

2017-2018-1 20155303 《信息安全系统设计基础》第一周学习总结
2017-2018-1 20155303 《信息安全系统设计基础》第一周学习总结
教材学习中的问题和解决过程
- 『问题一』:
课本第1章P2提到“像hello.c这样只由ASCII字符构成的文件称为文本文件,所有其他文件都称为二进制文件”,那么文本文件和二进制文件在存储时有什么区别呢?
- 『问题一解决』:
- 二进制文件是把内存中的数据按其在内存中的存储形式原样输出到磁盘上存放,也就是说存放的是数据的原形式。
- 文本文件是把数据的终端形式的二进制数据输出到磁盘上存放,也就是说存放的是数据的终端形式。
查询资料了解到,字符数据本身在内存中就经过了编码,所以无论是二进制还是文本形式都是一样的,而对于非字符数据来说,例如int i=10;如果用二进制来进行存储的话为1010,但是如果需要用文本形式来进行存储的话就必须进行格式化编码(对1和0分别编码,即形式为‘1’和‘0’分别对应的码值)。
由此看来,文本文件与二进制文件的区别即为编码上的不同。
一般认为,文本文件编码基于字符定长,译码容易些;二进制文件编码是变长的,所以它灵活,存储利用率要高些,译码难一些(不同的二进制文件格式,有不同的译码方式)。
- 『问题二』:
进程是操作系统对一个正在运行的程序的一种抽象,进程和线程对于处理数据有什么影响呢?
- 『问题二解决』:
在一个系统上可以同时运行多个进程,这是通过处理器在进程间切换来实现的。操作系统实现这种交错执行的机制称为上下文切换。
一个进程可以由多个称为线程的执行单元组成,每个线程都运行在进程的上下文中,并共享同样的代码和全局数据。
- 『问题三』:
课本第7章P465提到,需要通过在shell中输入以下命令来调用GCC驱动程序:
gcc -Og -o prog main.c sum.c
其中的-Og是什么含义呢?
- 『问题三解决』:
-On(n=0,1,2,3,也可以是其它单词)是gcc为了一般人方便而做的设定,根据n值大小包含预设标准由低到高的一些优化选项,均为-fxxx(xxx为优化项),但注意,即使是最高优化选项-O3,也不是包含所有的-f选项,这只是为大多数人的使用方便而预设的。
Using the GNU Compiler Collection (GCC) 对于 -Og 选项的解释是:
Optimize debugging experience. -Og enables optimizations that do not interfere with debugging. It should be the optimization level of choice for the standard edit-compile-debug cycle, offering a reasonable level of optimization while maintaining fast compilation and a good debugging experience.
也就是说,-Og标识会精心挑选部分与-g选项不冲突的优化选项,提供合理的优化水平,同时产生较好的可调试信息和较高的对语言标准的遵循程度。
- 『问题四』:
ELF头包含哪些信息?变量在内存中是如何存储的?
- 『问题四解决』:
一个典型的ELF可重定位目标文件如下图所示:
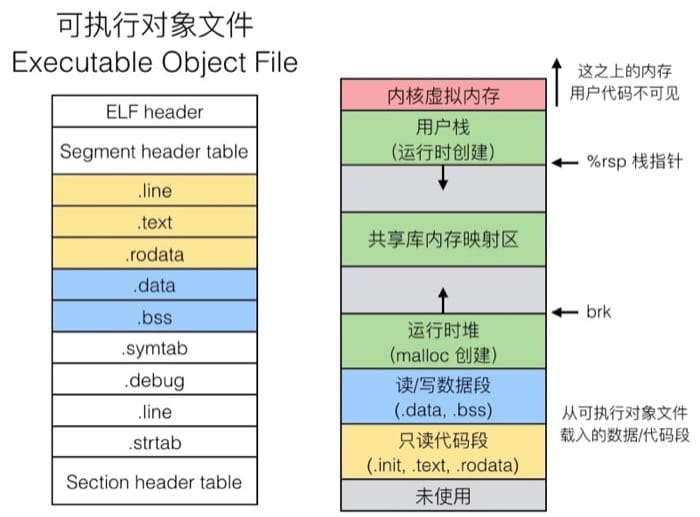
各节含义如下:
| 节 | 含义 |
|---|---|
| .text | 已编译程序的机器代码 |
| .rodata | 只读数据,如pintf和switch语句中的字符串和常量值 |
