decay_load()和__compute_runnable_contrib()。
decay_load()根据一个load值和周期序号n,返回衰减后的load值。
__compute_runnable_contrib()只有一个参数过去的periods周期数目,返回累计衰减load值。
1.4.2 update_entity_load_avg()
update_entity_load_avg()主要更新struct sched_avg结构体成员,其中__update_entity_runnable_avg()更新了last_runnable_update、runnable_avg_sum和runnable_avg_period三个数据;
__update_entity_load_avg_contrib()更新了load_avg_contrib;最后同时更新了cfs_rq->runnable_load_avg。
static inline void update_entity_load_avg(struct sched_entity *se, int update_cfs_rq) { struct cfs_rq *cfs_rq = cfs_rq_of(se); long contrib_delta; u64 now; /* * For a group entity we need to use their owned cfs_rq_clock_task() in * case they are the parent of a throttled hierarchy. */ if (entity_is_task(se)) now = cfs_rq_clock_task(cfs_rq); else now = cfs_rq_clock_task(group_cfs_rq(se)); if (!__update_entity_runnable_avg(now, &se->avg, se->on_rq))-------更新sched_avg的三个参数:last_runnable_update、runnable_avg_sum、runnable_avg_period。如果上次更新到本次不足1024
us,不做衰减计算,不计算负载贡献度。 return; contrib_delta = __update_entity_load_avg_contrib(se);--------------计算本次更新贡献度,更新到load_avg_contrib中。 if (!update_cfs_rq) return; if (se->on_rq) cfs_rq->runnable_load_avg += contrib_delta;--------------------累加到cfs_rq->runnable_laod_avg中 else subtract_blocked_load_contrib(cfs_rq, -contrib_delta); } static __always_inline int __update_entity_runnable_avg(u64 now, struct sched_avg *sa, int runnable)--------------------------------runnable表示该进程是否在就绪队列上接受调度 { u64 delta, periods; u32 runnable_contrib; int delta_w, decayed = 0; delta = now - sa->last_runnable_update;------------------------------上次更新负载到本次更新的间隔,单位是ns。 /* * This should only happen when time goes backwards, which it * unfortunately does during sched clock init when we swap over to TSC. */ if ((s64)delta < 0) { sa->last_runnable_update = now; return 0; } /* * Use 1024ns as the unit of measurement since it's a reasonable * approximation of 1us and fast to compute. */ delta >>= 10;--------------------------------------------------------delta单位变成近似1微秒 if (!delta) return 0; sa->last_runnable_update = now; /* delta_w is the amount already accumulated against our next period */ delta_w = sa->runnable_avg_period % 1024;----------------------------runnable_avg_period是上一次更新时的总周期数,delta_w是上一次周周期数不能凑成一个周期的剩余时间,单位是微秒。 if (delta + delta_w >= 1024) {---------------------------------------如果时间大于一个周期,就需要进行衰减计算。 /* period roll-over */ decayed = 1; /* * Now that we know we're crossing a period boundary, figure * out how much from delta we need to complete the current * period and accrue it. */ delta_w = 1024 - delta_w; if (runnable) sa->runnable_avg_sum += delta_w; sa->runnable_avg_period += delta_w; delta -= delta_w; /* Figure out how many additional periods this update spans */ periods = delta / 1024;---------------------------------------------本次更新和上次更新之间经历的周期数periods delta %= 1024; sa->runnable_avg_sum = decay_load(sa->runnable_avg_sum, periods + 1);-------------------------------------分别计算第periods+1个周期的runnable_avg_sum和runnable_avg_period的衰减。 sa->runnable_avg_period = decay_load(sa->runnable_avg_period, periods + 1); /* Efficiently calculate \sum (1..n_period) 1024*y^i */ runnable_contrib = __compute_runnable_contrib(periods);-------------得到过去periods个周期的累计衰减。 if (runnable) sa->runnable_avg_sum += runnable_contrib; sa->runnable_avg_period += runnable_contrib; } /* Remainder of delta accrued against u_0` */---------------------------不能凑成完成周期的部分直接进行相加。 if (runnable) sa->runnable_avg_sum += delta; sa->runnable_avg_period += delta; return decayed;---------------------------------------------------------decayed表示是否进行了衰减计算 } static __always_inline u64 decay_load(u64 val, u64 n)----------------------val表示n个周期前的负载值,n表示第n个周期。返回结果为val*yn,变成查表(val*runnable_avg_yN_inv[n])>>32。 { unsigned int local_n; if (!n) return val;---------------------------------------------------------n=0:表示当前周期,不衰减。 else if (unlikely(n > LOAD_AVG_PERIOD * 63))----------------------------n>=2016:LOAD_AVG_PERIOD=32,因此n超过2016就认为衰减值变为0。 return 0; /* after bounds checking we can collapse to 32-bit */ local_n = n; /* * As y^PERIOD = 1/2, we can combine * y^n = 1/2^(n/PERIOD) * y^(n%PERIOD) * With a look-up table which covers y^n (n<PERIOD) * * To achieve constant time decay_load. */ if (unlikely(local_n >= LOAD_AVG_PERIOD)) {-----------------------------32=<n<2016:每32个周期衰减1/2,即val右移一位。剩下周期数存入local_n。 val >>= local_n / LOAD_AVG_PERIOD; local_n %= LOAD_AVG_PERIOD; } val *= runnable_avg_yN_inv[local_n];------------------------------------0<n<32:根据local_n查表得到衰减值 /* We don't use SRR here since we always want to round down. */ return val >> 32;-------------------------------------------------------最终结果右移32位,归一化。 } static u32 __compute_runnable_contrib(u64 n) { u32 contrib = 0; if (likely(n <= LOAD_AVG_PERIOD))--------------------------------------n<=32:直接查表得到结果。 return runnable_avg_yN_sum[n]; else if (unlikely(n >= LOAD_AVG_MAX_N))--------------------------------n>=345:直接取最大值47742,这个值也是一共345个周期的累计衰减。 return LOAD_AVG_MAX; /* Compute \Sum k^n combining precomputed values for k^i, \Sum k^j */ do {-------------------------------------------------------------------以LOAD_AVG_PERIOD为步长,计算过去n/32个32周期的累计衰减 contrib /= 2; /* y^LOAD_AVG_PERIOD = 1/2 */ contrib += runnable_avg_yN_sum[LOAD_AVG_PERIOD];-------------------都取n=32的情况 n -= LOAD_AVG_PERIOD; } while (n > LOAD_AVG_PERIOD); contrib = decay_load(contrib, n);-------------------------------------还需经过n过周期衰减,因此经过decay_load()得到过去“n/32个32周期”的最终累计衰减。 return contrib + runnable_avg_yN_sum[n];------------------------------不能凑成32周期单独计算并和contrib累加得到最终的结果。 } static long __update_entity_load_avg_contrib(struct sched_entity *se) { long old_contrib = se->avg.load_avg_contrib; if (entity_is_task(se)) { __update_task_entity_contrib(se); } else { __update_tg_runnable_avg(&se->avg, group_cfs_rq(se)); __update_group_entity_contrib(se); } return se->avg.load_avg_contrib - old_contrib; } static inline void __update_task_entity_contrib(struct sched_entity *se) { u32 contrib; /* avoid overflowing a 32-bit type w/ SCHED_LOAD_SCALE */ contrib = se->avg.runnable_avg_sum * scale_load_down(se->load.weight); contrib /= (se->avg.runnable_avg_period + 1); se->avg.load_avg_contrib = scale_load(contrib);-------------------------更新sched_avg->load_avg_contrib }
load_avg_contrib = (runnable_avg_sum*weight)/runnable_avg_period
可见一个调度实体的平均负载和以下3个因素相关:
- 调度实体的权重weight
- 调度实体可运行状态下的总衰减累加时间runnable_avg_sum
- 调度实体在调度器中总衰减累加时间runnable_avg_period
runnable_avg_sum越接近runnable_avg_period,则平均负载越大,表示调度实体一直在占用CPU。
2. 进程创建
2.1 sched_entity、rq、cfs_rq
struct sched_entity内嵌在task_struct中,称为调度实体,描述进程作为一个调度实体参与调度的所需要的所有信息。
struct sched_entity { struct load_weight load; /* for load-balancing */----------------调度实体的权重。 struct rb_node run_node;--------------------------------------------表示调度实体在红黑树中的节点 struct list_head group_node; unsigned int on_rq;-------------------------------------------------表示该调度实体是否在就绪队列中接受调度 u64 exec_start; u64 sum_exec_runtime; u64 vruntime;---------------------------------------------------表示本调度实体的虚拟运行时间 u64 prev_sum_exec_runtime; u64 nr_migrations; #ifdef CONFIG_SCHEDSTATS struct sched_statistics statistics; #endif #ifdef CONFIG_FAIR_GROUP_SCHED int depth; struct sched_entity *parent; /* rq on which this entity is (to be) queued: */ struct cfs_rq *cfs_rq; /* rq "owned" by this entity/group: */ struct cfs_rq *my_q;-------------------------------------------------如果my_q不为null表示当前调度实体是调度组,而不是单个进程。 #endif #ifdef CONFIG_SMP /* Per-entity load-tracking */ struct sched_avg avg;-----------------------------------------------------表示调度实体平均负载信息。 #endif };
strcut sched_entity是per-task的,struct rq是per-cpu的。
系统中每个CPU就有一个struct rq数据结构,this_rq()可以获取当前CPU的就绪队列struct rq。
