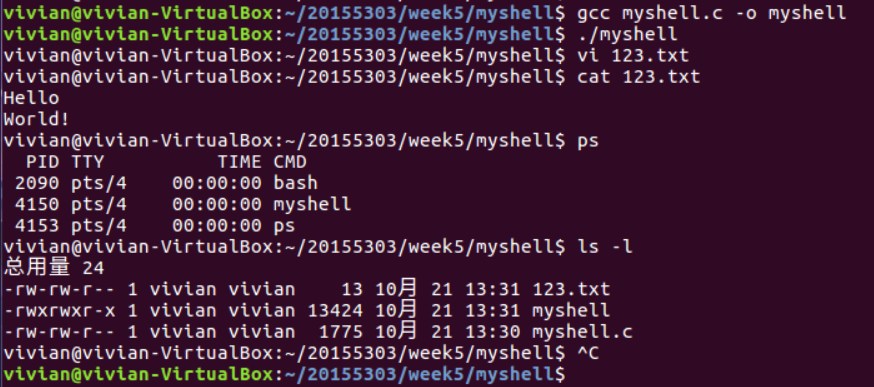
进程与fork()、wait()、exec函数组
进程与fork()、wait()、exec函数组
内容简介:本文将引入进程的基本概念;着重学习exec函数组、fork()、wait()的用法;最后,我们将基于以上知识编写Linux shell作为练习。
————————CONTENTS————————
进程与程序
Unix是如何运行程序的呢?这看起来很容易:首先登录,然后shell打印提示符,输入命令并按回车键,程序就开始运行了。当程序结束后,shell会打印一个新的提示符。但是,这些是如何实现的呢?shell在这段时间里做了什么呢?
首先,我们来引入“进程”的概念。
一、进程
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。
即使在系统中通常有许多其他的程序在运行,但进程也可以向每个程序提供一种假象,仿佛它在独占地使用处理器。但事实上进程是轮流使用处理器的。我们假设一个运行着三个进程的系统,如下图所示:
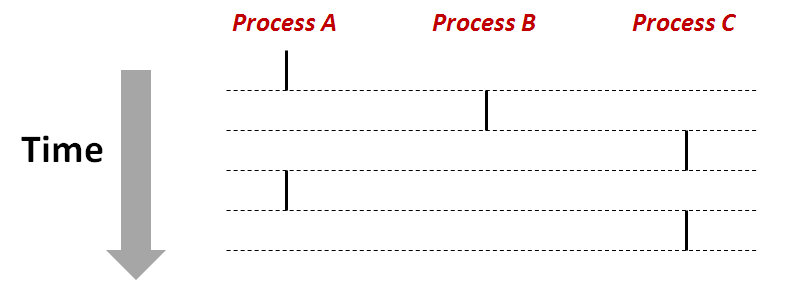
三个进程的执行是交错的。进程A运行一段时间后,B开始运行直到完成。然后进程C运行了一会儿,进程A接着运行直到完成。最后,进程C也运行结束了。
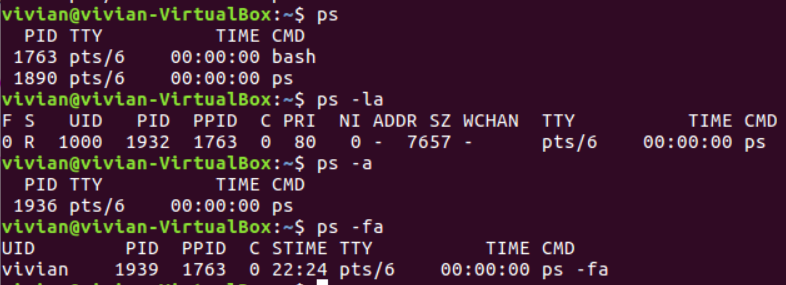
通过ps命令与一些参数的组合,可以查看当前状态下的所有进程:
二、上下文切换
内核为每个进程维持一个上下文(context)。上下文就是内核重新启动一个被强占的进程所需的状态。
当内核代表用户执行系统调用时,可能会发生上下文切换。如果系统调用因为等待某个事件而发生阻塞,那么内核可以让当前进程休眠,切换到另一个进程。
下图展示了一对进程A和B之间上下文切换的实例:
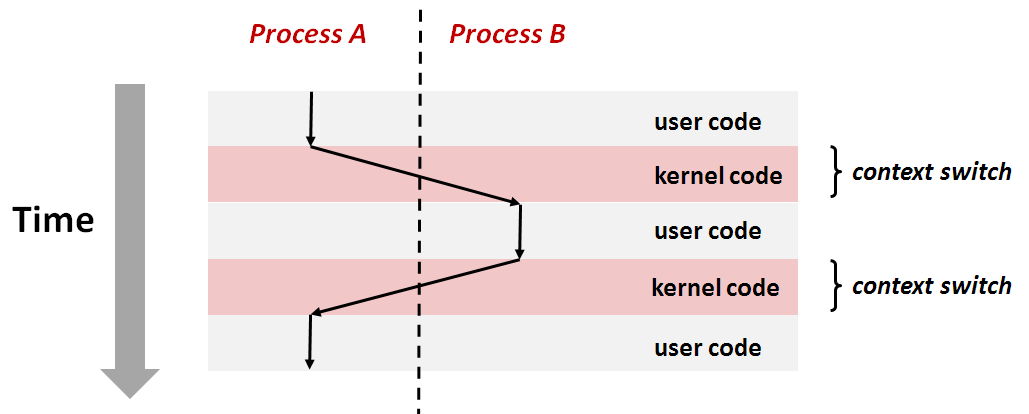
在这个例子中,进程A初始运行在用户模式中,直到它通过执行系统调用陷入到内核,在内核模式下执行指令。然后在某一时刻,它开始代表进程B(仍然是内核模式下)执行指令。在切换之后,内核代表进程B在用户模式下执行指令。随后,进程B在用户模式下执行了一会儿,内核判定进程B已经运行了足够长的时间,就执行一个从进程B到进程A的上下文切换,将控制返回给进程A中紧随在刚刚系统调用之后的那条指令。进程A继续运行,直到下一次异常发生。
exec函数组
那么问题来了:一个程序如何运行另一个程序呢?
