

SimpleDB解析之Log篇
Log包中包含三个类,依次是BasicLogRecord,LogIterator,LogMgr
BasicLogRecord 提供的是一种基础的日志记录。含有的成员对象是Page和Pos,它所完成的功能就是定位Page,定位Offset,然后提供读写记录的方法。
LogMgr,底层的日志管理器,只是负责日志记录的读写,它自己并不知道所写的日志的记录的内容是什么。所谓较高级的日志管理器是指恢复管理器,它可以明确的知道所写的日志记录的内容。
LogIterator,日志迭代器,提供关于遍历日志文件的方法,比如hasNext(),next(),moveToNextBlock()。
在Log包中最核心的东西是日志的记录方式。日志在记录的时候是从前往后记录的,但是在读的时候却是以相反的方向进行的。在作者所维护的这种机制下,能够实现这种功能的秘密在于它独特的日志记录的方式。

上面的就是在Log文件中所具有的记录的格式。
它是什么意思呢?
首先,在初始化的时候,在每个Block的开头都先写入一个LAST_POS值为0。然后,就开始写入日志记录。关键的部分是在写完日志之后。在写完每条日志之后,会加上一个便宜量,这个偏移量用来记录前一条记录的offset。
在详细介绍这个offset之前,需要看几行代码:(用以添加记录)
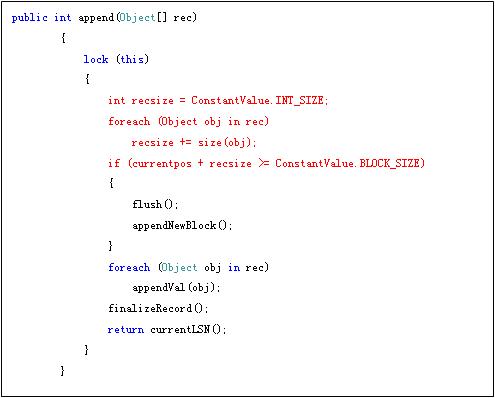
根据上面的代码,可以看出,这里的“记录”是记录内容和offset的结合体,在计算空间的时候,会自动加上在记录结尾offset所需要的空间。
在写完一条记录值之后,currentpos的值是真正记录结束后的便宜,不包含前一条记录的offset。
利用finalizeRecord来设置offset。
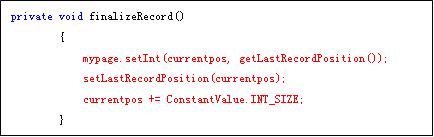
以上的三条语句:
1> 把LAST_POS的值卸载记录的后面,实际上就是给offset赋值
2> 把currentpos赋值给LAST_POS
3> 给currentpos加上4,跳过offset
通过以上的介绍,很容易明白记录offset的过程,下面,再看下LogeIterator中的next(),我们从读记录的角度,理解下这种记录方式。
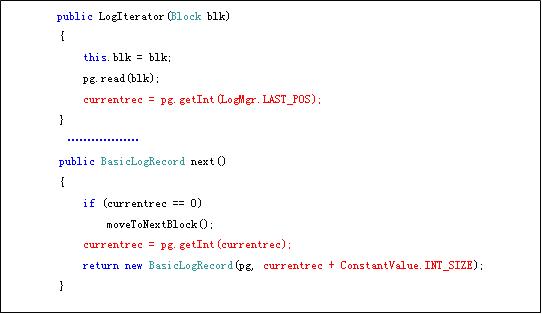
在读记录的时候,首先,定位currenrec,这里是读取LAST_POS,这样,就从头直接到了Block的尾部了,此时currenrec的值是最后一条记录的offset的pos;然后利用一句“currentrec = pg.getInt(LogMgr.LAST_POS);”,得到的是倒数第二条记录的offset,在这个情况下,实际上已经从最后一条移动到倒数第二条,这样就是REVERSE了,在获取记录值得时候,“currentrec + ConstantValue.INT_SIZE”,就定位到了最后一条记录的位置了,读取完成。
现在看来,实际上,早这个所谓的REVERSE机制中,所用的与原理就是“C++中链表的后向插入”,自然能够REVERSE读取了。LogRecord记录相当于链表的DataElem而已。只是,由于Java中没有指针,这里是利用偏移来是虚拟指针罢了。