struct rq是描述CPU的通用就绪队列,rq数据结构记录了一个就绪队列所需要的全部信息,包括一个cfs就绪队列数据结构strct cfs_rq、一个实时调度器就绪队列数据结构struct rt_rq和一个deadline就绪队列数据结构structdl_rq。
struct rq { /* runqueue lock: */ raw_spinlock_t lock; /* * nr_running and cpu_load should be in the same cacheline because * remote CPUs use both these fields when doing load calculation. */ unsigned int nr_running;-------------------------------------运行进程个数 #ifdef CONFIG_NUMA_BALANCING unsigned int nr_numa_running; unsigned int nr_preferred_running; #endif #define CPU_LOAD_IDX_MAX 5 unsigned long cpu_load[CPU_LOAD_IDX_MAX]; unsigned long last_load_update_tick; #ifdef CONFIG_NO_HZ_COMMON u64 nohz_stamp; unsigned long nohz_flags; #endif #ifdef CONFIG_NO_HZ_FULL unsigned long last_sched_tick; #endif /* capture load from *all* tasks on this cpu: */ struct load_weight load;---------------------------------------就绪队列权重。 unsigned long nr_load_updates; u64 nr_switches; struct cfs_rq cfs;---------------------------------------------cfs就绪队列 struct rt_rq rt;-----------------------------------------------rt就绪队列 struct dl_rq dl;-----------------------------------------------deadline就绪队列 #ifdef CONFIG_FAIR_GROUP_SCHED /* list of leaf cfs_rq on this cpu: */ struct list_head leaf_cfs_rq_list; struct sched_avg avg; #endif /* CONFIG_FAIR_GROUP_SCHED */ /* * This is part of a global counter where only the total sum * over all CPUs matters. A task can increase this counter on * one CPU and if it got migrated afterwards it may decrease * it on another CPU. Always updated under the runqueue lock: */ unsigned long nr_uninterruptible; struct task_struct *curr, *idle, *stop; unsigned long next_balance; struct mm_struct *prev_mm; unsigned int clock_skip_update; u64 clock; u64 clock_task; atomic_t nr_iowait; #ifdef CONFIG_SMP struct root_domain *rd; struct sched_domain *sd; unsigned long cpu_capacity; unsigned char idle_balance; /* For active balancing */ int post_schedule; int active_balance; int push_cpu; struct cpu_stop_work active_balance_work; /* cpu of this runqueue: */ int cpu; int online; struct list_head cfs_tasks; u64 rt_avg; u64 age_stamp; u64 idle_stamp; u64 avg_idle; /* This is used to determine avg_idle's max value */ u64 max_idle_balance_cost; #endif #ifdef CONFIG_IRQ_TIME_ACCOUNTING u64 prev_irq_time; #endif #ifdef CONFIG_PARAVIRT u64 prev_steal_time; #endif #ifdef CONFIG_PARAVIRT_TIME_ACCOUNTING u64 prev_steal_time_rq; #endif /* calc_load related fields */ unsigned long calc_load_update; long calc_load_active; #ifdef CONFIG_SCHED_HRTICK #ifdef CONFIG_SMP int hrtick_csd_pending; struct call_single_data hrtick_csd; #endif struct hrtimer hrtick_timer; #endif #ifdef CONFIG_SCHEDSTATS /* latency stats */ struct sched_info rq_sched_info; unsigned long long rq_cpu_time; /* could above be rq->cfs_rq.exec_clock + rq->rt_rq.rt_runtime ? */ /* sys_sched_yield() stats */ unsigned int yld_count; /* schedule() stats */ unsigned int sched_count; unsigned int sched_goidle; /* try_to_wake_up() stats */ unsigned int ttwu_count; unsigned int ttwu_local; #endif #ifdef CONFIG_SMP struct llist_head wake_list; #endif #ifdef CONFIG_CPU_IDLE /* Must be inspected within a rcu lock section */ struct cpuidle_state *idle_state; #endif }; struct cfs_rq { struct load_weight load;------------------------------------cfs就绪队列的权重 unsigned int nr_running, h_nr_running; u64 exec_clock; u64 min_vruntime;-------------------------------------------跟踪该就绪队列红黑树中最小的vruntime值。 #ifndef CONFIG_64BIT u64 min_vruntime_copy; #endif struct rb_root tasks_timeline;------------------------------运行队列红黑树根。 struct rb_node *rb_leftmost;--------------------------------红黑树最左边节点,也即为最小vruntime时间的节点,单进程选择下一个进程来运行时,就选择这个。 /* * 'curr' points to currently running entity on this cfs_rq. * It is set to NULL otherwise (i.e when none are currently running). */ struct sched_entity *curr, *next, *last, *skip; #ifdef CONFIG_SCHED_DEBUG unsigned int nr_spread_over; #endif #ifdef CONFIG_SMP /* * CFS Load tracking * Under CFS, load is tracked on a per-entity basis and aggregated up. * This allows for the description of both thread and group usage (in * the FAIR_GROUP_SCHED case). */ unsigned long runnable_load_avg, blocked_load_avg;----------runnable_load_avg跟踪该就绪队列中总平均负载。 atomic64_t decay_counter; u64 last_decay; atomic_long_t removed_load; #ifdef CONFIG_FAIR_GROUP_SCHED /* Required to track per-cpu representation of a task_group */ u32 tg_runnable_contrib; unsigned long tg_load_contrib; /* * h_load = weight * f(tg) * * Where f(tg) is the recursive weight fraction assigned to * this group. */ unsigned long h_load; u64 last_h_load_update; struct sched_entity *h_load_next; #endif /* CONFIG_FAIR_GROUP_SCHED */ #endif /* CONFIG_SMP */ #ifdef CONFIG_FAIR_GROUP_SCHED struct rq *rq; /* cpu runqueue to which this cfs_rq is attached */----本cfs_rq附着的struct rq /* * leaf cfs_rqs are those that hold tasks (lowest schedulable entity in * a hierarchy). Non-leaf lrqs hold other higher schedulable entities * (like users, containers etc.) * * leaf_cfs_rq_list ties together list of leaf cfs_rq's in a cpu. This * list is used during load balance. */ int on_list; struct list_head leaf_cfs_rq_list; struct task_group *tg; /* group that "owns" this runqueue */----------组调度数据结构 #ifdef CONFIG_CFS_BANDWIDTH int runtime_enabled; u64 runtime_expires; s64 runtime_remaining; u64 throttled_clock, throttled_clock_task; u64 throttled_clock_task_time; int throttled, throttle_count; struct list_head throttled_list; #endif /* CONFIG_CFS_BANDWIDTH */ #endif /* CONFIG_FAIR_GROUP_SCHED */ };
通过task_struct可以找到对应的cfs_rq,struct task_struct通过task_thread_info()找到thread_info;
通过struct thread_info得到cpu,通过cpu_rq()找到对应CPU的struct rq,进而找到对应的struct cfs_rq。
#define task_thread_info(task) ((struct thread_info *)(task)->stack) static inline unsigned int task_cpu(const struct task_struct *p) { return task_thread_info(p)->cpu; } DECLARE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues); #define cpu_rq(cpu) (&per_cpu(runqueues, (cpu))) #define this_rq() this_cpu_ptr(&runqueues)--------------------当前CPU的struct rq #define task_rq(p) cpu_rq(task_cpu(p))----------------------指定CPU的struct rq static inline struct cfs_rq *task_cfs_rq(struct task_struct *p) { return &task_rq(p)->cfs; }
2.2 fair_sched_class
struct sched_class是调度类操作方法,CFS调度器的调度类fair_sched_class定义了CFS相关操作方法。
这些方法的具体介绍会在下面一一介绍。
const struct sched_class fair_sched_class = { .next = &idle_sched_class, .enqueue_task = enqueue_task_fair, .dequeue_task = dequeue_task_fair, .yield_task = yield_task_fair, .yield_to_task = yield_to_task_fair, .check_preempt_curr = check_preempt_wakeup, .pick_next_task = pick_next_task_fair, .put_prev_task = put_prev_task_fair, #ifdef CONFIG_SMP .select_task_rq = select_task_rq_fair, .migrate_task_rq = migrate_task_rq_fair, .rq_online = rq_online_fair, .rq_offline = rq_offline_fair, .task_waking = task_waking_fair, #endif .set_curr_task = set_curr_task_fair, .task_tick = task_tick_fair, .task_fork = task_fork_fair, .prio_changed = prio_changed_fair, .switched_from = switched_from_fair, .switched_to = switched_to_fair, .get_rr_interval = get_rr_interval_fair, .update_curr = update_curr_fair, #ifdef CONFIG_FAIR_GROUP_SCHED .task_move_group = task_move_group_fair, #endif };
2.3 进程创建
进程创建由do_fork()函数来完成,do_fork-->copy_process参与了进程调度相关初始化。
copy_process()
sched_fork()
__sched_fork()
fair_sched_class->task_fork()->task_fork_fair()
__set_task_cpu()
update_curr()
place_entity()
wake_up_new_task()
activate_task()
enqueue_task
fair_sched_class->enqueue_task-->enqueue_task_fair()
2.3.1 sched_fork()
sched_fork()调用__sched_fork()对struct task_struct进行初始化,
