


想了解下关于数据挖掘方面知识,选择了《数据挖掘:概念与技术》这本书。边读边整理读书笔记,方便自己的学习。
数据仓库:即数据立方体的多维数据结构建模(每个维对应于模式中的一个或一组属性)。
数据特征化:一般的汇总所研究类(即目标类)的数据。
数据区分:将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。
一、分类过程
分类过程旨在找出描述和区分数据类或概念的模型(或函数),以便使用模型预测类标号未知的对象的类标号。导出模型是基于对训练数据集(即已知的数据对象)的分析。一般导出模型的形式为:(1)分类规则(即if-then规则);(2)决策树:类似流程图的树结构;(3)神经网络:类似神经元的处理单元,单元之间加权连接。
分类预测的类别标号是离散的,无序的。而回归建立的是连续值模型。
二、回归
回归是用来预测缺失的或难以获取的数据。术语预测可以指数值预测和类标号预测。
回归分析是一种最常用的数值预测的统计学方法。回归也包含基于可用数据的分布趋势识别。
三、相关分析
相关分析一般在分类和回归之前进行,用来识别与分类和回归相关的类属性,达到排除其他不相关属性的目的。
四、聚类分析
聚类分析的数据对象,不考虑数据标号。在大多数情况下,数据分析一开始是不存在类标号的。对象根据最大化类内相似法、最小化类间相似性的原则进行分类和聚类。这样就形成了对象的簇,同一个簇中有很高的相似性,形成的每一个簇都可以看成一个对象类,由它导出规则。聚类就是将观测组织分层结构,把类似的事件组织在一起。
================================================================================================================================
关于有趣的模式(即所需的知识)的特点:(1)易于理解的;(2)在某种确信度上,对新的或检验数据是有效的;(3)是潜在有用的(4)是新颖的
关于一些模式兴趣度的客观度量:(1)支持度,即事务数据库中满足规则的数据所占百分比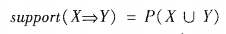
(2)置信度,即评估所发现规则的确信程度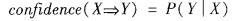
关于数据挖掘涉及的相关技术: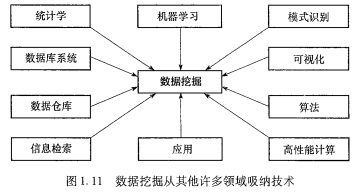
关于数据挖掘研究的主要问题:挖掘方法、用户交互、有效性与可伸缩性、数据类型的多样性、数据挖掘与社会。
第一章--引论
