

FOREIGN MySQL 之 多表查询
一.多表联合查询


#创建部门 CREATE TABLE IF NOT EXISTS dept ( did int not null auto_increment PRIMARY KEY, dname VARCHAR(50) not null COMMENT '部门名称' )ENGINE=INNODB DEFAULT charset utf8; #添加部门数据 INSERT INTO `dept` VALUES ('1', '教学部'); INSERT INTO `dept` VALUES ('2', '销售部'); INSERT INTO `dept` VALUES ('3', '市场部'); INSERT INTO `dept` VALUES ('4', '人事部'); INSERT INTO `dept` VALUES ('5', '鼓励部'); -- 创建人员 DROP TABLE IF EXISTS `person`; CREATE TABLE `person` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) NOT NULL, `age` tinyint(4) DEFAULT '0', `sex` enum('男','女','人妖') NOT NULL DEFAULT '人妖', `salary` decimal(10,2) NOT NULL DEFAULT '250.00', `hire_date` date NOT NULL, `did` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8; -- 添加人员数据 -- 教学部 INSERT INTO `person` VALUES ('1', 'alex', '28', '人妖', '53000.00', '2010-06-21', '1'); INSERT INTO `person` VALUES ('2', 'wupeiqi', '23', '男', '8000.00', '2011-02-21', '1'); INSERT INTO `person` VALUES ('3', 'egon', '30', '男', '6500.00', '2015-06-21', '1'); INSERT INTO `person` VALUES ('4', 'jingnvshen', '18', '女', '6680.00', '2014-06-21', '1'); -- 销售部 INSERT INTO `person` VALUES ('5', '歪歪', '20', '女', '3000.00', '2015-02-21', '2'); INSERT INTO `person` VALUES ('6', '星星', '20', '女', '2000.00', '2018-01-30', '2'); INSERT INTO `person` VALUES ('7', '格格', '20', '女', '2000.00', '2018-02-27', '2'); INSERT INTO `person` VALUES ('8', '周周', '20', '女', '2000.00', '2015-06-21', '2'); -- 市场部 INSERT INTO `person` VALUES ('9', '月月', '21', '女', '4000.00', '2014-07-21', '3'); INSERT INTO `person` VALUES ('10', '安琪', '22', '女', '4000.00', '2015-07-15', '3'); -- 人事部 INSERT INTO `person` VALUES ('11', '周明月', '17', '女', '5000.00', '2014-06-21', '4'); -- 鼓励部 INSERT INTO `person` VALUES ('12', '苍老师', '33', '女', '1000000.00', '2018-02-21', null);
|
1
2
|
#多表查询语法select 字段1,字段2... from 表1,表2... [where 条件] |
注意: 如果不加条件直接进行查询,则会出现以下效果,这种结果我们称之为 笛卡尔乘积
|
1
2
|
#查询人员和部门所有信息select * from person,dept |
笛卡尔乘积公式 : A表中数据条数 * B表中数据条数 = 笛卡尔乘积.
select * from person ,dept;
|
1
2
3
4
|
#查询人员和部门所有信息select * from person,dept where person.dept_id = dept.did;#注意: 多表查询时,一定要找到两个表中相互关联的字段,并且作为条件使用 |
select * from person,dept where person.did = dept.did;
二 多表连接查询
|
1
2
3
4
|
#多表连接查询语法(重点)SELECT 字段列表 FROM 表1 INNER|LEFT|RIGHT JOIN 表2ON 表1.字段 = 表2.字段; |
1 内连接查询 (只显示符合条件的数据)
|
1
2
|
#查询人员和部门所有信息select * from person inner join dept on person.did =dept.did; |
效果: 大家可能会发现, 内连接查询与多表联合查询的效果是一样的.
select * from person inner join dept on person.did =dept.did;
2 左外连接查询 (左边表中的数据优先全部显示)
|
1
2
|
#查询人员和部门所有信息select * from person left join dept on person.did =dept.did; |
效果:人员表中的数据全部都显示,而 部门表中的数据符合条件的才会显示,不符合条件的会以 null 进行填充.