int sched_fork(unsigned long clone_flags, struct task_struct *p) { unsigned long flags; int cpu = get_cpu();--------------------------------------------------禁止任务抢占并且获取cpu序号 __sched_fork(clone_flags, p); p->state = TASK_RUNNING;----------------------------------------------此时并没有真正运行,还没有加入到调度器 p->prio = current->normal_prio; /* * Revert to default priority/policy on fork if requested. */ if (unlikely(p->sched_reset_on_fork)) {-------------------------------如果sched_reset_on_fork为true,重置policy、static_prio、prio、weight、inv_weight等。 if (task_has_dl_policy(p) || task_has_rt_policy(p)) { p->policy = SCHED_NORMAL; p->static_prio = NICE_TO_PRIO(0); p->rt_priority = 0; } else if (PRIO_TO_NICE(p->static_prio) < 0) p->static_prio = NICE_TO_PRIO(0); p->prio = p->normal_prio = __normal_prio(p); set_load_weight(p); p->sched_reset_on_fork = 0; } if (dl_prio(p->prio)) { put_cpu(); return -EAGAIN; } else if (rt_prio(p->prio)) { p->sched_class = &rt_sched_class; } else { p->sched_class = &fair_sched_class;-------------------------------根据task_struct->prio选择调度器类, } if (p->sched_class->task_fork) p->sched_class->task_fork(p);-------------------------------------调用调度器类的task_fork方法,cfs对应task_fork_fair()。 raw_spin_lock_irqsave(&p->pi_lock, flags); set_task_cpu(p, cpu);-------------------------------------------------将p指定到cpu上运行,如果task_struct->stack->cpu和当前所在cpu不一致,需要将cpu相关设置到新CPU上。 raw_spin_unlock_irqrestore(&p->pi_lock, flags); #if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT) if (likely(sched_info_on())) memset(&p->sched_info, 0, sizeof(p->sched_info)); #endif #if defined(CONFIG_SMP) p->on_cpu = 0; #endif init_task_preempt_count(p);-------------------------------------------初始化preempt_count #ifdef CONFIG_SMP plist_node_init(&p->pushable_tasks, MAX_PRIO); RB_CLEAR_NODE(&p->pushable_dl_tasks); #endif put_cpu();------------------------------------------------------------启用任务抢占 return 0; }
__sched_fork()对task_struct数据结构进行初始值设定。
static void __sched_fork(unsigned long clone_flags, struct task_struct *p) { p->on_rq = 0; p->se.on_rq = 0; p->se.exec_start = 0; p->se.sum_exec_runtime = 0; p->se.prev_sum_exec_runtime = 0; p->se.nr_migrations = 0; p->se.vruntime = 0; #ifdef CONFIG_SMP p->se.avg.decay_count = 0; #endif INIT_LIST_HEAD(&p->se.group_node); #ifdef CONFIG_SCHEDSTATS memset(&p->se.statistics, 0, sizeof(p->se.statistics)); #endif RB_CLEAR_NODE(&p->dl.rb_node); init_dl_task_timer(&p->dl); __dl_clear_params(p); INIT_LIST_HEAD(&p->rt.run_list); #ifdef CONFIG_PREEMPT_NOTIFIERS INIT_HLIST_HEAD(&p->preempt_notifiers); #endif... }
task_fork_fair()参数是新创建的进程,
static void task_fork_fair(struct task_struct *p) { struct cfs_rq *cfs_rq; struct sched_entity *se = &p->se, *curr; int this_cpu = smp_processor_id();--------------------------获取当前cpu id struct rq *rq = this_rq(); unsigned long flags; raw_spin_lock_irqsave(&rq->lock, flags); update_rq_clock(rq); cfs_rq = task_cfs_rq(current);------------------------------获取当前进程所在cpu的cfs_rq curr = cfs_rq->curr; /* * Not only the cpu but also the task_group of the parent might have * been changed after parent->se.parent,cfs_rq were copied to * child->se.parent,cfs_rq. So call __set_task_cpu() to make those * of child point to valid ones. */ rcu_read_lock(); __set_task_cpu(p, this_cpu);--------------------------------将进程p和当前CUP绑定,p->wake_cpu在后续唤醒该进程时会用到这个成员。 rcu_read_unlock(); update_curr(cfs_rq);----------------------------------------更新当前调度实体的cfs_rq->curr信息 if (curr) se->vruntime = curr->vruntime; place_entity(cfs_rq, se, 1);--------------------------------cfs_rq是父进程对应的cfs就绪队列,se对应的是进程p调度实体,initial为1。 if (sysctl_sched_child_runs_first && curr && entity_before(curr, se)) { /* * Upon rescheduling, sched_class::put_prev_task() will place * 'current' within the tree based on its new key value. */ swap(curr->vruntime, se->vruntime); resched_curr(rq); } se->vruntime -= cfs_rq->min_vruntime; raw_spin_unlock_irqrestore(&rq->lock, flags); }
set_task_cpu()将进程和指定的cpu绑定。
update_curr()是cfs调度器核心函数,主要更新cfs_rq->curr,即当前调度实体。
主要更新了调度实体的vruntime、sum_exec_runtime、exec_start等等。
void set_task_cpu(struct task_struct *p, unsigned int new_cpu)
{
if (task_cpu(p) != new_cpu) {
if (p->sched_class->migrate_task_rq)
p->sched_class->migrate_task_rq(p);
p->se.nr_migrations++;
perf_event_task_migrate(p);
}
__set_task_cpu(p, new_cpu);
}
static inline void __set_task_cpu(struct task_struct *p, unsigned int cpu) { set_task_rq(p, cpu); #ifdef CONFIG_SMP /* * After ->cpu is set up to a new value, task_rq_lock(p, ...) can be * successfuly executed on another CPU. We must ensure that updates of * per-task data have been completed by this moment. */ smp_wmb(); task_thread_info(p)->cpu = cpu; p->wake_cpu = cpu; #endif } static void update_curr(struct cfs_rq *cfs_rq) { struct sched_entity *curr = cfs_rq->curr;----------------------------------curr指向父进程调度实体。 u64 now = rq_clock_task(rq_of(cfs_rq));------------------------------------获取当前就绪队列保存的rq->clock_task值,该变量在每次时钟tick到来时更新。 u64 delta_exec; if (unlikely(!curr)) return; delta_exec = now - curr->exec_start;----------------------------------------delta_exec计算该进程从上次调用update_curr()函数到现在的时间差。 if (unlikely((s64)delta_exec <= 0)) return; curr->exec_start = now; schedstat_set(curr->statistics.exec_max, max(delta_exec, curr->statistics.exec_max)); curr->sum_exec_runtime += delta_exec;---------------------------------------sum_exec_runtime直接加上delta_exec。 schedstat_add(cfs_rq, exec_clock, delta_exec); curr->vruntime += calc_delta_fair(delta_exec, curr);------------------------根据delta_exec和进程curr->load计算该进程的虚拟事件curr->vruntime。 update_min_vruntime(cfs_rq);------------------------------------------------更新当前cfs_rq->min_vruntime if (entity_is_task(curr)) {-------------------------------------------------如果curr->my_q为null,那么当前调度实体是进程 struct task_struct *curtask = task_of(curr); trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime); cpuacct_charge(curtask, delta_exec); account_group_exec_runtime(curtask, delta_exec); } account_cfs_rq_runtime(cfs_rq, delta_exec); }
place_entity()参数cfs_rq是se对应进程的父进程对应的cfs就绪队列,se是新进程调度实体,initial为1。
place_entity()考虑当前se所在cfs_rq总体权重,然后更新se->vruntime。
static void place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial) { u64 vruntime = cfs_rq->min_vruntime;-----------------------------是单步递增的,用于跟踪整个cfs就绪队列中红黑树里最小的vruntime值。 if (initial && sched_feat(START_DEBIT))--------------------------如果当前进程用于fork新进程,那么这里会对新进程的vruntime做一些惩罚,因为新创建了一个新进程导致cfs运行队列权重发生了变化。 vruntime += sched_vslice(cfs_rq, se);------------------------sched_vslice()计算得到虚拟时间作为惩罚值,累加到vruntime。 /* sleeps up to a single latency don't count. */ if (!initial) { unsigned long thresh = sysctl_sched_latency; if (sched_feat(GENTLE_FAIR_SLEEPERS)) thresh >>= 1; vruntime -= thresh; } se->vruntime = max_vruntime(se->vruntime, vruntime);--------------取se->vruntime和惩罚后的vruntime的最大值,方式vruntime回退。 } static u64 sched_vslice(struct cfs_rq *cfs_rq, struct sched_entity *se) { return calc_delta_fair(sched_slice(cfs_rq, se), se);---------------根据sched_slice()计算得到的执行时间和se中的权重,计算出虚拟时间。 } static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se) { u64 slice = __sched_period(cfs_rq->nr_running + !se->on_rq);-------根据运行中进程数目计算就绪队列调度周期长度。 for_each_sched_entity(se) {----------------------------------------遍历当前se所在就绪队列上所有的调度实体。 struct load_weight *load; struct load_weight lw; cfs_rq = cfs_rq_of(se);----------------------------------------通过sched_entity找到其所在的cfs_rq,进而获得cfs_rq->load。 load = &cfs_rq->load; if (unlikely(!se->on_rq)) { lw = cfs_rq->load; update_load_add(&lw, se->load.weight); load = &lw; } slice = __calc_delta(slice, se->load.weight, load);------------根据当前进程的权重来计算在cfs就绪队列总权重中可以瓜分的调度时间。 } return slice; }
unsigned int sysctl_sched_latency = 6000000ULL;
static unsigned int sched_nr_latency = 8;
