ClearTrace
一年前两次手动使用fn_trace_gettable对跟踪文件进行分析,按TextData排序,通过截取TextData左边N位尝试分组,观察总体相同的过程或语句中的关键字,逐一得出跟踪分析报表,罗列出过程(语句)按CPU、Duration、Reads的执行情况。之后决定找工具,于是正式开启使用RML。最近在博客园看到推荐ClearTrace,尝试使用。
RML下载:https://github.com/Microsoft/SqlNexus/wiki/RML-Utility,ClearTrace下载:http://www.scalesql.com/cleartrace/
首先从服务器收集半小时的跟踪数据,然后分别使用RML和ClearTrace来分析跟踪数据。最看好的都是[按照同一类型的语句,统计最昂贵的语句]
1、将跟踪文件分别导入,具体方法请度娘
RML导入完成后,首先打开的是总体报告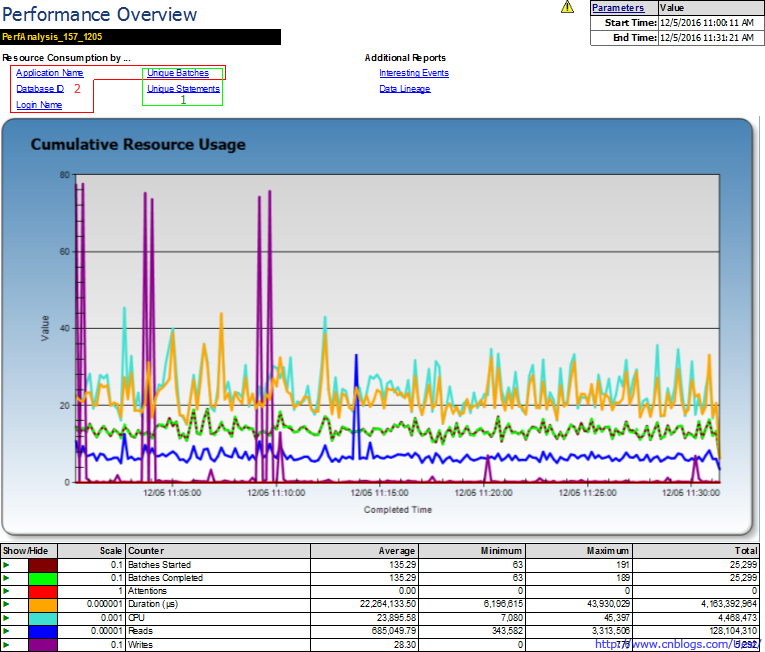
ClearTrace导入完成后,首先打开的是按SQL Text汇总的语句,类似于RML中的"Unique Batches"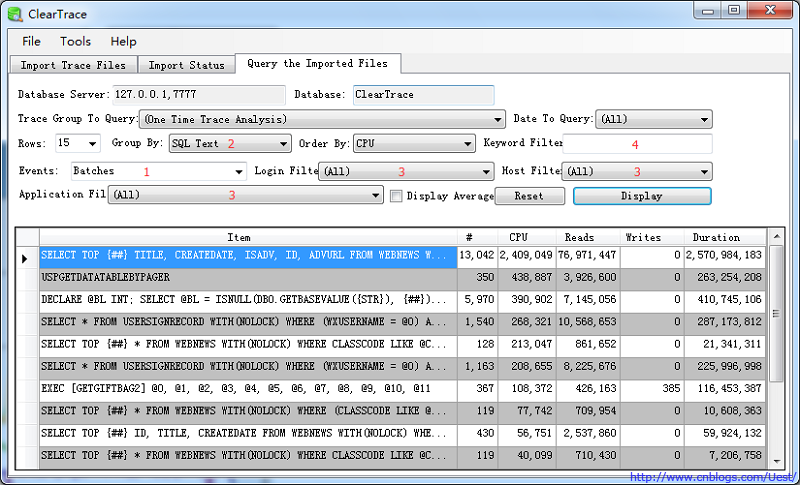
2、查看它们的共同点
ClearTrace图中标1的地方,用于选择事件Batches(RPC:Completed、SQL:BatchCompleted)/Statements(SP:StmtCompleted、SQL:StmtCompleted)。大部分跟踪我们选择Batches级别,需要细化问题时才会跟踪Statements级别。因此这里我们只讨论Events为Batches的操作。ClearTrace图中标1与RML图中标1(Unique Batches/Unique Statements)类似。
ClearTrace图中标2的地方,针对跟踪语句按类型分组。等效于RML图中的标2,按程序(Application Name)、数据库(Database Id)、用户名(Login Name)、Unique Batches分组
RML中按程序(Application Name)分组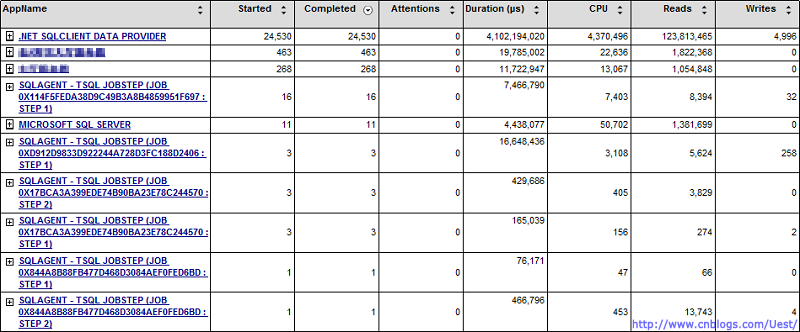
ClearTrace图中标3的地方,可以查看具体的Login、Host、Application语句消耗情况。类似于点击RML图中的标2的链接后,继续点击下层链接。例如ClearTrace只查看Application为[.Net SqlClient Data Provider]的消耗情况
在RML中对应的Performance Overview->Application Name->.Net SqlClient Data Provider
ClearTrace图中标4的地方,Keyword Filter文本框可以输入关键字进行过滤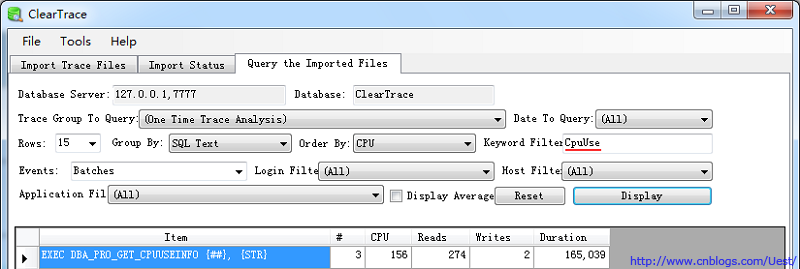
结果只返回SQL Text中包含CpuUse的记录,这个功能貌似在RML中没有。
当ClearTrace的Group By置为SQL Text时,双击Item中的条目,会打开对应语句的详细信息,包括以下三个页签:
->SQL:指定语句的规范化语句和样例语句
->History:指定语句按天执行次数,平均消耗情况
->Details:指定语句最后一天,按HostName, LoginName, ApplicationName分组的执行次数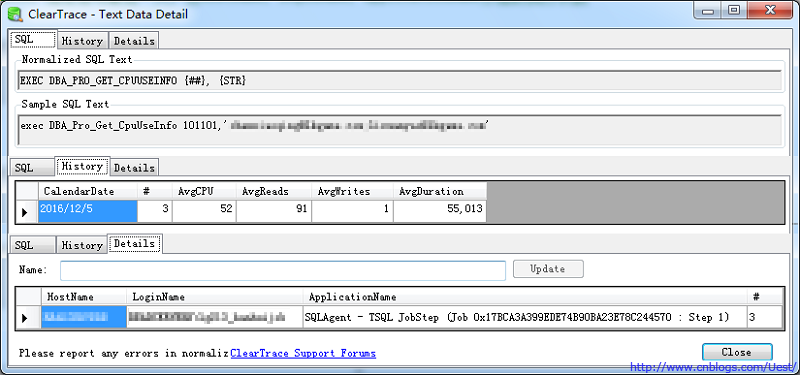
不过ClearTrace返回的都是表格,没有图形也不支持导出;RML有图表,并且支持导出,视觉效果直观(貌似图形显示需要MSChart控件)。
