
每日一记--HashTable/HashMap/ConcurrentHashMap
今天重点学习一下HashTable/HashMap/ConcurrentHashMap之间区别,这个问题一直困扰着我,所以想看看这里面到底有什么神奇的东东在里面。
只是简单的对这三者之间的区别进行总结,目的很简单为了将知识点进行一次有结构的复习思路,来面对面试。
然后将看到的几篇有质量的文章进行推荐。
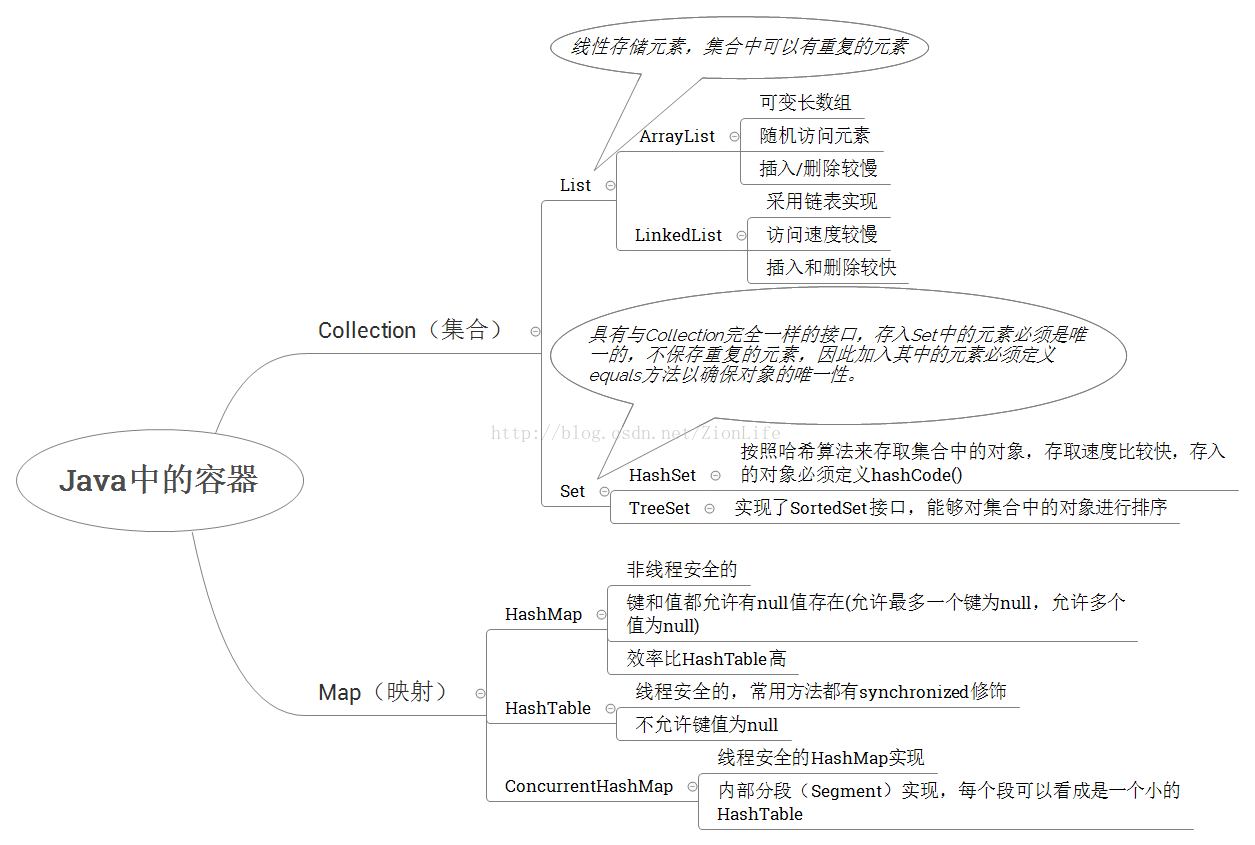
1、首先HashTable与HashMap之间的区别。
①从继承的父类上看:HashTable继承Dictionary,HashMap继承AbstractMap。
②内部使用迭代器的区别:HashTable使用Enumeration枚举,遍历的结果是先进后出,HashMap使用Iterator迭代器,遍历的结果是先进先出。
③线程安全性:HashTable线程安全采用synchronized关键字,HashMap线程不安全,因此执行效率高。
④内部扩容机制:HashTable扩容采用Old*2+1,且默认大小为11;HashMap扩容机制为2^n,默认大小为16。
⑤键值:HashTable的key与value都不可以为null,否则会抛出NullPointerException异常,HashMap的key可以为null,但是键值只能有一个null。
2、ConcurrentHashMap
对于ConcurrentHashMap,主要的是将Map划分为多个HashTable,采用锁分离技术。
Hashtable是线程安全的,synchronized是针对整张表,即每次锁住整张表让线程独占,
ConcurrentHashMap则允许多个修改并发进行,其关键在于使用了锁分离技术,使用多个锁来控制对hash表不同部分进行的修改。
ConcurrentHashMap内部使用段(Segment)来表示不同的部分,每个段其实就是一个小的hash表,它们有自己的锁,只要多个修改发生在不同的段上,它们就可以并发进行。
针对有些需要跨段的方法,比如size()、containsValue()等,需要锁定的是整张表,因此需要按顺序锁定所有的段,操作完毕后再按顺序释放所有的段。这里的顺序很重要,否则可能发生死锁。
ConcurrentHashMap中的读操作不用加锁,完全允许多个读操作并发进行。