unsigned int sysctl_sched_min_granularity = 750000ULL;
static u64 __sched_period(unsigned long nr_running)------------------计算CFS就绪对列中的一个调度周期的长度,可以理解为一个调度周期的时间片,根据当前运行的进程数目来计算。 { u64 period = sysctl_sched_latency;---------------------------------cfs默认调度时间片6ms unsigned long nr_latency = sched_nr_latency;-----------------------运行中的最大进程数目阈值 if (unlikely(nr_running > nr_latency)) {---------------------------如果运行中的进程数目大于8,按照每个进程最小的调度延时0.75ms计时,乘以进程数目来计算调度周期时间片。 period = sysctl_sched_min_granularity; period *= nr_running; } return period; }
2.3.2 wake_up_new_task()
void wake_up_new_task(struct task_struct *p) { unsigned long flags; struct rq *rq; raw_spin_lock_irqsave(&p->pi_lock, flags); #ifdef CONFIG_SMP set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0));------------重新选择CPU,有可能cpus_allowed在fork中被改变,或者之前前选择的CPU被关闭了。 #endif /* Initialize new task's runnable average */ init_task_runnable_average(p); rq = __task_rq_lock(p); activate_task(rq, p, 0);--------------------------------------------------------最终调用到enqueue_task_fair()将进程p添加到cfs就绪队列中。 p->on_rq = TASK_ON_RQ_QUEUED; trace_sched_wakeup_new(p, true); check_preempt_curr(rq, p, WF_FORK);---------------------------------------------检查是否有进程可以抢占当前正在运行的进程。 #ifdef CONFIG_SMP if (p->sched_class->task_woken) p->sched_class->task_woken(rq, p); #endif task_rq_unlock(rq, p, &flags); } void activate_task(struct rq *rq, struct task_struct *p, int flags) { if (task_contributes_to_load(p)) rq->nr_uninterruptible--; enqueue_task(rq, p, flags); } static void enqueue_task(struct rq *rq, struct task_struct *p, int flags) { update_rq_clock(rq); sched_info_queued(rq, p); p->sched_class->enqueue_task(rq, p, flags); }
enqueue_task_fair()把新进程p放入cfs就绪队列rq中。
static void enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags) { struct cfs_rq *cfs_rq; struct sched_entity *se = &p->se; for_each_sched_entity(se) {--------------------------对于没有定义CONFIG_FAIR_GROUP_SCHED的情况,只有一次结束for循环,即只有se一个调度实体。 if (se->on_rq) break; cfs_rq = cfs_rq_of(se); enqueue_entity(cfs_rq, se, flags);---------------把调度实体se添加到cfs_rq就绪队列中。 if (cfs_rq_throttled(cfs_rq)) break; cfs_rq->h_nr_running++; flags = ENQUEUE_WAKEUP; } for_each_sched_entity(se) { cfs_rq = cfs_rq_of(se); cfs_rq->h_nr_running++; if (cfs_rq_throttled(cfs_rq)) break; update_cfs_shares(cfs_rq); update_entity_load_avg(se, 1);----------------------------------------更新该调度实体的负载load_avg_contrib和就绪队列负载runnable_load_avg。 } if (!se) { update_rq_runnable_avg(rq, rq->nr_running); add_nr_running(rq, 1); } hrtick_update(rq); } static void enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags) { /* * Update the normalized vruntime before updating min_vruntime * through calling update_curr(). */ if (!(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_WAKING)) se->vruntime += cfs_rq->min_vruntime; /* * Update run-time statistics of the 'current'. */ update_curr(cfs_rq);-------------------------------------------------------更新当前进程的vruntime和该cfs就绪队列的min_vruntime。 enqueue_entity_load_avg(cfs_rq, se, flags & ENQUEUE_WAKEUP);---------------计算调度实体se的load_avg_contrib,然后添加到整个cfs就绪队列总平局负载cfs_rq->runnable_load_avg中。 account_entity_enqueue(cfs_rq, se); update_cfs_shares(cfs_rq); if (flags & ENQUEUE_WAKEUP) {-----------------------------------------------处理刚被唤醒的进程。 place_entity(cfs_rq, se, 0);--------------------------------------------对唤醒进程有一定补偿,最多可以补偿一个调度周期的一般,即vruntime减去半个调度周期时间。 enqueue_sleeper(cfs_rq, se); } update_stats_enqueue(cfs_rq, se); check_spread(cfs_rq, se); if (se != cfs_rq->curr) __enqueue_entity(cfs_rq, se);-------------------------------------------把调度实体se加入到cfs就绪队列的红黑树中。 se->on_rq = 1;--------------------------------------------------------------表示该调度实体已经在cfs就绪队列中。 if (cfs_rq->nr_running == 1) { list_add_leaf_cfs_rq(cfs_rq); check_enqueue_throttle(cfs_rq); } }
check_preempt_curr()用于检查是否有新进程抢占当前进程。
void check_preempt_curr(struct rq *rq, struct task_struct *p, int flags) { const struct sched_class *class; if (p->sched_class == rq->curr->sched_class) { rq->curr->sched_class->check_preempt_curr(rq, p, flags); } else { for_each_class(class) { if (class == rq->curr->sched_class) break; if (class == p->sched_class) { resched_curr(rq); break; } } } /* * A queue event has occurred, and we're going to schedule. In * this case, we can save a useless back to back clock update. */ if (task_on_rq_queued(rq->curr) && test_tsk_need_resched(rq->curr)) rq_clock_skip_update(rq, true); } static void check_preempt_wakeup(struct rq *rq, struct task_struct *p, int wake_flags) { struct task_struct *curr = rq->curr; struct sched_entity *se = &curr->se, *pse = &p->se; struct cfs_rq *cfs_rq = task_cfs_rq(curr); int scale = cfs_rq->nr_running >= sched_nr_latency; int next_buddy_marked = 0; if (unlikely(se == pse)) return; /* * This is possible from callers such as attach_tasks(), in which we * unconditionally check_prempt_curr() after an enqueue (which may have * lead to a throttle). This both saves work and prevents false * next-buddy nomination below. */ if (unlikely(throttled_hierarchy(cfs_rq_of(pse)))) return; if (sched_feat(NEXT_BUDDY) && scale && !(wake_flags & WF_FORK)) { set_next_buddy(pse); next_buddy_marked = 1; } /* * We can come here with TIF_NEED_RESCHED already set from new task * wake up path. * * Note: this also catches the edge-case of curr being in a throttled * group (e.g. via set_curr_task), since update_curr() (in the * enqueue of curr) will have resulted in resched being set. This * prevents us from potentially nominating it as a false LAST_BUDDY * below. */ if (test_tsk_need_resched(curr)) return; /* Idle tasks are by definition preempted by non-idle tasks. */ if (unlikely(curr->policy == SCHED_IDLE) && likely(p->policy != SCHED_IDLE)) goto preempt; /* * Batch and idle tasks do not preempt non-idle tasks (their preemption * is driven by the tick): */ if (unlikely(p->policy != SCHED_NORMAL) || !sched_feat(WAKEUP_PREEMPTION)) return; find_matching_se(&se, &pse); update_curr(cfs_rq_of(se)); BUG_ON(!pse); if (wakeup_preempt_entity(se, pse) == 1) { /* * Bias pick_next to pick the sched entity that is * triggering this preemption. */ if (!next_buddy_marked) set_next_buddy(pse); goto preempt; } return; preempt: resched_curr(rq); /* * Only set the backward buddy when the current task is still * on the rq. This can happen when a wakeup gets interleaved * with schedule on the ->pre_schedule() or idle_balance() * point, either of which can * drop the rq lock. * * Also, during early boot the idle thread is in the fair class, * for obvious reasons its a bad idea to schedule back to it. */ if (unlikely(!se->on_rq || curr == rq->idle)) return; if (sched_feat(LAST_BUDDY) && scale && entity_is_task(se)) set_last_buddy(se); }
3. 进程调度
__schedule()是调度器的核心函数,其作用是让调度器选择和切换到一个合适进程运行。调度轨迹如下:
__schedule()
->pick_next_task()
->pick_next_task_fair()
->context_switch()
->switch_mm()
->cpu_v7_switch_mm()
->switch_to()
->__switch_to
3.1 进程调度时机
调度的时机分为如下3种:
1. 阻塞操作:互斥量(mutex)、信号量(semaphore)、等待队列(waitqueue)等。
2. 在中断返回前和系统调用返回用户空间时,去检查TIF_NEED_RESCHED标志位以判断是否需要调度。
3. 将要被唤醒的进程不会马上调用schedule()要求被调度,而是会被添加到cfs就绪队列中,并且设置TIF_NEED_RESCHED标志位。那么唤醒进程什么时候被调度呢?这要根据内核是否具有可抢占功能(CONFIG_PREEMPT=y)分两种情况。
3.1 如果内核可抢占,则:
- 如果唤醒动作发生在系统调用或者异常处理上下文中,在下一次调用preempt_enable()时会检查是否需要抢占调度。
- 如果唤醒动作发生在硬中断处理上下文中,硬件中断处理返回前夕(不管中断发生点在内核空间还是用户空间)会检查是否要抢占当前进程。
3.2 如果内核不可抢占,则:
- 当前进程调用cond_resched()时会检查是否要调度。
- 主动调度用schedule()。
- 系统调用或者异常处理返回用户空间时。
- 中断处理完成返回用户空间时(只有中断发生点在用户空间才会检查)。
3.2 preempt_schedule()
asmlinkage __visible void __sched notrace preempt_schedule(void)
{
/*
* If there is a non-zero preempt_count or interrupts are disabled,
* we do not want to preempt the current task. Just return..