ClearTrace和RML界面上的表格结果差不多,很多时候界面上的东西限制得太死。比如ClearTrace/RML都只是针对一个维度进行Group By,有时我们可能希望在Unique Batches的基础上能显示DatabaseName。这时就需要我们使用脚本去提取,RML的提取脚本参考报表语句。ClearTrace的提取脚本如下


USE ClearTrace GO --默认只对TextDataHashCode分组,可根据需求增加Application、Login、Host分组 --关联显示样例语句 ;WITH CTE AS ( SELECT TextDataHashCode, NormalizedTextData AS Item,LoginName, SUM(ExecutionCount) AS [Executes], SUM(CPU) AS CPU, CAST( CAST(SUM(CPU) AS DECIMAL(22, 2)) / SUM(ExecutionCount) AS DECIMAL(22, 2) ) AS AvgCPU, SUM(Reads) AS Reads, CAST( CAST(SUM(Reads) AS DECIMAL(22, 2)) / SUM(ExecutionCount) AS DECIMAL(22, 2) ) AS AvgReads, SUM(Writes) AS Writes, CAST( CAST(SUM(Writes) AS DECIMAL(22, 2)) / SUM(ExecutionCount) AS DECIMAL(22, 2) ) AS AvgWrites, SUM(Duration)/1000 AS Duration, CAST( CAST(SUM(Duration) AS DECIMAL(22, 2)) / SUM(ExecutionCount)/1000 AS DECIMAL(22, 2) ) AS AvgDuration, ROW_NUMBER() OVER(ORDER BY SUM(CPU) DESC) AS CpuRank, ROW_NUMBER() OVER(ORDER BY SUM(Reads) DESC) AS ReadsRank --还可以添加其他项Rank FROM [dbo].[CTTraceSummaryView] TD WHERE EventClass IN (10, 12) --Batches:10,12;Statements:41,45 AND NormalizedTextData IS NOT NULL AND NormalizedTextData <> '' AND TraceName = '(One Time Trace Analysis)' --AND ApplicationName = '.Net SqlClient Data Provider'--各种筛选Filter --AND CalendarDate >= '2016-10-21' AND LoginName not like '%Administrator%' GROUP BY TextDataHashCode, NormalizedTextData,LoginName ) SELECT TOP(25) WITH TIES [Item], b.SampleTextData,LoginName, --Add DatabaseName 需要再打开,不然从跟踪文件通过TextData匹配消耗很大 --(select top 1 DatabaseName from fn_trace_gettable(N'F:\TroubleShooting\Trace\FINANCEDB_HighCPU30_20161222.trc', default) where