

cgroup原理简析:vfs文件系统
要了解cgroup实现原理,必须先了解下vfs(虚拟文件系统).因为cgroup通过vfs向用户层提供接口,用户层通过挂载,创建目录,读写文件的方式与cgroup交互.
因为是介绍cgroup的文章,因此只阐述cgroup文件系统是如何集成进vfs的,过多的vfs实现可参考其他资料.
1 2 3 4 | 1.[root@VM_109_95_centos /cgroup]#mount -t cgroup -ocpu cpu /cgroup/cpu/2.[root@VM_109_95_centos /cgroup]#cd cpu/ && mkdir cpu_c13.[root@VM_109_95_centos /cgroup/cpu]#cd cpu_c1/ && echo 2048 >> cpu.shares4.[root@VM_109_95_centos /cgroup/cpu/cpu_c1]#echo 7860 >> tasks |
我们以上面4行命令为主线进行分析,从一个cgroup使用者的角度来看:
命令1 创建了一个新的cgroup层级(挂载了一个新cgroup文件系统).并且绑定了cpu子系统(subsys),同时创建了该层级的根cgroup.命名为cpu,路径为/cgroup/cpu/.
命令2 在cpu层级(姑且这么叫)通过mkdir新创建一个cgroup节点,命名为cpu_c1.
命令3 将cpu_c1目录下的cpu.shares文件值设为2048,这样在系统出现cpu争抢时,属于cpu_c1这个cgroup的进程占用的cpu资源是其他进程占用cpu资源的2倍.(默认创建的根cgroup该值为1024).
命令4 将pid为7860的这个进程加到cpu_c1这个cgroup.就是说在系统出现cpu争抢时,pid为7860的这个进程占用的cpu资源是其他进程占用cpu资源的2倍.
那么系统在背后做了那些工作呢?下面逐一分析(内核版本3.10).
--------------------------------------------------------
1.mount -t cgroup -ocpu cpu /cgroup/cpu/
static struct file_system_type cgroup_fs_type = {
.name = "cgroup",
.mount = cgroup_mount,
.kill_sb = cgroup_kill_sb,
// 其他属性未初始化
};
cgroup模块以cgroup_fs_type实例向内核注册cgroup文件系统,用户层通过mount()系统调用层层调用,最终来到cgroup_mount()函数:

static struct dentry *cgroup_mount(struct file_system_type *fs_type,int flags, const char *unused_dev_name,void *data) {
ret = parse_cgroupfs_options(data, &opts); // 解析mount时的参数
new_root = cgroup_root_from_opts(&opts); // 根据选项创建一个层级(struct cgroupfs_root)
sb = sget(fs_type, cgroup_test_super, cgroup_set_super, 0, &opts); // 创建一个新的超级快(struct super_block)
ret = rebind_subsystems(root, root->subsys_mask); // 给层级绑定subsys
cgroup_populate_dir(root_cgrp, true, root->subsys_mask); // 创建根cgroup下的各种文件
}
首先解析mount时上层传下的参数,这里就解析到该层级需要绑定cpu subsys统.然后根据参数创建一个层级.跟进到cgroup_root_from_opts()函数:
static struct cgroupfs_root *cgroup_root_from_opts(struct cgroup_sb_opts *opts)
{
struct cgroupfs_root *root;
if (!opts->subsys_mask && !opts->none) // 未指定层级,并且用户曾未明确指定需要空层级return NULL
return NULL;
root = kzalloc(sizeof(*root), GFP_KERNEL); // 申请内存
if (!root)
return ERR_PTR(-ENOMEM);
if (!init_root_id(root)) { // 初始化层级unique id
kfree(root);
return ERR_PTR(-ENOMEM);
}
init_cgroup_root(root); // 创建根cgroup
root->subsys_mask = opts->subsys_mask;
root->flags = opts->flags;
ida_init(&root->cgroup_ida); // 初始化idr
if (opts->release_agent) // 拷贝清理脚本的路径,见后面struct cgroupfs_root说明.
strcpy(root->release_agent_path, opts->release_agent);
if (opts->name) // 设置name
strcpy(root->name, opts->name);
if (opts->cpuset_clone_children) // 该选项打开,表示当创建子cpuset cgroup时,继承父cpuset cgroup的配置
set_bit(CGRP_CPUSET_CLONE_CHILDREN, &root->top_cgroup.flags);
return root;
}
层级结构体:
struct cgroupfs_root {
struct super_block *sb; // 超级块指针,最终指向该cgroup文件系统的超级块
unsigned long subsys_mask; // 该层级准备绑定的subsys统掩码
int hierarchy_id; // 全局唯一的层级ID
unsigned long actual_subsys_mask; // 该层级已经绑定的subsys统掩码(估计和上层remount有关吧?暂不深究)
struct list_head subsys_list; // subsys统链表,将该层级绑定的所有subsys统连起来.