*/
if (likely(!preemptible()))
return;
preempt_schedule_common();
}
static void __sched notrace preempt_schedule_common(void)
{
do {
__preempt_count_add(PREEMPT_ACTIVE);
__schedule();
__preempt_count_sub(PREEMPT_ACTIVE);
/*
* Check again in case we missed a preemption opportunity
* between schedule and now.
*/
barrier();
} while (need_resched());
}
3.3 __schedule()
__schedule()函数调用pick_next_task()让进程调度器从就绪队列中选择一个最合适的进程next,然后context_switch()切换到next进程运行。
static void __sched __schedule(void) { struct task_struct *prev, *next; unsigned long *switch_count; struct rq *rq; int cpu; preempt_disable(); cpu = smp_processor_id(); rq = cpu_rq(cpu); rcu_note_context_switch(); prev = rq->curr; schedule_debug(prev); if (sched_feat(HRTICK)) hrtick_clear(rq); smp_mb__before_spinlock(); raw_spin_lock_irq(&rq->lock); rq->clock_skip_update <<= 1; /* promote REQ to ACT */ switch_count = &prev->nivcsw; if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {--------------当前进程状态不处于TASK_RUNNING状态, if (unlikely(signal_pending_state(prev->state, prev))) { prev->state = TASK_RUNNING; } else { deactivate_task(rq, prev, DEQUEUE_SLEEP); prev->on_rq = 0; if (prev->flags & PF_WQ_WORKER) { struct task_struct *to_wakeup; to_wakeup = wq_worker_sleeping(prev, cpu); if (to_wakeup) try_to_wake_up_local(to_wakeup); } } switch_count = &prev->nvcsw; } if (task_on_rq_queued(prev)) update_rq_clock(rq); next = pick_next_task(rq, prev);---------------------------------------调用pick_next_task_fair()从就绪队列rq上选择合适的进程返回给next。 clear_tsk_need_resched(prev); clear_preempt_need_resched(); rq->clock_skip_update = 0; if (likely(prev != next)) {--------------------------------------------如果待切入的进程next和待切出的进程next不等,那么调用context_switch()进行上下文切换。 rq->nr_switches++; rq->curr = next; ++*switch_count; rq = context_switch(rq, prev, next); /* unlocks the rq */ cpu = cpu_of(rq); } else raw_spin_unlock_irq(&rq->lock); post_schedule(rq); sched_preempt_enable_no_resched(); }
下面重点分析选择待切入函数pick_next_task()和进行切换函数context_switch()两部分。
3.3.1 pick_next_task()
pick_next_task()是对调度类中pick_next_task()方法的包裹,这里主要对应cfs调度策略的pick_next_task_fair()。
/* * Pick up the highest-prio task: */ static inline struct task_struct * pick_next_task(struct rq *rq, struct task_struct *prev) { const struct sched_class *class = &fair_sched_class; struct task_struct *p; /* * Optimization: we know that if all tasks are in * the fair class we can call that function directly: */ if (likely(prev->sched_class == class && rq->nr_running == rq->cfs.h_nr_running)) {------------------------如果当前进程prev的调度类是cfs,并且该CPU就绪队列中进程数量等于cfs就绪队列中进程数量。说明该CPU就绪队列中只有普通进程没有其它调度类进程。 p = fair_sched_class.pick_next_task(rq, prev); if (unlikely(p == RETRY_TASK)) goto again; /* assumes fair_sched_class->next == idle_sched_class */ if (unlikely(!p)) p = idle_sched_class.pick_next_task(rq, prev); return p; } again: for_each_class(class) {--------------------------------------------------其它情况就需要遍历整个调度类,优先级为stop->deadline->realtime->cfs->idle。从这里也可以看出不同调度策略的优先级。 p = class->pick_next_task(rq, prev); if (p) { if (unlikely(p == RETRY_TASK)) goto again; return p; } } BUG(); /* the idle class will always have a runnable task */ } static struct task_struct * pick_next_task_fair(struct rq *rq, struct task_struct *prev) { struct cfs_rq *cfs_rq = &rq->cfs; struct sched_entity *se; struct task_struct *p; int new_tasks; again: #ifdef CONFIG_FAIR_GROUP_SCHED ... #endif if (!cfs_rq->nr_running)--------------------------------如果cfs就绪队列上没有进程,那么选择idle进程。 goto idle; put_prev_task(rq, prev); do { se = pick_next_entity(cfs_rq, NULL);----------------选择cfs就绪队列中的红黑树最左边进程。 set_next_entity(cfs_rq, se); cfs_rq = group_cfs_rq(se);--------------------------如果定义CONFIG_FAIR_GROUP_SCHED,需要遍历cfs_rq->rq上的就绪队列。如果没定义,则返回NULL。 } while (cfs_rq); p = task_of(se); if (hrtick_enabled(rq)) hrtick_start_fair(rq, p); return p; idle: new_tasks = idle_balance(rq); /* * Because idle_balance() releases (and re-acquires) rq->lock, it is * possible for any higher priority task to appear. In that case we * must re-start the pick_next_entity() loop. */ if (new_tasks < 0) return RETRY_TASK; if (new_tasks > 0) goto again; return NULL; }
在没有定义CONFIG_FAIR_GROUP_SCHED的情况下,pick_next_entity()参数curr为NULL。表示pick_next_entity()优先获取cfs_rq->rb_leftmost结点。
set_next_entity()将cfs_rq->curr指向se,并且更行se的exec_start和prev_sum_exec_runtime。
static struct sched_entity * pick_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *curr) { struct sched_entity *left = __pick_first_entity(cfs_rq); struct sched_entity *se; /* * If curr is set we have to see if its left of the leftmost entity * still in the tree, provided there was anything in the tree at all. */ if (!left || (curr && entity_before(curr, left)))-----------------如果left不存在,left指向curr;或者left存在,curr不为NULL且curr的vruntime小于left的,那么left指向curr。 left = curr; se = left; /* ideally we run the leftmost entity */---------------在curr为NULL情况下,se即cfs_rq的最左侧节点。 ... /* * Prefer last buddy, try to return the CPU to a preempted task. */ if (cfs_rq->last && wakeup_preempt_entity(cfs_rq->last, left) < 1)----如果cfs_rq->last存在,且其vruntime小于left的。那么更新se为cfs_rq->last。 se = cfs_rq->last; /* * Someone really wants this to run. If it's not unfair, run it. */ if (cfs_rq->next && wakeup_preempt_entity(cfs_rq->next, left) < 1)----类似于cfs_rq->next,如果cfs_rq->next小于left的vruntime,那么更新se为cfs_rq->next。 se = cfs_rq->next; clear_buddies(cfs_rq, se); return se; } static void set_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *se) { /* 'current' is not kept within the tree. */ if (se->on_rq) {-----------------------------------------------------如果当前调度实体在就绪队列,则移除。 /* * Any task has to be enqueued before it get to execute on * a CPU. So account for the time it spent waiting on the * runqueue. */ update_stats_wait_end(cfs_rq, se); __dequeue_entity(cfs_rq, se); } update_stats_curr_start(cfs_rq, se); cfs_rq->curr = se; #ifdef CONFIG_SCHEDSTATS /* * Track our maximum slice length, if the CPU's load is at * least twice that of our own weight (i.e. dont track it * when there are only lesser-weight tasks around): */ if (rq_of(cfs_rq)->load.weight >= 2*se->load.weight) { se->statistics.slice_max = max(se->statistics.slice_max, se->sum_exec_runtime - se->prev_sum_exec_runtime); } #endif se->prev_sum_exec_runtime = se->sum_exec_runtime; }
3.3.2 context_switch()
context_switch()共3个参数,其中rq表示进程切换所在的就绪队列,prev将要被换出的进程,next将要被换入执行的进程。