首先我们得搞清楚需要调用什么函数来完成这个过程。如果想使用man -k xxx这个命令进行搜索,必须知道相应的关键字。思考一下,我们想到了process(进程)、execute(执行)、program(程序)等等
我们可以尝试man -k program | grep execute | grep process命令,但发现没有搜到任何相关的内容。扩大搜索范围,我们再试试man -k program | grep execute,这下找到了不少内容:
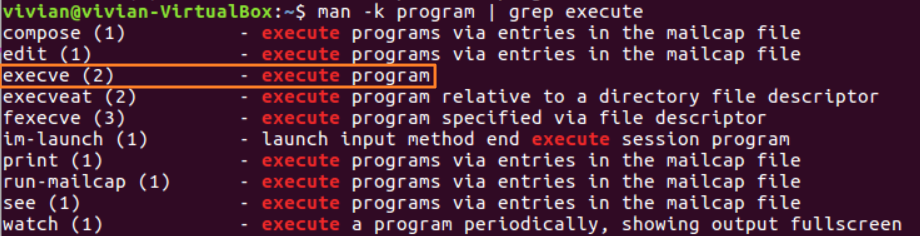
“execve(2) -execute program”这个解释似乎是我们想要的,再进一步使用man -k execute搜索,通过观察说明,我们找到了一系列相关的函数:
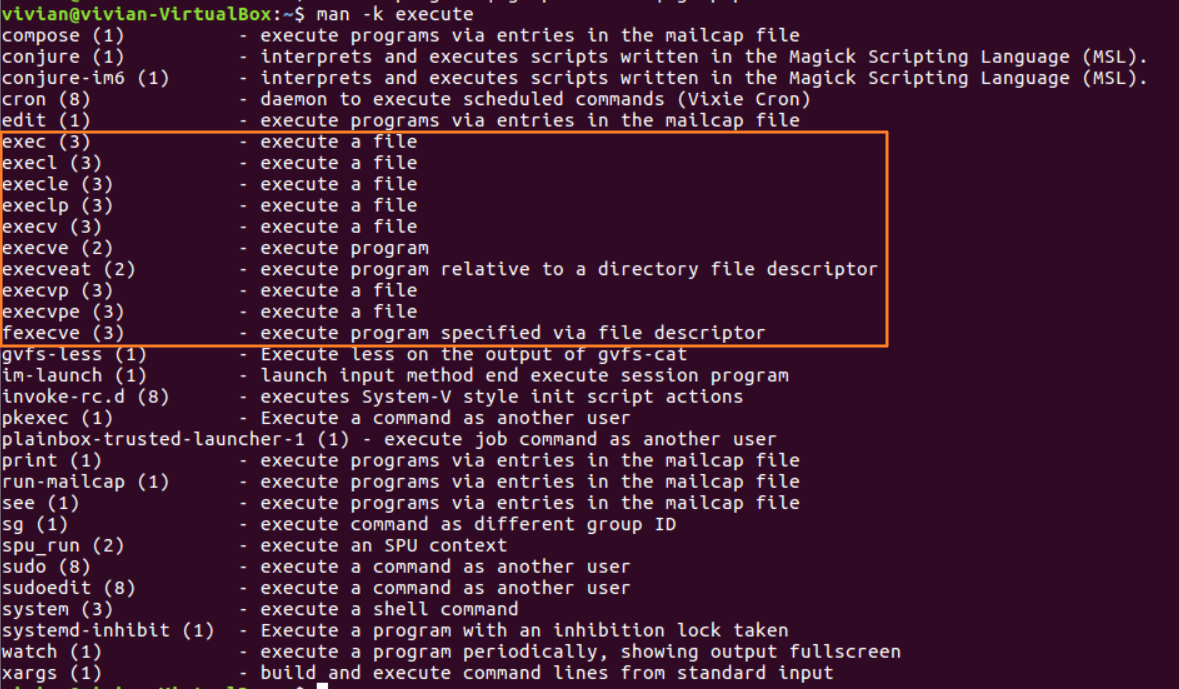
这些函数均以“exec”开头,exec是一组函数的总称,我们可以通过man -k exec来寻找相关信息:
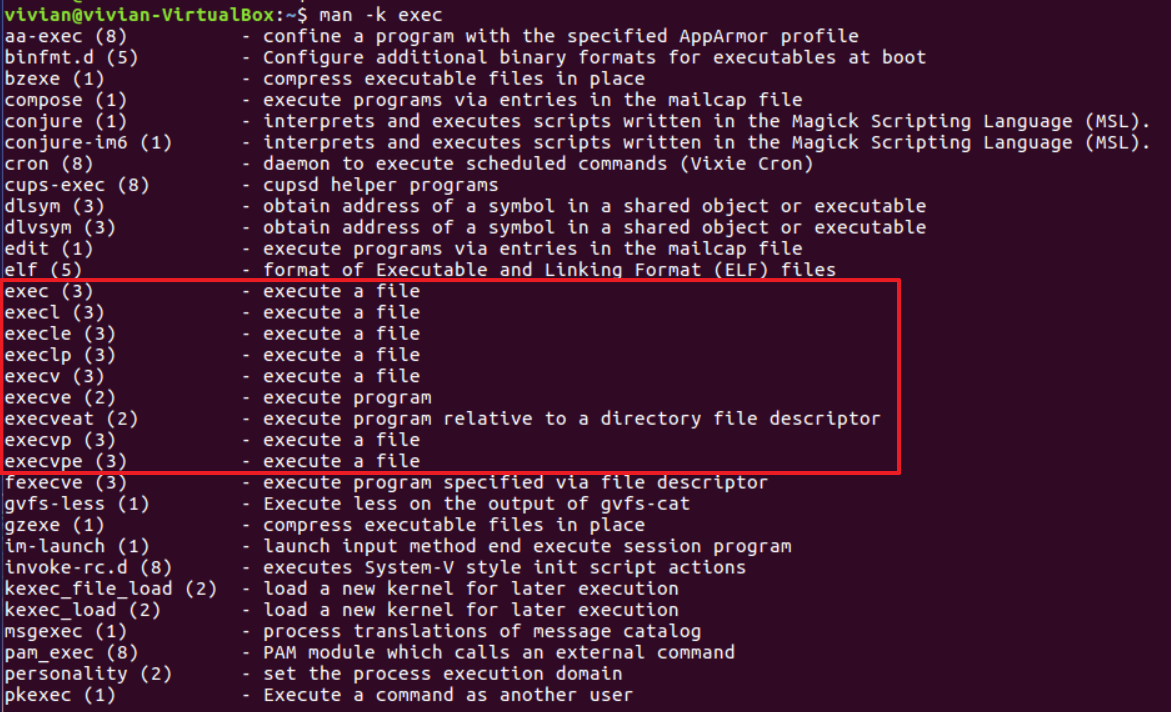
通过描述,我们大概找到了符合要求的几个函数。
查阅资料了解到,exec系列函数共有7个函数可供使用,这些函数的区别在于:指示新程序的位置是使用路径还是文件名,如果是使用文件名,则在系统的PATH环境变量所描述的路径中搜索该程序;在使用参数时使用参数列表的方式还是使用argv[]数组的方式。
如果想了解关于exec函数组的详细信息,可以通过man 3 exec查看:
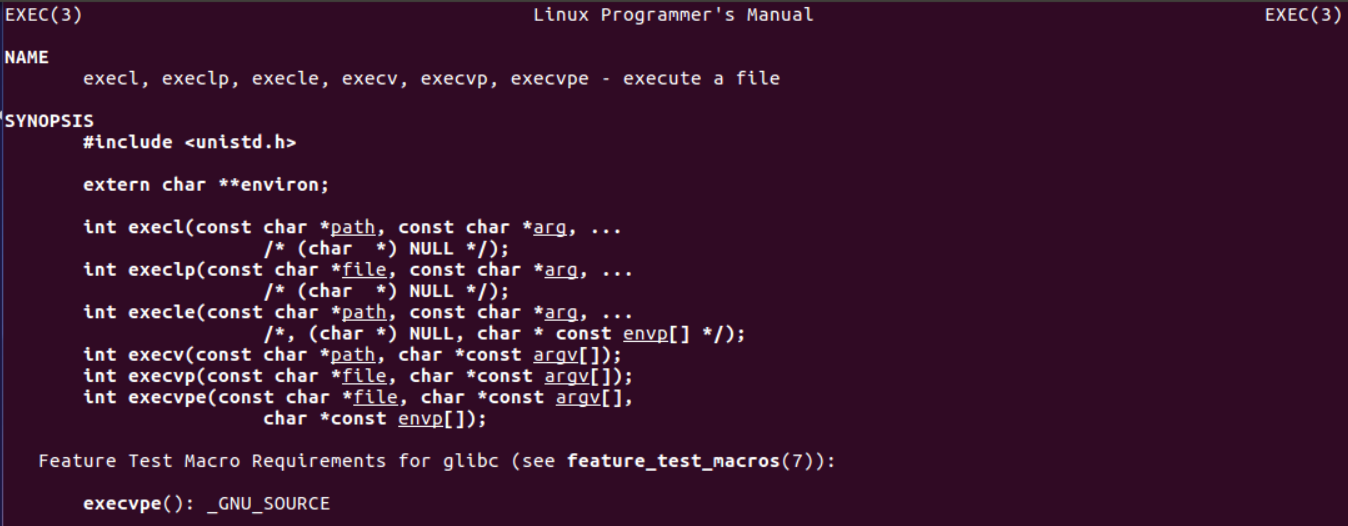
函数组可简要表示为:
#include <unistd.h>
int execl(const char *pathname, const char *arg0, ... /* (char *)0 */ );
int execv(const char *pathname, char *const argv[]);
int execle(const char *pathname, const char *arg0, .../* (char *)0, char *const envp[] */ );
int execve(const char *pathename, char *const argv[], char *const envp[]);