struct cgroup top_cgroup; // 该层级的根cgroup
int number_of_cgroups; //该层级下cgroup的数目(层级可以理解为cgroup组成的树)
struct list_head root_list; // 层级链表,将系统上所有的层级连起来
struct list_head allcg_list; // cgroup链表,将该层级上所有的cgroup连起来???
unsigned long flags; // 一些标志().
struct ida cgroup_ida; // idr机制,方便查找(暂不深究)
char release_agent_path[PATH_MAX]; // 清理脚本的路径,对应应用层的根cgroup目录下的release_agent文件
char name[MAX_CGROUP_ROOT_NAMELEN]; //层级名称
};
接下来创建超级块,在vfs中超级块用来表示一个已安装文件系统的相关信息.跟进到cgroup_root_from_opts()函数:
struct super_block *sget(struct file_system_type *type, int (*test)(struct super_block *,void *), int (*set)(struct super_block *,void *), int flags, void *data)
{
struct super_block *s = NULL;
struct super_block *old;
int err;
retry:
spin_lock(&sb_lock);
if (test) { // 尝试找到一个已存在的sb
hlist_for_each_entry(old, &type->fs_supers, s_instances) {
if (!test(old, data))
continue;
if (!grab_super(old))
goto retry;
if (s) {
up_write(&s->s_umount);
destroy_super(s);
s = NULL;
}
return old;
}
}
if (!s) {
spin_unlock(&sb_lock);
s = alloc_super(type, flags); //分配一个新的sb
if (!s)
return ERR_PTR(-ENOMEM);
goto retry;
}
err = set(s, data); // 初始化sb属性
if (err) {
spin_unlock(&sb_lock);
up_write(&s->s_umount);
destroy_super(s);
return ERR_PTR(err);
}
s->s_type = type; //该sb所属文件系统类型为cgroup_fs_type
strlcpy(s->s_id, type->name, sizeof(s->s_id)); // s->s_id = "cgroup"
list_add_tail(&s->s_list, &super_blocks); // 加进super_block全局链表
hlist_add_head(&s->s_instances, &type->fs_supers); //同一文件系统可挂载多个实例,全部挂到cgroup_fs_type->fs_supers指向的链表中
spin_unlock(&sb_lock);
get_filesystem(type);
register_shrinker(&s->s_shrink);
return s;
}
超级块结构体类型(属性太多,只列cgroup差异化的,更多内容请参考vfs相关资料):
struct super_block {
struct list_head s_list; // 全局sb链表
...
struct file_system_type *s_type; // 所属文件系统类型
const struct super_operations *s_op; // 超级块相关操作
struct hlist_node s_instances; // 同一文件系统的sb链表
char s_id[32]; // 文本格式的name
void *s_fs_info; //文件系统私有数据,cgroup用其指向层级
};
sget函数里先在已存的链表里查找是否有合适的,没有的话再分配新的sb.err = set(s, data) set是个函数指针,根据上面的代码可以知道最终调用的是cgroup_set_super函数,主要是给新分配的sb赋值.这段代码比较重要,展开看下:
static int cgroup_set_super(struct super_block *sb, void *data)
{
int ret;
struct cgroup_sb_opts *opts = data;
/* If we don't have a new root, we can't set up a new sb */
if (!opts->new_root)
return -EINVAL;
BUG_ON(!opts->subsys_mask && !opts->none);
ret = set_anon_super(sb, NULL);
if (ret)
return ret;
sb->s_fs_info = opts->new_root; // super_block的s_fs_info字段指向对应的cgroupfs_root
opts->new_root->sb = sb; //cgroupfs_root的sb字段指向super_block
sb->s_blocksize = PAGE_CACHE_SIZE;
sb->s_blocksize_bits = PAGE_CACHE_SHIFT;
sb->s_magic = CGROUP_SUPER_MAGIC;
sb->s_op = &cgroup_ops; //super_block的s_op字段指向cgroup_ops,这句比较关键.
return 0;
}
这样超级块(super_block)和层级(cgroupfs_root)这两个概念就一一对应起来了,并且可以相互索引到.super_block.s_op指向一组函数,这组函数就是该文件系统向上层提供的所有操作.看下cgroup_ops:
static const struct super_operations cgroup_ops = {
.statfs = simple_statfs,
.drop_inode = generic_delete_inode,
.show_options = cgroup_show_options,
.remount_fs = cgroup_remount,
};
竟然只提供3个操作....常见的文件系统(ext2)都会提供诸如alloc_inode read_inode等函数供上层操作文件.但是cgroup文件系统不需要这些操作,
很好理解,cgroup是基于memory的文件系统.用不到那些操作.