| .data | 已初始化的全局变量 |
| .bss | 未初始化的全局变量 |
| .symtab | 符号表,存放在程序中被定义和引用的函数和全局变量的信息 |
| .rel.text | 当链接器吧这个目标文件和其他文件结合时,.text节中的信息需修改 |
| .rel.data | 被模块定义和引用的任何全局变量的信息 |
| .debug | 一个调试符号表 |
| .line | 原始C程序的行号和.text节中机器指令之间的映射 |
| .strtab | 一个字符串表,其内容包含.systab和.debug节中的符号表 |
对于static类型的变量,gcc编译器在.data和.bss中为每个定义分配空间,并在.symtab节中创建一个有唯一名字的本地链接器符号。对于malloc而来的变量存储在堆(heap)中,局部变量都存储在栈(stack)中。
以下面这个程序为例,来分析一下变量是如何存储的:
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
int z = 9;
int a;
static int b =10;
static int c;
void swap(int* x,int* y)
{
int temp;
temp=*x;
*x=*y;
*y=temp;
}
int main()
{
int x=4,y=5;
swap(&x,&y);
printf(“x=%d,y=%d,z=%d,w=%d/n”,x,y,z,b);
return 0;
}
使用objdump -S var.o查看C源程序的汇编代码可以发现,z和b在.data段,main和swap在.text段,a和c在.bss段,x,y,temp在stack中,printf函数所打印的字符串在.rodata中。
- 『问题五』:
符号和符号表是什么?以上面的程序为例,通过符号表解释变量的存储。
- 『问题五解决』:
程序编译的链接阶段,将函数和变量统称为符号;符号表是由汇编器构造的,使用编译器输出到汇编语言.s文件中的符号。
每个可重定位目标文件都有一个符号表,它包含该文件所定义和引用的符号的信息。在链接器的上下文中,有三种不同的符号:
- 1.由该文件定义并能被其他模块引用的全局符号。即非静态的C函数和非静态的全局变量,如程序中的a,z,swap。
- 2.由其他模块定义并被该文件引用的全局符号。用extern关键字所定义的变量和函数。
- 3.只被该文件定义和引用的本地符号。用static关键字定义的函数和变量。如程序中的b和c。
使用readelf -s var.o可以查看程序的符号表。问题四中的程序对应的符号表为:

上图各字段的含义为:
| 字段名 | 含义 |
|---|---|
| Num | 序号 |
| Value | 符号地址。可重定位目标文件:距定义目标文件的节的起始位置的偏移;可执行目标文件:一个绝对运行的地址 |
| Size | 目标的大小 |
| Type | 要么是数据,要么是函数,或各个节的表目 |
| Bind | 符号是全局的还是本地的 |
| Ndx | 通过索引来表示每个节ABS:不该被重定位的符号UND:代表未定义的符号(在其他地方定义)COM:未初始化的数据目标 |
| Name | 指向符号的名字 |
对于变量b和z,Ndx索引为3,我们观察图1,不难发现索引3对应的是.data段。变量c对应的索引为4(.bss段),变量a对应的索引是COM,最终当该程序被链接时,它将做为一个.bss目标分配。
- 『问题六』:
链接器是如何进行符号解析的?若遇到多重定义的全局符号,该如何处理?