convert(varchar(max),textdata)=convert(varchar(max),b.SampleTextData)) as DatabaseName, [Executes], [CPU], [AvgCPU], [Reads], [AvgReads], [Writes], [AvgWrites], [Duration], [AvgDuration], [CpuRank],[ReadsRank] --Add FROM [CTE] a INNER JOIN [dbo].[CTTextData] b ON a.[TextDataHashCode]=b.[TextDataHashCode] ORDER BY CASE WHEN [CpuRank] < [ReadsRank] THEN [CpuRank] ELSE [ReadsRank] END , [CpuRank], [ReadsRank] --按CPU&Reads排序,类似于RML中的Top/Bottom N --Executes DESC select top 100 b.Name EventClass,TextData,DatabaseName,DatabaseID,Duration/1000 Duration_ms,CPU CPU_ms,Reads,Writes,StartTime,EndTime,HostName,LoginName,ApplicationName from fn_trace_gettable(N'F:\TroubleShooting\Trace\FINANCEDB_HighCPU30_20161222.trc', default) a inner join sys.trace_events b on a.EventClass=b.trace_event_id where TextData like '%DBA_Pro_Get_BlockedInfo%'
貌似ClearTrace把Database相关项给舍弃,找到语句不知道是哪个库就有点尴尬了(≧Д≦)。上面脚本尝试使用TextData到跟踪文件中匹配得到DatabaseName,有点鸡胁~
小充电:TOP N WITH TIES..ORDER BY
返回Top N+[ORDER BY字段]与第N条记录的[ORDER BY字段]相同的记录
View Code--看看就懂 select top 3 --with ties id,remark from ( select 1 id,'1st' remark union all select 2,'2nd' union all select 2,'3rd' union all select 3,'4th' union all select 4,'5th' ) t order by id desc --不带with ties id remark ----------- ------ 4 5th 3 4th 2 3rd (3 行受影响) --with ties id remark ----------- ------ 4 5th 3 4th 2 3rd 2 2nd (4 行受影响)
总得来说,如果是要通过分析跟踪文件得到消耗高的语句/存储过程,不需要花哨的图表数据,使用ClearTrace即可。ClearTrace简单的点击导入即可(文件滚动更新得到的.trc可一次性导入),RML需要使用导入命令。有时间再测试下ClearTrace对跟踪文件中的跟踪列是不是有限制,RML必需添加BinaryData列。
|
|
【作者】: 醒嘞 |
| 【出处】: http://www.cnblogs.com/Uest/ | |
| 【声明】: 本文内容仅代表个人观点。如需转载请保留此段声明,且在文章页面明显位置给出原文链接! |