到这里好多struct已经复出水面,眼花缭乱.画个图理理.
图1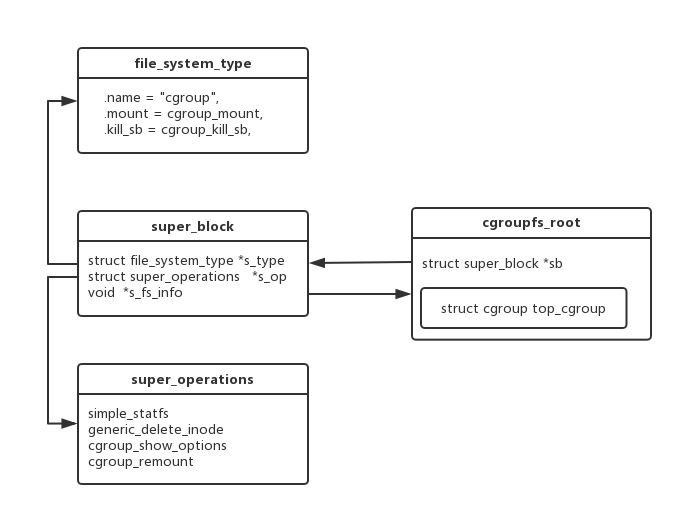
继续.创建完超级块后ret = rebind_subsystems(root, root->subsys_mask);根据上层的参数给该层级绑定subsys统(subsys和根cgroup联系起来),看下cgroup_subsys_state,cgroup和cgroup_subsys(子系统)的结构.
struct cgroup_subsys_state {
struct cgroup *cgroup;
atomic_t refcnt;
unsigned long flags;
struct css_id __rcu *id;
struct work_struct dput_work;
};
先看下cgroup_subsys_state.可以认为cgroup_subsys_state是subsys结构体的一个最小化的抽象
各个子系统各有自己的相关结构,cgroup_subsys_state保存各个subsys之间统一的信息,各个subsys的struct内嵌cgroup_subsys_state为第一个元素,通过container_of机制使得cgroup各个具体(cpu mem net io)subsys信息连接起来.
(例如进程调度系统的task_group)见图2
struct cgroup {
unsigned long flags;
struct list_head sibling; // 兄弟链表
struct list_head children; // 孩子链表
struct list_head files; // 该cgroup下的文件链表(tasks cpu.shares ....)
struct cgroup *parent; // 父cgroup
struct dentry *dentry;
struct cgroup_name __rcu *name;
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT]; //指针数组,每个非空元素指向挂载的subsys
struct cgroupfs_root *root; //根cgroup
struct list_head css_sets;
struct list_head pidlists; // 加到该cgroup下的taskid链表
};
subsys是一个cgroup_subsys_state* 类型的数组,每个元素指向一个具体subsys的cgroup_subsys_state,通过container_of(cgroup_subsys_state)就拿到了具体subsys的控制信息.
struct cgroup_subsys { // 删减版
struct cgroup_subsys_state *(*css_alloc)(struct cgroup *cgrp);
int (*css_online)(struct cgroup *cgrp); // 一堆函数指针,由各个subsys实现.函数名意思比较鲜明
void (*css_offline)(struct cgroup *cgrp);
void (*css_free)(struct cgroup *cgrp);
int (*can_attach)(struct cgroup *cgrp, struct cgroup_taskset *tset);
void (*cancel_attach)(struct cgroup *cgrp, struct cgroup_taskset *tset);
void (*attach)(struct cgroup *cgrp, struct cgroup_taskset *tset);
void (*fork)(struct task_struct *task);
void (*exit)(struct cgroup *cgrp, struct cgroup *old_cgrp,
struct task_struct *task);
void (*bind)(struct cgroup *root);
int subsys_id; // subsys id
int disabled;
...
struct list_head cftsets; // cftype结构体(参数文件管理结构)链表
struct cftype *base_cftypes; // 指向一个cftype数组
struct cftype_set base_cftset; //
struct module *module;
};
cgroup_subsys也是各个subsys的一个抽象,真正的实现由各个subsys实现.可以和cgroup_subsys_state对比下,cgroup_subsys更偏向与描述各个subsys的操作钩子,cgroup_subsys_state则与各个子系统的任务结构关联.
cgroup_subsys是与层级关联的,cgroup_subsys_state是与cgroup关联的。
struct cftype { // 删减版
char name[MAX_CFTYPE_NAME];
int private;
umode_t mode;
size_t max_write_len;
unsigned int flags;
s64 (*read_s64)(struct cgroup *cgrp, struct cftype *cft);
int (*write_s64)(struct cgroup *cgrp, struct cftype *cft, s64 val);
...
