

人脸识别常用数据集大全(12/20更新)
人脸识别常用数据集大全(12/20更新)
原文首发地址:人脸识别常用数据集大全(12/20更新) - 极市博客
1.PubFig: Public Figures Face Database(哥伦比亚大学公众人物脸部数据库)
The PubFig database is a large, real-world face dataset consisting of 58,797 images of 200 people collected from the internet. Unlike most other existing face datasets, these images are taken in completely uncontrolled situations with non-cooperative subjects.
这是哥伦比亚大学的公众人物脸部数据集,包含有200个人的58k+人脸图像,主要用于非限制场景下的人脸识别。

2.Large-scale CelebFaces Attributes (CelebA) Dataset
CelebFaces Attributes Dataset (CelebA) is a large-scale face attributes dataset with more than 200K celebrity images, each with 40 attribute annotations. The images in this dataset cover large pose variations and background clutter. CelebA has large diversities, large quantities, and rich annotations, including
10,177 number of identities,
202,599 number of face images, and
5 landmark locations, 40 binary attributes annotations per image.
这是由香港中文大学汤晓鸥教授实验室公布的大型人脸识别数据集。该数据集包含有200K张人脸图片,人脸属性有40多种,主要用于人脸属性的识别。

3.Colorferet
The database is used to develop, test, and evaluate face recognition.
为促进人脸识别算法的研究和实用化,美国国防部的Counterdrug Technology Transfer Program(CTTP)发起了一个人脸识别技术(Face Recognition Technology 简称FERET)工程,它包括了一个通用人脸库以及通用测试标准。到1997年,它已经包含了1000多人的10000多张照片,每个人包括了不同表情,光照,姿态和年龄的照片。
4.Multi-Task Facial Landmark (MTFL) dataset
This dataset contains 12,995 face images collected from the Internet. The images are annotated with (1) five facial landmarks, (2) attributes of gender, smiling, wearing glasses, and head pose.
该数据集包含了将近13000张人脸图片,均采自网络。

5.BioID Face Database - FaceDB
1521 images with human faces, recorded under natural conditions, i.e. varying illumination and complex background. The eye positions have been set manually.
这个数据集包含了1521幅分辨率为384x286像素的灰度图像。 每一幅图像来自于23个不同的测试人员的正面角度的人脸。为了便于做比较,这个数据集也包含了对人脸图像对应的手工标注的人眼位置文件。 图像以 "BioID_xxxx.pgm"的格式命名,其中xxxx代表当前图像的索引(从0开始)。类似的,形如"BioID_xxxx.eye"的文件包含了对应图像中眼睛的位置。

6.Labeled Faces in the Wild Home (LFW)
More than 13,000 images of faces collected from the web. Each face has been labeled with the name of the person pictured. 1680 of the people pictured have two or more distinct photos in the data set.
LFW数据集是为了研究非限制环境下的人脸识别问题而建立的。这个数据集包含超过13,000张人脸图像,均采集于Internet。
每个人脸均被标准了一个人名。其中,大约1680个人包含两个以上的人脸。
这个集合被广泛应用于评价Face Verification算法的性能。

7.Person identification in TV series
Face tracks, features and shot boundaries from our latest CVPR 2013 paper. It is obtained from 6 episodes of Buffy the Vampire Slayer and 6 episodes of Big Bang Theory.
该数据集所选用的人脸照片均来自于两部比较知名的电视剧,《吸血鬼猎人巴菲》和《生活大爆炸》。
8.CMUVASC & PIE Face dataset
The face datasets were provided by the face reserch group at CMU.
CMU PIE人脸库建立于2000年11月,它包括来自68个人的40000张照片,其中包括了每个人的13种姿态条件,43种光照条件和4种表情下的照片,现有的多姿态人脸识别的文献基本上都是在CMU PIE人脸库上测试的。
9.YouTube Faces
The data set contains 3,425 videos of 1,595 different people. The shortest clip duration is 48 frames, the longest clip is 6,070 frames, and the average length of a video clip is 181.3 frames.
YouTube Video Faces是用来做人脸验证的。在这个数据集下,算法需要判断两段视频里面是不是同一个人。有不少在照片上有效的方法,在视频上未必有效/高效。

10.CASIA-FaceV5
CASIA Face Image Database Version 5.0 (or CASIA-FaceV5) contains 2,500 color facial images of 500 subjects.
该数据集包含了来自500个人的2500张亚洲人脸图片.