int execlp(const char *filename, const char *arg0, ... /* (char *)0 */ );
int execvp(const char *filename, char *const argv[]);
int fexecve(int fd, char *const argv[], char *const envp[]);
//返回:如果执行成功将不返回,否则返回-1,失败代码存储在errno中。
//前4个函数取路径名作为参数,后两个是取文件名作为参数,最后一个是以一个文件描述符作为参数。
可以见到这些函数名字不同, 而且他们用于接受的参数也不同。
实际上他们的功能都是差不多的, 因为要用于接受不同的参数所以要用不同的名字区分它们(类似于Java中的函数重载)。
但是实际上它们的命名是有规律的:
exec[l or v][p][e]
exec函数里的参数可以分成3个部分:执行文件部分,命令参数部分,和环境变量部分。
假如要执行:ls -l /etc
- 执行文件部分就是:"/usr/bin/ls"
- 命令参数部分就是:"ls","-l","/etc",NULL
- 环境变量部分:这是1个数组,最后的元素必须是NULL 例如:char * env[] = {"PATH=/etc", "USER=vivian", "STATUS=testing", NULL};
命名规则如下:
-
e:参数必须带环境变量部分,环境变量部分参数会成为执行exec函数期间的环境变量;
-
l:命令参数部分必须以"," 相隔, 最后1个命令参数必须是NULL;
-
v:命令参数部分必须是1个以NULL结尾的字符串指针数组的头部指针。例如char * pstr就是1个字符串的指针, char * pstr[] 就是数组了, 分别指向各个字符串;
-
p:执行文件部分可以不带路径, exec函数会在$PATH中找。
下面我们将以ls -l为例,详细介绍这几个函数:
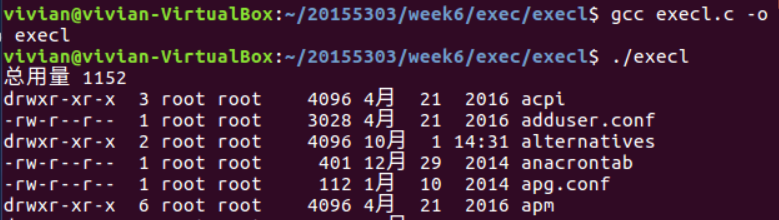
1、execl()
int execl(const char *pathname, const char *arg0, ... /* (char *)0 *\);
- execl()函数用来执行参数path字符串所指向的程序,第二个及以后的参数代表执行文件时传递的参数列表,最后一个参数必须是空指针以标志参数列表为空.