};
cftsets base_cftypes base_cftset这个三个属性保存的是同一份该subsys下对应控制文件的操作方法.只是访问方式不同.
以cpu subsys为例,该subsys下有cpu.shares cpu.cfs_quota_us cpu.cpu_cfs_period_read_u64这些控制文件,每个访问方式都不同.
因此每个文件对应一个struct cftype结构,保存其对应文件名和读写函数.
图2
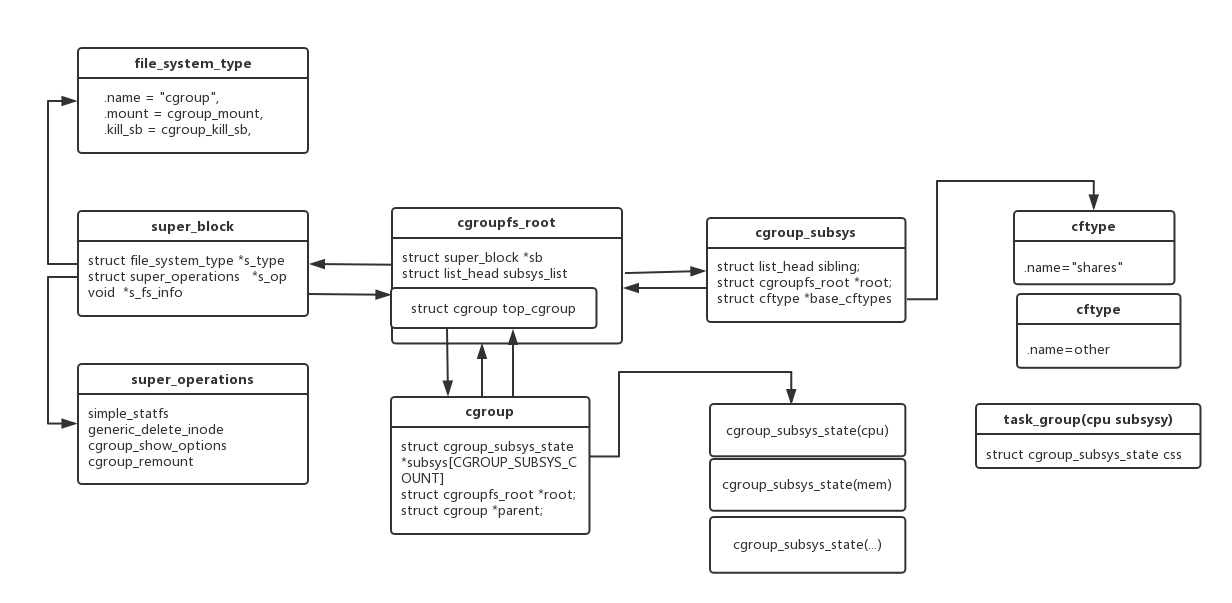
例如用户曾执行echo 1024 >> cpu.shares 最终通过inode.file_operations.cgroup_file_read->cftype.write_s64.
同理,创建子group除了正常的mkdir操作之外,inode.inode_operations.cgroup_mkdir函数内部额外调用上面已经初始化好的钩子,创建新的cgroup.
最后一步,cgroup_populate_dir(root_cgrp, true, root->subsys_mask);就是根据上面已经实例化好的cftype,创建cgroup下每个subsys的所有控制文件
static int cgroup_populate_dir(struct cgroup *cgrp, bool base_files, unsigned long subsys_mask)
{
int err;
struct cgroup_subsys *ss;
if (base_files) { //基本控制文件
err = cgroup_addrm_files(cgrp, NULL, files, true);
if (err < 0)
return err;
}
/* process cftsets of each subsystem */
for_each_subsys(cgrp->root, ss) { //每个subsys
struct cftype_set *set;
if (!test_bit(ss->subsys_id, &subsys_mask))
continue;
list_for_each_entry(set, &ss->cftsets, node) //每个subsys的每个控制文件
cgroup_addrm_files(cgrp, ss, set->cfts, true);
}
...
return 0;
}
显而易见,先初始化了基本的文件,进而初始化每个subsys的每个控制文件.什么是基本文件?
