


解析纯真IP地址库
一周以来,一直在做 IP地址库的解析。从调研到编码到优化,大概花了有七八天的时间。感觉很好玩。总结一下整个做的过程。
1、关于IP 地址库的解析方式
目前主要的解析方式有两种:通过API,或通过IP数据库。
API方式很简单,目前国内大厂不少提供API接口,只要发送请求的IP,就能获得相应的地理位置。像BAT等等公司都提供IP查询接口。这种解析方式的好处在于,编码简单,一个请求获得数据,然后解析一下就好了(通常只是个json数据),而且不用维护数据库,对本地没有负担。但是缺点也挺明显的,首先是慢,发送网络请求一秒钟发不了几条,其次是有限制,比如百度限制每秒钟 250条请求,防止并发量太大造成网络阻塞,再次要受制于人,什么都要听人家的,万一今天地址换了,明天接口数据格式改了,后天要收费了……哦卖糕的。
IP数据库方式相对来讲复杂一点,需要有完善的数据库,还要建立相应的查询服务。优缺点则跟API方式正好相反:优点是查询快,不受网络和网站的限制,缺点是编码相对复杂,而且要一直维护数据库。数据库国内最著名的是纯真网络,ipip,国外更加著名的GeoIP等等。
我们在权衡利弊之后,决定采取数据库方式。听说GeoIP对国外ip 数据很完善,但是对于国内的ip还是不太全的。因此,我们初步选用纯真IP数据库来解析。
2、存储
下载下来纯真数据库的过程就不介绍了,我也没有闲心去解析dat,就直接解压成txt来做了。数据一共不到45万条。
先普及个常识,那就是IP地址实际上是一个unsigned int值。在群里询问做法的时候我发现很多人居然都不知道这一点。我们看到的IP地址,是4个0~255之间的数,而实际上在计算机中IP地址的表示是32位二进制。 01010101.10101010.00110011.11001100酱婶的。32位二进制,当然就是一个unsigned int的取值范围。IP解析也是一样,把IP转化成int 进行存储和查询,是最节省空间、最效率的方法。
书归正文,解压出来的IP地址库是酱婶的:
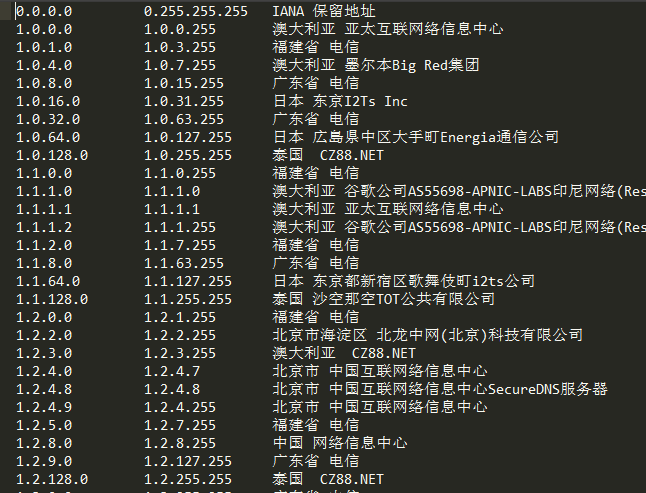
(纯真IP数据库,可以到http://www.cz88.net去下载。这个是公开的。我相信我要不说的话一定有人不知道。)
三个字段,start, end, address,从start到end之间的IP都是address这个位置。然而仔细观察可以发现,end其实并没有什么卵用。因为end跟下一个start是连接的,中间没有断开的ip。所以只需要记录start: address就好了,所以——我们得到了一个键值对。啊哈,关于键值对我们能用的武器就多了,最典型的可以用redis这样的数据库或者直接用字典。
那么查询怎么查?最简单的方法,提取keys,顺序排列,二分查找。45万条数据最多19次比较即可。注意这里我们要找的是“小于等于给定IP的最大值”。
什么?你说每一条ip对应一个address ,把所有ip的address写成一个列表?唔……也不是不可以,不过首先你的服务器得有200G内存。没错,200G。内存。
3、算法演进
3.1、首先考虑redis
我需要保持程序一直运行,即需要一个server,里面是保存好的地址结构,当我需要查询一条ip的时候,只需要发送一条请求即可。那么,如果使字典保持在内存里,就必须要程序一直运行,需要我写一个server。tcp还是udp还是http的无所谓。然而,我懒。所以首先考虑redis。毕竟人家存储结构都写好了,我都不用动脑筋,往里存就好了。
然而事实证明我想错了。
3.1.1、普通键值对
先用最简单的方法,set ip addr,全部存进去;然后查询的时候读取keys,类型转换,排序,二分,查到小于等于给定ip的最大值,行云流水的一套下来——3.2秒。泥煤这速度还不如直接发api请求呢!仔细想想,自己确实是犯二了,40多万数类型转换再排序,能快就见鬼了。
3.1.2、有序集合
考虑下一方案,一要存整数,二要有序。存整数是不可能了,在网上查到redis中的数据类型,根本没有数字相关的,只有字符串和各种序列类型。经人介绍选定有序集合。zadd ip2addr ip addr添加好。然而查询时候始终有错误。莫名其妙了好久,终于查到原因了:假设一条ip1对应地址是addr ,过不久一条ip2对应的地址也是addr,那么ip2就会把ip1覆盖掉。这不科学啊!唉,只能抛弃有序集合了。
