Python3爬虫(2)_利用urllib.urlopen发送数据获得反馈信息
一、urlopen的url参数 Agent
url不仅可以是一个字符串,例如:https://baike.baidu.com/。url也可以是一个Request对象,这就需要我们先定义一个Request对象,然后将这个Request对象作为urlopen的参数使用,
代码:
1 from urllib import request 2 3 if __name__ == "__main__": 4 req = request.Request("https://baike.baidu.com//") 5 response = request.urlopen(req) 6 html = response.read() 7 html = html.decode("utf-8") 8 print(html)
运行之后,结果就不做展示了。
urlopen()返回的对象,可以使用read()进行读取,同样也可以使用geturl()方法、info()方法、getcode()方法。
-
geturl()返回的是一个url的字符串;
-
info()返回的是一些meta标记的元信息,包括一些服务器的信息;
-
getcode()返回的是HTTP的状态码,如果返回200表示请求成功。
下面更新代码,进行下面的测试:
from urllib import request if __name__=="__main__": re=request.Request("http://baike.baidu.com") response=request.urlopen(re) print("geturl打印信息:%s"%(response.geturl())) print('**********************************************') print("info打印信息:%s"%(response.info())) print('**********************************************') print("getcode打印信息:%s"%(response.getcode()))

二、urlopen的data参数
我们可以使用data参数,向服务器发送数据。根据HTTP规范,GET用于信息获取,POST是向服务器提交数据的一种请求,再换句话说:
从客户端向服务器提交数据使用POST;
从服务器获得数据到客户端使用GET(GET也可以提交,暂不考虑)。
如果没有设置urlopen()函数的data参数,HTTP请求采用GET方式,也就是我们从服务器获取信息,如果我们设置data参数,HTTP请求采用POST方式,也就是我们向服务器传递数据。
data参数有自己的格式,它是一个基于application/x-www.form-urlencoded的格式,具体格式我们不用了解, 因为我们可以使用urllib.parse.urlencode()函数将字符串自动转换成上面所说的格式。
三、发送data实例
遇到一些问题,我也暂时使用有道翻译,以后有好的方法更新这部分关于百度百科的爬取。
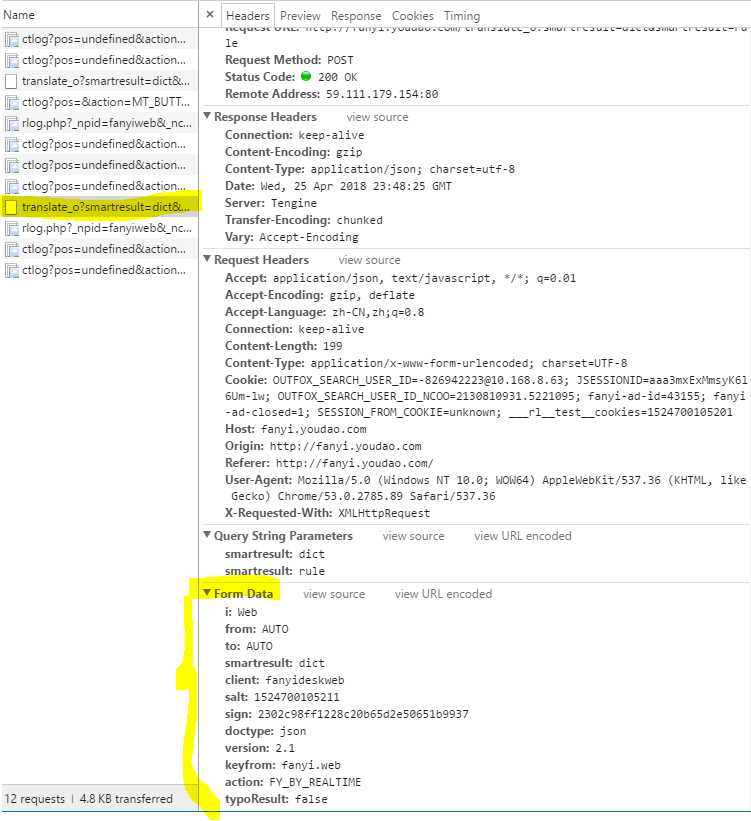
向有道翻译发送数据,得到网页反馈:
1.打开界面
2.鼠标右键检查元素
3.选择网络/network
4.在搜索输入框 输入查找内容,“network”界面出现了大量内容。
5.得到下方内容:
编写新程序:
from urllib import request from urllib import parse import json if __name__ == "__main__": Request_URL = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule' Form_Data = {} Form_Data['i'] = 'Web' Form_Data['from'] = 'AUTO' Form_Data['to'] = 'AUTO' Form_Data['smartresult'] = 'dict' Form_Data['client'] = 'fanyideskweb' Form_Data['salt'] = '1524700622507' Form_Data['sign'] = 'c8c86253bcfb23d8405ab58cc0d2b5fa' Form_Data['doctype'] = 'json' Form_Data['xmlVersion'] = '2.1' Form_Data['keyfrom'] = 'fanyi.web' Form_Data['action'] = 'FY_BY_CLICKBUTTON' data = parse.urlencode(Form_Data).encode('utf-8') response = request.urlopen(Request_URL,data) html = response.read().decode('utf-8') translate_results = json.loads(html) translate_results = translate_results['translateResult'][0][0]['tgt'] print("翻译的结果是:%s" % translate_results)
报错:
RESTART: C:\Users\DELL\AppData\Local\Programs\Python\Python36\urllib_test01.py
Traceback (most recent call last):
File "C:\Users\DELL\AppData\Local\Programs\Python\Python36\urllib_test01.py", line 23, in <module>
translate_results = translate_results['translateResult'][0][0]['tgt']
KeyError: 'translateResult'
这是因为data['salt']是时间戳,data['sign']是时间戳和翻译内容加密后生成的,因为不知道网站的加密方法,
在这里选择调整uri和data,并根据http://bbs.fishc.com/thread-98973-1-1.html这里的帖子做出调整:
import os,urllib.request import urllib.parse import json a = 5 while a > 0: txt = input('输入要翻译的内容:') if txt == '0': break else: url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&sessionFrom=https://www.baidu.com/link' data = { 'from':'AUTO', 'to':'AUTO', 'smartresult':'dict', 'client':'fanyideskweb', 'salt':'1524700622507', 'sign':'c8c86253bcfb23d8405ab58cc0d2b5fa', 'doctype':'json', 'version':'2.1', 'keyfrom':'fanyi.web', 'action':'FY_BY_CL1CKBUTTON', 'typoResult':'false'} data['i'] = 'Web' data = urllib.parse.urlencode(data).encode('utf - 8') wy = urllib.request.urlopen(url,data) html = wy.read().decode('utf - 8') print(html) ta = json.loads(html) print('翻译结果: %s '% (ta['translateResult'][0][0]['tgt'])) a = a - 1
结果为:

JSON是一种轻量级的数据交换格式,我们需要在爬取到的内容中找到JSON格式的数据,再将得到的JSON格式的翻译结果进行解析。
总而言之,这部分的内容我终于结束了,debug太耗费时间了!