static struct cftype files[] = {
{
.name = "tasks",
.open = cgroup_tasks_open,
.write_u64 = cgroup_tasks_write,
.release = cgroup_pidlist_release,
.mode = S_IRUGO | S_IWUSR,
},
{
.name = CGROUP_FILE_GENERIC_PREFIX "procs",
.open = cgroup_procs_open,
.write_u64 = cgroup_procs_write,
.release = cgroup_pidlist_release,
.mode = S_IRUGO | S_IWUSR,
},
{
.name = "notify_on_release",
.read_u64 = cgroup_read_notify_on_release,
.write_u64 = cgroup_write_notify_on_release,
},
{
.name = CGROUP_FILE_GENERIC_PREFIX "event_control",
.write_string = cgroup_write_event_control,
.mode = S_IWUGO,
},
{
.name = "cgroup.clone_children",
.flags = CFTYPE_INSANE,
.read_u64 = cgroup_clone_children_read,
.write_u64 = cgroup_clone_children_write,
},
{
.name = "cgroup.sane_behavior",
.flags = CFTYPE_ONLY_ON_ROOT,
.read_seq_string = cgroup_sane_behavior_show,
},
{
.name = "release_agent",
.flags = CFTYPE_ONLY_ON_ROOT,
.read_seq_string = cgroup_release_agent_show,
.write_string = cgroup_release_agent_write,
.max_write_len = PATH_MAX,
},
{ } /* terminate */
};
这些文件在用户层应该见过.进到cgroup_create_file()函数看下:
static int cgroup_create_file(struct dentry *dentry, umode_t mode, struct super_block *sb)
{
struct inode *inode;
if (!dentry)
return -ENOENT;
if (dentry->d_inode)
return -EEXIST;
inode = cgroup_new_inode(mode, sb); // 申请inode
if (!inode)
return -ENOMEM;
if (S_ISDIR(mode)) { //目录
inode->i_op = &cgroup_dir_inode_operations;
inode->i_fop = &simple_dir_operations;
...
} else if (S_ISREG(mode)) { //文件
inode->i_size = 0;
inode->i_fop = &cgroup_file_operations;
inode->i_op = &cgroup_file_inode_operations;
}
d_instantiate(dentry, inode);
dget(dentry); /* Extra count - pin the dentry in core */
return 0;
}
const struct file_operations simple_dir_operations = {
.open = dcache_dir_open,
.release = dcache_dir_close,
.llseek = dcache_dir_lseek,
.read = generic_read_dir,
.readdir = dcache_readdir,
.fsync = noop_fsync,
};
static const struct inode_operations cgroup_dir_inode_operations = {
.lookup = cgroup_lookup,
.mkdir = cgroup_mkdir,
.rmdir = cgroup_rmdir,
.rename = cgroup_rename,
.setxattr = cgroup_setxattr,
.getxattr = cgroup_getxattr,
.listxattr = cgroup_listxattr,
.removexattr = cgroup_removexattr,
};
static const struct file_operations cgroup_file_operations = {
.read = cgroup_file_read,
.write = cgroup_file_write,
.llseek = generic_file_llseek,
.open = cgroup_file_open,
.release = cgroup_file_release,
};
static const struct inode_operations cgroup_file_inode_operations = {
.setxattr = cgroup_setxattr,
.getxattr = cgroup_getxattr,
.listxattr = cgroup_listxattr,
.removexattr = cgroup_removexattr,
};
这些回调函数,上面以file_operations.cgroup_file_read cgroup_dir_inode_operations.cgroup_mkdir举例已经说明.
除了常规vfs的操作,还要执行cgroup机制相关操作.
有点懵,还好说的差不多了.后面会轻松点,也许结合后面看前面,也会轻松些.
--------------------------------------------------------
2.mkdir cpu_c1
这个简单来说就是分成两个部分,正常vfs创建目录的逻辑,在该目录下创建新的cgroup,集成父cgroup的subsys.
命令贴全[root@VM_109_95_centos /cgroup]#cd cpu/ && mkdir cpu_c1
我们是在/cgroup/目录下挂载的新文件系统,对于该cgroup文件系统,/cgroup/就是其根目录(用croot代替吧).
那么在croot目录下mkdir cpu_c1.对于vfs来说,当然是调用croot目录对应inode.i_op.mkdir.
static int cgroup_get_rootdir(struct super_block *sb)
{
struct inode *inode =
cgroup_new_inode(S_IFDIR | S_IRUGO | S_IXUGO | S_IWUSR, sb);
inode->i_fop = &simple_dir_operations;
inode->i_op = &cgroup_dir_inode_operations;
return 0;
}
可以看到croot目录项的inode.i_op也被设置为&cgroup_dir_inode_operations,那么mkdir就会调用cgroup_mkdir函数
cgroup_mkdir只是简单的包装,实际工作的函数是cgroup_create()函数.