- 『问题六解决』:
链接器解析符号引用的方法是将每个引用与它输入的可重定位目标文件的符号表中的一个确定的符号定义关联起来。
以课本上的程序为例:
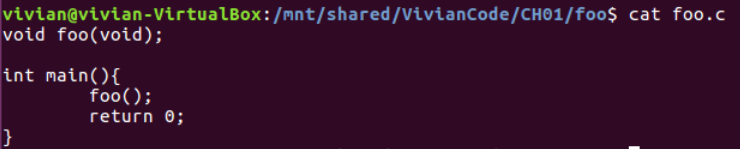
查看该程序的符号表,可以看到foo为UND
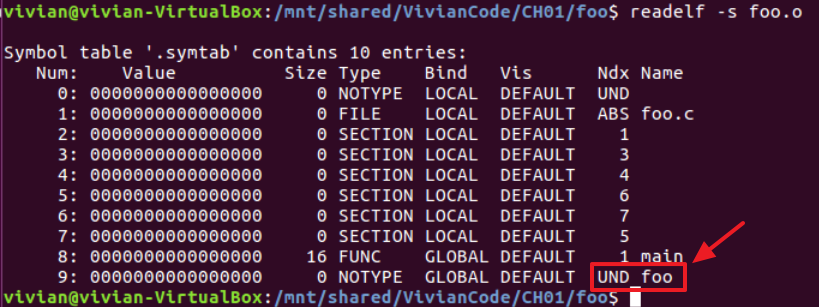
但是链接器无法解析对foo的引用,因为其他地方也未定义:

要判断多个模块定义同名的全局符号会出现什么结果,这需要引入强符号和弱符号的概念:
函数和已初始化的全局变量是强符号,未初始化的全局变量是弱符号。
对于它们,下列三条规则使用:
- 同名的强符号只能有一个,否则编译器报"重复定义"错误。
- 允许一个强符号和多个弱符号,但定义会选择强符号的。
- 当有多个弱符号相同时,链接器选择占用内存空间最大的那个。
教材每章提问汇总
要求:快速浏览一遍教材,课本每章提出至少一个自己不懂的或最想解决的问题并在期末回答这些问题
-
『第1章 计算机系统漫游』:一个可执行程序是如何一步步产生的?
-
『第2章 信息的表示和处理』:如何利用计算机的算术运算特性保证运算结果的精度?
-
『第3章 程序的机器级表示』:不同的数据结构,分配和访问方式有何差异?
-
『第4章 处理器体系结构』:五阶段处理器流水线具体指什么?
-
『第5章 优化程序性能』:如何在理解现代处理器的原理上,提高代码性能?
-
『第6章 存储器层次结构』:如何通过改善程序的时间局部性和空间局部性来提高应用程序的性能?
-
『第7章 链接』:链接的具体过程是怎样的?在生成可执行目标文件的过程中起什么作用?
-
『第8章 异常控制流』:进程是如何工作的?如何在应用中创建和操纵进程?
-
『第9章 虚拟内存』:虚拟内存是如何体现计算机系统软硬件结合的优点的?
-
『第10章 系统级I/O』:C的标准I/O库与Linux I/O有什么关系?
-
『第11章 网络编程』:如何开发简单的迭代式Web服务器?
-
『第12章 并发编程』:如何利用线程级并行性使得程序在多核机器上更快运行?
代码托管
结对及互评
本周结对学习情况
- 20155213
- 结对学习内容
- 学习第1、7章
- 交流课堂学习内容
- 大致了解本学期实验
其他(感悟、思考等,可选)
正式上课的第一周。
到了大三,进入了专业课学习的重要阶段,学习方法也需要做相应的调整。这学期的课与上学期相比,增加了不少动手实践的环节,门门课都有相关的上机实验。动手实践,虽然可以激发我对一门课的兴趣,但也确实是我的弱项,总归不能懈怠。
最近一阵,繁多的事务性工作让我有点分心,常常忙得晕头转向,学习的计划也常常被打乱。本打算利用空闲时间夯实基础,拓展知识,但真的力不从心。拿本周的《信息安全系统设计基础》来讲,一周自学两章的任务并不算轻松,可我只花了不到十小时的时间学习。一字一句啃书本需要大量的精力,但如果最起码的学习时间都不能保证,怎么能学到起码令自己满意的程度?在学习过程中遇到难懂的知识点,我都查阅了大量资料,也自己动手验证了结果是否与预期相符,但仍有个别问题不太理解,比如第七章的重定位符号引用。这需要通过观察反汇编代码,探究链接器是如何定位PC相对引用和绝对引用的。产生了反汇编代码,却不知道如何分析。所以在接下来的几天我还会继续深入学习这两章的内容。
老师常说,要分清主次轻重。不管是工作还是学习,找到一个平衡点至关重要。之后我会试着调整心态,尽量做到两者兼顾,而不是舍本求末,因小失大。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 20篇 | 400小时 | |
| 第一周 | 330/330 | 1/1 | 8/8 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:20小时
-
实际学习时间:8小时
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)