select * from person left join dept on person.did =dept.did;
3 右外连接查询 (右边表中的数据优先全部显示)
|
1
2
|
#查询人员和部门所有信息select * from person right join dept on person.did =dept.did; |
效果:正好与[左外连接相反]
select * from person right join dept on person.did =dept.did;
4 全连接查询(显示左右表中全部数据)
全连接查询:是在内连接的基础上增加 左右两边没有显示的数据
注意: mysql并不支持全连接 full JOIN 关键字
注意: 但是mysql 提供了 UNION 关键字.使用 UNION 可以间接实现 full JOIN 功能
|
1
2
3
4
5
|
#查询人员和部门的所有数据SELECT * FROM person LEFT JOIN dept ON person.did = dept.didUNIONSELECT * FROM person RIGHT JOIN dept ON person.did = dept.did; |
SELECT * FROM person LEFT JOIN dept ON person.did = dept.did
UNION
SELECT * FROM person RIGHT JOIN dept ON person.did = dept.did;
注意: UNION 和 UNION ALL 的区别:UNION 会去掉重复的数据,而 UNION ALL 则直接显示结果
三 复杂条件多表查询
1. 查询出 教学部 年龄大于20岁,并且工资小于40000的员工,按工资倒序排列.(要求:分别使用多表联合查询和内连接查询)
#1.多表联合查询方式: select * from person where did =(select did from dept where dname ='教学部') and age>20 and salary <40000 ORDER BY salary DESC; #2.内连接查询方式: SELECT * FROM person p1 INNER JOIN dept d2 ON p1.did= d2.did and d2.dname='教学部' and age>20 and salary <40000 ORDER BY salary DESC;
2.查询每个部门中最高工资和最低工资是多少,显示部门名称
select MAX(salary),MIN(salary),dept.dname from person LEFT JOIN dept ON person.did = dept.did GROUP BY person.did;
四 子语句查询
子查询(嵌套查询): 查多次, 多个select
注意: 第一次的查询结果可以作为第二次的查询的 条件 或者 表名 使用.
子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字. 还可以包含比较运算符:= 、 !=、> 、<等.
1.作为表名使用
|
1
2
3
|
select * from (select * from person) as 表名(起别名,不能带引号);ps:大家需要注意的是: 一条语句中可以有多个这样的子查询,在执行时,最里层括号(sql语句) 具有优先执行权.<br>注意: as 后面的表名称不能加引号('') |
2.求最大工资那个人的姓名和薪水
1.求最大工资 select max(salary) from person; 2.求最大工资那个人叫什么 select name,salary from person where salary=53000; 合并 select name,salary from person where salary=(select max(salary) from person);
3. 求工资高于所有人员平均工资的人员
1.求平均工资 select avg(salary) from person; 2.工资大于平均工资的 人的姓名、工资 select name,salary from person where salary > 21298.625; 合并 select name,salary from person where salary >(select avg(salary) from person);
4.练习
1.查询平均年龄在20岁以上的部门名
2.查询教学部 下的员工信息
3.查询大于所有人平均工资的人员的姓名与年龄
#1.查询平均年龄在20岁以上的部门名 SELECT * from dept where dept.did in ( select dept_id from person GROUP BY dept_id HAVING avg(person.age) > 20 ); #2.查询教学部 下的员工信息 select * from person where dept_id = (select did from dept where dname ='教学部'); #3.查询大于所有人平均工资的人员的姓名与年龄 select * from person where salary > (select avg(salary) from person);
5.关键字
假设any内部的查询语句返回的结果个数是三个,如:result1,result2,result3,那么, select ...from ... where a > any(...); -> select ...from ... where a > result1 or a > result2 or a > result3;
ALL关键字与any关键字类似,只不过上面的or改成and。即: select ...from ... where a > all(...); -> select ...from ... where a > result1 and a > result2 and a > result3;
some关键字和any关键字是一样的功能。所以: select ...from ... where a > some(...); -> select ...from ... where a > result1 or a > result2 or a > result3;
EXISTS 和 NOT EXISTS 子查询语法如下: SELECT ... FROM table WHERE EXISTS (subquery) 该语法可以理解为:主查询(外部查询)会根据子查询验证结果(TRUE 或 FALSE)来决定主查询是否得以执行。 mysql> SELECT * FROM person -> WHERE EXISTS -> (SELECT * FROM dept WHERE did=5); Empty set (0.00 sec) 此处内层循环并没有查询到满足条件的结果,因此返回false,外层查询不执行。 NOT EXISTS刚好与之相反 mysql> SELECT * FROM person -> WHERE NOT EXISTS -> (SELECT * FROM dept WHERE did=5); +----+----------+-----+-----+--------+------+ | id | name | age | sex | salary | did | +----+----------+-----+-----+--------+------+ | 1 | alex | 28 | 女 | 53000 | 1 | | 2 | wupeiqi | 23 | 女 | 29000 | 1 | | 3 | egon | 30 | 男 | 27000 | 1 | | 4 | oldboy | 22 | 男 | 1 | 2 | | 5 | jinxin | 33 | 女 | 28888 | 1 | | 6 | 张无忌 | 20 | 男 | 8000 | 3 | | 7 | 令狐冲 | 22 | 男 | 6500 | 2 | | 8 | 东方不败 | 23 | 女 | 18000 | NULL | +----+----------+-----+-----+--------+------+ 8 rows in set 当然,EXISTS关键字可以与其他的查询条件一起使用,条件表达式与EXISTS关键字之间用AND或者OR来连接,如下: mysql> SELECT * FROM person -> WHERE AGE >23 AND NOT EXISTS -> (SELECT * FROM dept WHERE did=5); 提示: •EXISTS (subquery) 只返回 TRUE 或 FALSE,因此子查询中的 SELECT * 也可以是 SELECT 1 或其他,官方说法是实际执行时会忽略 SELECT 清单,因此没有区别。
五 其他查询
1.临时表查询
需求: 查询高于本部门平均工资的人员
解析思路: 1.先查询本部门人员平均工资是多少.