看下cgroup_create函数(删减版)
static long cgroup_create(struct cgroup *parent, struct dentry *dentry,umode_t mode)
{
struct cgroup *cgrp;
struct cgroup_name *name;
struct cgroupfs_root *root = parent->root;
int err = 0;
struct cgroup_subsys *ss;
struct super_block *sb = root->sb;
cgrp = kzalloc(sizeof(*cgrp), GFP_KERNEL); //分配cgroup
name = cgroup_alloc_name(dentry);
rcu_assign_pointer(cgrp->name, name); // 设置名称
init_cgroup_housekeeping(cgrp); //cgroup一些成员的初始化
dentry->d_fsdata = cgrp; //目录项(dentry)与cgroup关联起来
cgrp->dentry = dentry;
cgrp->parent = parent; // 设置cgroup层级关系
cgrp->root = parent->root;
if (notify_on_release(parent)) // 继承父cgroup的CGRP_NOTIFY_ON_RELEASE属性
set_bit(CGRP_NOTIFY_ON_RELEASE, &cgrp->flags);
if (test_bit(CGRP_CPUSET_CLONE_CHILDREN, &parent->flags)) // 继承父cgroup的CGRP_CPUSET_CLONE_CHILDREN属性
set_bit(CGRP_CPUSET_CLONE_CHILDREN, &cgrp->flags);
for_each_subsys(root, ss) {
struct cgroup_subsys_state *css;
css = ss->css_alloc(cgrp); // mount时各个subsys的钩子函数已经注册,这里直接使用来创建各个subsys的结构(task_group)
init_cgroup_css(css, ss, cgrp); //初始化cgroup_subsys_state类型的值
if (ss->use_id) {
err = alloc_css_id(ss, parent, cgrp);
}
}
err = cgroup_create_file(dentry, S_IFDIR | mode, sb); //创建该目录项对应的inode,并初始化后与dentry关联上.
list_add_tail(&cgrp->allcg_node, &root->allcg_list); // 该cgroup挂到层级的cgroup链表上
list_add_tail_rcu(&cgrp->sibling, &cgrp->parent->children); // 该cgroup挂到福cgroup的子cgroup链表上.
....
for_each_subsys(root, ss) { // 将各个subsys的控制结构(task_group)建立父子关系.
err = online_css(ss, cgrp);
}
err = cgroup_populate_dir(cgrp, true, root->subsys_mask); // 生成该cgroup目录下相关子系统的控制文件
...
}
cgroup_create里面做的事情,上面几乎都看过了.不再解释.
css = ss->css_alloc(cgrp);
err = online_css(ss, cgrp);
这两行简单说明下:我们用cgroup来限制机器的cpu mem IO net,但是cgroup本身是没有限制功能的.cgroup更像是内核几大核心子系统为上层提供的入口..
以这个例子来说,我们创建了一个绑定了cpu subsys的cgroup.当我们把某个进程id加到该cgroup的tasks文件中时,
其实是改变了该进程在进程调度系统中的相关参数,从而影响完全公平调度算法和实时调度算法达到限制的目的.
因此在这个例子中,ss->css_alloc虽然返回的是cgroup_subsys_state指针,但其实它创建了task_group.
该结构第一个变量为cgroup_subsys_state.
struct task_group { //删减版
struct cgroup_subsys_state css;
struct sched_entity **se;
struct cfs_rq **cfs_rq;
unsigned long shares;
atomic_t load_weight;
atomic64_t load_avg;
atomic_t runnable_avg;
struct rcu_head rcu;
struct list_head list;
struct task_group *parent;
struct list_head siblings;
struct list_head children;
};
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
};
cpu子系统是通过设置task_group来限制进程的,相应的mem IO子系统也有各自的结构.
不过它们的共性就是第一个变量是cgroup_subsys_state,这样cgroup和子系统控制结构就通过cgroup_subsys_state连接起来.
mount时根cgroup也是要创建这些子系统控制结构的,被我略掉了.
--------------------------------------------------------
3.echo 2048 >> cpu.shares
上面已经看见了cpu.shares这个文件的inode_i_fop = &cgroup_file_operations,写文件调用cgroup_file_read:
static ssize_t cgroup_file_read(struct file *file, char __user *buf, size_t nbytes, loff_t *ppos)
{
struct cftype *cft = __d_cft(file->f_dentry);
struct cgroup *cgrp = __d_cgrp(file->f_dentry->d_parent);
if (cft->read)
return cft->read(cgrp, cft, file, buf, nbytes, ppos);
if (cft->read_u64)
return cgroup_read_u64(cgrp, cft, file, buf, nbytes, ppos);
if (cft->read_s64)
return cgroup_read_s64(cgrp, cft, file, buf, nbytes, ppos);
return -EINVAL;
}
mount时已经知道每个subsys的每个控制文件的操作函数都是不一样的(通过cftype实现的).我们直接看下cpu.shares文件的操作函数.
static struct cftype cpu_files[] = {
{
.name = "shares",
.read_u64 = cpu_shares_read_u64,
.write_u64 = cpu_shares_write_u64,
},
...
}
写cpu.shares最终调用cpu_shares_write_u64, 中间几层细节略过.最终执行update_load_set:
static inline void update_load_set(struct load_weight *lw, unsigned long w)
{
lw->weight = w;
lw->inv_weight = 0;
}
其中load_weight=task_group.se.load,改变了load_weight.weight,起到了限制该task_group对cpu的使用.
--------------------------------------------------------
4.echo 7860 >> tasks
过程是类似的,不过tasks文件最终调用的是cgroup_tasks_write这个函数.
static struct cftype files[] = {
{
.name = "tasks",
.open = cgroup_tasks_open,
.write_u64 = cgroup_tasks_write,
.release = cgroup_pidlist_release,
.mode = S_IRUGO | S_IWUSR,
},
}
cgroup_tasks_write最终调用attach_task_by_pid
static int attach_task_by_pid(struct cgroup *cgrp, u64 pid, bool threadgroup)
{
struct task_struct *tsk;
const struct cred *cred = current_cred(), *tcred;
int ret;
if (pid) { //根据pid找到该进程的task_struct
tsk = find_task_by_vpid(pid);
if (!tsk) {
rcu_read_unlock();
ret= -ESRCH;
goto out_unlock_cgroup;
}
}
.....
.....
ret = cgroup_attach_task(cgrp, tsk, threadgroup); //将进程关联到cgroup
return ret;
}
最终通过cgroup_attach_task函数,将进程挂载到响应cgroup.先看几个新的结构体.
struct css_set {
atomic_t refcount; //引用计数
struct hlist_node hlist; //css_set链表,将系统中所有css_set连接起来.
struct list_head tasks; //task链表,链接所有属于这个set的进程
struct list_head cg_links; // 指向一个cg_cgroup_link链表
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT]; // 关联到subsys
struct rcu_head rcu_head;
};
struct cg_cgroup_link {
struct list_head cgrp_link_list; //内嵌到cgroup->css_set链表
struct cgroup *cgrp; // 指向对应的cgroup
struct list_head cg_link_list; //内嵌到css_set->cg_links链表
struct css_set *cg; // 指向对应的css_set
};
struct task_struct {
struct css_set __rcu *cgroups; // 指向所属的css_set
struct list_head cg_list; // 将同属于一个css_set的task_struct连接起来.
}
css_set感觉像是进程和cgroup机制间的一个桥梁.cg_cgroup_link又将css_set和cgroup多对多的映射起来.
task_struct中并没有直接与cgroup关联,struct css_set __rcu *cgroups指向自己所属的css_set.
这样task和cgroup subsys cgroup都可以互相索引到了.
图3
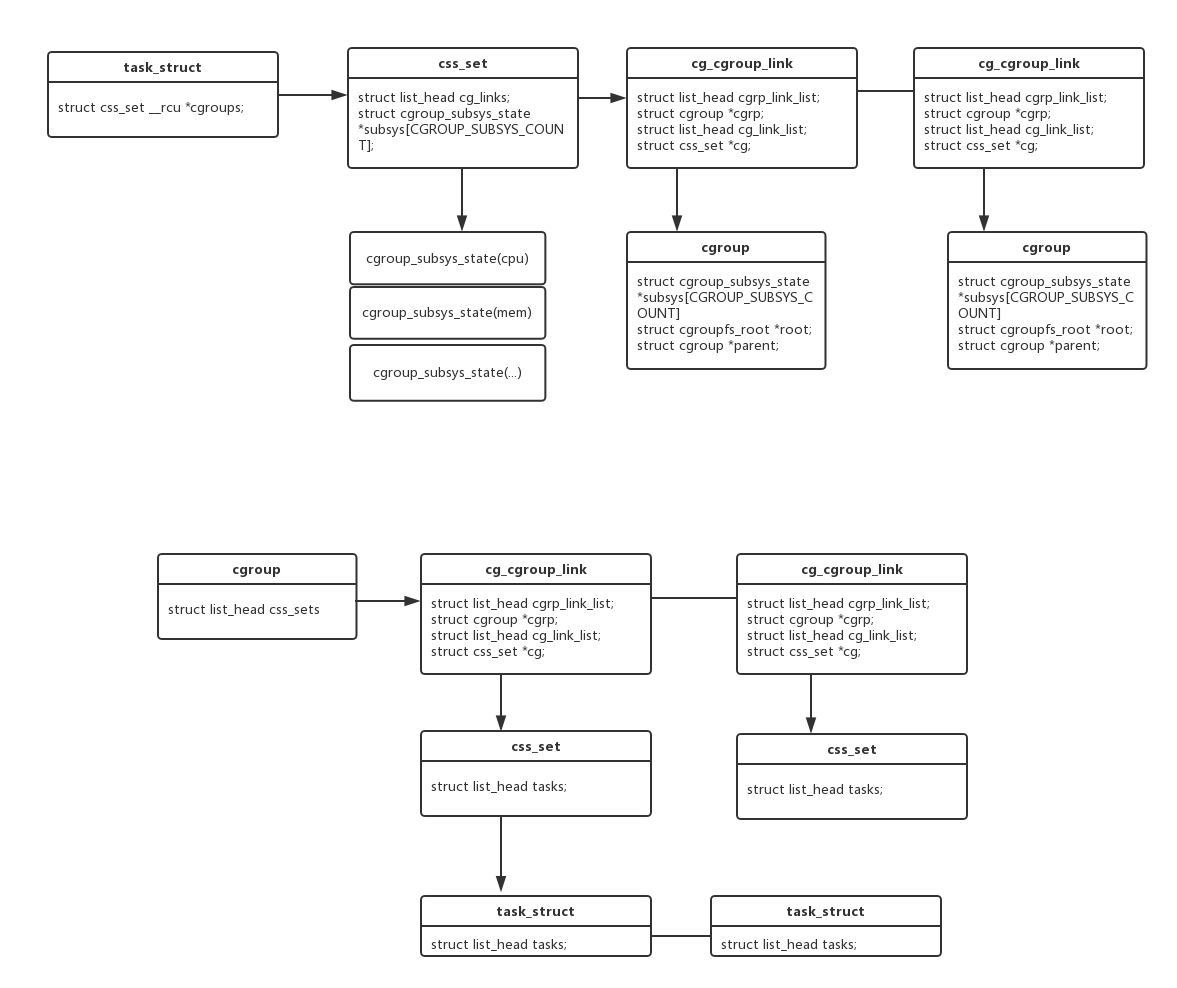
进到cgroup_attach_task看看:
struct task_and_cgroup {
struct task_struct *task;
struct cgroup *cgrp;
struct css_set *cg;
};
struct cgroup_taskset {
struct task_and_cgroup single;
struct flex_array *tc_array;
int tc_array_len;
int idx;
struct cgroup *cur_cgrp;
};
static int cgroup_attach_task(struct cgroup *cgrp, struct task_struct *tsk,
bool threadgroup)
{
int retval, i, group_size;
struct cgroup_subsys *ss, *failed_ss = NULL;
struct cgroupfs_root *root = cgrp->root;
/* threadgroup list cursor and array */
struct task_struct *leader = tsk;
struct task_and_cgroup *tc;
struct flex_array *group;
struct cgroup_taskset tset = { };
group = flex_array_alloc(sizeof(*tc), group_size, GFP_KERNEL);
retval = flex_array_prealloc(group, 0, group_size, GFP_KERNEL); //预分配内存,考虑到了多线程的进程
i = 0;
rcu_read_lock();
do { // 兼顾多线程进程,将所有线程的相关信息放在tset里
struct task_and_cgroup ent;
ent.task = tsk;
ent.cgrp = task_cgroup_from_root(tsk, root);
retval = flex_array_put(group, i, &ent, GFP_ATOMIC);
BUG_ON(retval != 0);
i++;
next:
if (!threadgroup)
break;
} while_each_thread(leader, tsk);
rcu_read_unlock();
group_size = i;
tset.tc_array = group;
tset.tc_array_len = group_size;
for_each_subsys(root, ss) { //调用每个subsys的方法,判断是否可绑定.
if (ss->can_attach) {
retval = ss->can_attach(cgrp, &tset);
if (retval) {
failed_ss = ss;
goto out_cancel_attach;
}
}
}
for (i = 0; i < group_size; i++) { // 为每个task准备(已有或分配)css_set,css_set是多个进程共享.
tc = flex_array_get(group, i);
tc->cg = find_css_set(tc->task->cgroups, cgrp);
if (!tc->cg) {
retval = -ENOMEM;
goto out_put_css_set_refs;
}
}
for (i = 0; i < group_size; i++) { // 将所有task从old css_set迁移到new css_set.
tc = flex_array_get(group, i);
cgroup_task_migrate(tc->cgrp, tc->task, tc->cg);
}
for_each_subsys(root, ss) { // 调用subsys的attach方法,执行绑定.
if (ss->attach)
ss->attach(cgrp, &tset);
}
retval = 0
return retval;
}
这里的can_attach和attach由每个subsys实现,这里先不说了.
因为创建层级时会把系统上所有的进程加到根cgroup的tasks中,所以用户层将task加进某个cgroup等同于将task从一个cgroup移到另一个cgriup.
cgroup_task_migrate就是将task与新的cgroup对应的css_set重新映射起来.
如若不对请指出。
参考资料:
linux-3.10源码
<linux cgroup详解><zhefwang@gmail.com>连接找不到了

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步