
ubuntu14.04搭建Hadoop2.9.0集群(分布式)环境
本文进行操作的虚拟机是在伪分布式配置的基础上进行的,具体配置本文不再赘述,请参考本人博文:ubuntu14.04搭建Hadoop2.9.0伪分布式环境
本文主要参考 给力星的博文——Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS,以及《Hadoop应用开发技术详解(作者:刘刚)》
本文主要用3台虚拟机来搭建Hadoop分布式环境,三台虚拟机的拓扑图如下图所示
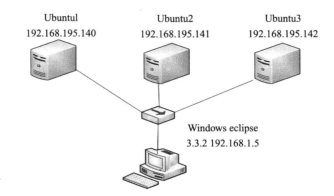
Hadoop集群中每个节点的角色如下表所示
| 主机名 | Hadoop角色 | IP地址 | Hadoop jps命令结果 | Hadoop用户 | Hadoop安装目录 |
| Master |
master slave |
192.168.8.210 |
Jps NameNode SecondaryNameNode ResourceManager JobHistoryServer |
hadoop | /usr/local/hadoop |
| Slave1 | slave | 192.168.8.211 |
Jps NameNode DataNode |
||
| Slave2 | slave | 192.168.8.212 |
Jps NameNode DataNode |
||
| Windows | 开发环境 | 192.168.0.169 | |||
一、网络设置
1. 虚拟机设为桥接模式
网络配置方法见博文:http://blog.csdn.net/zhongyoubing/article/details/71081464
2. 修改主机名
按照上表修改对应主机名,配置文件/etc/hostname
3. 设置IP映射
配置文件/etc/hosts, 所有节点的配置均相同
127.0.0.1 localhost 192.168.8.210 Master 192.168.8.211 Slave1 192.168.8.212 Slave2
4. 测试
重启,测试是否相互 ping 得通
$ ping Master -c 3 $ ping Slave1 -c 3 $ ping Slave2 -c 3
二、SSH无密码登录节点
Master:
$ rm ~/.ssh $ ssh Master $ cd ~/.ssh $ ssh-keygen -t rsa $ cat ./id_rsa.pub >> ./authorized_keys $ scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/ $ scp ~/.ssh/id_rsa.pub hadoop@Slave2:/home/hadoop/
Slave1 & Slave2:
$ rm ~/.ssh $ mkdir ~/.ssh $ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys $ rm ~/id_rsa.pub
Master端测试:
登录节点Slave2
$ ssh Slave2
退出
$ exit
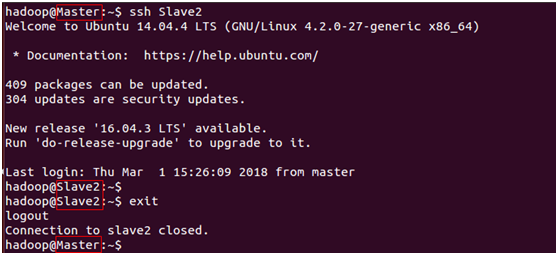
三、Master节点配置分布式环境
配置文件在目录/usr/local/hadoop/etc/hadoop/下
slaves
Slave1
Slave2
core-site.xml,详细说明见:http://hadoop.apache.org/docs/r2.9.0/hadoop-project-dist/hadoop-common/core-default.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Hadoop重要临时文件存放目录</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://Master:9000</value> <description>一种方案和权限决定文件系统实现的URI</description> </property> </configuration>
hdfs-site.xml,详细说明见:http://hadoop.apache.org/docs/r2.9.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> <description>复制的块(即数据节点)的数量</description> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>Master:50090</value> <description>辅助管理节点HTTP服务器地址和端口</description> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> <description>DFS管理节点的本地存储路径</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> <description>DFS数据节点的本地存储路径</description> </property> </configuration>
mapred-site.xml,详细说明见:http://hadoop.apache.org/docs/r2.9.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <description>执行MapReduce作业时运行的框架</description> </property> <property> <name>mapreduce.jobhistory.address</name> <value>Master:10020</value> <description>MapReduce jobhistory服务器的进程间通信地址</description> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>Master:19888</value> <description>MapReduce jobhistory服务器的用户界面地址</description> </property> </configuration>
yarn-site.xml,详细说明见:http://hadoop.apache.org/docs/r2.9.0/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>Master</value> <description>ResourceManager的主机名</description> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <description>NodeManager的辅助服务</description> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> <description>启用日志聚合,默认值为False,即禁用</description> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value>${yarn.log.dir}/userlogs</value> <description>应用程序的本地化的日志目录</description> </property> </configuration>
关于日志的查看问题,请见本人另一篇博文:
四、其他节点配置分布式环境
Master:
$ cd /usr/local/ $ sudo rm -r ./hadoop/tmp $ sudo rm -r ./hadoop/logs $ tar -zcf ~/hadoop.master.tar.gz ./hadoop $ scp ~/hadoop.master.tar.gz Slave1:/home/hadoop $ scp ~/hadoop.master.tar.gz Slave2:/home/hadoop $ rm ~/hadoop.master.tar.gz
Slave1 & Slave2:
$ sudo rm -r /usr/local/hadoop $ sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local $ sudo chown -R hadoop /usr/local/hadoop $ rm ~/hadoop.master.tar.gz
五、启动Hadoop
Master:
0. 格式化NameNode(更改配置后才执行这一步)
$ hdfs namenode -format
1. 启动NameNode和DataNode守护进程,以及YARN
$ start-all.sh