2.再使用人员的工资与部门的平均工资进行比较
#1.先查询部门人员的平均工资 SELECT did,AVG(salary)as sal from person GROUP BY did; #2.再用人员的工资与部门的平均工资进行比较 SELECT * FROM person as p1, (SELECT did,AVG(salary)as '平均工资' from person GROUP BY did) as p2 where p1.did = p2.did AND p1.salary >p2.`平均工资`;#注意引号不一样 ps:在当前语句中,我们可以把上一次的查询结果当前做一张表来使用.因为p2表不是真是存在的,所以:我们称之为 临时表 临时表:不局限于自身表,任何的查询结果集都可以认为是一个临时表.
2. 判断查询 IF关键字
需求1 :根据工资高低,将人员划分为两个级别,分别为 高端人群和低端人群。显示效果:姓名,年龄,性别,工资,级别
select *,if(p.salary > 10000,'高端人群','低端人群') as '级别' from person p; #ps: 语法: IF(条件表达式,"结果为true",'结果为false');
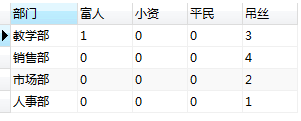
需求2: 根据工资高低,统计每个部门人员收入情况,划分为 富人,小资,平民,吊丝 四个级别, 要求统计四个级别分别有多少人
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#语法一:SELECT CASE WHEN STATE = '1' THEN '成功' WHEN STATE = '2' THEN '失败' ELSE '其他' END FROM 表;#语法二:SELECT CASE age WHEN 23 THEN '23岁' WHEN 27 THEN '27岁' WHEN 30 THEN '30岁' ELSE '其他岁' ENDFROM person; |
select dname '部门', sum(case when salary >50000 then 1 else 0 END) as '富人', sum(case when salary between 29000 and 50000 then 1 else 0 end) as '小资', sum(case when salary between 10000 and 29000 then 1 else 0 end) as '平民', sum(case when salary < 10000 then 1 else 0 end) as '屌丝' from person,dept where person.did = dept.did group by person.did;
六 SQL逻辑查询语句执行顺序(重点***)
先来一段伪代码,首先你能看懂么?
|
1
2
3
4
5
6
7
8
9
|
SELECT DISTINCT <select_list>FROM <left_table><join_type> JOIN <right_table>ON <join_condition>WHERE <where_condition>GROUP BY <group_by_list>HAVING <having_condition>ORDER BY <order_by_condition>LIMIT <limit_number> |
如果你知道每个关键字的意思和作用,并且你还用过的话,那再好不过了。但是,你知道这些语句,它们的执行顺序你清楚么?如果你非常清楚,你就没有必要再浪费时间继续了;如果你不清楚,非常好!!! 请点击我...
七 外键约束
1.问题?
什么是约束:约束是一种限制,它通过对表的行或列的数据做出限制,来确保表的数据的完整性、唯一性
2.问题?
以上两个表 person和dept中, 新人员可以没有部门吗?
3.问题?
新人员可以添加一个不存在的部门吗?
4.如何解决以上问题呢?
简单的说,就是对两个表的关系进行一些约束 (即: froeign key).
foreign key 定义:就是表与表之间的某种约定的关系,由于这种关系的存在,能够让表与表之间的数据,更加的完整,关连性更强。
5.具体操作
5.1创建表时,同时创建外键约束
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
CREATE TABLE IF NOT EXISTS dept ( did int not null auto_increment PRIMARY KEY, dname VARCHAR(50) not null COMMENT '部门名称')ENGINE=INNODB DEFAULT charset utf8; CREATE TABLE IF NOT EXISTS person( id int not null auto_increment PRIMARY KEY, name VARCHAR(50) not null, age TINYINT(4) null DEFAULT 0, sex enum('男','女','人妖') NOT NULL DEFAULT '人妖', salary decimal(10,2) NULL DEFAULT '250.00', hire_date date NOT NULL, dept_id int(11) DEFAULT NULL, CONSTRAINT fk_did FOREIGN KEY(dept_id) REFERENCES dept(did) -- 添加外键约束)ENGINE = INNODB DEFAULT charset utf8; |
5.2 已经创建表后,追加外键约束
|
1
2
3
4
5
|
#添加外键约束ALTER table person add constraint fk_did FOREIGN key(dept_id) REFERENCES dept(did);#删除外键约束ALTER TABLE person drop FOREIGN key fk_did; |
定义外键的条件:
(1)外键对应的字段数据类型保持一致,且被关联的字段(即references指定的另外一个表的字段),必须保证唯一
(2)所有tables的存储引擎必须是InnoDB类型.
(3)外键的约束4种类型: 1.RESTRICT 2. NO ACTION 3.CASCADE 4.SET NULL
数据库设计三范式: http://www.cnblogs.com/aaronthon/p/8480011.html
