软工个人项目之词频统计
GitHub仓库地址:https://github.com/ZCplayground/personal-project
PSP 表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 60 |
| Development | 开发 | 440 | 745 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 60 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 30 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 15 |
| · Design | · 具体设计 | 60 | 30 |
| · Coding | · 具体编码 | 120 | 330 |
| · Code Review | · 代码复审 | 60 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 240 |
| Reporting | 报告 | 80 | 60 |
| · Test Repor | · 测试报告 | 60 | 40 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | 540 | 865 |
需求分析
对程序的功能进行需求分析如下:
- 统计文件有多少个字符,包括空格制表符换行符等。
- 统计文件的有效行数,含非空白字符的行的数量,也就是跳过 空行 的行数。
- 统计单词的总数,本题中“单词”的定义是:
- 以4个英文字母
A-Z,a-z开头,后续可以是字母和数字A-Z, a-z,0-9。file123是一个单词,123file不是一个单词。(换言之,如果有一行内容是123file,那么“单词”是file。)(9/10注:此处题意理解有误,请看文章末尾的更新) - 分割符是非字母数字符号,空格。
- 不区分大小写,例如
file和FILE是同一个单词。
- 以4个英文字母
- 统计文件中各单词的出现次数,然后输出频率最高的10个,单词定义同上,按照如下格式输出:频率相同的单词,优先输出字典序靠前的单词。
非功能性方面的分析:
- 使用GitHub进行代码管理,代码有进展即签入Github。对代码签入的具体要求如下:根据需求划分功能后,每做完一个功能,编译成功后,应至少commit一次。
- 是一个命令行程序,参数是一个输入文件的文件名,
input.txt - 希望把“统计字符数”、“统计单词数”、“统计最多的10个单词词频”这三个功能独立出来,成为独立的模块。
- 除了核心模块之外,还需要有一定的界面和必要的辅助功能。
- 单元测试,要设计至少10个测试用例。
思路
拿到题目之后,可以说要求中的第1和第2点都不算太难,C语言的练习题的难度。看到要求3一下子想到了有限自动机(Deterministic Finite Automaton,DFA) 。上学期在计算理论上课上学到了在数学上自动机和正则表达式是等价的,就打算实现一个DFA来做。对于功能4,首先想到了用哈希表(unordered_map)来统计出现的单词数量,这样在查询时时间复杂度较小,为O(1)。统计最多的十个,自然想到了堆/优先队列(priority_queue),但发现有字典序排序的要求,想了想是否可以用红黑树(map)存储后直接输出,但实现了红黑树版本之后,分析一番发现可以通过只维护10个单词的大小的堆处理所有单词,最后排序输出,可以剩下大量的空间,并小部分优化时间复杂度。大概花了半个小时画了画自动机的图,理清需要分几个模块,以及要求123的思路;再花了二十分钟左右分析了要求4的算法。

设计文档
输入输出
输入由命令行参数指定需要进行统计的文件名。普通的后缀为.txt的文本文件,不考虑汉字的存在。
示例输入,对于一个内容如下input.txt的文件:
a
a
a
abcd
abcd1234
abcd
abcd
file
FILE
123file
运行指令 > .\WordCount.exe .\input.txt 应该得到如下的示例输出:
In this file:
Number of characters: 48
Number of non-empty lines: 10
Number of words: 7
Top 10 words:
3 abcd
3 file
1 abcd1234
解释:
- 共有49个字符,10个非空行,7个单词;
a由于没有4个连续字母,故不是单词;abcd和abcd1234是不同的单词;abcd和abcd(字母前有一个空格)都算作单词abcd、123file和file算同一个单词;(9/10注:此处题意理解有误,请看文章末尾的更新)file和FILE算同一个单词;abcd和file都出现了三次,要先输出字典序靠前的abcd。
环境
- 操作系统:Windows 10
- IDE:Visual Studio 2017 Community
- 编程语言:C++
代码规范
翻阅了《构建之法(第三版)》P68的代码规范内容,选取了部分用的上的规范应用到本项目中。
- 行宽限制为100字符。不过在编码时没有注意看一行的字符数,在编完整个项目后找了句最长的语句看也没有超过90个字符。
- 断行与空白的大括号行,选择了左大括号和当前语句同一行,右大括号独占一行的形式。
- 命名风格。
- 变量使用Camel:由多个单词组成的变量名,第一个单词的首字母小写,随后单词的第一个字母大写。
- 函数使用Pascal:所有单词的第一个字母大写。
- 注释
- 不要注释How(程序怎样工作),而是注释What和Why(程序做了什么,为什么这么做)。好的代码自身就可以解释How。
- 注释不要用中文。
- 在头文件中对函数进行详细的注释,格式参考了这一篇博客
举个例子,下面是我对统计有效行数CountLines()这个函数的注释:
/*
* Function name: CountLines
* Description:
* Count the number of lines of the file, skip empty lines.
* Parameter:
* @filename: File that need to be counted
* Return:
* @int: total number of lines
*/
int CountLines(char * filename);
具体设计
代码文件结构组织
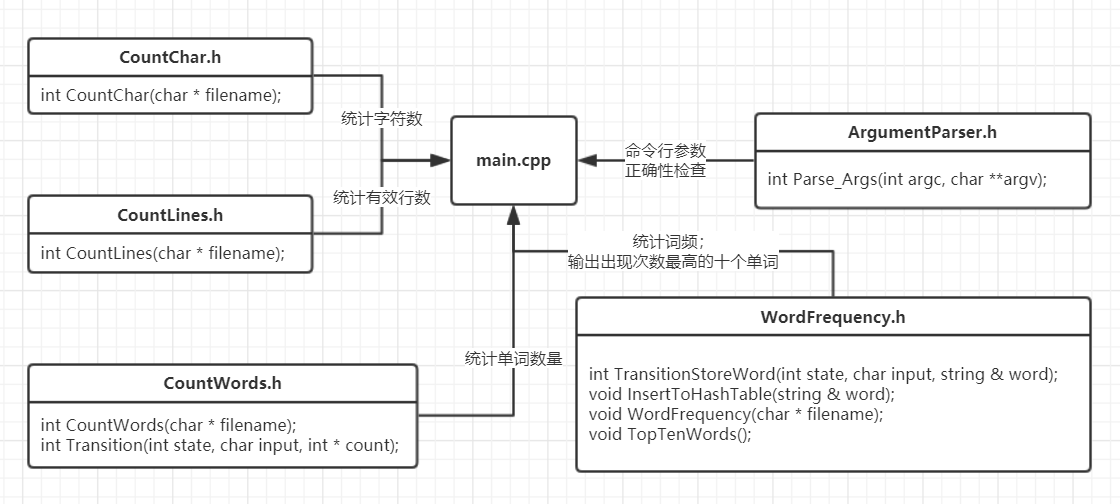
为了达到设计要求中的“统计字符数”、“统计单词数”、“统计最多的10个单词词频”三个功能独立成为独立的模块,将本项目的代码文件结构进行如下的组织:
ArgumentParser.h:用于解析命令行参数;CountChar.h:用于统计一个文件内的字符数;CountLines.h:用于统计一个文件内的有效行数;CountWords.h:用于统计一个文件内的有效单词数量;WordFrequency.h:用于分析一个文件内的词频数据,并输出最高的十个;main.cpp:调用如上文件内的函数,向用户显示统计结果;UnitTest1:单元测试内容。
算法
- 统计文件内的字符数,打开文件后循环读入字符直到文件尾,计数即可。
- 统计一个文件内的有效行数,设置一个状态,每次读到一个换行符
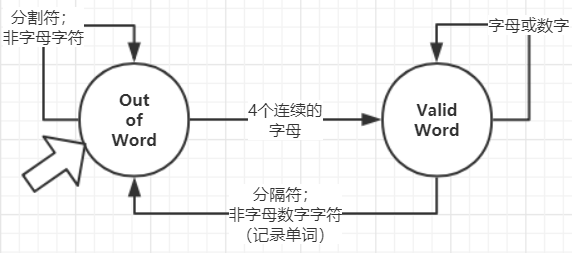
\n时,判断该行状态是否为空行,只有不为空行时才计数。 - 统计一个文件内的有效单词数量:使用了有限状态自动机思想
- 共有两个状态,
Out of Word表示当前没有识别到合法单词,是,Valid Word状态表示当前识别到了合法单词。 Out of Word要识别连续4个字母,转变为Valid Word状态。- 进入
Valid Word状态后,输入字母和数字都会继续保持在Valid Word状态。 - 识别到分隔符和非字母数字的字符,会进入
Out of Word状态。 - 从
Valid Word状态转移至Out of Word状态时,单词计数器加1。自动机如下图所示:
- 共有两个状态,
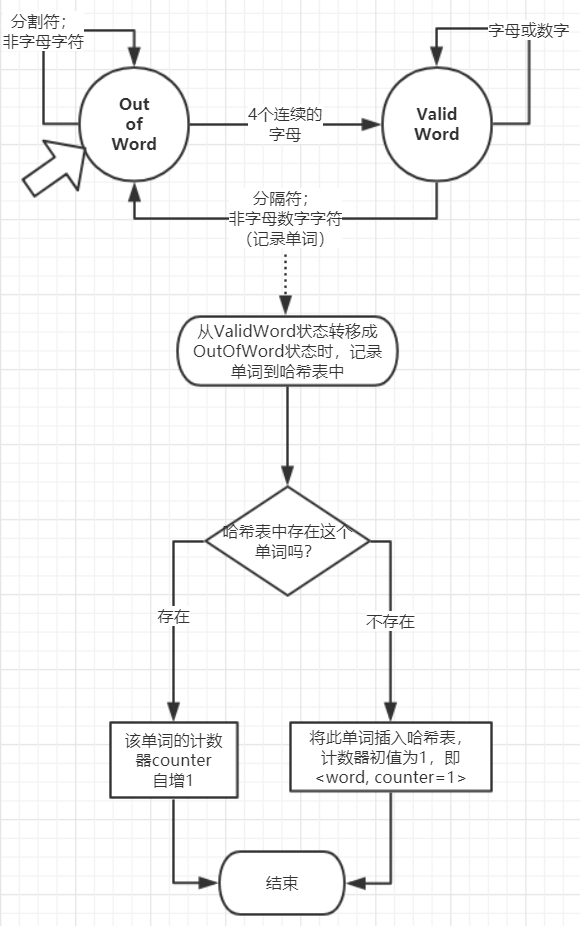
- 统计一个文件内的词频,并输出最多的10个单词:
- 记录识别到的单词。在上一个有限自动机的基础上做一些小小改动就可以实现。
- 每识记录了一个合法的完整单词,都插入哈希表中。插入前先在哈希表中查找此单词:
- 若没有找到,则说明是新单词,设置其计数器counter=1,将
<word, counter=1>插入哈希表; - 若找到,说明是已经出现过的单词,counter++即可。
- 若没有找到,则说明是新单词,设置其计数器counter=1,将
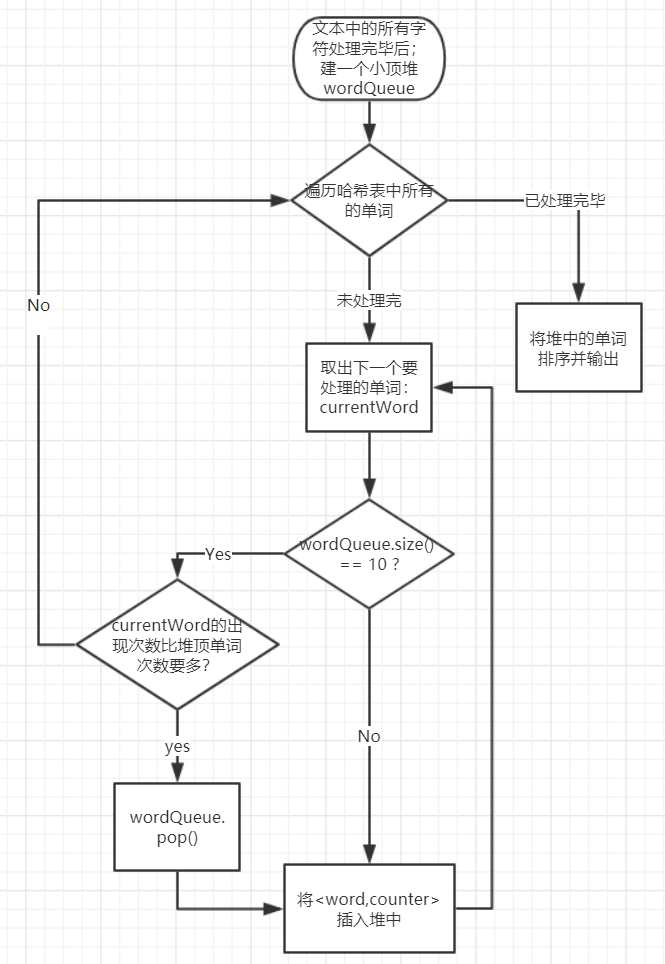
- 建立一个小顶堆。
- 遍历hashtable中的每一个单词,准备将其放入堆中。
- 若堆内元素大小小于10,则直接push进堆即可。返回步骤4
- 若堆内元素大小达到10,则需要对比堆顶单词的计数器和当前单词的计数器,若堆顶单词出现次数更少,则弹出堆顶单词,插入新单词。若计数器一样,就比较字典序,字典序小的会被淘汰。返回步骤4
- 所有单词处理完毕后,将堆中的10个(或小于10个)单词按要求排序并输出即可。
算法复杂度
- 统计字符、行数、单词数都是O(N),N为
input.txt的文件内容的长度。由于用了自己写的自动机,也许常数会(相较成熟的正则表达式库)大一点。 - 输出10个出现次数最多的单词。设N为
input.txt的文件内容的长度,设M为input.txt合法单词的个数,设K为小顶堆的size,也就是要输出K个最常见的单词,这里K=10。- O(N)扫描文本,找出所有单词;
- 共有M个单词,将所有单词插入hashtable,复杂度O(1)
- 最坏情况是有M个不同的单词,这M个单词都要执行优先队列的操作。优先队列的大小是K,复杂度 M*O(log K)
- 总时间复杂度为 O(N) + M*O(log K)
流程图 & 结构图
- 工程框架
- 有穷自动机 & 插入HashTable
- 统计词频算法
编码 & 展示部分关键代码
(博文中用中文进行注释,实际项目文件中是英文):
1.使用有穷自动机识别合法单词,并存储到一个string对象中。识别到一个完整的单词后,插入hashtable。
#define OUTWORD 0 // 5个自动机状态
#define P1 1
#define P2 2
#define P3 3
#define VALIDWORD 4
#define ERROR 5
int TransitionStoreWord(int state, char input, string & word)
{
switch (state)
{
case OUTWORD:
if (!isalpha(input) || isspace(input)) return OUTWORD;
else if (isalpha(input)) { word += input; return P1; } // 在形成合法单词的过程中,将其记录在一个string对象中
case P1:
if (isalpha(input)) { word += input; return P2; }
else { word.clear(); return OUTWORD; } // 若要回到 OUTWORD 状态,将string对象清空
case P2:
if (isalpha(input)) { word += input; return P3; }
else { word.clear(); return OUTWORD; }
case P3:
if (isalpha(input)) { word += input; return VALIDWORD; }
else { word.clear(); return OUTWORD; }
case VALIDWORD:
if (isalnum(input)) { word += input; return VALIDWORD; }
else {
InsertToHashTable(word); // 得到一个完整的合法单词后,就插入到HashTable中
word.clear();
return OUTWORD;
}
}
return ERROR;
}
2.按照格式要求显示词频最高的十个单词:
int TopTenWords()
{
for (hash_iter = hash_table.begin(); hash_iter != hash_table.end(); hash_iter++) { // 遍历hashtable中的每个单词
pair<int, string> currentWord = make_pair(hash_iter->second, hash_iter->first); // 当前处理的单词
if (wordQueue.size() == 10) { // 若优先队列内已有10个单词
pair<int, string> minFreqWord = wordQueue.top(); // 查看堆顶(小顶堆,所以就是出现次数目前排第十位的)单词的出现次数
if (currentWord.first > minFreqWord.first ||
(currentWord.first == minFreqWord.first && currentWord.second > minFreqWord.second)) {
// 若当前处理的单词的出现次数比堆顶更大,或出现次数相同但字典序靠前,就将堆顶抛出,将新单词入堆
wordQueue.pop();
wordQueue.push(currentWord);
}
}
else { // 若优先队列内不满10个单词,直接入队
wordQueue.push(currentWord);
}
}
if (wordQueue.size() == 0) {
return -1;
}
int count = wordQueue.size();
vector<pair<int, string>> Top10words;
while (!wordQueue.empty()) {
Top10words.push_back(wordQueue.top());
wordQueue.pop();
}
sort(Top10words.begin(), Top10words.end(), MySort); // 按要求排序并输出
vector<pair<int, string>>::iterator iter;
for (iter = Top10words.begin(); iter != Top10words.end(); iter++) {
cout << iter->first << " " << iter->second << endl;
}
hash_table.clear();
return count;
}
性能分析报告 & 改进性能
参考博客是刘乾学长的培训文档。测试时使用的输入文件和设计文档中的样例输入文件内容是一样的。将main函数循环执行10000次,花费时间是56.201秒。性能分析图如下:
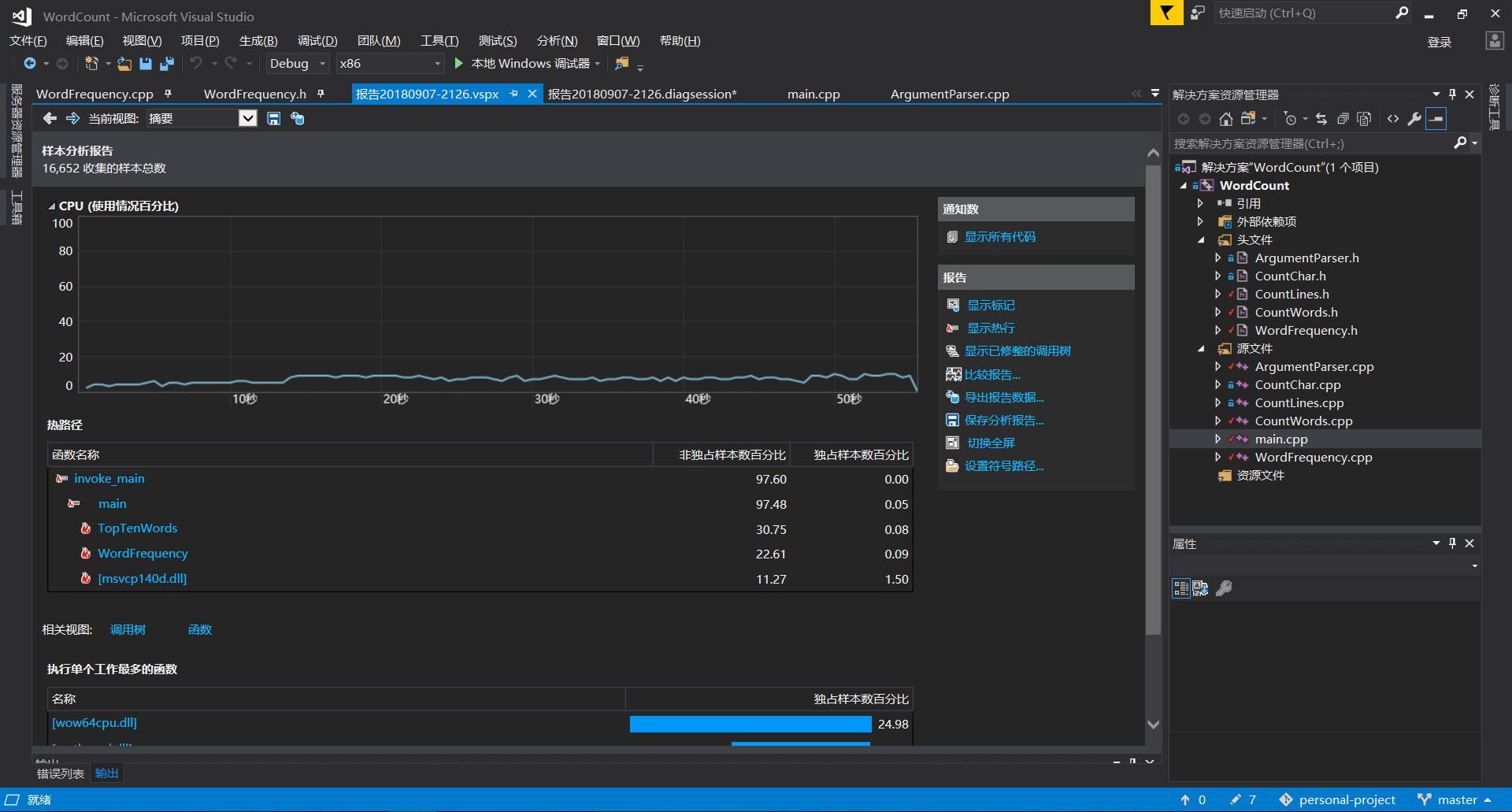
main函数占了93%的执行时间,这是因为测试性能时就是循环执行main函数。在main函数中调用的几个函数中,TopTenWords()占用了30.75%的执行时间,WordFrequency()占用了22.61%的执行时间。
对于TopTenWords(),可以看到一行字符串的C++标准输出语句占用了大量的运行时间:
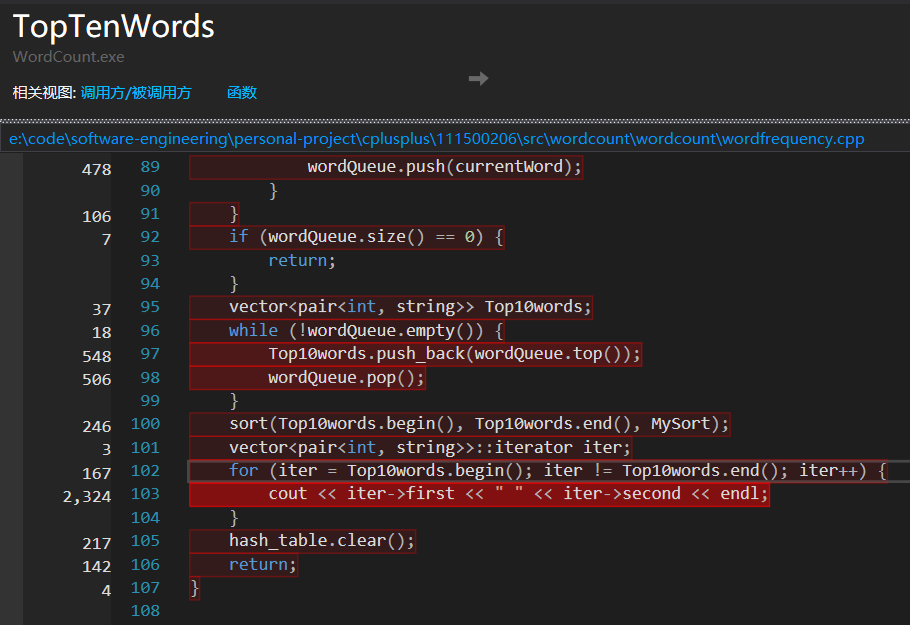
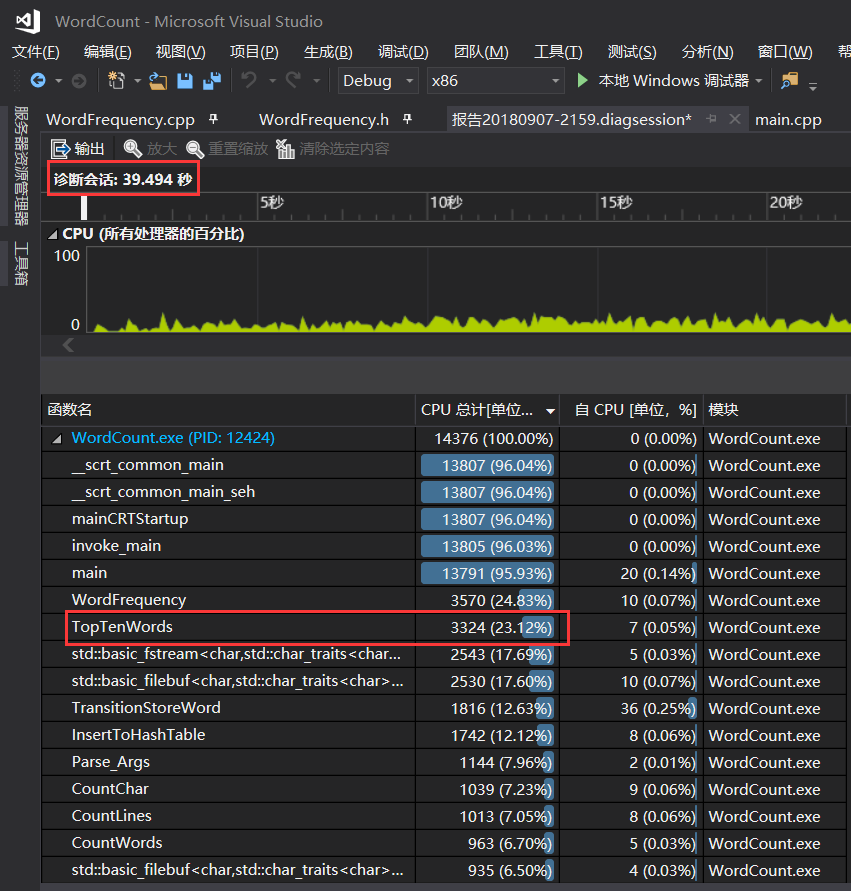
于是,将文件内所有的类似cout<<...<<...输出语句改成如下的C语言风格的输出模式,运行时间从56秒优化至了39秒。
for (iter = Top10words.begin(); iter != Top10words.end(); iter++) {
// cout << iter->first << " " << iter->second << endl;
// 修改原本的C++输出语句为下列形式:
const char *word = iter->second.c_str();
printf("%s: %d\n", word, iter->first);
}
单元测试
在VisualStdio中构建单元测试参考了邹欣老师给出的链接里刘乾学长的这篇博客。
以下是我设计的十个单元测试内容:
| 单元测试名称 | 解释 | 被测试文件 | 期待输出 |
|---|---|---|---|
| WrongInputFileName | 打开错误的文件名 | CountChar.h | 能够正确返回错误信息 |
| CountCharTest | 测试CountChar函数 | CountChar.h | 能够正确地统计字符数 |
| EmptyFileTest | 传入一个空文件 | 全部 | 统计字符数、行数、单词数的结果都应该为0 |
| EmptyLineTest | 传入一个文件,只包含空格、tab和换行符 | CountLines.h | 统计有效行数,应为0 |
| ValidLineTest | 传入一个文件,既有空行也有有效行,有效行是空白符和字符的混合 | CountLines.h | 应显示正确的有效行数 |
| WrongWord | 传入一个文件,里面每一行都是一个不能构成题目要求的有效单词的字符串 | CountWords.h | 统计单词数量,应为0 |
| ValidWord | 传入一个文件,里面每一行都是一个有效单词 | CountWords.h | 能正确统计单词数量 |
| CaseInsensitive | 传入一个文件,里面的内容是file和FILE | WordFrequency.h | 统计词频时,应将这两个单词识别为同一个单词file,计数器应该为2 |
| WordWithNumber | 单词形如file123的,字母加数字组合类型 |
WordFrequency.h | 能正确统计此种类型的词频 |
| TenMoreWord | 传入一个文件,里面有超过十个的合法单词 | WordFrequency.h | 只显示前十个的单词,且按照字典序 |
单元测试的运行结果如下图:
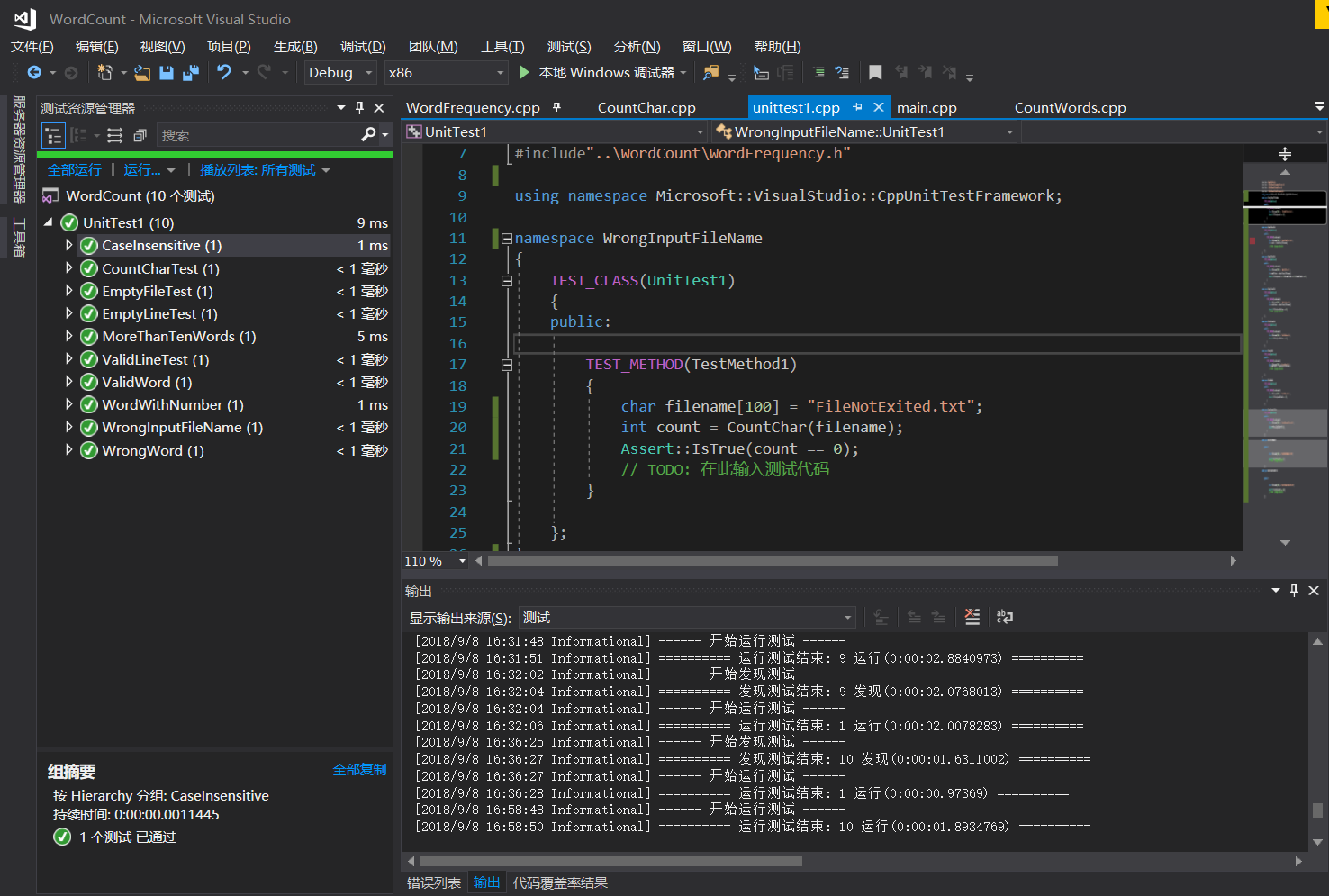
我挑选了三个单元测试代码在这里列出并给出中文注释。全部的单元测试代码在github仓库中的UnitTest1项目中可以看到。
namespace EmptyFileTest // 传入空文件的单元测试
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
char filename[100] = "EmptyFile.txt";
int count = CountChar(filename);
int numOfLines = CountLines(filename);
int numOfWords = CountWords(filename);
// 统计的结果应该都为零
Assert::IsTrue(count == 0 && numOfLines == 0 && numOfWords == 0);
// TODO: 在此输入测试代码
}
};
}
namespace WrongWord // 传入不属于题目要求的“单词”的字符串
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
char filename[100] = "WrongWord.txt";
int numOfWord = CountWords(filename);
// 统计单词的结果应该为0,因为字符串都不符合“单词”的要求
Assert::IsTrue(numOfWord == 0);
// TODO: 在此输入测试代码
}
};
}
namespace CaseInsensitive // 传入 file 和 FILE
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
char filename[100] = "CaseInsensitive.txt";
WordFrequency(filename);
int count = TopTenWords();
Assert::IsTrue(count == 1); // 这两个单词应该被识别为同一个单词
// TODO: 在此输入测试代码
}
};
}
代码覆盖率
在做这项工作时先进行了搜索,得知 VisualStudio Community 版本没有自带的分析代码覆盖率功能。经过一番搜索找到了开源的插件——OpenCppCoverage,这个插件也是比较易用的,直接下载后重启VS就可以加载。
代码覆盖率的截图如下:
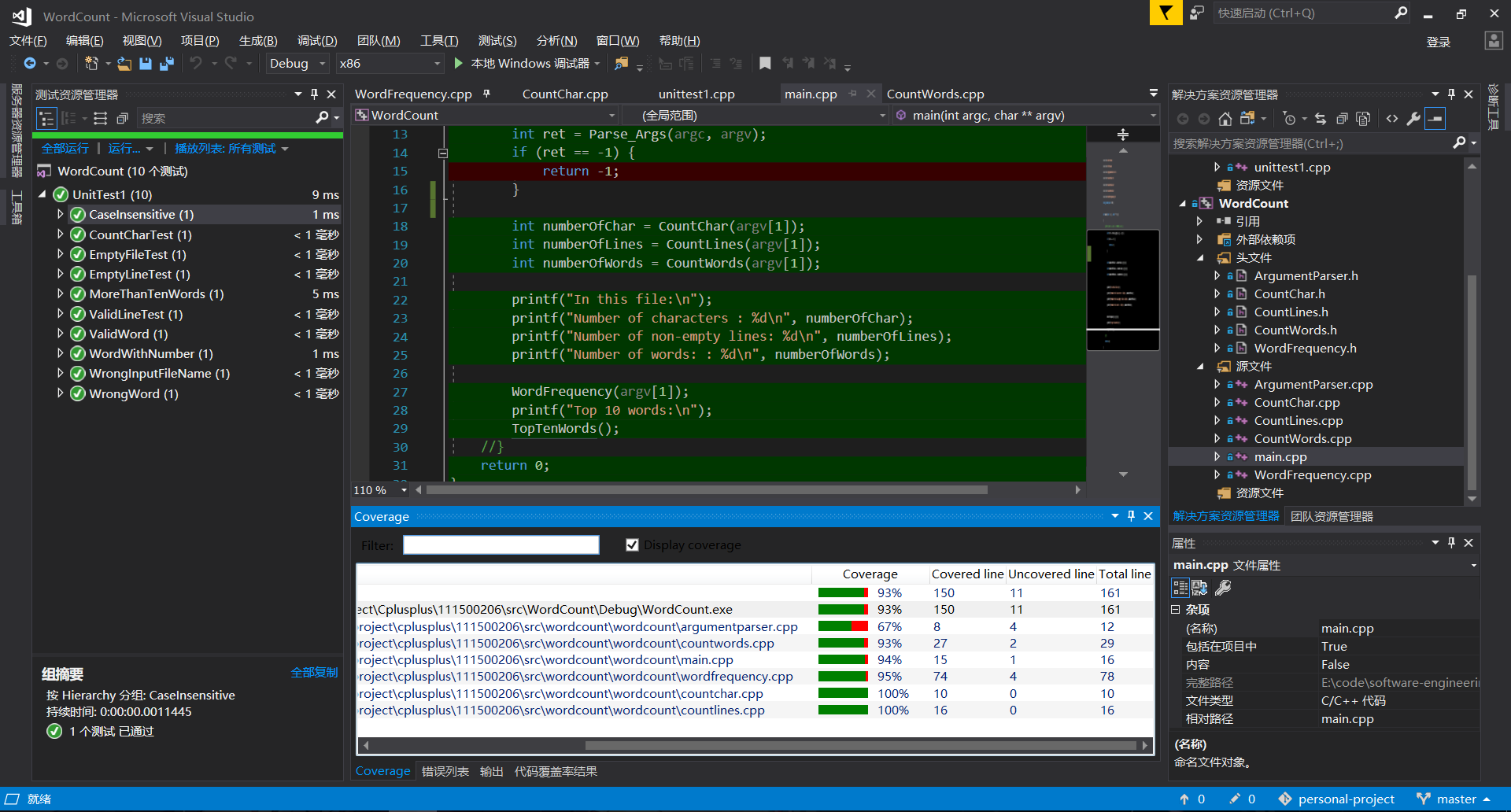
可以看到总体的代码覆盖率是不错的,除了Parse_Args()这个文件的覆盖率低得比较明显,只有64%。究其原因,是因为这个文件是为了检测不符合要求的命令行参数的,而运行正确的测试时要传入正确的命令行参数,所以异常处理的代码就没有用到。如下图所示:
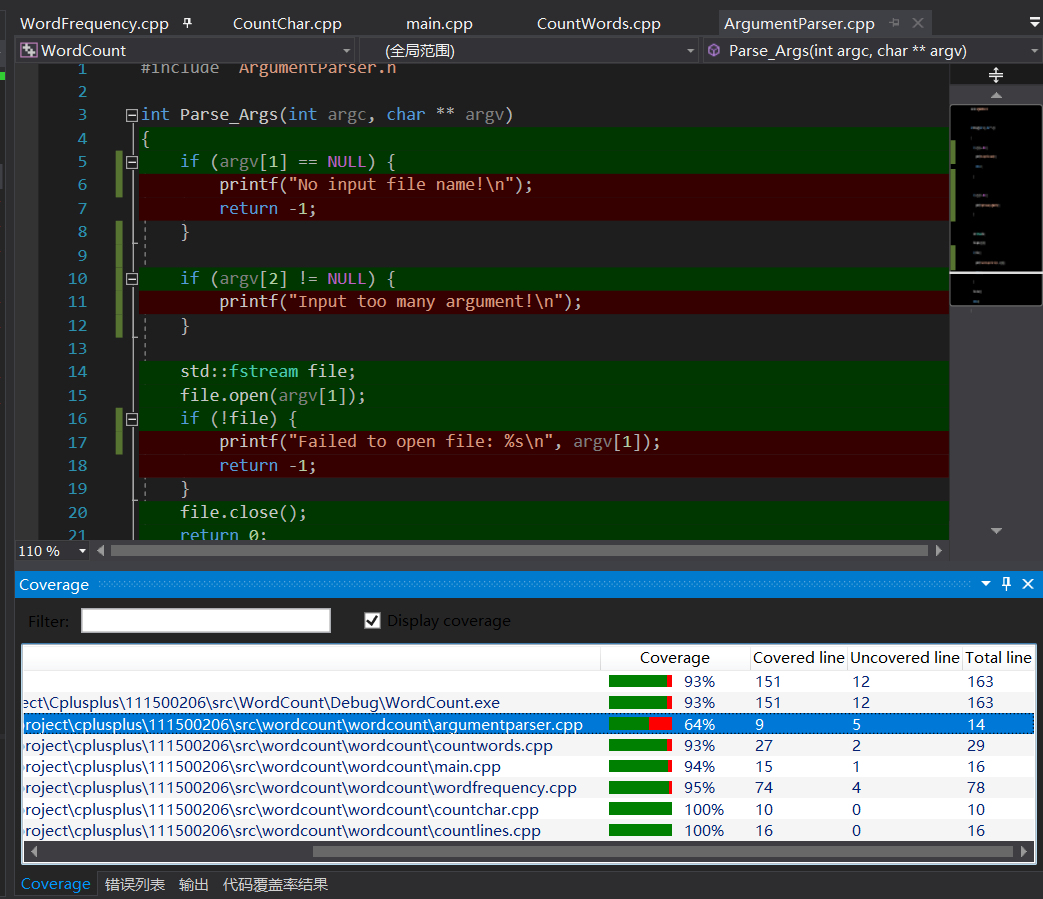
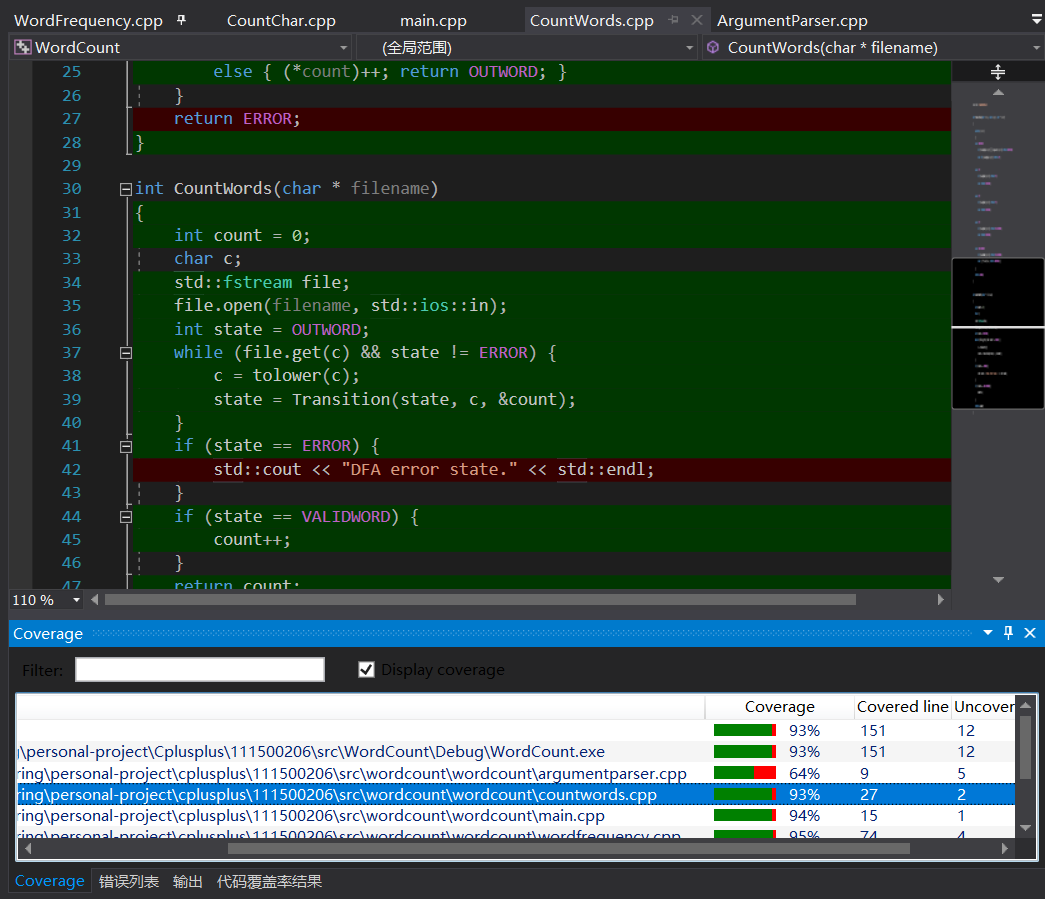
用到有限自动机的文件,例如CountWord.cpp,为其设计了一个出错的状态(防止不测),这些防御性编程的代码没有在测试时被运行到,如下图所示:
异常处理
我设计了如下异常处理:
ArgumentParser.h这个文件,用于解析命令行参数,如果出现以下情况:
- 没有传入文件名
- 传入过多的命令行参数
- 文件不能打开
都会返回错误代码并提示对应的提示信息:
int Parse_Args(int argc, char ** argv)
{
if (argv[1] == NULL) {
printf("No input file name!\n");
return -1;
}
if (argv[2] != NULL) {
printf("Input too many argument!\n");
}
std::fstream file;
file.open(argv[1]);
if (!file) {
printf("Failed to open file: %s\n", argv[1]);
return -1;
}
file.close();
return 0;
}
int main(int argc, char **argv)
{
int ret = Parse_Args(argc, argv);
if (ret == -1) {
return -1;
}
/*......*/
}
在算法中,有对应的异常处理和检查。例如TopTenWords中对于空文件的处理:
if (wordQueue.size() == 0) {
return -1;
}
总结和感想
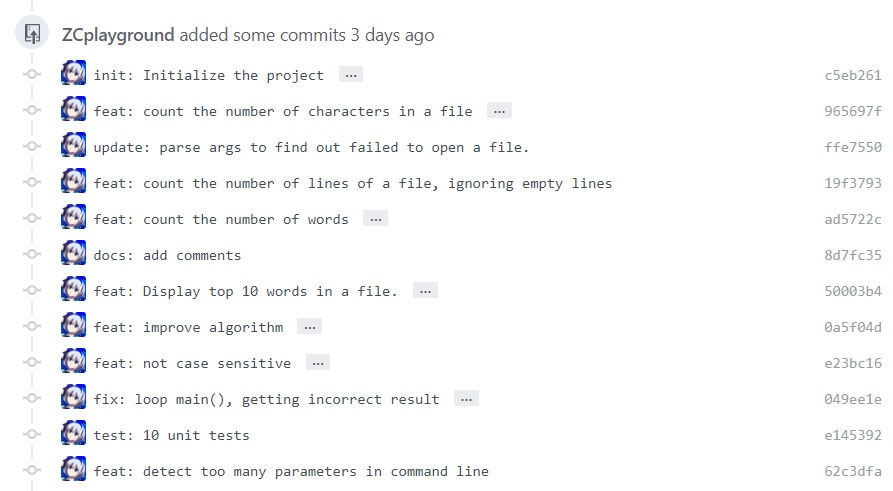
首先自己在这个项目中获得的提升是从这个作业要求中得到的:代码有进展即签入Github。按照我以前的习惯做法,可能是一天晚上准备睡觉前 git commit 一次。而这次的作业要求每次有新功能,代码有新进展,每一次编译都要commit,这样子做才是符合软件工程的要求的。为此我还对怎么写好的 commit 信息进行了学习,一趟下来感觉颇有收获。每次对项目有新的修改后就commit,加上清晰的commit信息,这样才有利于在项目出现问题时回退解决。
看书看到“不要注释How(程序怎样工作),而是注释What和Why(程序做了什么,为什么这么做)。好的代码自身就可以解释How。”,这点时表示很受用,暑假看了一些开源项目时就发现了他们的代码和注释风格就符合这一要求。所以要写出逻辑清晰的高质量代码,而不是写完烂代码加一堆注释。
作业要求我们在开始动手之前,要完成PSP的表格中的预测。一开始很不解:为什么还要估计要花多少时间?而且当时觉得估计自己要花多少时间还是挺困难的,想了很久。所以重读了《构建之法》,里面讲到“为了记录工程师如何实现需求的效率”。再阅读博客,得知之所以要估计各个模块耗费的时间并记录下来,也是为了更好地管理自己的时间。此外,“工程师在需求分析和测试这两方面明显地要比在校学生花更多的时间,从学生到程序员并不是更加没完没了地写程序”,对这一表述我深表赞同,所以这一次完成这个作业时,我先仔细地完成了需求分析和设计方面的文档。虽然自己以前就挺注重测试,以及程序的完备性,能处理各种出错的输入,以及对各个输入有正确的输出。但我花在测试方面的时间比我预估的要多很多,主要是花在了学习使用代码覆盖率工具,以及设计十个单元测试上。
通过阅读《构建之法》和博客上的例子,我大概知道了单元测试是用来干什么的:“单元测试应该准确、快速地保证程序基本模块的准确性。……单元测试测试的是程序最基本的单元——C++中的类”。虽然自己写了个基本上是C语言的纯过程语法,所幸的是还是有仔细地封装各个接口,可以使用单元测试来测试各个接口的正确性。继续看书:“最好在设计的时候就写好单元测试”,这是我没做到的地方——应该先写单元测试再写代码——自己想当然地认为单元测试可以放到整个程序都完成之后再来做。我的做法是编码时直接手动运行程序,手动在文件中自己打一些样例来测试,就是延续了在做算法题时的思路。通过读书,我得知了我这样的做法不符合软件工程的要求,没有达到单元测试的一些好处:“单元测试应该产生可重复、一致的结果”、“单元测试应该集成到自动测试的框架,这样每个人都能随时随地运行单元测试”。比较可惜的是单元测试是在整个程序写完时才写,而不是先写单元测试再写程序(或者最起码单元测试和程序要一起写),这个做法应该下次要改进。
一年前就看了《构建之法》,但当时只是纯粹地看书,仅了解过作业的形式但没有去做。今天是实打实地完成了个人项目,才体会到“纸上得来终觉浅”。
更新
9/10
1.补上了输出到文件result.txt的功能,调用方法如下:
int main(int argc, char **argv)
{
WordFrequency(argv[1]);
auto topTenWordList = TopTenWords();
StandardOutput(topTenWordList); // 标准输出
OutputToFile(topTenWordList); // 输出到文件
}
2.经 @王彬 同学提醒,误解了题意。题意里“123file不是单词”。意思是,123file后续再跟着多少字母都不算单词了,而是要遇到一个分隔符之后,才能再次进入判断是否为连续4个字母开头的分支。分隔符是“空格,或非数字字母的字符”。为此定义一个宏:
#define IsNum(x) (x >= '0' && x <= '9')
#define Separator(x) (isspace(x) || (!IsNum(x) && !isalpha(x)))
并更改有穷自动机如下:
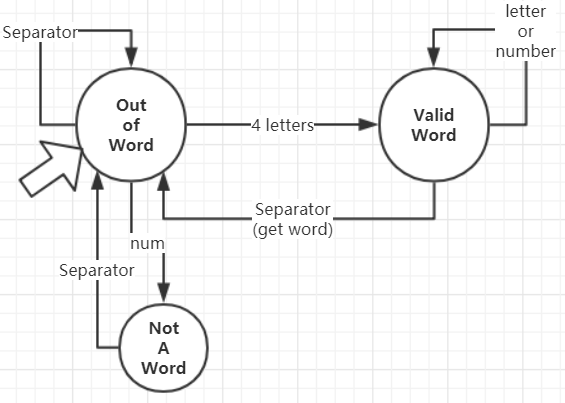
解释:如果在形成有效单词的过程中扫描到了数字,应该进入 Not A Word 状态,只有遇到分隔符才能回到初始状态。修复bug后,123file不是再合法单词,也不会被识别成合法单词file,而abc123d,file、abc123d file可以被识别成合法的单词file,因为在串abcd123d之后有分隔符(逗号或空格)。