/* * context_switch - switch to the new MM and the new thread's register state. */ static inline struct rq * context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next) { struct mm_struct *mm, *oldmm; prepare_task_switch(rq, prev, next);-----------和finish_task_switch()成对操作,其中next->on_cpu置1。 mm = next->mm; oldmm = prev->active_mm; /* * For paravirt, this is coupled with an exit in switch_to to * combine the page table reload and the switch backend into * one hypercall. */ arch_start_context_switch(prev); if (!mm) {-------------------------------------对于内核线程来说是没有进程地址空间的 next->active_mm = oldmm;-------------------因为进程调度的需要,需要借用一个进程的地址空间,因此有了active_mm成员。为什么不用prev->mm呢?因为prev也可能是内核线程。 atomic_inc(&oldmm->mm_count); enter_lazy_tlb(oldmm, next); } else switch_mm(oldmm, mm, next);----------------对普通进程,需要调用switch_mm()函数做一些进程地址空间切换的处理。 if (!prev->mm) {-------------------------------对于prev是内核线程情况,prev->active_mm为NULL,rq->prev_mm记录prev->active_mm。 prev->active_mm = NULL; rq->prev_mm = oldmm; } /* * Since the runqueue lock will be released by the next * task (which is an invalid locking op but in the case * of the scheduler it's an obvious special-case), so we * do an early lockdep release here: */ spin_release(&rq->lock.dep_map, 1, _THIS_IP_); context_tracking_task_switch(prev, next); /* Here we just switch the register state and the stack. */ switch_to(prev, next, prev);-------------------切换进程,从prev进程切换到next进程来运行。该函数完成时,CPU运行next进程,prev进程被调度出去,俗称“睡眠”。 barrier(); return finish_task_switch(prev);---------------进程切换后的清理工作,prev->on_cpu置0,递减old_mm->mm_count,由next处理prev进程残局。 }
switch_mm()和switch_to()都是体系结构密切相关函数。
switch_mm()把新进程页表基地址设置到页目录表基地址寄存器中。
switch_mm()首先把当前CPU设置到下一个进程的cpumask位图中,然后调用check_and_switch_context()来完成ARM体系结构相关的硬件设置,例如flush TLB。
/* * This is the actual mm switch as far as the scheduler * is concerned. No registers are touched. We avoid * calling the CPU specific function when the mm hasn't * actually changed. */ static inline void switch_mm(struct mm_struct *prev, struct mm_struct *next, struct task_struct *tsk) { #ifdef CONFIG_MMU unsigned int cpu = smp_processor_id(); /* * __sync_icache_dcache doesn't broadcast the I-cache invalidation, * so check for possible thread migration and invalidate the I-cache * if we're new to this CPU. */ if (cache_ops_need_broadcast() && !cpumask_empty(mm_cpumask(next)) && !cpumask_test_cpu(cpu, mm_cpumask(next))) __flush_icache_all(); if (!cpumask_test_and_set_cpu(cpu, mm_cpumask(next)) || prev != next) { check_and_switch_context(next, tsk); if (cache_is_vivt()) cpumask_clear_cpu(cpu, mm_cpumask(prev)); } #endif }
switch_to()最终调用__switch_to()汇编函数。
__switch_to()包含三个参数,r0是移出进程(prev)的task_struct结构,r1是移出进程(task_thread_info(prev))的thread_info结构,r2是移入进程(task_thread_info(next))的thread_info结构。
这里把prev进程相关寄存器上下文保存到该进程的thread_info->cpu_context结构体中,然后再把next进程thread_info->cpu_context结构体中的值设置到物理CPU寄存器中,从而实现进程堆栈的切换。
#define switch_to(prev,next,last) \ do { \ last = __switch_to(prev,task_thread_info(prev), task_thread_info(next)); \ } while (0) /* * Register switch for ARMv3 and ARMv4 processors * r0 = previous task_struct, r1 = previous thread_info, r2 = next thread_info * previous and next are guaranteed not to be the same. */ ENTRY(__switch_to) UNWIND(.fnstart ) UNWIND(.cantunwind ) add ip, r1, #TI_CPU_SAVE ARM( stmia ip!, {r4 - sl, fp, sp, lr} ) @ Store most regs on stack THUMB( stmia ip!, {r4 - sl, fp} ) @ Store most regs on stack THUMB( str sp, [ip], #4 ) THUMB( str lr, [ip], #4 ) ldr r4, [r2, #TI_TP_VALUE] ldr r5, [r2, #TI_TP_VALUE + 4] #ifdef CONFIG_CPU_USE_DOMAINS ldr r6, [r2, #TI_CPU_DOMAIN] #endif switch_tls r1, r4, r5, r3, r7 #if defined(CONFIG_CC_STACKPROTECTOR) && !defined(CONFIG_SMP) ldr r7, [r2, #TI_TASK] ldr r8, =__stack_chk_guard ldr r7, [r7, #TSK_STACK_CANARY] #endif #ifdef CONFIG_CPU_USE_DOMAINS mcr p15, 0, r6, c3, c0, 0 @ Set domain register #endif mov r5, r0 add r4, r2, #TI_CPU_SAVE ldr r0, =thread_notify_head mov r1, #THREAD_NOTIFY_SWITCH bl atomic_notifier_call_chain #if defined(CONFIG_CC_STACKPROTECTOR) && !defined(CONFIG_SMP) str r7, [r8] #endif THUMB( mov ip, r4 ) mov r0, r5 ARM( ldmia r4, {r4 - sl, fp, sp, pc} ) @ Load all regs saved previously THUMB( ldmia ip!, {r4 - sl, fp} ) @ Load all regs saved previously THUMB( ldr sp, [ip], #4 ) THUMB( ldr pc, [ip] ) UNWIND(.fnend ) ENDPROC(__switch_to)
3.4 调度实体sched_entity红黑树操作
cfs使用红黑树来管理调度实体,红黑树的键值为sched_entity->vruntime。
__enqueue_entity()用于将调度实体se键入到cfs_rq运行队列上,具体是加入到cfs_rq->tasks_timeline的红黑树上。
/* * Enqueue an entity into the rb-tree: */ static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se) { struct rb_node **link = &cfs_rq->tasks_timeline.rb_node;----------------------取当前cfs_rq->tasks_timeline树上的第一个节点,注意不一定是最左侧节点。 struct rb_node *parent = NULL; struct sched_entity *entry; int leftmost = 1; /* * Find the right place in the rbtree: */ while (*link) {---------------------------------------------------------------从第一个节点开始遍历当前cfs_rq红黑树,知道找到空的插入节点。 parent = *link; entry = rb_entry(parent, struct sched_entity, run_node);------------------通过parent找到其对应的调度实体 /* * We dont care about collisions. Nodes with * the same key stay together. */ if (entity_before(se, entry)) {-------------------------------------------如果se->vruntime < entry->vruntime则条件成立,插入点指向entry对应的左节点。 link = &parent->rb_left; } else {------------------------------------------------------------------否则插入点指向entry对应的右节点,则leftmost为0。 link = &parent->rb_right; leftmost = 0; } } /* * Maintain a cache of leftmost tree entries (it is frequently * used): */ if (leftmost)----------------------------------------------------------------如果新插入的节点为最左侧节点,那么需要改变cfs_rq->rb_leftmost。 cfs_rq->rb_leftmost = &se->run_node; rb_link_node(&se->run_node, parent, link);-----------------------------------将link指向se->run_node rb_insert_color(&se->run_node, &cfs_rq->tasks_timeline);---------------------在将se->run_node插入后,进行平衡调整。 } static void __dequeue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se) { if (cfs_rq->rb_leftmost == &se->run_node) {---------------------------------如果待删除的节点是cfs_rq->rb_leftmose,那么还需要更新cfs_rq->rb_leftmost,然后再删除。 struct rb_node *next_node; next_node = rb_next(&se->run_node); cfs_rq->rb_leftmost = next_node; } rb_erase(&se->run_node, &cfs_rq->tasks_timeline);---------------------------从cfs_rq->tasks_timeline删除节点se->run_node。 } struct sched_entity *__pick_first_entity(struct cfs_rq *cfs_rq)-----------------获取cfs_rq->rb_leftmost对应的调度实体。 { struct rb_node *left = cfs_rq->rb_leftmost; if (!left) return NULL; return rb_entry(left, struct sched_entity, run_node); } static struct sched_entity *__pick_next_entity(struct sched_entity *se)----------获取当前调度实体右侧的调度实体。 { struct rb_node *next = rb_next(&se->run_node); if (!next) return NULL; return rb_entry(next, struct sched_entity, run_node); } struct sched_entity *__pick_last_entity(struct cfs_rq *cfs_rq)------------------获取cfs_rq最右侧的调度实体。 { struct rb_node *last = rb_last(&cfs_rq->tasks_timeline);--------------------rb_last在cfs_rq->tasks_timeline不停遍历右节点,直到最后一个。 if (!last) return NULL; return rb_entry(last, struct sched_entity, run_node); }
static inline int entity_before(struct sched_entity *a,
struct sched_entity *b)
{
return (s64)(a->vruntime - b->vruntime) < 0;----------------------------比较调度实体a->vruntime和b->vruntime,如果a before b返回true。
}
4. schedule tick
时钟分为周期性时钟和单次触发时钟,通过clockevents_register_device()进行注册。
广播和非广播时钟的区别在于设备的clock_event_device->cpumask设置。
clockevnets_register_device()
->tick_check_new_device()
->tick_setup_device()
->tick_setup_periodic()-----------------------------如果tick_device->mode定义为TICKDEV_MODE_PERIODIC,则注册为周期性时钟。
->tick_set_periodic_handler()
->tick_handle_periodic()------------------------周期性时钟
->tick_handle_periodic_broadcast()---------周期性广播时钟
->tick_setup_oneshot()-----------------------------如果tick_device->mode定义为TICKDEV_MODE_ONESHOT,则为单次触发时钟。
tick_set_periodic_handler()将struct clock_event_device的event_handler设置为tick_handle_periodic()。
上面是时钟的注册,时钟是由中断驱动的,在中断的处理函数中会调用到clock_event_device->event_handler()。
对于周期性时钟对应函数为tick_handle_periodic()-->tick_periodic()-->update_process_times()-->scheduler_tick()。
/* * This function gets called by the timer code, with HZ frequency. * We call it with interrupts disabled. */ void scheduler_tick(void) { int cpu = smp_processor_id(); struct rq *rq = cpu_rq(cpu); struct task_struct *curr = rq->curr; sched_clock_tick(); raw_spin_lock(&rq->lock); update_rq_clock(rq);--------------------------更新当前CPU就绪队列rq中的时钟计数clock和clock_task。 curr->sched_class->task_tick(rq, curr, 0);----对应调度类方法task_tick,cfs调度类对应task_tick_fair(),用于处理时钟tick到来时与调度器相关的事情。 update_cpu_load_active(rq);-------------------更新运行队列中的cpu_load[] raw_spin_unlock(&rq->lock); perf_event_task_tick(); #ifdef CONFIG_SMP rq->idle_balance = idle_cpu(cpu); trigger_load_balance(rq); #endif rq_last_tick_reset(rq); }
task_tick_fair()是cfs调度类task_tick()对应函数,首先调用entity_tick()检查是否需要调度,然后调用update_rq_runnable_avg更新该就绪队列的统计信息。
/* * scheduler tick hitting a task of our scheduling class: */ static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued) { struct cfs_rq *cfs_rq; struct sched_entity *se = &curr->se; for_each_sched_entity(se) { cfs_rq = cfs_rq_of(se);-----------------------由sched_entity找到对应task_struct,进而找到所在的就绪队列,再找到cfs_rq。 entity_tick(cfs_rq, se, queued);--------------除了更新se和cfs_rq的统计信息之外,调用check_preempt_tick()检查是否需要调度。 } if (numabalancing_enabled) task_tick_numa(rq, curr); update_rq_runnable_avg(rq, 1); }
static void entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued) { /* * Update run-time statistics of the 'current'. */ update_curr(cfs_rq);------------------------------------更新当前进程的vruntime、exec_start等和就绪队列cfs_rq的min_vruntime等。 /* * Ensure that runnable average is periodically updated. */ update_entity_load_avg(curr, 1);------------------------更新curr调度实体的sched_avg参数load_avg_contrib等。 update_cfs_rq_blocked_load(cfs_rq, 1); update_cfs_shares(cfs_rq); ... if (cfs_rq->nr_running > 1) check_preempt_tick(cfs_rq, curr);------------------如果当前就绪队列运行中进程数nr_running大于1,check_preempt_tick()进行检查当前进程是否需要让出CPU。 }
/* * Preempt the current task with a newly woken task if needed: */ static void check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr) { unsigned long ideal_runtime, delta_exec; struct sched_entity *se; s64 delta; ideal_runtime = sched_slice(cfs_rq, curr);----------------------------该进程根据权重在一个调度周期里分到的实际运行时间,和sched_vslice()得到的虚拟运行时间区别。 delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;----delta_exec是该进程已经运行的实际时间 if (delta_exec > ideal_runtime) {-------------------------------------如果实际运行时间超过了理论分配运行时间,那么该进程需要被调度出去,设置该进程thread_info中TIF_NEED_RESCHED标志位。 resched_curr(rq_of(cfs_rq)); /* * The current task ran long enough, ensure it doesn't get * re-elected due to buddy favours. */ clear_buddies(cfs_rq, curr); return; } if (delta_exec < sysctl_sched_min_granularity)------------------------如果进程实际运行时间小于sysctl_sched_min_granularity(0.75ms),那么同样不需要调度。 return; se = __pick_first_entity(cfs_rq);-------------------------------------选择当前cfs_rq就绪队列最左侧调度实体。 delta = curr->vruntime - se->vruntime; if (delta < 0)--------------------------------------------------------如果当前curr->vruntime小于最左侧调度实体vruntime,同样不需要调度。 return; if (delta > ideal_runtime)--------------------------------------------这里为什么要这么比?delta是虚拟事件差值,ideal_runtime是实际时间差值。 resched_curr(rq_of(cfs_rq)); }
5. 组调度
CFS调度器的调度粒度是进程,在某些场景下希望调度粒度是组。
组与组之间的关系是公平的,组内的调度实体又是公平的。组调度就是解决这方面的应用需求。
CFS调度器定义一个数据结构来抽象组调度struct task_group。
/* task group related information */ struct task_group { struct cgroup_subsys_state css; #ifdef CONFIG_FAIR_GROUP_SCHED /* schedulable entities of this group on each cpu */ struct sched_entity **se; /* runqueue "owned" by this group on each cpu */ struct cfs_rq **cfs_rq; unsigned long shares; #ifdef CONFIG_SMP atomic_long_t load_avg; atomic_t runnable_avg; #endif #endif #ifdef CONFIG_RT_GROUP_SCHED struct sched_rt_entity **rt_se; struct rt_rq **rt_rq; struct rt_bandwidth rt_bandwidth; #endif struct rcu_head rcu; struct list_head list; struct task_group *parent; struct list_head siblings; struct list_head children; #ifdef CONFIG_SCHED_AUTOGROUP struct autogroup *autogroup; #endif struct cfs_bandwidth cfs_bandwidth; }
5.1 创建组调度
组调度属于cgroup架构中的cpu子系统,在系统配置时需要打开CONFIG_CGROUP_SCHED和CONFIG_FAIR_GROUP_SCHED。
创建一个组调度的接口是sched_create_group()。
/* allocate runqueue etc for a new task group */ struct task_group *sched_create_group(struct task_group *parent)-----------parent指上一级的组调度节点,系统中有一个组调度的根root_task_group。 { struct task_group *tg; tg = kzalloc(sizeof(*tg), GFP_KERNEL);---------------------------------分配task_group数据结构 if (!tg) return ERR_PTR(-ENOMEM); if (!alloc_fair_sched_group(tg, parent))-------------------------------创建cfs调度器需要的组调度数据结构 goto err; if (!alloc_rt_sched_group(tg, parent))---------------------------------创建rt调度器需要的组调度数据结构 goto err; return tg; err: free_sched_group(tg); return ERR_PTR(-ENOMEM); }
alloc_fair_sched_group()创建cfs调度器需要的组调度数据结构。
int alloc_fair_sched_group(struct task_group *tg, struct task_group *parent) { struct cfs_rq *cfs_rq; struct sched_entity *se; int i; tg->cfs_rq = kzalloc(sizeof(cfs_rq) * nr_cpu_ids, GFP_KERNEL);--分配NR_CPUS个cfs_rq数据结构,存放到指针数组中,这里数据结构不是struct cfs_rq。 if (!tg->cfs_rq) goto err; tg->se = kzalloc(sizeof(se) * nr_cpu_ids, GFP_KERNEL);----------分配NR_CPUS个se数据结构,注意这里不是struct sched_entity。 if (!tg->se) goto err; tg->shares = NICE_0_LOAD;---------------------------------------调度组的权重初始化为NICE值为0的权重。 init_cfs_bandwidth(tg_cfs_bandwidth(tg)); for_each_possible_cpu(i) {--------------------------------------遍历系统中所有possible CPU,为每个CPU分配一个struct cfs_rq调度队列和struct sched_entity调度实体。 cfs_rq = kzalloc_node(sizeof(struct cfs_rq),----------------之前分配的是指针数组,这里为每个CPU分配struct cfs_rq和struct sched_entity数据结构。 GFP_KERNEL, cpu_to_node(i)); if (!cfs_rq) goto err; se = kzalloc_node(sizeof(struct sched_entity), GFP_KERNEL, cpu_to_node(i)); if (!se) goto err_free_rq; init_cfs_rq(cfs_rq);----------------------------------------初始化cfs_rq就绪队列中的tasks_timeline和min_vruntime等信息。 init_tg_cfs_entry(tg, cfs_rq, se, i, parent->se[i]);--------构建组调度结构的关键函数。 } return 1; err_free_rq: kfree(cfs_rq); err: return 0; }
init_cfs_rq()初始化cfs_rq的tasks_timeline红黑树、min_vruntime。
init_tg_cfs_entry()初始化构建组调度结构的关键函数,,将rg和cfs_rq关联,。