11.The CNBC Face Database
This database includes multiple images for over 200 individuals of many different races with consistent lighting, multiple views, real emotions, and disguises (and some participants returned for a second session several weeks later with a haircut, or a new beard, etc.).
该数据集采集了200个人在不同状态下(不同的神情,装扮,发型等)的人脸照片。
12.CASIA-3D FaceV1
4624 scans of 123 persons using the non-contact 3D digitizer, Minolta Vivid 910, as shown in figure.
该数据集包含了来自123个人的4624张人脸图片,所有图片均由下图的仪器进行拍摄。

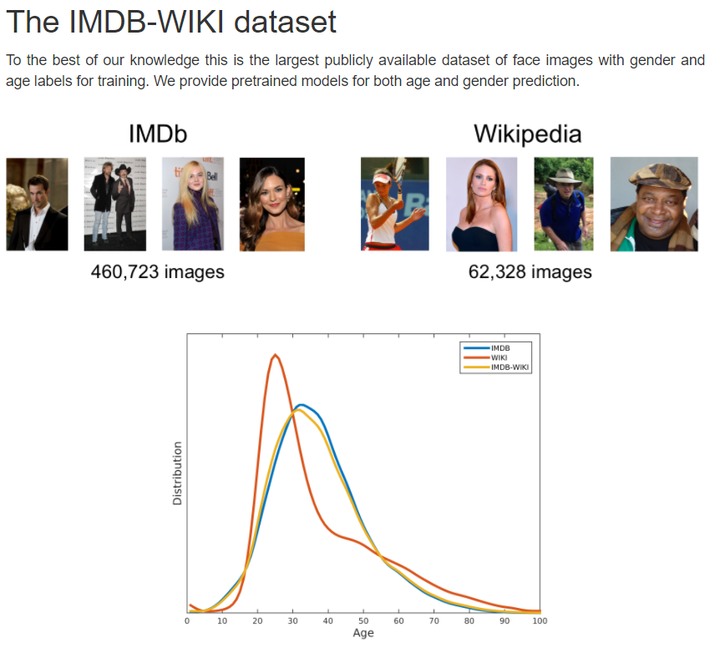
13.IMDB-WIKI
In total we obtained 460,723 face images from 20,284 celebrities from IMDb and 62,328 from Wikipedia, thus 523,051 in total.
IMDB-WIKI人脸数据库是有IMDB数据库和Wikipedia数据库组成,其中IMDB人脸数据库包含了460,723张人脸图片,而Wikipedia人脸数据库包含了62,328张人脸数据库,总共523,051张人脸数据库,IMDB-WIKI人脸数据库中的每张图片都被标注了人的年龄和性别,对于年龄识别和性别识别的研究有着重要的意义。
14.FDDB
A data set of face regions designed for studying the problem of unconstrained face detection. This data set contains the annotations for 5171 faces in a set of 2845 images taken from the Faces in the Wild data set.
FDDB是UMass的数据集,被用来做人脸检测(Face Detection)。这个数据集比较大,比较有挑战性。而且作者提供了程序用来评估检测结果,所以在这个数据上面比较算法也相对公平。

15.Caltech人脸数据库
The dataset contains images of people collected from the web by typing common given names into Google Image Search. The coordinates of the eyes, the nose and the center of the mouth for each frontal face are provided in a ground truth file. This information can be used to align and crop the human faces or as a ground truth for a face detection algorithm. The dataset has 10,524 human faces of various resolutions and in different settings, e.g. portrait images, groups of people, etc. Profile faces or very low resolution faces are not labeled.
10k+人脸,提供双眼和嘴巴的坐标位置
16.The Japanese Female Facial Expression (JAFFE) Database
The database contains 213 images of 7 facial expressions (6 basic facial expressions + 1 neutral) posed by 10 Japanese female models. Each image has been rated on 6 emotion adjectives by 60 Japanese subjects. The database was planned and assembled by Michael Lyons, Miyuki Kamachi, and Jiro Gyoba. We thank Reiko Kubota for her help as a research assistant. The photos were taken at the Psychology Department in Kyushu University.
该数据库是由10位日本女性在实验环境下根据指示做出各种表情,再由照相机拍摄获取的人脸表情图像。整个数据库一共有213张图像,10个人,全部都是女性,每个人做出7种表情,这7种表情分别是: sad, happy, angry, disgust, surprise, fear, neutral. 每个人为一组,每一组都含有7种表情,每种表情大概有3,4张样图。
所有的人脸识别数据集打包下载链接:https://pan.baidu.com/s/1bpjQNh1
密码:4xlk

