
福大软工1816 · 第二次作业 - 个人项目
一.GitHub:
GitHub地址
二.PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 100 | 120 |
| · Design Spec | · 生成设计文档 | 60 | 60 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| · Design | · 具体设计 | 20 | 30 |
| · Coding | · 具体编码 | 120 | 200 |
| · Code Review | · 代码复审 | 40 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 40 | 60 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 20 | 100 |
| · Size Measurement | · 计算工作量 | 30 | 60 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 560 | 830 |
三.思路
拿到题目之后其实是懵了挺久,第一个让我头疼的是对文件的操作一无所知,只是隐隐约约记得学c语言的时候有听过,查了百度之后了解到读、写文件使用的ifstream、ofstream操作,类似输入输出流那样对文件进行读写。
对字符的统计以及对行数的统计挺好想的,对于字符的统计用while ((ch=file.get())!=EOF )逐字输入,每次读入计数,循环次数就是总字数,对于具体的要求还需要加入一些判断,对行数的统计,就是逐行读入,每次读完总数加一,具体代码如下:
int CountChar(char *filename)//统计字符数 { int sum = 0; ifstream file; file.open(filename); char ch; while ((ch=file.get())!=EOF ) { sum++; } file.close(); return sum; } int CountLines(char *filename)//统计行数 { ifstream file; file.open(filename); string s; int sum = 0; while (getline(file, s)) { if(s!="\0")//遇到空行跳过 sum++; } file.close(); return sum; }
对于剩下的处理花费了我很多时间,对于单词数的统计我本想用while(cin>>s);来逐词输入,但是忽略了分割符除了空格以外还包括非英文字母与数字的其他符号,而且还需要判断单词中不能以数字开头、前四个字母必须是英文字母这些条件,用暴力搜索来解决这个问题复杂度太高,而且代码看上去也比较冗余。
当时是希望能想到一个东西能够用来匹配单词,参考百度找到了用正则表达式来解决。

对于正则表达式我并不陌生,在上个学期的可计算理论中有学到过,很快我就能给出判断单词的正则表达式{a-zA-Z}^4{a-zA-Z0-9}*。但是对于c++中正则表达式的运用我比较陌生,需要调用regex库中的函数。
regex_search是搜索匹配,即搜索字符串中存在的符合规则的子字符串,用事先定义的正则表达式r与读入的字符串s进行匹配,匹配成功后返回true,具体的相关代码如下:
int CountWords(char *filename)//统计单词数 { ifstream file; file.open(filename); string s; int sum = 0; regex r("\\b[a-zA-Z]{4}[a-zA-Z0-9]*", regex::icase); while (file>>s) { smatch m; while (regex_search(s, m, r)) {//匹配符合正则表达式的单词 sum++; s = m.suffix().str(); } } file.close(); return sum; }
在统计词频时用到了一个STL模板map,每读到一个单词它所对应容器中的键值+1,对于不区分大小写的做法,我采用将所有的大写字母转换成小写,提取单词的方法也是使用正则表达式。
void topten(char *filename)//频率最高的十个单词 { ifstream file; file.open(filename); string s; regex r("\\b[a-zA-Z]{4}[a-zA-Z0-9]*", regex::icase); while (file>>s) { for(int i=0;i<s.size();i++) { if(s[i]<='Z'&&s[i]>='A') s[i]=s[i]+32;//干脆将所有的字母转换成小写 } smatch m; while (regex_search(s, m, r)) { M[m[0]]++; s = m.suffix().str(); } } file.close(); }
对于整体代码,我设置了四个函数接口,分别是CountChar、CountLines、CountWords、topten四个函数。
整体代码的流程图如下:

四.性能分析:
在主函数上加入for循环,重复运行main函数10000次,耗时21.719秒,耗时最大的是CountWord()函数,占比8.84%。
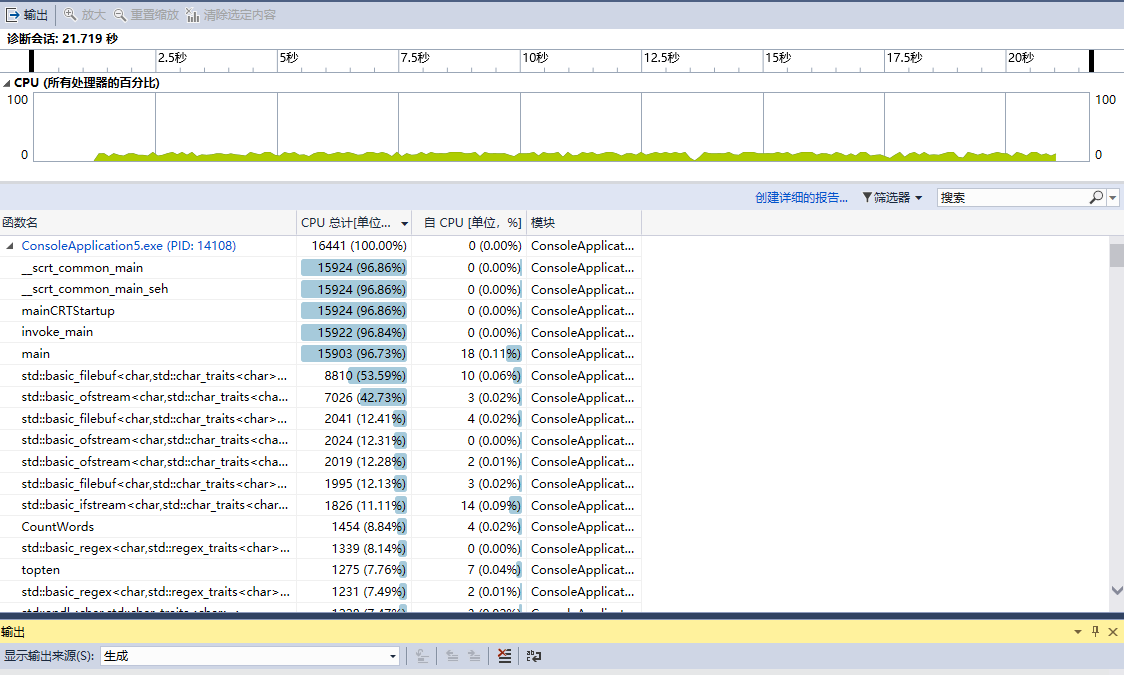
在执行10000次过程中,执行单个工作最多的函数是[ntsll.dll]占独立样本数百分比53.21。

CPU使用情况百分比如下:
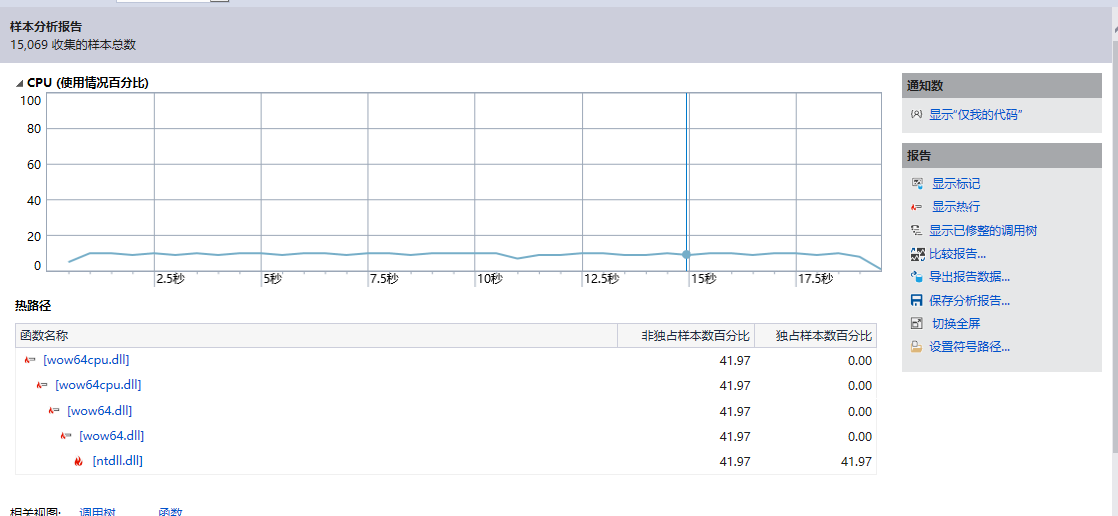
五.单元测试:
分别对字符数、行数、单词个数、词频、不区分大小写、按字典序输入以及空文件输入进行测试,分别创建不同的测试文本,测试代码如下:
namespace CountCharTest//统计字符数 { TEST_CLASS(UnitTest1) { public: TEST_METHOD(TestMethod1) { char filename[] = "CharTest.txt"; int chars = CountChar(filename); Assert::IsTrue(chars == 38); } }; } namespace CountLinesTest//统计行数 { TEST_CLASS(UnitTest1) { public: TEST_METHOD(TestMethod1) { char filename[] = "LinesTest.txt"; int lines = CountLines(filename); Assert::IsTrue(lines == 3); } }; } namespace CountWordsTest//统计单词个数 { TEST_CLASS(UnitTest1) { public: TEST_METHOD(TestMethod1) { char filename[] = "CountWordsTest.txt"; int words = CountWords(filename); Assert::IsTrue(words == 7); } }; } namespace toptenTest//按词频输出 { TEST_CLASS(UnitTest1) { public: TEST_METHOD(TestMethod1) { char filename[] = "toptenTest.txt"; topten(filename); int count = 10; vector<pair<string, int> > ans; for (auto u : M) { ans.push_back(u); } sort(ans.begin(), ans.end(), cmp); for (auto u : ans) { if (count) fileOutput << u.first << " " << u.second << endl; else break; } Assert::IsTrue((ans)->second == 5 && (ans + 1)->second == 4 && (ans + 2)->second == 3); } }; } namespace CapitalTest//大小写单词 { TEST_CLASS(UnitTest1) { public: TEST_METHOD(TestMethod1) { char filename[] = "CapitalTest.txt"; int words = CountWords(filename); vector<pair<string, int>> v; CountAndSort(f, v); vector<pair<string, int>>::iterator vec = v.begin(); Assert::IsTrue((vec)->first == "aaaa" &&words == 3); } }; } namespace SortCountTest//综合排序 { TEST_CLASS(UnitTest1) { public: TEST_METHOD(TestMethod1) { char filename[] = "SortCountTest.txt"; topten(filename); vector<pair<string, int> > ans; for (auto u : M) { ans.push_back(u); } sort(ans.begin(), ans.end(), cmp); for (auto u : ans) { if (count) fileOutput << u.first << " " << u.second << endl; else break; } Assert::IsTrue((ans)->first == "aaaa" && (ans + 1)->first == "bbbb" && (ans + 2)->first == "bbbb1"); } }; } namespace EmptyFile//空文件 { TEST_CLASS(UnitTest1) { public: TEST_METHOD(TestMethod1) { char filename[] = "EmptyFile.txt"; int chars = CountChar(filename); int lines = CountLines(filename); int words = CountWords(filename); Assert::IsTrue(chars == 0 && lines == 0 && words == 0); } }; }
六.异常分析:
在统计字符个数时一开始用while(getline(cin,s))读入字符串,忽略了换行符也算一个字符,之后想设置一个计数的变量k,每读入一次加一,最后返回sum+k-1,但是如果遇到空文本就会出现字符数为-1的情况。
异常代码如下:
//异常代码 int CountChar(char *filename)//统计字符数 { int sum=0,k = 0; ifstream file; file.open(filename); string s; while (getline(cin,s) ) { sum+=s.length(); l++; } file.close(); return sum+k-1; }
七.感悟:
第一次实践就花费了我相当多的时间,好在开学初没有考试压力,可以尽情的花时间在研究和学习代码上。这次作业涉及太多我的知识盲区,发布作业的博客也是看得一头雾水,很多新东西都要现学,不过确实可以学到很多东西。有些东西不自己去百度、去找书,可能大学四年都不会在课上学到。
对于接下来的结对和团队任务,只希望队友不要嫌弃我太菜了。