查看进程
$ jps
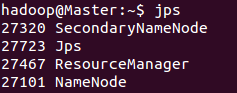
由于在配置文件/usr/local/hadoop/etc/hadoop/slaves中,未添加"Master",所以Master只作为管理节点,不作为数据节点,所以没有进程DataNode和进程NodeManager。
Slave1 & Slave2:
查看进程
$ jps
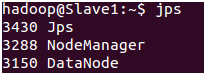
Master:
2. 启动JobHistoryServer进程
$ mr-jobhistory-daemon.sh start historyserver
查看进程
$ jps
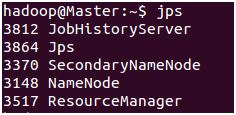
查看DataNode
$ hdfs dfsadmin -report


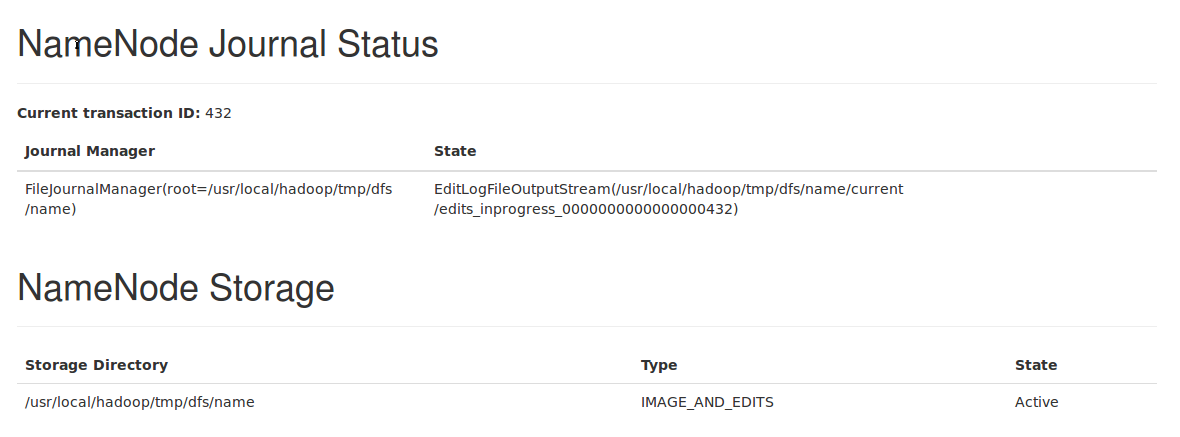
可以访问Web页面http://master:50070/查看DataNode和NameNode的状态,如下图所示:

六、关闭Hadoop
Master:
1. 关闭NameNode和DataNode守护进程,以及YARN
$ stop-all.sh

查看进程
$ jps

Slave1 & Slave2:
查看进程
$ jps

可以看到,在Master端执行stop-all.sh脚本时,将节点的相应进程也关闭了。但是Master端还有一个JobHistoryServer进程未关闭。
Master:
2. 关闭JobHistoryServer进程
$ mr-jobhistory-daemon.sh stop historyserver
查看进程
$ jps

七、分布式实例
1. 创建文件test.txt(目录没有要求)
Hello world
Hello world
Hello world
Hello world
Hello world
2. 在HDFS中创建用户目录
$ hdfs dfs -mkdir -p /user/hadoop
3. 创建input目录
$ hdfs dfs -mkdir input
4. 将本地文件上传到input里
$ hdfs dfs -put ./test.txt input
5. 查看是否上传成功
$ hdfs dfs -ls /user/hadoop/input
6. 操作(统计词频)
$ hdfs dfs -rm -r output #Hadoop运行程序时,输出目录不能存在,否则会提示错误 $ hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount /user/hadoop/input/test.txt /user/hadoop/output
7. 查看运行结果
$ hdfs dfs -cat output/*

可以访问Web界面http://master:8088/cluster/查看任务进度,在Web界面点击“Tracking UI”这一列的History连接,可以看到任务的运行信息,如下图所示:

8. 将运行结果取回本地
$ rm -r ./output #如果本地存在output目录 $ hdfs dfs -get output ./output $ cat ./output/*

9. 删除output目录
$ hdfs dfs -rm -r output $ rm -r ./output
八、更改配置或初始化工作环境
如果要初始化工作环境,或者更改了配置文件,请执行以下步骤:
四 → 五 → 七-2 → 七-3
以上

 浙公网安备 33010602011771号
浙公网安备 33010602011771号