高性能队列Disruptor系列1--传统队列的不足
在前一篇文章Java中的阻塞队列(BlockingQueue)中介绍了Java中的阻塞队列。从性能上我们能得出一个结论:数组优于链表,CAS优于锁。那么有没有一种队列,通过数组的方式实现,而且采用无锁的结构?嗯,那就是Disruptor,而且比想象中更为强大。
1. 无处不在的锁
Java中的阻塞队列采用锁来实现对临界区资源的同步访问,保证操作的线程安全。
在上一篇文章中我们知道ArrayBlockingQueue通过ReentrantLock以及它的两个condition来控制并发:
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull;
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
比如在压入元素的时候:
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
如果数组已满,则等待notfull,在enqueue中如果消费者去除元素,则会调用notFull.signal(),put方法将会被唤醒。
这种wait-notify模式很好的实现了阻塞队列。
但是在性能上因为锁的缘故,会有额外的性能消耗。
2. 无声的伪共享
从计算机的存储结构说起,在CPU和主存之间插入一个更小、更快的存储设备(例如,高速缓存存储器)已成为存储设备的一个设计主流,在计算机系统中,存储设备被组织成一个存储器层次模型,如下图(来自《深入理解计算机系统》),在此层次中,从上至下,容量越来越大,访问速度越来越慢,但是造价也更便宜。
下图是简化版的多核计算机基本结构,当CPU执行运算的时候,先去L1查找所需要的数据源,再去L2,如果这些缓存中都没有,所需的数据就得去主存中拿。
下面是Martin 和 Mike的 QCon presentation 演讲中给出了一些缓存未命中的消耗数据:
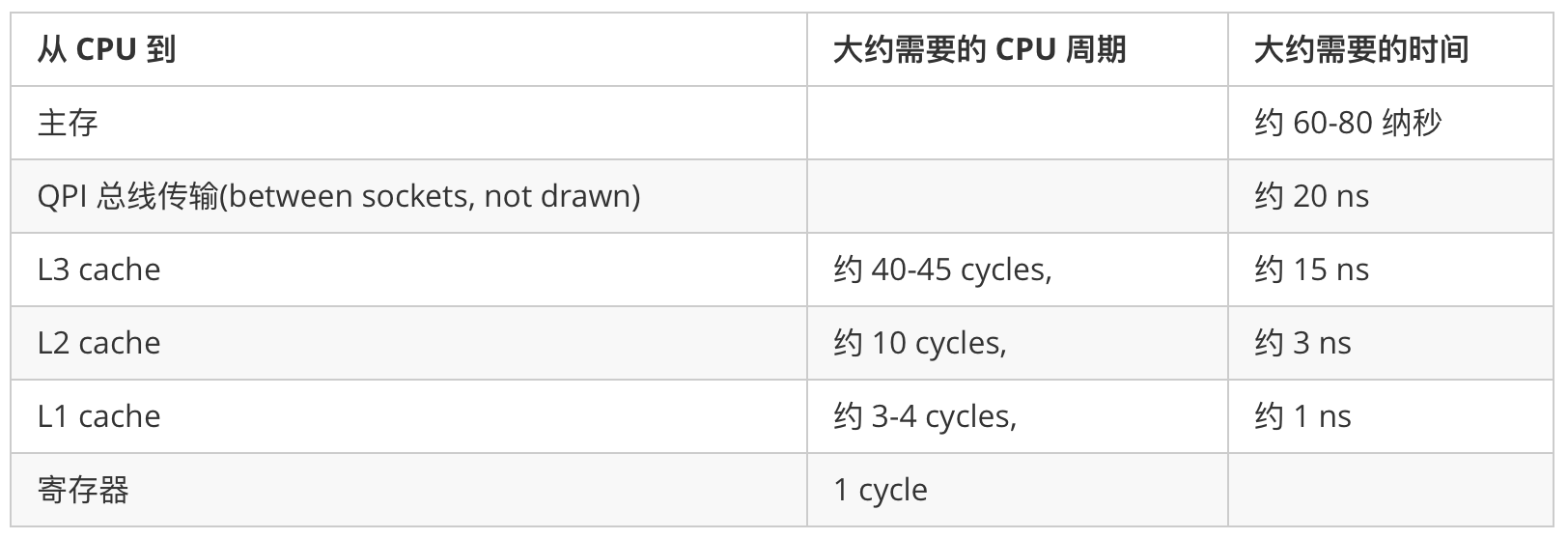
今天的CPU不再是按字节访问内存,而是以64字节(64位系统)为单位的块(chunk)拿取,称为一个缓存行(cache line)。当你读一个特定的内存地址,整个缓存行将从主存换入缓存,并且访问同一个缓存行内的其它值的开销是很小的。
比如,Java中的long类型是8个字节,因此在一个缓冲行中可以存8个long类型的变量,也就是说如果访问一个long类型的数组,访问第一个元素的时候,会把另外7个也加载到缓存中,可以非常快速的遍历数组,这也是数组比链表快的原因。
美团点评技术团队写了测试程序,利用一个long型的二维数组,测试cache line的特性的效果:
public class CacheLineEffect {
//考虑一般缓存行大小是64字节,一个 long 类型占8字节
static long[][] arr;
public static void main(String[] args) {
arr = new long[1024 * 1024][];
for (int i = 0; i < 1024 * 1024; i++) {
arr[i] = new long[8];
for (int j = 0; j < 8; j++) {
arr[i][j] = 0L;
}
}
long sum = 0L;
long marked = System.currentTimeMillis();
for (int i = 0; i < 1024 * 1024; i+=1) {
for(int j =0; j< 8;j++){
sum = arr[i][j];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
marked = System.currentTimeMillis();
for (int i = 0; i < 8; i+=1) {
for(int j =0; j< 1024 * 1024;j++){
sum = arr[j][i];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
}
}
运行结果:
Loop times:24ms
Loop times:97ms
缓存行利用局部性的确能提高效率,但是有一个弊端,当我们的数据不相关,只是一个单独的变量,这两个数据在一个缓存行中,而且他们的访问频率都很高,这时候反而会影响效率。如下图:
比如我们有一个类存放了两个变量的值data1,data2。当加载data1的时候,data2也被加载到缓存中,也就是存在于同一个缓存行。当core1改变data1的值的时候,core1缓存中的值和内存中的值都被改变了,这时候core2也会重新加载这个缓存行,因为data1变了,而core2只是想读取自己缓存中的data2,却任然要等从内存中重新加载这个缓存行。
这种无法充分使用缓存行特性的现象,称为伪共享。
3. 总结
无论是锁还是伪共享,都对我们程序的性能产生了或多或少的影响,而Disruptor很好的解决了这些问题,采用了无锁的数据结构,而且利用 cache line padding(缓存行填充)很好的解决了伪共享问题。
引用范仲淹在infoq接受采访时的语录:
我个人的观点,就看你对性能的要求有多高。如果你要达到极致的性能,对延迟要求非常低,而且对高并发要求性能非常高的时候,你肯定要选择Disruptor。但是从易用性上来讲,Disruptor使用起来并没有传统的queue使用上更方便。你在百万级别并发的时候,我推荐大家使用Java的ConcurrentQueue跟BlockingQueue。但是如果你需要更低的延迟的话,我推荐用Disruptor。
参考资料:

