
福大软工1816 · 第五次作业 - 结对作业2
软工1816 · 第五次作业 - 结对作业2
我的队友:
- 博客地址A https://www.cnblogs.com/YooRarely/p/9769553.html
- 博客地址B http://www.cnblogs.com/dawnduck/p/9769715.html
- [Github链接] https://github.com/YooRarely/pair-project/tree/master/Java/031502531%26031602101
分工明细
- 分工如下
- 白晨曦:完成数据爬取与博客
- :使用C++实现其余需求功能
- 吴佳炜:使用java完成除爬虫外的编码内容
- : 补充博客
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 80 | 90 |
| · Estimate | · 估计这个任务需要多少时间 | 90 | 150 |
| Development | 开发 | 500 | 430 |
| · Analysis | · 需求分析 (包括学习新技术) | 200 | 20 |
| · Design Spec | · 生成设计文档 | 10 | 20 |
| · Design Review | · 设计复审 | 10 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 50 |
| · Design | · 具体设计 | 60 | 90 |
| · Coding | · 具体编码 | 360 | 200 |
| · Code Review | · 代码复审 | 30 | 80 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 160 |
| Reporting | 报告 | 25 | 40 |
| · Test Repor | · 测试报告 | 0 | 0 |
| · Size Measurement | · 计算工作量 | 5 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 30 |
| | 合计 |950 |1050
解题思路描述与设计实现说明
1.爬虫实现及使用
- 用python代码编写爬
利用python写出脚本,在目标网页爬取数据,最后以txt格式保存输出
#geteverydiv抓取每个论文的信息
def geteverydiv(self,source):
everydiv = re.findall('(<div class="moco-course-wrap".*?</div>)',source,re.S)
return everydiv
#getinfo从每个课程块中提取出论文标题和内容描述
def getinfo(self,eachclass):
info = {}
info['title'] = re.search('<h3>(.*?)</h3>',eachclass,re.S).group(1)
info['content'] = re.search('<p>(.*?)</p>',eachclass,re.S).group(1)
return info
最后附上主函数
if __name__ == '__main__':
classinfo = []
url = 'http://openaccess.thecvf.com/CVPR2018.py'
testspider = func()
print u'正在处理页面:' + url
html = testspider.getsource(url)
for each in everydiv:
info = testspider.getinfo(each)
classinfo.append(info)
testspider.saveinfo(classinfo)
2.代码组织与内部实现设计
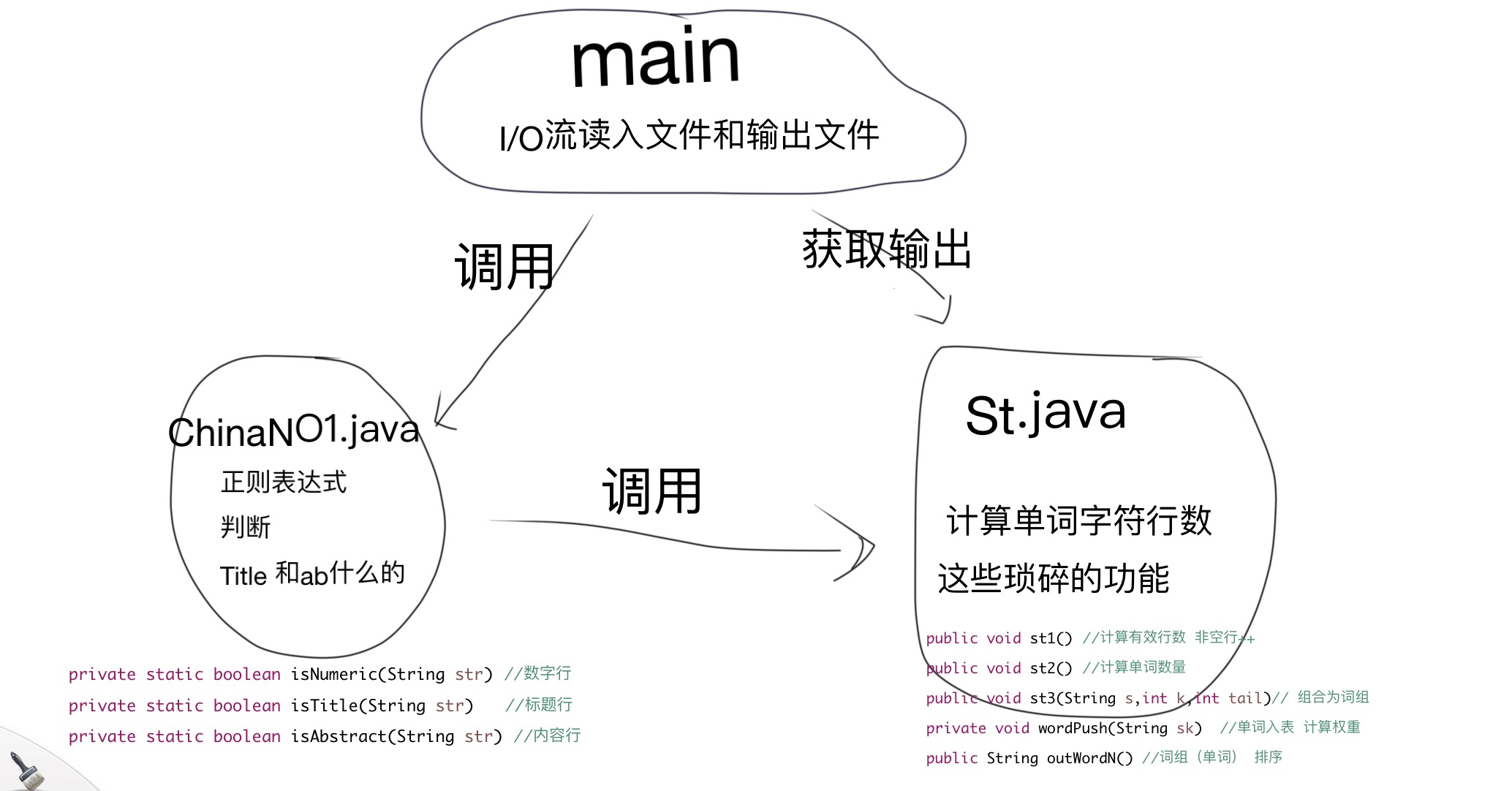
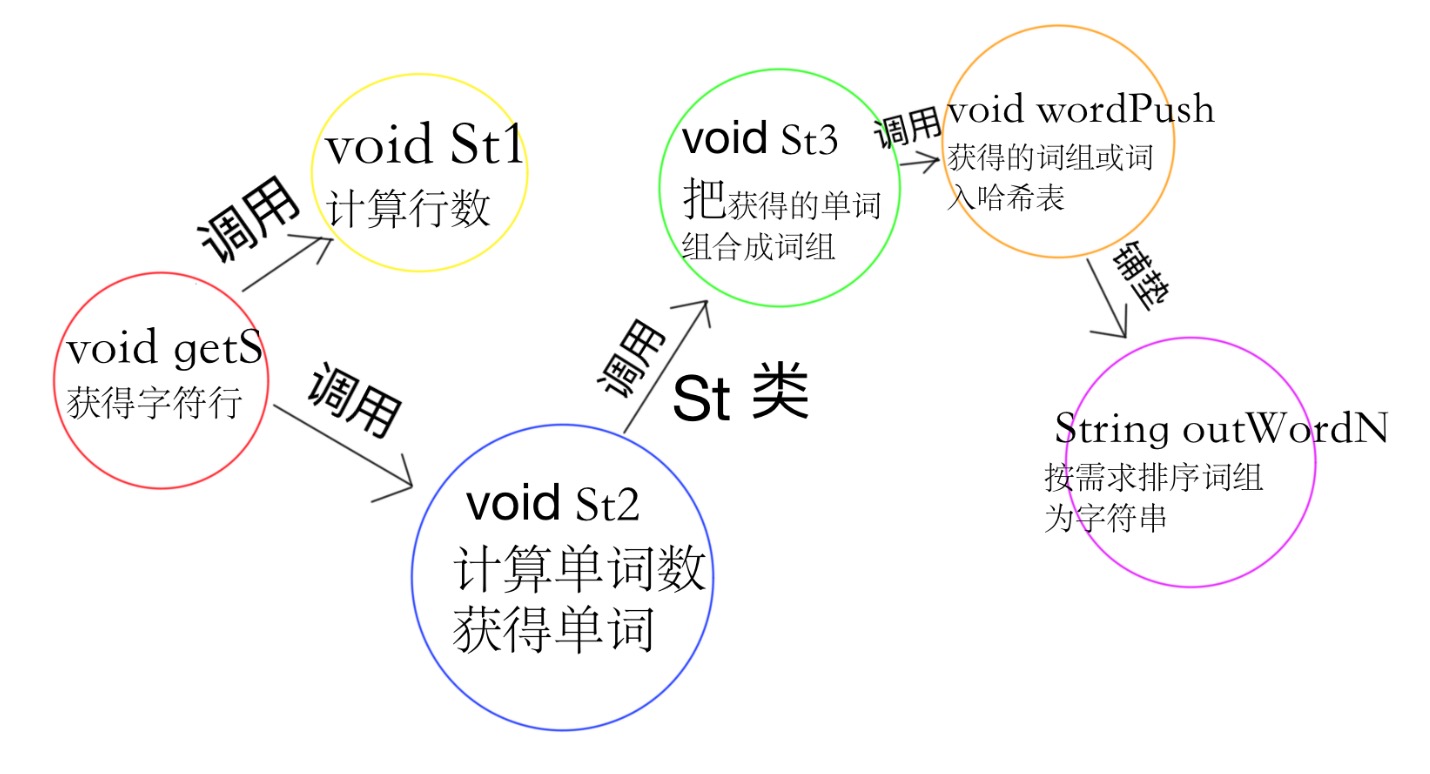
3.说明算法的关键与关键实现部分流程图
-
算法关键: 正则表达式分别出各个行
private static boolean isNumeric(String str){ //数字行
Pattern pattern = Pattern.compile("^[0-9]+?$");
return pattern.matcher(str).matches();
}
private static boolean isTitle(String str){ //标题行
Pattern pattern = Pattern.compile("^Title: .+?");
return pattern.matcher(str).matches();
}
private static boolean isAbstract(String str){ //内容行
Pattern pattern = Pattern.compile("^Abstract: .+?");
return pattern.matcher(str).matches();
}
-
St类与之前作业相差无几,详情见 前博客 :https://www.cnblogs.com/YooRarely/p/9637279.html
-
St类新增过程。
-
String s 为St2计算出来的单词,(一个),包括分隔符。
-
int k 为组成一个词组需要的长度。
-
int tail 为 分隔符长度。
-
queue {integer} Qi 为词组队列,达到词组数量则压入哈希表。先进先出。
-
public void st3(String s,int k,int tail){ // 组合为词组
if (k==0) {
kon="";
while (!Qi.isEmpty()) Qi.remove();
return;
}
Qi.offer(s.length());
if (Qi.size()>k) kon=kon.substring(Qi.remove());
kon=kon+s;
if (Qi.size()==k) wordPush(kon.substring(0, kon.length()-tail));
}
}
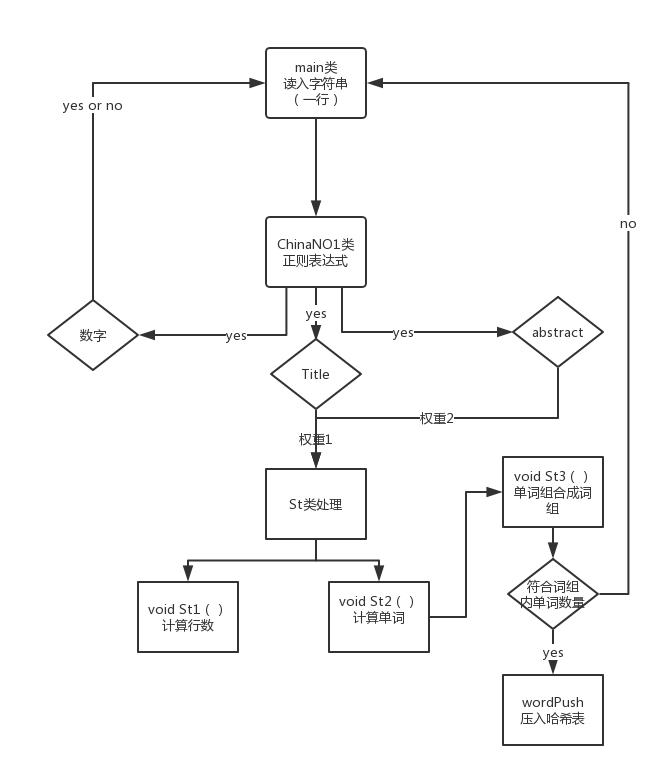
词项/单词 词频统计流程图
性能分析与改进
-
改进思路
-
我在进行词组(单词排序)的时候使用的是暴力的冒泡排序,当数量级达到百千万的时候运行速度会十分的低下。
-
可以改为更加灵活的快速排序。但是我忘记了怎么弄,嫌麻烦一直没有改。
-
其他部分代码已经尽力做到最优了,不懂怎么更优了。
-
单元测试
-
1
-
java main -i input.txt -o output.txt -m 3 -n 100 -w 1
-
对整程序进行测试,输入为爬取的数据
-
characters: 1206878
words: 120374
lines: 1958


