
《算法导论》第十一章----散列表(直接寻址、链接法解决碰撞)
散列表(哈希表)是根据关键字直接访问内存存储位置的数据结构,仅支持插入、查找、删除操作。在最坏情况下,查找一个元素的时间为Θ(n),而在一些合理的假设下,查找一个元素的期望时间为O(1)。
散列表是普通数组的推广。对于普通数组:
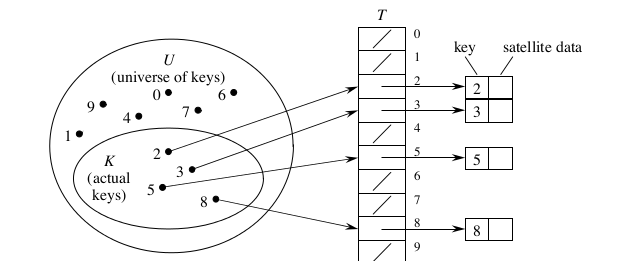
1、我们可以将关键字为k的元素存到数组下标为k的位置里。
2、如果有一个关键字k,我们直接查看数组下标为k的位置。
这种方式为直接寻址方式。但是这种方式有不足:只适用于关键字的全域比较小,而且没有两个元素的关键字完全相同。而显示中存储的关键字集合会比关键字的全域相对小很多。
下图为直接寻址表:
代码实现如下:(刚开始打算直接开个装元素的数组,慢慢发现删除的时候有点麻烦,所以改为指针数组,方便删除后直接指向NULL指针)


1 #include <stdio.h> 2 #include <stdlib.h> 3 4 #define MAX 6 5 6 typedef struct { 7 int key; 8 int satellite; 9 }Data; //元素结构体,有关键字和卫星数据 10 11 Data* direct_address_search(Data *T[], int key); //散列表查找操作 12 13 void direct_address_insert(Data *T[], Data *x); //散列表插入操作 14 15 void direct_address_delete(Data *T[], Data *x); //散列表删除操作 16 17 void print_table(Data *T[]); //打印散列表(为了方便查看删除操作后,散列表的变化) 18 19 int main(){ 20 int i, num, key, satellite; 21 Data *data[MAX]; 22 Data *d; 23 for(i = 0; i < MAX; i++){ 24 data[i] = (Data *)malloc(sizeof(Data)); 25 data[i] = NULL; 26 } 27 28 for(i = 0; i <= 3; i++){ 29 d = (Data *)malloc(sizeof(Data)); 30 printf("Input the key_value:\n"); 31 scanf("%d", &key); 32 printf("Input the satellite:\n"); 33 scanf("%d", &satellite); 34 d->key = key; 35 d->satellite = satellite; 36 direct_address_insert(data, d); 37 } 38 print_table(data); 39 key = 3; 40 d = direct_address_search(data, key); 41 printf("the key is %d, and its satellite is %d\n", d->key, d->satellite); 42 43 direct_address_delete(data, d); 44 print_table(data); 45 free(d); 46 for(i = 0; i < MAX; i++) 47 free(data[i]); 48 return 0; 49 } 50 51 /* 52 *直接返回下标为key的元素 53 */ 54 Data* direct_address_search(Data *T[], int key){ 55 return T[key]; 56 } 57 58 /* 59 * 直接将元素插入下标key的位置里 60 */ 61 void direct_address_insert(Data *T[], Data *x){ 62 T[x->key] = x; 63 } 64 65 /* 66 * 将要删除的元素所在的位置指向空指针 67 */ 68 void direct_address_delete(Data *T[], Data *x){ 69 T[x->key] = NULL; 70 } 71 72 /* 73 * 打印直接寻址表 74 */ 75 void print_table(Data *T[]){ 76 int i; 77 for(i = 0; i < MAX; i++){ 78 if(T[i] != NULL){ 79 printf("key is %d, and its satellite is %d\n", T[i]->key, T[i]->satellite); 80 } 81 } 82 }
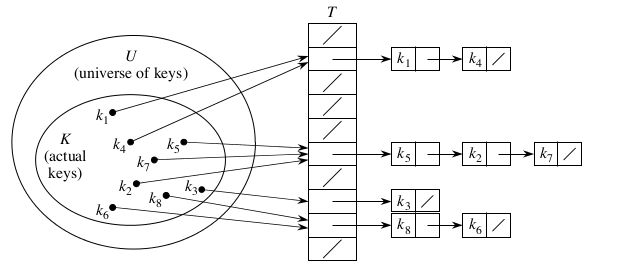
散列方式为通过散列函数将关键字域映射到散列表的位置上,使用散列函数的目标是为了缩小需要处理的下标位置,从而降低空间开销。但是还是有小问题:有可能两个关键字映射到散列表同一个位置(碰撞)。
解决碰撞的最理想方法为完全避免碰撞(是散列函数尽可能“随机”),因为关键字全域比存储关键字域要大,所以存在两个或者以上的元素的散列值相同。
解决碰撞的两种方法有连接法和开放寻址法。PS:该文章暂时只有链接法。。。。。。
下图为链接法的示意图
代码实现如下:(基于双链表实现,关于链表的东西见此第十章 已添加双链表实现!)(注释可参考)
1 #include <stdio.h> 2 #include <stdlib.h> 3 4 #define MAX 10 5 typedef struct { 6 int key; 7 int satellite; 8 }Data; //元素结构体,有关键字和卫星数据 9 10 typedef struct ListNode { 11 Data data; 12 struct ListNode * next; 13 struct ListNode * prev; 14 }ListNode; //双链表结点结构体,存储的数据为元素,前后指针 15 16 typedef struct { 17 ListNode *List[MAX]; 18 }Hash_table; //散列表结构体,双链表数组 19 20 int hash_function(int n); //散列函数 21 22 void list_insert(ListNode *l, Data d); //链表插入 23 24 int list_search(ListNode *l, int key); //链表查找 25 26 int list_delete(ListNode *l, Data d); //链表删除 27 28 void print_list(ListNode *l); //打印链表 29 30 void chained_hash_insert(Hash_table *T, Data x); //散列表插入,基于链表插入 31 32 int chained_hash_delete(Hash_table *T, Data x); //散列表删除,基于链表删除 33 34 int