insert into linksvr or insert into from linksvr
通过链接服务器将实例A上的数据写入实例B,通常有以下两种方式
--方案1:在实例A上执行
insert into LinkForB.B..TableB select * from TableA
--方案2:在实例B上执行
insert into TableB select * from LinkForA.A..TableA
目前接手的数据库,大量使用链接服务器来搬迁数据,并且使用者随心所欲。本地写入到链接服务器,从链接服务器读数据写入本地,从链接服务器读数据写入到另一链接服务器。更有坑爹的,本来是写入本地,却在本地的前面加上本地实例的链接服务器!
--20160519
问个问题,实例A上的作业通过链接服务器从实例B获取数据然后写入到实例C,三个实例在不同的服务器。这个实例A充当的是什么角色,它和直接实例B"推"数据给实例C,或者实例C从实例B"拉"数据有什么区别,优劣势如何?
--20160629
Q:三台数据库服务器A、B、C,大致的定位是A写入、B读取、C归档。所有新数据写入到A;页面查询、统计作业放在B。目前A到B,B到C是在作业中通过链接服务器insert...select from linksvr的方式。然后会定期删除A、B中的历史数据。感觉这种方式不稳定,而且如果表的个数很多,通过链接服务器也不方便。大家有没有什么建议?
A:1、使用复制,A复制到B和C;2、AlwaysOn;3、定时跑存储过程,将要插入的语句和删除的语句放在存储过程里面。你把插入的语句放在它本机,通过链接服务器去查询。
以前没有特别关注哪种方式更好,有在群里针对搬迁数据的方式请教过,有朋友建议最好采用pull的链接方式,即insert into TableB select * from LinkForA.A..TableA
偶然看到园子里的文章(为什么透过链接服务器写入,速度会很慢),结合自己遇到的问题,尝试分析通过链接服务器insert数据的区别。
此处为了方便,我所创建的链接服务器[MY]实际是指向当前实例,但是不影响对结果的分析。
首先创建测试表,并在测试表上创建触发器



USE TEST GO --脚本参考http://www.cnblogs.com/wanyong117/p/5764644.html修改 --创建测试表 CREATE TABLE [dbo].[Product]( [ProductID] INT, [Name] [nvarchar](50), [Remark] [nvarchar](50) ) GO --创建触发器 CREATE TRIGGER [dbo].[Product_TR] ON [dbo]. [Product] FOR INSERT AS BEGIN SET XACT_ABORT ON BEGIN TRY IF (select len(ProductID) from inserted)>0--当select查询只返回一个值时才能操作=、!=、<、<=、>、>= BEGIN PRINT 'one row' END END TRY BEGIN CATCH PRINT '消息 '+CONVERT(VARCHAR,ERROR_NUMBER())+',级别 '+CONVERT(VARCHAR,ERROR_SEVERITY()) +',状态 '+CONVERT(VARCHAR,ERROR_STATE())+',过程 '+CONVERT(VARCHAR,ERROR_PROCEDURE()) +',第 '+CONVERT(VARCHAR,ERROR_LINE())+' 行' PRINT ERROR_MESSAGE() END CATCH END GO
注意触发器脚本,是为了在批量插入数据,select...from inserted子查询返回多条记录,进行>操作出错。
插入数据检验
--Step1:插入1条数据,成功 INSERT [Test].[dbo].[Product]( [ProductID],[Name],[Remark]) SELECT TOP 1 [ProductID],[Name],'one row' FROM [AdventureWorks2008R2].[Production].[Product] --Step2:插入5条数据,失败 INSERT [Test].[dbo].[Product]( [ProductID],[Name],[Remark]) SELECT TOP 5 [ProductID],[Name],'more than one row' FROM [AdventureWorks2008R2].[Production].[Product] --Step3:插入5条数据到链接服务器,成功 INSERT [MY].[Test].[dbo].[Product]([ProductID],[Name],[Remark]) SELECT TOP 5 [ProductID],[Name],'ToLink more than one row' FROM [AdventureWorks2008R2].[Production].[Product] --Step4:从链接服务器获取5条数据再插入,失败 INSERT [Test].[dbo].[Product]( [ProductID],[Name],[Remark]) SELECT TOP 5 [ProductID],[Name],'FromLink more than one row' FROM [MY].[AdventureWorks2008R2].[Production].[Product]
Step2和Step4的错误信息如下
我们查看表中数据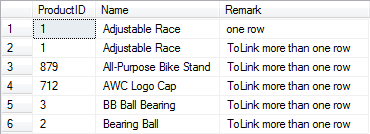
通过图中的Remark字段,可以看出Step1和Step3的语句执行成功,Step2和Step4的语句执行失败
Step1:插入1条数据时,select...from inserted子查询返回1行值,它可和0进行比较(>),数据insert成功。
Step2:插入5条数据时,select...from inserted子查询返回5行值,它不能和单一的0进行比较,触发器报错,整个insert语句失败。
Step3:插入5条数据到链接服务器,竟然成功!对比前面的语句,说明insert into linksvr.db.sch.tb是一行一行的insert(因为表上有触发器,如果一次多行insert会报错)
Step4:当从链接服务器获取5条数据,再insert失败!它近似等效于Step2。
现在我们的问题是Step3和Step4到底哪个更高效?虽然此时我们已经知道,Step3会拆分成单条写入,Step4一次写入多条。为了让这两个语句正常执行,我们禁用表上的触发器
--禁用/启用触发器 alter table [dbo].[Product] disable trigger [Product_TR] --disable/enable --查看触发器 select name,type_desc,create_date,modify_date,is_disabled from sys.triggers t

开启跟踪,然后再次执行Step3、Step4中的语句
INSERT [MY].[Test].[dbo].[Product]([ProductID],[Name],[Remark]) SELECT TOP 5 [ProductID],[Name],'ToLink more than one row' FROM [AdventureWorks2008R2].[Production].[Product]
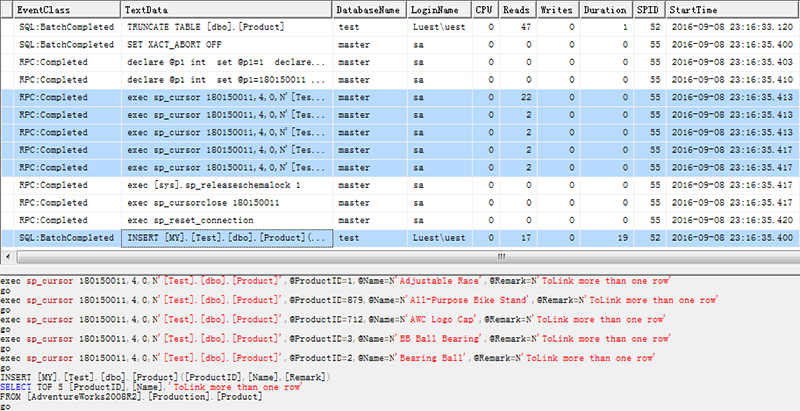
在SPID=52窗口执行INSERT Linksvr SELECT TOP 5 FROM语句,链接服务器在SPID=55下执行,有5个RPC:Completed事件
INSERT [Test].[dbo].[Product]( [ProductID],[Name],[Remark]) SELECT TOP 5 [ProductID],[Name],'FromLink more than one row' FROM [MY].[AdventureWorks2008R2].[Production].[Product]
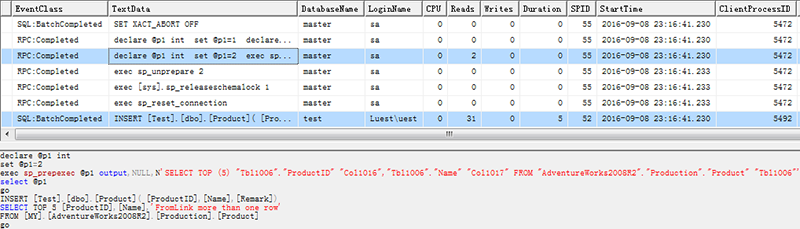
在SPID=52窗口执行INSERT Tab SELECT TOP 5 FROM Linksvr语句,链接服务器在SPID=55的会话中执行,仅一个RPC:Completed事件
此时表中的数据如下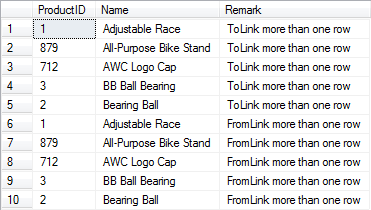
如果将表中数据全部写入到测试表,跟踪添加筛选器SPID=52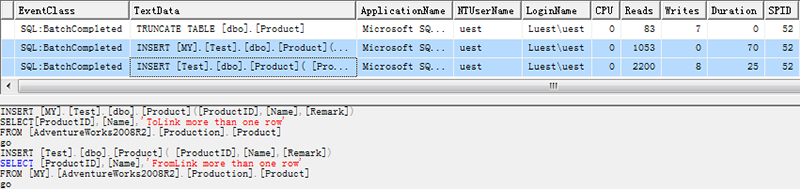
Duration字段可以看出insert linksvr要比insert select linksvr耗时些。其实就是要存一万块钱,是每次只存一百(需100次),还是每次存一万(需1次)。显然后者更高效。
--删除测试表 USE TEST GO DROP TABLE [TEST].[dbo].[Product]
|
|
【作者】: 醒嘞 |
| 【出处】: http://www.cnblogs.com/Uest/ | |
| 【声明】: 本文内容仅代表个人观点。如需转载请保留此段声明,且在文章页面明显位置给出原文链接! |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
2015-09-08 【译】第十篇 SQL Server安全行级安全