void init_cfs_rq(struct cfs_rq *cfs_rq) { cfs_rq->tasks_timeline = RB_ROOT; cfs_rq->min_vruntime = (u64)(-(1LL << 20)); #ifndef CONFIG_64BIT cfs_rq->min_vruntime_copy = cfs_rq->min_vruntime; #endif #ifdef CONFIG_SMP atomic64_set(&cfs_rq->decay_counter, 1); atomic_long_set(&cfs_rq->removed_load, 0); #endif } void init_tg_cfs_entry(struct task_group *tg, struct cfs_rq *cfs_rq, struct sched_entity *se, int cpu, struct sched_entity *parent) { struct rq *rq = cpu_rq(cpu); cfs_rq->tg = tg; cfs_rq->rq = rq; init_cfs_rq_runtime(cfs_rq); tg->cfs_rq[cpu] = cfs_rq;-----------------------------将alloc_fair_sched_group()分配的指针数组和对应的数据结构关联上。 tg->se[cpu] = se; /* se could be NULL for root_task_group */ if (!se) return; if (!parent) { se->cfs_rq = &rq->cfs; se->depth = 0; } else { se->cfs_rq = parent->my_q; se->depth = parent->depth + 1; } se->my_q = cfs_rq;------------------------------------针对组调度中实体才有的my_q。 /* guarantee group entities always have weight */ update_load_set(&se->load, NICE_0_LOAD); se->parent = parent; }
5.1.1 双核task_group、cfs_rq、sched_entity、task_struct关系图
5.2 将进程加入组调度
通过调用cpu_cgrp_subsys的接口函数cpu_cgroup_attach()将今晨加入到组调度中。
struct cgroup_subsys cpu_cgrp_subsys = { ... .attach = cpu_cgroup_attach, .exit = cpu_cgroup_exit, .legacy_cftypes = cpu_files, .early_init = 1, }; static void cpu_cgroup_attach(struct cgroup_subsys_state *css, struct cgroup_taskset *tset) { struct task_struct *task; cgroup_taskset_for_each(task, tset)----------------遍历tset包含的进程链表。 sched_move_task(task);-------------------------将task进程迁移到组调度中。 } void sched_move_task(struct task_struct *tsk) { struct task_group *tg; int queued, running; unsigned long flags; struct rq *rq; rq = task_rq_lock(tsk, &flags); running = task_current(rq, tsk);--------------------------判断进程tsk是否正在运行 queued = task_on_rq_queued(tsk);--------------------------判断进程tsk是否在就绪队列里,tsk->on_rq等于TASK_ON_RQ_QUEUED表示该进程在就绪队列中。 if (queued) dequeue_task(rq, tsk, 0);-----------------------------如果进程在就绪队列中,那么要让该进程暂时先退出就绪队列。 if (unlikely(running))------------------------------------如果该进程在在运行中,刚才已经调用dequeue_task()把进程退出就绪队列,现在只能继续加回到就绪队列中。 put_prev_task(rq, tsk); /* * All callers are synchronized by task_rq_lock(); we do not use RCU * which is pointless here. Thus, we pass "true" to task_css_check() * to prevent lockdep warnings. */ tg = container_of(task_css_check(tsk, cpu_cgrp_id, true), struct task_group, css); tg = autogroup_task_group(tsk, tg); tsk->sched_task_group = tg; #ifdef CONFIG_FAIR_GROUP_SCHED if (tsk->sched_class->task_move_group) tsk->sched_class->task_move_group(tsk, queued); else #endif set_task_rq(tsk, task_cpu(tsk));---------------------将tsk对应的调度实体的cfs_rq、parent和当前CPU对应的cfs_rq、se关联起来。 if (unlikely(running)) tsk->sched_class->set_curr_task(rq); if (queued) enqueue_task(rq, tsk, 0); task_rq_unlock(rq, tsk, &flags); } static void task_move_group_fair(struct task_struct *p, int queued) { struct sched_entity *se = &p->se; struct cfs_rq *cfs_rq; if (!queued && (!se->sum_exec_runtime || p->state == TASK_WAKING)) queued = 1; if (!queued) se->vruntime -= cfs_rq_of(se)->min_vruntime; set_task_rq(p, task_cpu(p)); se->depth = se->parent ? se->parent->depth + 1 : 0; if (!queued) { cfs_rq = cfs_rq_of(se); se->vruntime += cfs_rq->min_vruntime; #ifdef CONFIG_SMP se->avg.decay_count = atomic64_read(&cfs_rq->decay_counter); cfs_rq->blocked_load_avg += se->avg.load_avg_contrib; #endif } } static inline void set_task_rq(struct task_struct *p, unsigned int cpu) { #if defined(CONFIG_FAIR_GROUP_SCHED) || defined(CONFIG_RT_GROUP_SCHED) struct task_group *tg = task_group(p);----------获取当前进程对应的task_group。 #endif #ifdef CONFIG_FAIR_GROUP_SCHED p->se.cfs_rq = tg->cfs_rq[cpu];-----------------设置调度实体的cfs_rq和parent。 p->se.parent = tg->se[cpu]; #endif... } static void enqueue_task(struct rq *rq, struct task_struct *p, int flags) { update_rq_clock(rq); sched_info_queued(rq, p); p->sched_class->enqueue_task(rq, p, flags); } static void enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags) { struct cfs_rq *cfs_rq; struct sched_entity *se = &p->se; for_each_sched_entity(se) {------------------------------在打开CONFIG_FAIR_GROUP_SCHED之后,需要遍历进程调度实体和它的上一级调度实体。第一次遍历是p->se,第二滴遍历是对应组调度实体tg->se[]。 if (se->on_rq) break; cfs_rq = cfs_rq_of(se); enqueue_entity(cfs_rq, se, flags); /* * end evaluation on encountering a throttled cfs_rq * * note: in the case of encountering a throttled cfs_rq we will * post the final h_nr_running increment below. */ if (cfs_rq_throttled(cfs_rq)) break; cfs_rq->h_nr_running++; flags = ENQUEUE_WAKEUP; } for_each_sched_entity(se) { cfs_rq = cfs_rq_of(se); cfs_rq->h_nr_running++; if (cfs_rq_throttled(cfs_rq)) break; update_cfs_shares(cfs_rq); update_entity_load_avg(se, 1); } if (!se) { update_rq_runnable_avg(rq, rq->nr_running); add_nr_running(rq, 1); } hrtick_update(rq); } static void set_curr_task_fair(struct rq *rq) { struct sched_entity *se = &rq->curr->se; for_each_sched_entity(se) { struct cfs_rq *cfs_rq = cfs_rq_of(se); set_next_entity(cfs_rq, se); /* ensure bandwidth has been allocated on our new cfs_rq */ account_cfs_rq_runtime(cfs_rq, 0); } }
组调度基本策略如下:
- 在创建组调度tg时,tg为每个CPU同时创建组调度内部使用的cfs_rq就绪队列。
- 组调度作为一个调度实体加入到系统的cfs就绪队列rq->cfs_rq中。
- 进程加入到一个组中后,就脱离了系统的cfs就绪队列,并且加入到组调度的cfs就绪队列tg->cfs_rq[]中。
- 在选择下一个进程时,从系统的cfs就绪队列开始,如果选中的调度实体是组调度tg,那么还需要继续遍历tg中的就绪队里,从中选择一个进程来运行。
5.3 组调度相关实验
6. PELT算法改进
PELT(Per-Entity Load Tracking)算法中有一个重要的变量runnable_load_avg,用于描述就绪队列基于可运行状态的总衰减累加时间(runnable time)和权重计算出来的平均负载。
在Linux 4.0中,一次只更新一个调度实体的负载,而没有更新cfs_rq所有调度实体的负载变化情况。
Linux 4.3做出了优化,在每次更新平均负载时会更新整个cfs_rq的平均负载。
struct cfs_rq中增加了struct sched_avg,并且struct sched_avg也做出了改变。
原来load_avg_contrib变成了load_avg,它是计算调度实体基于可运行时间的平均负载,并且考虑CPU频率因素。
util_avg是计算调度实体基于执行时间内的平均负载。对于就绪队列来说,这两个成员包括运行时间和阻塞时间。
struct sched_avg { /* * These sums represent an infinite geometric series and so are bound * above by 1024/(1-y). Thus we only need a u32 to store them for all * choices of y < 1-2^(-32)*1024. */ u32 runnable_avg_sum, runnable_avg_period; u64 last_runnable_update; s64 decay_count; unsigned long load_avg_contrib; }; /* * The load_avg/util_avg accumulates an infinite geometric series. * 1) load_avg factors the amount of time that a sched_entity is * runnable on a rq into its weight. For cfs_rq, it is the aggregated * such weights of all runnable and blocked sched_entities. * 2) util_avg factors frequency scaling into the amount of time * that a sched_entity is running on a CPU, in the range [0..SCHED_LOAD_SCALE]. * For cfs_rq, it is the aggregated such times of all runnable and * blocked sched_entities. * The 64 bit load_sum can: * 1) for cfs_rq, afford 4353082796 (=2^64/47742/88761) entities with * the highest weight (=88761) always runnable, we should not overflow * 2) for entity, support any load.weight always runnable */ struct sched_avg { u64 last_update_time, load_sum; u32 util_sum, period_contrib; unsigned long load_avg, util_avg; };
7. 小结


 浙公网安备 33010602011771号
浙公网安备 33010602011771号