chained_hash_search(Hash_table *T, int key); //散列表查找,基于链表查找 35 36 void print_table(Hash_table *T); //打印散列表,基于打印链表 37 38 39 int main(){ 40 int i, num, key, satellite; 41 Data dd; 42 Hash_table *ht = (Hash_table *)malloc(sizeof(Hash_table)); 43 for(i = 0; i < MAX; i++){ 44 ht->List[i] = (ListNode *)malloc(sizeof(ListNode)); 45 ht->List[i]->next = NULL; 46 } 47 48 for(i = 0; i < 15; i++){ 49 Data d; 50 printf("Input the key:\n"); 51 scanf("%d", &key); 52 printf("Input the satellite:\n"); 53 scanf("%d", &satellite); 54 d.key = key; 55 d.satellite = satellite; 56 chained_hash_insert(ht, d); 57 58 if(i == 14){ 59 dd.key = d.key; 60 dd.satellite = d.satellite; 61 } 62 } 63 64 key = 3; 65 printf("Does %d in the table?\n", key); 66 if(chained_hash_search(ht, key)) 67 printf("Yes!\n"); 68 else 69 printf("No!\n"); 70 71 printf("Delete the last input element!\n"); 72 chained_hash_delete(ht,dd); 73 74 print_table(ht); 75 free(ht); 76 77 return 0; 78 } 79 80 /* 81 * 散列函数为直接将n对散列表大小取余 82 */ 83 int hash_function(int n){ 84 return n % 10; 85 } 86 87 void list_insert(ListNode *l, Data d){ 88 ListNode *p; 89 p = (ListNode *)malloc(sizeof(ListNode)); 90 p->data = d; 91 92 if(l->next == NULL){ 93 l->next = p; 94 p->prev = l; 95 p->next = NULL; 96 } 97 else{ 98 l->next->prev = p; 99 p->next = l->next; 100 l->next = p; 101 p->prev = l; 102 } 103 } 104 105 int list_search(ListNode *l, int key){ 106 ListNode *p = l->next; 107 108 while(p != NULL){ 109 if(p->data.key == key) 110 return 1; 111 p = p->next; 112 } 113 114 return 0; 115 } 116 117 int list_delete(ListNode *l, Data d){ 118 ListNode *p = l->next; 119 120 while(p != NULL){ 121 if(p->data.key == d.key){ 122 p->prev->next = p->next; 123 p->next->prev = p->prev; 124 125 free(p); 126 return 1; 127 } 128 p = p->next; 129 } 130 return 0; 131 } 132 133 void print_list(ListNode *l){ 134 ListNode *p = l->next; 135 136 while(p != NULL){ 137 printf("\tKey: %d, Satellite: %d", p->data.key, p->data.satellite); 138 p = p->next; 139 } 140 printf("\n"); 141 } 142 143 144 void chained_hash_insert(Hash_table *T, Data d){ 145 list_insert(T->List[hash_function(d.key)], d); 146 } 147 148 int chained_hash_delete(Hash_table *T, Data d){ 149 return list_delete(T->List[hash_function(d.key)], d); 150 } 151 152 int chained_hash_search(Hash_table *T, int key){ 153 return list_search(T->List[hash_function(key)], key); 154 } 155 156 void print_table(Hash_table *T){ 157 int i; 158 for(i = 0; i < MAX; i++){ 159 printf("Row %d in Table: ", i); 160 print_list(T->List[i]); 161 } 162 }
链接法散列的最坏情况下运行时间为:Θ(n),所有关键字都散列到同一个位置上,就相当于在一个链表上进行查找。
散列方法的平均性能依赖于所选取的散列函数在一般情况下将所有的关键字分布在散列表的位置上的均匀程度。
简单一致性散列:假设任何元素散列到长度为m的散列表中的每一个位置的可能性都是相同的,且和其他已被散列到什么位置上是无关的。
对于n个数据,在长度为m的散列表上,每个为位置的链表长度为a, a=n/m。
在简单一致性散列的假设下,在用链接法的散列表上的一次不成功的查找的期望时间为Θ(1+a)。
因为链表的平均长度为a,一次不成功查找平均检查a个元素,再加上计算该元素的散列值的总时间为Θ(1+a)。
对于如何设计好的散列函数,有两种方法:启发式(除法进行散列和乘法进行散列)、随机化(全域散列)。
除法散列法的散列函数为: h(k) = k mod m 。m的取值应该为与2的整数幂不太接近的质数。
乘法散列法的散列函数为: h(k) = floor(m(k * A mod 1)) 。其中k * A mod 1 为k * A 的小数部分, A 为小数。Knuth大神认为A 应该约等于√5 - 1 。。。
全域散列的散列函数为在散列函数组里随机选择散列函数。。。。。。。
PS:书中有很多理论的东西都看不懂。。。。。。。继续努力。。。。该文章会继续更新!!!特别是开放寻址法。。。。。