(其实后来有大神查到还是可以用的,如果相同的addr会覆盖,那就人为的让它不同,例如可以存储addr@ip这样的形式。当时着急了,也没多想想。)
3.1.3、列表
让ip有序,最合适的还是列表。于是在redis里面我建立了两个列表,一个是ip,另一个是对应位置的addr。查询时候先获得ip列表,查到给定ip,用这个ip的索引去查找对应位置的addr。愿望是美好的,现实是残酷的。由于redis中的列表采用的是双向链表,要获取全部40多万数据也是够慢,这就造成了结果查询一条数据要360ms。而且有个看似奇怪的特性:ip值较小的,比如1.2.3.4,查询结果就4ms,而ip值大到222.222.222.222这样的就要接近400ms了。
这仍然是一个慢到不能忍的结果。
3.1.4、列表+分块
列表做出来的结果大概在300ms多,还是太慢,我在redis里面大概扫了一遍,没有什么更合适的数据结构了。那么就只能进行算法层面的优化了。观察了一下ip地址的结构,前22万条数据应该包含了前面一半ip,剩下的ip在后一半数据里,试了试从ip列表里只提取一半数据进行查询,果然时间也缩到了一半,大概170ms。那么,能否更精确的定位ip所在的位置?
想象一下42亿个ip,分散在44万条数据中,每块里面有多少个ip?肯定不是平均分布的,但是数量是可以统计的。我把int范围切分,每10^7作为一个块,那么42亿多的int数可以切分出来430块(例如ip值小于10^7放在第0区,小于2*10^7大于10^7放在第1区,等等),这样就统计出来每个块中ip的数量。下一步进行累加,算出前0块共有多少个ip,前1块有多少ip,前2块共有多少ip……举个栗子,统计ip数量的列表为[a1,a2,a3,a4...],那么累加的列表为[a1,a1+a2, a1+a2+a3, a1+a2+a3+a4...]。这个列表即ip索引。这样可以精确的定位ip。查询的时候,先计算ip属于哪个块,然后找到对应的索引,最后通过索引来找到对应的ip范围。虽然多查询了一次,但是极大地缩减了从redis中取数的数量。经测试,速度已经达到了65ms左右。
然而这个算法有两个问题:首先是块大小的设置,需要人为干预,块大小涉及到每个块里的ip数量,还涉及到块的数量,也就是索引列表的大小。这个完全靠经验,没有什么理论。另一个问题是块中ip数量为0的情况。还用刚才的栗子,有个ip列表[a1,0,0,0,a3,a4...],索引列表为[a1,a1,a1,a1,a1+a3, a1+a3+a4...] ,也就是一个ip在a1范围内,而下一条ip已经在a3范围内了。现在我查询一条ip,本应查询范围是[a1, a1+a3],而现在查询的范围变成了[a1, a1],这样必然结果错误。我也没有太好的办法解决,现在想到的只能是再记录一下ip数量表,现查询一下ip所在块是不是0,如果是,就去找到在这之前第一个不为0的块。这样性能肯定是要下降的。
3.2、内存
3.2.1、有序字典
碰到问题后,询问了一下q群里的大神们。几个做过的人都是自己写服务的。唉,本想偷懒,折腾了一圈反倒把自己坑了。于是自己写socket来做。存储结构为了保持整数和有序,使用OrderedDict来保存。像以前那样拿到keys,二分,查询,看眼时间,哭了,怎么还是50ms?
3.2.2、字典+列表
继续请教大神们,怎么做的,得到的答案是用列表。恍然大悟。用dict.iteritems()这种形式的列表,既能保持字典的键值对形状,又是有序的。OrderedDict内部使用双向链表,当然怎么算都是列表更快。在原来的基础上简单的改了改,重新测一下,1ms。1ms?!对比了一下ip库,似乎结果并没有错。
那好吧,就到这里了,这个问题就可以暂时告一段落了。从个人来讲我觉得最有趣的是中间redis列表+分块那个算法,不能应用实在可惜,因为在后面的算法中,主要瓶颈在于socket的传输速度,而不是列表数据的多少,单纯查询过程的速度已经达到了10^-5s的级别。遗留了几个小问题吧,知道思路就好,反正也没法用到最优解中去。