程序如下:
#include <unistd.h>
int main()
{
execl("/bin/ls","ls","-l","/etc",(char *)0);
return 0;
}
运行结果如下:
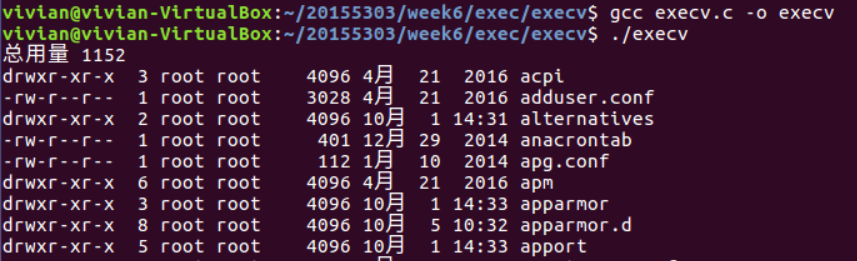
2、execv()
int execv(const char *path, char *const argv[]);
- execv()函数函数用来执行参数path字符串所指向的程序,第二个为数组指针维护的程序参数列表,该数组的最后一个成员必须是空指针。
程序如下:
#include <unistd.h>
int main()
{
char *argv[] = {"ls", "-l", "/etc"/*,(char *)0*/};
execv("/bin/ls", argv);
return 0;
}
运行结果如下:
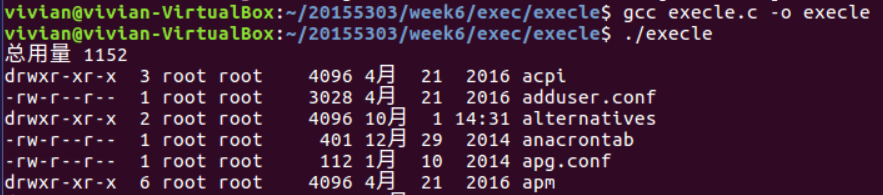
3、execle()
int execle(const char *pathname, const char *arg0, .../* (char *)0, char *const envp[] */ );
- execle()函数用来执行参数path字符串所指向的程序,第二个及以后的参数代表执行文件时传递的参数列表,最后一个参数必须指向一个新的环境变量数组,即新执行程序的环境变量。
程序如下:
#include <unistd.h>
int main(int argc, char *argv[], char *env[])
{
execle("/bin/ls","ls","-l","/etc",(char *)0,env);
return 0;
}
运行结果如下:
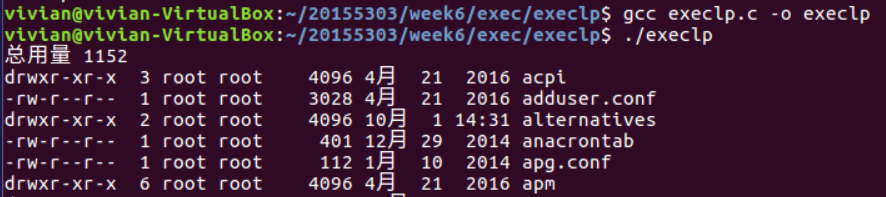
4、execlp()
int execlp(const char *filename, const char *arg0, ... /* (char *)0 */ );
- execlp()函数会从PATH环境变量所指的目录中查找文件名为第一个参数指示的字符串,找到后执行该文件,第二个及以后的参数代表执行文件时传递的参数列表,最后一个参数必须是空指针.
程序如下:
#include <unistd.h>
int main()
{
execlp("ls", "ls", "-l", "/etc", (char *)0);
return 0;
}
运行结果:
5、execvp()
int execvp(const char *file, char *const argv[]);
- execvp()函数会从PATH环境变量所指的目录中查找文件名为第一个参数指示的字符串,找到后执行该文件,第二个及以后的参数代表执行文件时传递的参数列表,最后一个成员必须是空指针。
程序如下:
#include <unistd.h>
int main()
{
char *argv[] = {"ls", "-l", "/etc", /*(char *)0*/};
execvp("ls", argv);
return 0;
}
运行结果如下:
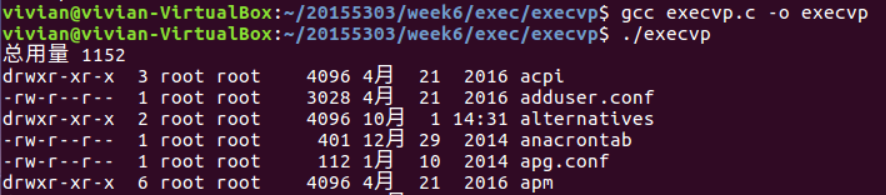
6、argv[0]的值对程序运行的影响
以上我们以ls -l示范了exec函数组的使用。如何实现对其他命令的调用呢?很简单,我们只需要修改argv[0]的值。比如:
#include <unistd.h>
int main()
{
char *argv[] = {"who",(char *)0};
execvp("who", argv);
return 0;
}
运行结果为:

7、总结
我们再来看这样一个使用到“execvp()”函数的程序:
#include <unistd.h>
int main()
{
char *argv[] = {"ls", "-l", ".", (char *)0};
printf("*** Begin to Show ls -l\n");
execvp("ls", argv);
printf("ls -l is done! ***");
return 0;
}
运行程序:

竟然只有第一行printf的输出!!execvp后面的那一条printf打印的消息哪里去了???
原因在于:一个程序在一个程序中运行时,内核将新程序载入到当前进程,替代当前进程的代码和数据。如果执行成功,execvp没有返回值。当前程序从进程中清除,新的程序在当前进程中运行。
这使我们联想到“庄周梦蝶”的故事。庄子在梦中化作了蝴蝶,虽然身体是蝴蝶的身体,但思想已换做庄子的思想,蝴蝶的思想已被完全覆盖了。类比execv函数组,系统调用从当前进程中把当前程序的机器指令清除,然后在空的进程中载入调用时指定的程序代码,最后运行这个新的程序。exec调整进程的内存分配使之适应新的程序对内存的要求。相同的进程,不同的内容。
fork()
那么问题来了:如果execvp用命令指定的程序代码覆盖了shell的程序代码,然后在命令指定的程序结束之后退出。这样shell就不能再次接受新的命令。那shell如何能做到运行程序的同时还能等待下一个命令呢?
我们设想,如果能创建一个完全相同的新进程就好了,这样就可以在新进程里执行命令程序,且不影响原进程了。
寻找关键词:process(进程)、create(创建)、new(新的)......
使用man -k xxx | grep xxx命令,我们最终找到了这样一个函数:
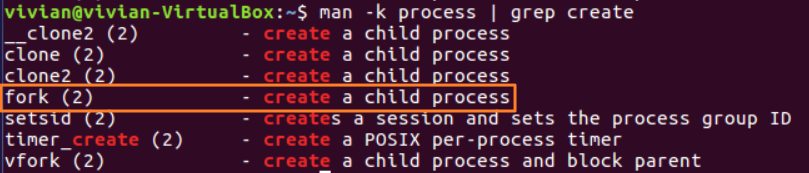
(注:Unix标准的复制进程的系统调用时fork(即分叉),但是Linux,BSD等操作系统并不止实现这一个,确切的说linux实现了三个:fork,vfork,clone。在这里我们重点讲解fork的使用。)
如何知道更多关于fork函数的细节?参考娄老师的别出心裁的Linux系统调用学习法这篇博客,我们可以通过man -k fork命令进行搜索,可以看到,fork函数位于manpages的第二节,与系统调用有关。

使用man 2 fork命令查看fork函数,可以看到关于fork函数的所有信息:
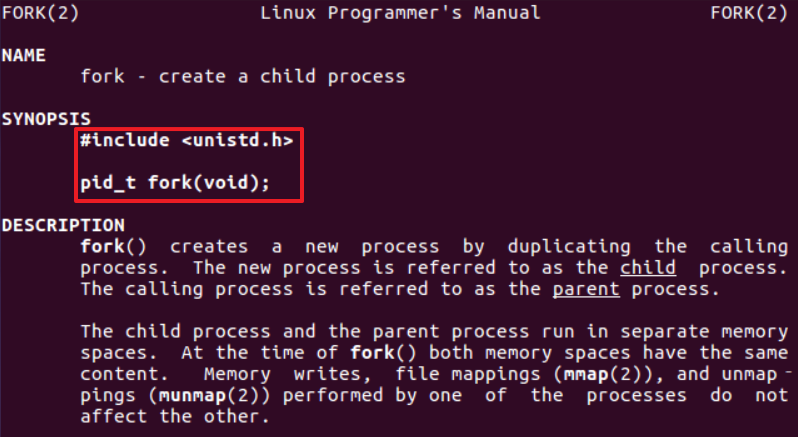
大致将fork()可以总结为:
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
//返回:子进程返回0,父进程返回子进程的PID,如果出错,则返回-1。
一般来说,运行一个C程序直到该程序全部结束,系统只会分配一个PID给这个程序,也就是说,系统里只有一条关于这个程序的进程。但执行了fork函数就不同了。fork()的作用是复制当前进程(包括进程在内存的堆栈数据),然后这个新的进程和旧的进程一起执行下去。而且这两个进程是互不影响的。
例如:调用一次fork()之后的进程如下:

以下面这个程序为例:
int main(){
printf("it's the main process step 1!!\n\n");
fork();//创建一个新的进程
printf("step2 after fork() !!\n\n");
int i; scanf("%d",&i);//防止程序退出
return 0;
}
运行结果为:

根据上面调用fork()的示意图不难理解,程序在fork()函数之前只有一条主进程,所以只打印一次step 1;而执行fork()函数之后,程序分为了两个进程,一个是原来的主进程,另一个是fork()的新进程,他们都会执行fork()函数之后的代码,所以step 2打印了两次。
此时使用ps -ef | grep fork4命令查看系统的进程,可以发现两条名字相同的进程:

可以看到,4732那个为父进程,4733为子进程(因为由图可知4733的父进程为4732)。
wait()
考虑下面这个程序:
void fork2()
{
printf("L0 ");
fork();
printf("L1 ");
fork();
printf("Bye ");
}
程序执行情况的示意图为:
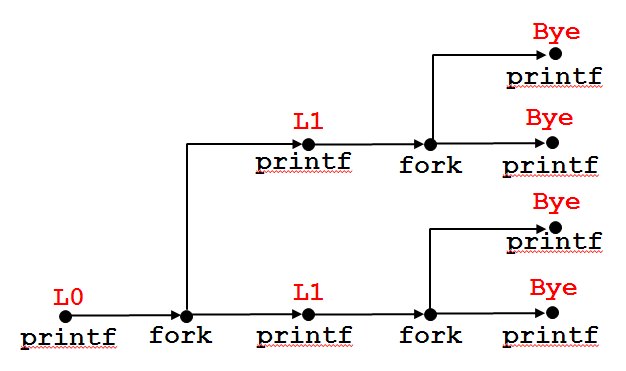
进程图可以帮助我们看清这个程序运行了四个进程,每个都调用了一次printf("Bye "),这些printf可以以任意顺序执行。“L0 L1 Bye Bye L1 Bye Bye ”为一种可能的输出,而“L0 Bye L1 Bye L1 Bye Bye ”这种情况就不可能出现。
通过分析上面的进程图,我们可以发现:一旦子进程建立,父进程与子进程的执行顺序并不固定。这种不确定性有时并不是我们想要的。那么,如何调用一个函数,使得父进程等待子进程结束后,再继续执行呢?
关键词:wait(等待)、process(进程)......
使用man -k xxx | grep xxx命令,按照关键词进行搜索:

我们了解到,一个进程可以通过调用wait函数来等待它的子进程终止或者停止。
同样地,我们使用man -k wait查看与“wait”相关的信息,从它们的功能说明可以看到,最后几个函数似乎是我们想要的。
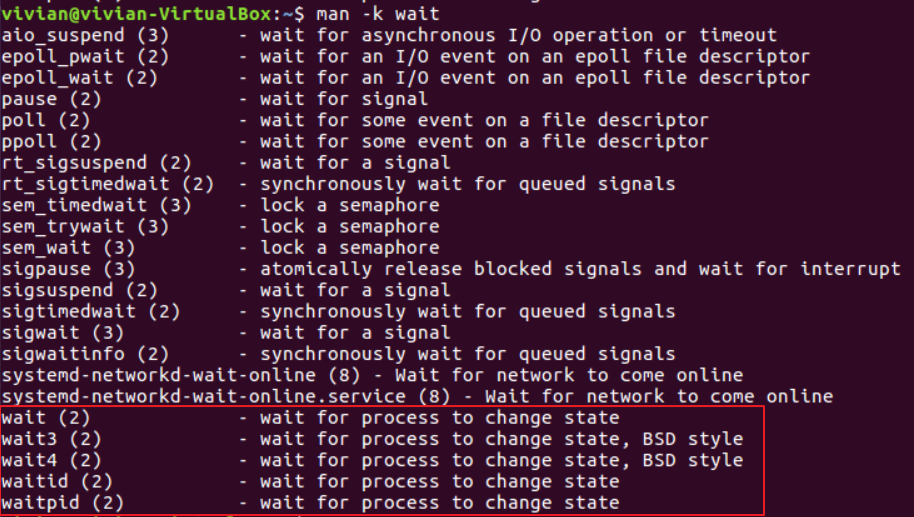
再使用man 2 wait命令查看详细信息:
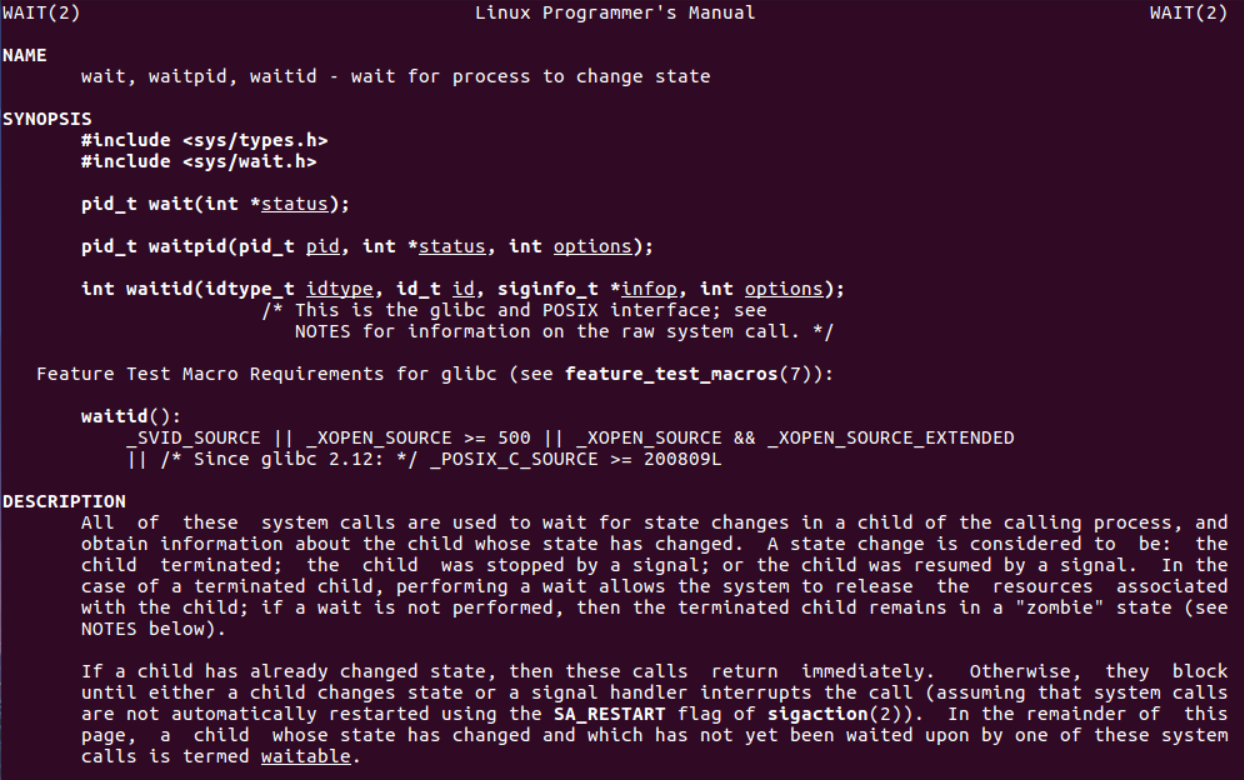
wait()的使用方法为:
#include <sys/types.h>
#include <unistd.h>
pid_t wait(int *status);
//返回:如果成功,则返回子进程的PID,如果出错,则返回-1。
函数功能是:父进程一旦调用了wait就立即阻塞自己,由wait自动分析是否当前进程的某个子进程已经退出,如果让它找到了这样一个已经变成僵尸的子进程,wait就会收集这个子进程的信息,并把它彻底销毁后返回;如果没有找到这样一个子进程,wait就会一直阻塞在这里,直到有一个出现为止。
需要注意的几点是:
-
当父进程忘了用wait()函数等待已终止的子进程时,子进程就会进入一种无父进程的状态,此时子进程就是僵尸进程。
-
wait()要与fork()配套出现,如果在使用fork()之前调用wait(),wait()的返回值则为-1,正常情况下wait()的返回值为子进程的PID。
-
如果先终止父进程,子进程将继续正常进行,只是它将由init进程(PID 1)继承,当子进程终止时,init进程捕获这个状态。
那么,传给函数wait()的参数status是什么呢?
参数status用来保存被收集进程退出时的一些状态,它是一个指向int类型的指针。但如果我们对这个子进程是如何死掉毫不在意,只想把这个僵尸进程消灭掉,(事实上绝大多数情况下,我们都会这样想),我们就可以设定这个参数为NULL,就像下面这样:
pid = wait(NULL);
如果成功,wait会返回被收集的子进程的进程ID,如果调用进程没有子进程,调用就会失败,此时wait返回-1,同时errno被置为ECHILD。
如果参数status的值不是NULL,wait就会把子进程退出时的状态取出并存入其中, 这是一个整数值(int),指出了子进程是正常退出还是被非正常结束的,以及正常结束时的返回值,或被哪一个信号结束的等信息。由于这些信息 被存放在一个整数的不同二进制位中,所以用常规的方法读取会非常麻烦,人们就设计了一套专门的宏(macro)来完成这项工作,以下是其中最常用的两个:
-
1.WIFEXITED(status) 这个宏用来指出子进程是否为正常退出的,如果是,它会返回一个非零值。
-
2.WEXITSTATUS(status) 当WIFEXITED返回非零值时,我们可以用这个宏来提取子进程的返回值,如果子进程调用exit(5)退出,WEXITSTATUS(status) 就会返回5;如果子进程调用exit(7),WEXITSTATUS(status)就会返回7。请注意,如果进程不是正常退出的,也就是说, WIFEXITED返回0,这个值就毫无意义。
如果想知道status参数的所有宏,可以先通过grep -nr "wait" /usr/include命令查看与wait相关的头文件的位置:
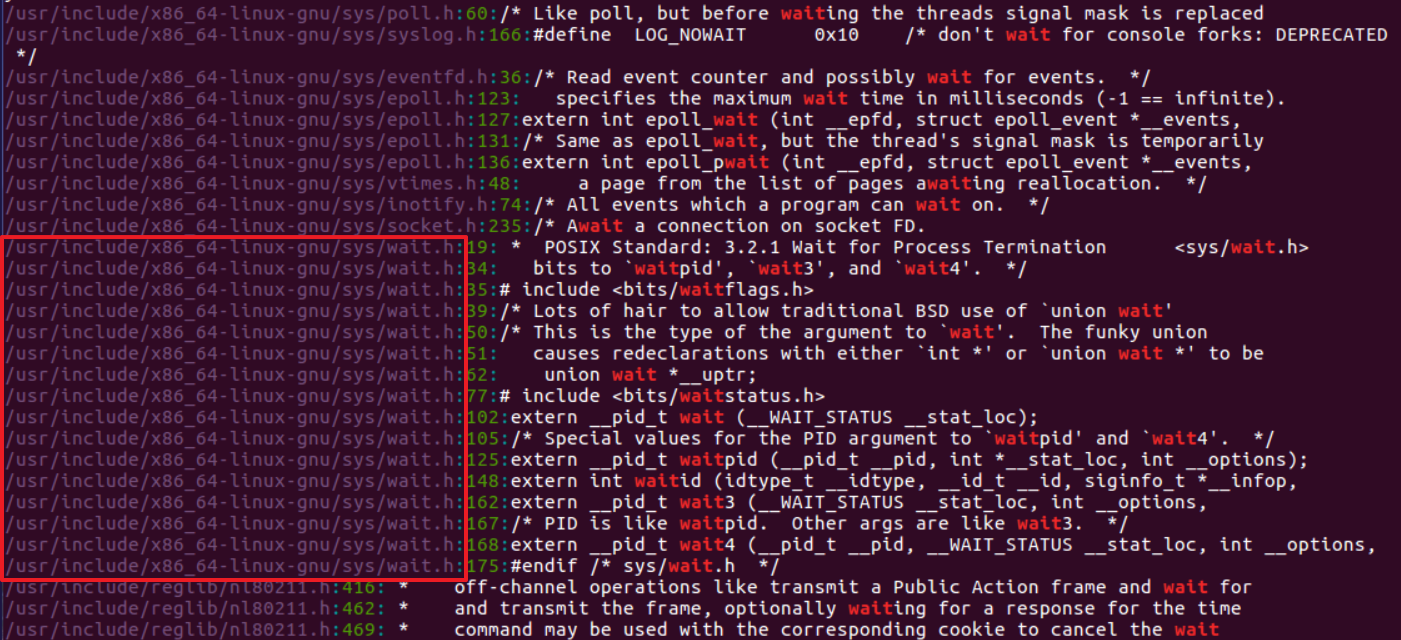
从结果我们可以得出结论,wait.h的所在位置为:/usr/include/x86_64-linux-gnu/sys/wait.h。接下来只需要执行cat /usr/include/x86_64-linux-gnu/sys/wait.h命令,即可查看到其中包含的所有信息:
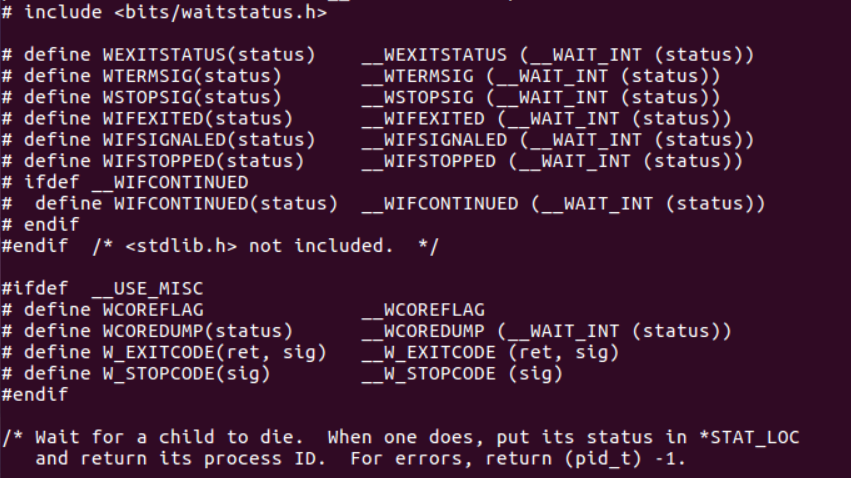
下面通过一个实例进一步学习wait()的用法:
void fork9() {
int child_status;
if (fork() == 0) {
printf("HC: hello from child\n");
exit(0);
} else {
printf("HP: hello from parent\n");
wait(&child_status);
printf("CT: child has terminated\n");
}
printf("Bye\n");
}
此进程的示意图可表示为:
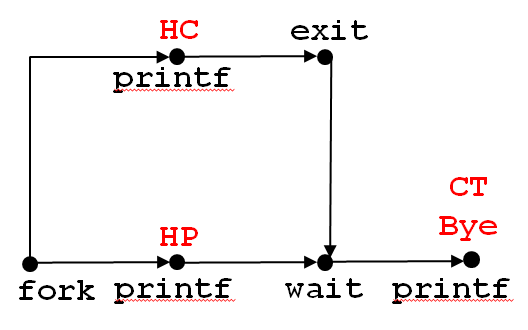
由于父进程必须等待子进程执行完毕后,才能打印“CT”,所以“HC\nHP\nCT\nBye”为一种可能的输出,而“HP\nCT\nBye\nHC”这种情况就不可能出现。
返回目录
编程练习:myshell
一、思路分析
在上面的学习中,我们知道了如何在应用程序中创建和操作进程,以及如何通过Linux系统调用来使用多个进程。事实上,像Unix shell和Web服务器这样的程序大量使用了fork()和execve()函数,现在我们通过调用以上学习的函数,自己写一个类似于shell的程序。
一个shell的主循环执行下面的4步:
- 用户键入a.out;
- shell建立一个新的进程来运行这个程序;
- shell将程序从磁盘载入;
- 程序在它的进程中运行直到结束。
二、伪代码
shell由下面的循环组成:
while(!end_of_input)
get command
execute command
wait for command to finish
