覆盖索引
前提
为了通用,更为了避免造数据的痛苦,文中所涉及表、数据,均来自于MySQL官网提供的示例库employees,可通过 https://launchpad.net/test-db/employees-db-1/1.0.6 自行下载。
什么是覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。
不是所有的类型的索引都可以成为覆盖索引,覆盖索引必须要存储索引列的值,而哈希索引,空间索引和全文索引等都不存储引列的值,所以MySQL只能使用B-Tree索引做覆盖索引。另外不同的存储引擎实现覆盖索引的方式也不同,而且不是所有的覆盖索引都支持覆盖索引。
当发起一个被索引覆盖的查询(也叫索引覆盖查询)时,在EXPLAIN的Extra列可以看到“Using index”的信息。
覆盖索引是非常有用的工具,能够极大的提高性能。考虑一下如果查询只需要索引而无需返回表,会带来多大好处:
索引条目通常远小于数据行大小,所以只需要读取索引,那么MySQL就会极大的减少数据访问量。这对缓存的负载非常重要,因为这种情况下相应时间大部分花费在数据拷贝上。覆盖索引对于I/O密集型的应用也有帮助,以为索引比数据更小,更容易全部放入内存中(这对于MyIsam 尤其正确,因为myisam 能压缩索引以变得更小)。
因为索引是按照列值顺序存储的(至少在单个页内是如此),所以对于IO密集型的范围查询会比随机从磁盘读取没以后数据的io要小的多。对于某些存储引擎,例如MyISAM,甚至可以通过OPTIMIZE命令使得索引完全顺序排列,这让简单的范围查询能使用完全顺序的索引访问。
一些存储引擎如MyISAM,在内存中只缓存索引,数据则依赖操作系统来缓存,因此要访问数据需要一次系统调用。这可能会导致严重的性能问题,尤其是那些系统调用占了数据访问中的最大开销的场景。
由于InnoDB的聚簇索引,覆盖索引对InnoDB表特别有用。InnoDB的二级索引在叶子节点中保存了行的主键值,所以如果二级主键能够覆盖查询,则可以避免对主键索引的二次查询。在所有这些场景中,索引中满足查询的成本一般比查询要小的多。
在employees表上创建索引 alter table employees add index `idx_first_last_birth`(first_name,last_name,birth_date);

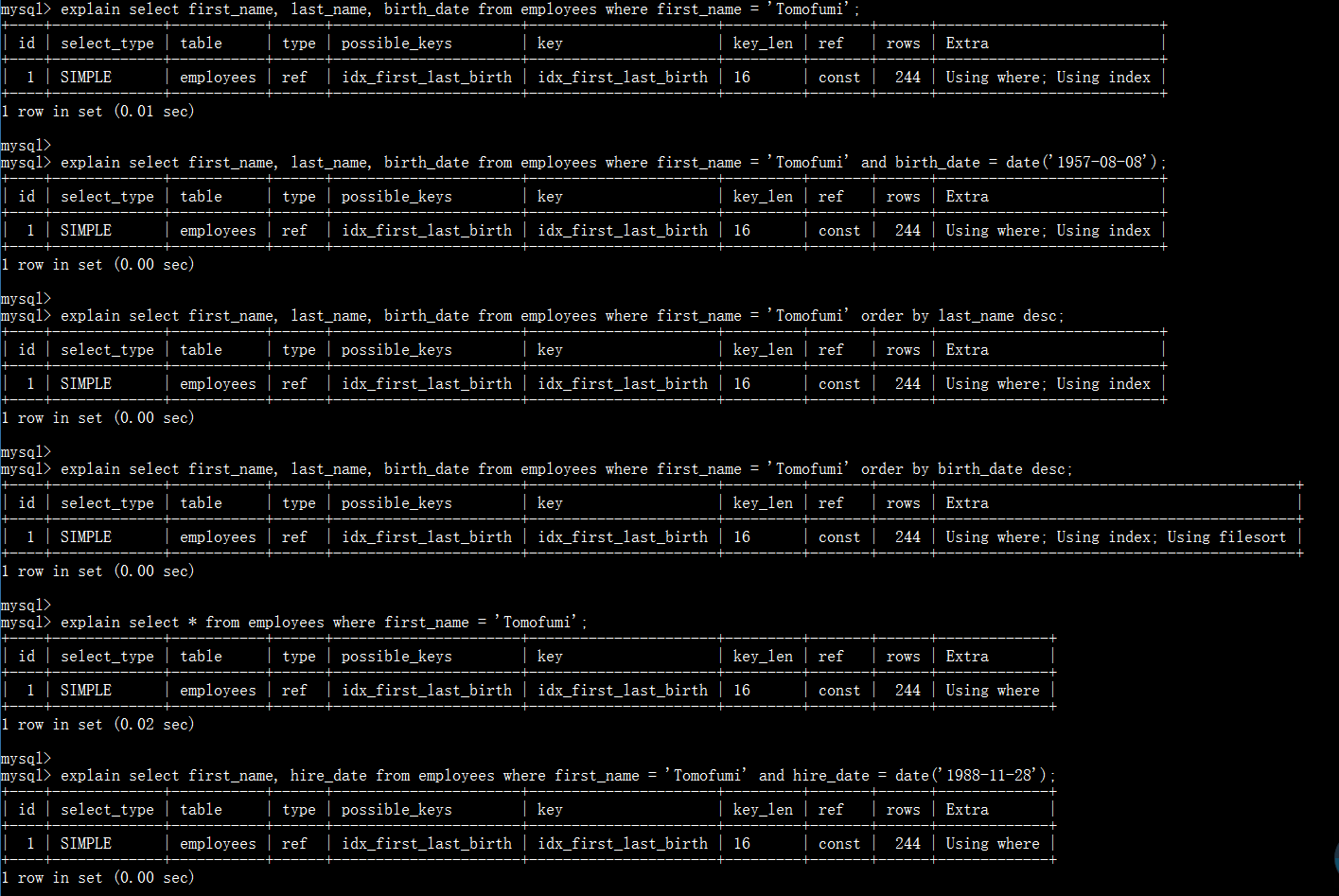
对于以上SQL对索引的使用情况:
1:所有信息都可以从idx_first_last_birth索引中获取(即索引已覆盖SQL所需所有信息)
2:所有信息都可以从idx_first_last_birth索引中获取
3:所有信息都可以从idx_first_last_birth索引中获取,并且也能通过索引直接获取排序
4:所有信息都可以从idx_first_last_birth索引中获取,但无法通过索引直接获取排序,需有额外的排序过程,但索引中依然包含排序字段。
5:where条件能通过idx_first_last_birth索引过滤出结果集(此时仍需回表查出select部分所需字段返回给用户)
6:先通过first_name字段所在idx_first_last_birth索引快速过滤出结果集1,在回表获取表中其它字段信息,并通过hire_date字段过滤出结果集1中的符合条件的数据,最终反馈给用户。
explain 相关列解读请参考 http://www.cnblogs.com/ggjucheng/archive/2012/11/11/2765237.html
警告
创建这些索引只是用来描述确认覆盖索引的过程,但在生产环境中它们可能并不是理想的索引。由于数据集大小有限,我们在这些例子中使用了一个长字符列。随着数据容量的增加,尤其是超过内存和磁盘最大容量的时候,为一个大型列创建索引可能会对系统整体性能有影响。覆盖索引对于那些使用了很多较小长度的主码和外键约束的大型规范化模式来说是理想的优化方式。
参考文献
[1] Baron Scbwartz等 著, 宁海元等 译;高性能MySQL(第三版)(High Performance MySQL);电子工业出版社,2010
