

基于层次关联的鲁棒多目标跟踪
基于层次关联的鲁棒多目标跟踪
读"C. Huang, B. Wu, R. Nevatia. Robust Object Tracking by Hierarchical Association of Detection Responses[J],ECCV,2008"笔记
论文方法将MOT问题转化为3层逐步细化的数据关联问题。在最底层是通过样本和样本的关联实现简单的tracklets的检测,中间层使用最大化后验概率的方法实现底层tracklets的初步拼接,最高层依据中间层的结果获得一定的先验知识使用EM算法去优化中间层检测的结果得到最终多目标的跟踪轨迹。
先定义一些量
检测响应(detection response):  ,分别表示位置,大小,时刻和表观特征,这里表观可以使用颜色直方图
,分别表示位置,大小,时刻和表观特征,这里表观可以使用颜色直方图
响应集合: 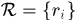
目标轨迹(object tracklet/trajectory): 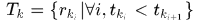 ,表示集合中元素是有序的
,表示集合中元素是有序的
不同层轨迹集合: 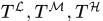
前提假设1:
所有的响应属于且仅属于一条运动轨迹,这里的轨迹包括某些单独的响应自身形成的长度为1的轨迹。
最底层关联
关键词:direct link, two-threshold strategy
首先定义响应之间相连的概率(可称为direct link概率)
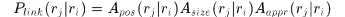
其中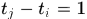 ,
,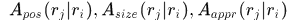 分别表示响应
分别表示响应 和
和 之间的位置、尺寸和表观相似性。
之间的位置、尺寸和表观相似性。
由前提假设,可知对于 两个时刻间任意的两个响应对
两个时刻间任意的两个响应对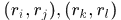 ,不可能存在
,不可能存在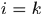 或
或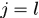 的情况。
的情况。
为了保证这一层关联的精度,要求direct link的概率要大于某一个阈值,而且要显著的高于相关的其他关联的direct link概率,即
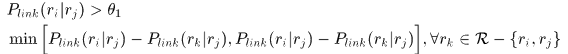
这个过程就是two-threshold strategy。
这个阶段进行关联时,由于采用了two-threshold strategy能够使关联到的点对尽可能的精确,但同时也会导致那些相对于其他相关关联(存在一个响应重合的关联)优势不明显的关联被遗漏。
下一阶段采取一定方法缓解了这种困境。
中间层关联
关键词:MAP,Hungarian algorithm, Markov Chain, Kalman Filter, RANSAC
这一阶段希望对底层关联出的tracklets进行初步的整合,形成更长的轨迹。当然这个过程是个循环的过程,每一层循环都尽可能使获得的轨迹长度更长。
用 表示获得的有tracklets组成的更长的轨迹,那么中间层获得的tracklets集合为
表示获得的有tracklets组成的更长的轨迹,那么中间层获得的tracklets集合为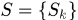 ,我们希望由
,我们希望由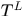 推出
推出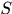 ,这可以看作是最大化后延概率问题MAP,即
,这可以看作是最大化后延概率问题MAP,即
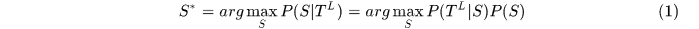
由假设1可以认为不同的 是相互独立的,现在
是相互独立的,现在
假设2.  在给定
在给定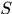 的前提下是条件独立的,那么式(1)可以写为
的前提下是条件独立的,那么式(1)可以写为
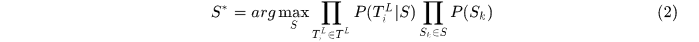
对于单独的一条轨迹可以使用Markov Chain刻画,所以

其中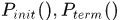 分别对应起始段和终止段的概率,中间项对应着转移概率。
分别对应起始段和终止段的概率,中间项对应着转移概率。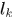 是集合的基数。
是集合的基数。
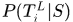 表示轨迹集合
表示轨迹集合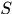 中应该有
中应该有 的概率,也就是说
的概率,也就是说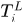 是正确检测的概率,因为正确的都应该出现在最终轨迹集合中
是正确检测的概率,因为正确的都应该出现在最终轨迹集合中
假设3. 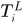 中的每一个响应服从伯努利分布。
中的每一个响应服从伯努利分布。
假设检测器的正确率为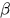 ,那么
,那么
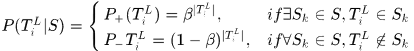
那么将(2)式写成对数形式
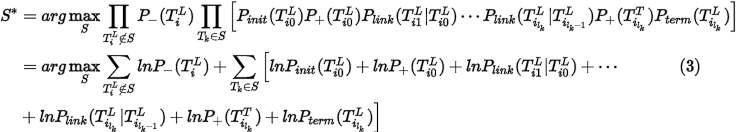
可以发现出现在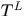 中的tracklet有两类四种可能:轨迹开始段、轨迹终止段、轨迹中间段和虚警段,其中前三种响应应该出现在
中的tracklet有两类四种可能:轨迹开始段、轨迹终止段、轨迹中间段和虚警段,其中前三种响应应该出现在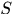 中,第四种将不会出现在
中,第四种将不会出现在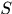 中。(或许会好奇“你说不出现就不出现了?”,但因为我们使用的的是MAP方法,所以认为
中。(或许会好奇“你说不出现就不出现了?”,但因为我们使用的的是MAP方法,所以认为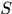 是已知的,而这种认为也就意味着可以自己确定希望的
是已知的,而这种认为也就意味着可以自己确定希望的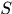 。)
。)
因此(3)式可以看做是一种计算最大目标函数的指派问题,也就可以使用Hungarian algorithm求解,系数矩阵如下:

其中n是tracklets的个数,其中元素的值如下设置

其中将虚警段设置为自关联的元素位置,当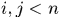 时,认为是将
时,认为是将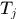 关联到
关联到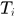 的后面,这里
的后面,这里 被分成两个0.5是因为作为中间段,既承前又启后,所以个出现一半。对于每一段轨迹只可能出现唯一一个开始段,所以在每一个开始段分配时只有一个赋值作为起始段的概率,其余的都设置为负无穷(因为这里计算的是最大问题),同样处理终止段的元素赋值。而对于
被分成两个0.5是因为作为中间段,既承前又启后,所以个出现一半。对于每一段轨迹只可能出现唯一一个开始段,所以在每一个开始段分配时只有一个赋值作为起始段的概率,其余的都设置为负无穷(因为这里计算的是最大问题),同样处理终止段的元素赋值。而对于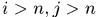 处元素没有实际意义,可以设置为0.
处元素没有实际意义,可以设置为0.
这样最终得到assignment matrix,出现在左下方区域的1元素认为对应列的tracklet可以作为起始段,出现在右上角的1元素,意味着对应行的tracklet可以作为终止段,出现在左上角块矩阵中对角位置上的1元素则认为是false alarm,左上角矩阵中其他1元素意味着轨迹的中间连接段,所在行的tracklet是关联的前一个tracklet,所在列的tracklet对应关联的后一个tracklet。
通过寻找起始段,然后逐步链接直到链接到终止段,也就找到一条更长的轨迹。
中间层的关联是一个迭代的过程,首先依据底层tracklets关联出稍长的tracklet,然后再在此基础上关联出更长的tracklet...
下面就要来看一看MAP中使用的概率都是怎么定义的。
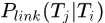
类似于底层关联使用的link概率定义方法
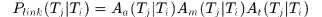
分别表示两个tracklet的表观相似性、运动相似性和时间相似性
为了使结果更加鲁棒,这里首先对tracklet进行了一些预操作,使用Kalman filter对Tracklet中响应的位置和大小,速度进行平滑和微调,使用RANSCA对Tracklet中所有的响应操作以获得一个表达能力更好的appearance color histogram.
于是
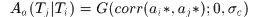
假设4. 即认为相关联的tracklet中的响应相关程度 符合
符合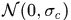 的高斯分布,
的高斯分布, 是算法参数
是算法参数
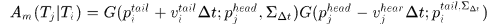
假设5. 关联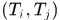 中的两个tracklet
中的两个tracklet 的起点
的起点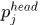 和终点
和终点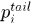 与对应预测位置
与对应预测位置 ,
,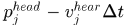 的差异应该服从方差为
的差异应该服从方差为 的高斯分布。
的高斯分布。
如下图示意

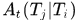 表征在定义的最大时间差内,两个tracklet中间间隔若干个未检测到目标时,他俩仍然应该关联的概率
表征在定义的最大时间差内,两个tracklet中间间隔若干个未检测到目标时,他俩仍然应该关联的概率

其中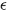 表示允许的最大时间间隔,
表示允许的最大时间间隔,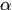 是检测器漏检的概率(检测器有漏检率,检测正确率,检测错误率)。
是检测器漏检的概率(检测器有漏检率,检测正确率,检测错误率)。
这里还有一个量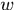 表示
表示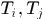 中丢失的响应中被其他目标遮挡的帧数。
中丢失的响应中被其他目标遮挡的帧数。
首先检测丢失的帧如何确定?文中使用的是对 和
和 插值得到的结果。
插值得到的结果。

其次如何确定被其他目标遮挡?参见基于人体部件小边特征的多行人检测和跟踪算法。依据近大远小的成像原理,一般认为摄像头都是俯视视角,所以响应重合时可以通过纵坐标
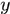 值来确定谁在最前面,一般而言,
值来确定谁在最前面,一般而言,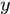 较大的认为在相对前方位置。
较大的认为在相对前方位置。最后未检测的响应中仅考虑的其他目标遮挡,那剩下的怎么办?为什么不考虑?这个问题放在了最高层解决。
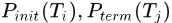
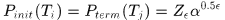
这样就可以通过匈牙利算法得到中间层的tracklets了。
最高层关联
EM算法,ground palne coordinates
最高层关联是对中间层关联的修正,在中间层计算概率时,提到过 对于未检测到的响应仅考虑了被其他目标遮挡的响应,而其余的未检测出的响应没考虑,另外对于所有的tracklets,其作为起始段和终止段的概率都相同,也是不尽合理的。所以最高层对此进行了一步EM的修正
对于未检测到的响应仅考虑了被其他目标遮挡的响应,而其余的未检测出的响应没考虑,另外对于所有的tracklets,其作为起始段和终止段的概率都相同,也是不尽合理的。所以最高层对此进行了一步EM的修正
论文中处理的是单出入口的场景,这点很重要。如果找到出入口的位置,那么根据与出入口的距离可以对不同的tracklet赋予不同的概率,越靠近入口是起始段的可能越大,越靠近出口是终止段的可能性越大。
所以论文中定义了scene structure model包括entry map、exit map和scene occluder map,即图像中像素位置是入口、出口和场景遮挡的概率。
这里因为在scene occluder map中要考虑场景的遮挡,所以要用到大地坐标,图像坐标和大地坐标之间的映射关系是通过认为标定若干对应点计算出来的。
E-step
利用中检测结果,去评估scene structure model.
假设6. 绝大多数tracklets的起始响应都应该在入口附近,即可以认为距离tracklet起点越近的位置越有可能是入口。
假设7. 同样的绝大多数tracklets的终止响应都应该在出口附近,也就是说距离tracklet终点越近的位置越有可能是出口。
于是

这里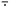 表示的是大地坐标,
表示的是大地坐标,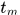 表示预测入口和出口的时间延迟间隔。
表示预测入口和出口的时间延迟间隔。
假设8. 离轨迹tracklet中间响应节点越近,是出口或者入口的可能就越小
于是
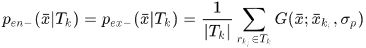
这里 对应了响应
对应了响应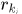 的大地坐标。
的大地坐标。
于是考虑所有的轨迹后,位置 可以作为入口和出口的概率分别为
可以作为入口和出口的概率分别为
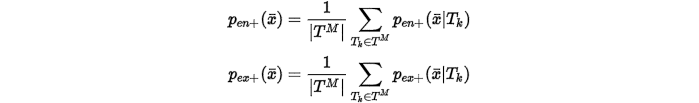
位置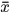 不是出口或者出口的概率分别为
不是出口或者出口的概率分别为
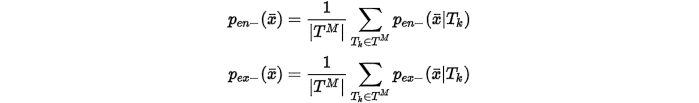
这样就可以计算得到entry map 和exit map。需要注意的是这里用到的 是完整的轨迹,也就是说是包含插值产生的虚拟响应的。
是完整的轨迹,也就是说是包含插值产生的虚拟响应的。
如何判断图像中哪些位置会给目标造成场景遮挡呢?
首先如果有遮挡,那么对应的目标肯定检测不出来,其次检测不出来的目标不一定是场景遮挡,还有可能是其他目标遮挡。
如果确定了被scene occluder的响应位置和相机的位置,那么遮挡的场景位置就极大可能出现在丢失响应的位置和相机位置之间,为什么不说一定在连线上是因为有些目标即使是部分遮挡也检测不出来,造成丢失响应。
所以 作为场景遮挡了
作为场景遮挡了 的概率可以表示为
的概率可以表示为
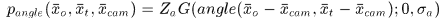
其中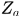 是归一化量,
是归一化量,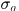 是高斯分布的方差,待输入。
是高斯分布的方差,待输入。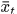 是没有检测到的且不是因为其他目标遮挡导致没检测到的插值出来的响应。
是没有检测到的且不是因为其他目标遮挡导致没检测到的插值出来的响应。

于是可以利用这些不是由于其他目标遮挡导致的未检测点来推断图像像素位置会产生场景遮挡的概率
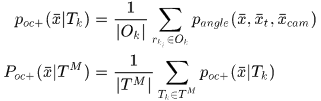
反过来,那些检测到的响应就可以提供位置点不会产生场景遮挡的可能性,于是
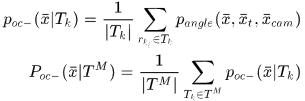
上面四个式子中的 是非其他目标遮挡却未被检测到的响应集合,
是非其他目标遮挡却未被检测到的响应集合, 是检测到的响应的集合。
是检测到的响应的集合。
这样就得到了scene occluder map
M-step
既然已经通过E-step获得scene structure model,那么就可以利用这个model去细化tracklet作为起始段、终止段的概率,而且在处理 是就可以考虑到所有的未被检测到的响应的影响了。
是就可以考虑到所有的未被检测到的响应的影响了。

其中
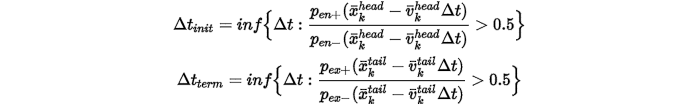
这里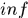 是下确界符号,我觉得文中的(22)式可能是写错了,根本没有使用到negative 概率。,通过正负概率的比值大于0.5,可以判定该点属于入口或者出口,进而断定所在的tracklet是初始段或者终止段才合理。
是下确界符号,我觉得文中的(22)式可能是写错了,根本没有使用到negative 概率。,通过正负概率的比值大于0.5,可以判定该点属于入口或者出口,进而断定所在的tracklet是初始段或者终止段才合理。
那么对于未检测到却通过插值得到的响应,可以判断属于被其他目标遮挡导致的个数,以及是由于场景遮挡到这检测失败的响应的个数,然后计算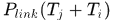 ,
,
如何判断是被场景遮挡?

即判断中间点存不存在可能导致场景遮挡的位置,如果存在,那么这个未被检测到的响应就应该是因为场景遮挡导致的。
假设被其他目标遮挡的个数为 ,被场景遮挡的个数为
,被场景遮挡的个数为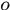 ,那么公式(4)可以重新写为
,那么公式(4)可以重新写为
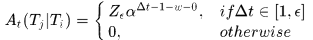
现在概率都重新确定了,就可以再次使用匈牙利算法细化结果了。
整个层次关联的步骤如下表

总结与分析
论文提出了一种处理获得多目标运动轨迹的层次递进的思想。该方法相对鲁棒也实验结果也比较理想,但是也存在着不少问题。
首先该方法中预先假设很多,分布也都是用的高斯分布刻画的,是否足够合理?
需要设定的参数也比较多,比如双阈值策略的阈值,各个高斯分布的方差,最大时间差,以及中间层迭代次数等等
方法在获取scene structure model时显然针对的是单出入口的方法,对于多个出入口,假设肯定不成立,也就不能这么评估entry map和exit map了