以时间为参考,shell的主循环可以由下图来表示:
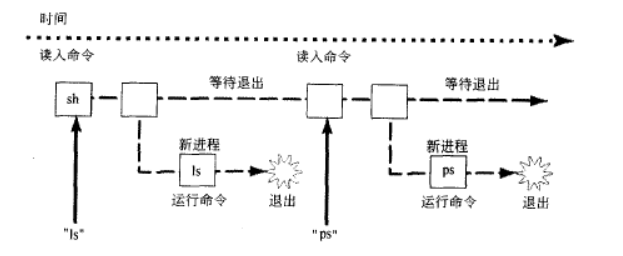
shell读入一个新的一行输入,建立一个新进程,在这个程序中运行程序并等待这个进程结束。当shell检测到输入结束时,它就退出。
因此,要写一个shell,需要学会:
- 运行一个程序——exec函数组;
- 建立一个进程——fork()函数;
- 等待进程结束——wait()函数。
学习了以上内容,我们就可以实现自己的shell了。
三、产品代码
有了以上的分析之后,我们可以根据伪代码写出详细的代码,以下程序可作为参考:
#include <stdio.h>
#include <unistd.h>
#include <wait.h>
#include <stdlib.h>
#include <string.h>
#define MAX 128
void eval (char *cmdline); //对用户输入的命令进行解析
int parseline (char *buf, char **argv);
int builtin_command(char **argv);
int main()
{
char cmdline[MAX];
while(1){
printf("vivian@vivian-VirtualBox:~/20155303/week5/myshell$ ");
fgets(cmdline,MAX,stdin);
if(feof(stdin))
{
printf("error");
exit(0);
}
eval(cmdline);
}
}
void eval(char *cmdline)
{
char *argv[MAX];
char buf[MAX];
int bg;
pid_t pid;
strcpy(buf,cmdline);
bg = parseline(buf,argv);
if(argv[0]==NULL)
return;
if(!builtin_command(argv))
{
if((pid=fork()) == 0)
{
if(execvp(argv[0],argv) < 0) {
printf("%s : Command not found.\n",argv[0]);
exit(0);
}
}
if(!bg){
int status;
if(waitpid(-1,&status,0) < 0)
printf("waitfg: waitpid error!");
}
else
printf("%d %s",pid, cmdline);
return;
}
}
int builtin_command(char **argv)
{
if(!strcmp(argv[0], "quit"))
exit(0);
if(!strcmp(argv[0],"&"))
return 1;
return 0;
}
int parseline(char *buf,char **argv)
{
char *delim;
int argc;
int bg;
buf[strlen(buf)-1]=' ';
while(*buf && (*buf == ' '))
buf++;
argc=0;
while( (delim = strchr(buf,' '))){
argv[argc++] = buf;
*delim= '\0';
buf = delim + 1;
while(*buf && (*buf == ' '))
buf++;
}
argv[argc] = NULL;
if(argc == 0)
return 1;
if((bg=(*argv[argc-1] == '&')) != 0)
argv[--argc] = NULL;
return bg;
}
运行结果如下: