Resolving SQL Server Disk IO bottlenecks
网上看到这篇文章挺不错的,直接翻译过来。
在尝试诊断SQL Server性能时,不要仅仅依赖某个单一的诊断数据,比如CPU的使用率、SQL Server磁盘性能,就得出结论却忽略的问题的根源。实际上,使用单一的度量经常会得出一个错误的诊断。
在SQL Server中CPU、IO和内存的使用是相互依赖。在我们采取"knee-jerk"修正行动(添加内存、提升磁盘吞吐量或者更改配置设置)之前,我们需要先查看整体情况。
一、服务器级别
"进程X运行缓慢,你能修复它吗?"
作为DBA,你决定打开资源监视器(resmon),发现磁盘活动异常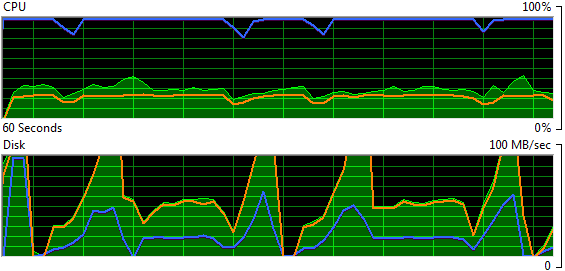
在性能监视器(perfmon)查看部分磁盘相关的计数器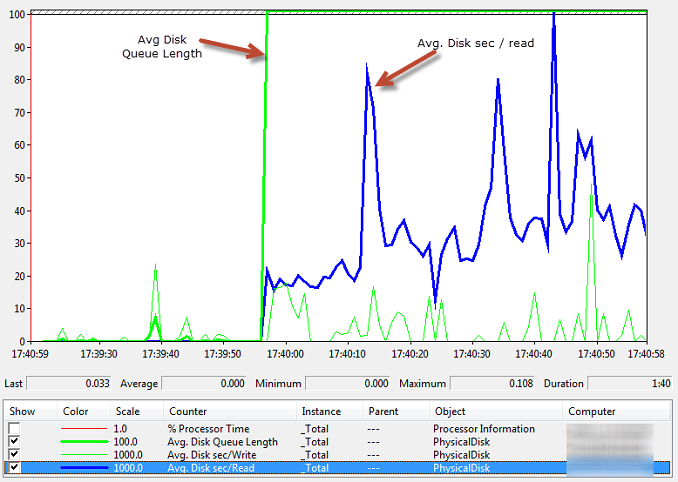
伴随着磁盘请求队列的平均长度急剧上升,从磁盘读取数据存在较高的延迟。好像磁盘子系统成为一个瓶颈,它正努力跟上请求数量,SQL Server磁盘IO性能恶化,队列形成。
你应该采取什么行动解决这个问题呢?在你打算联系系统管理员去看是否可以做些什么来提升磁盘能力,你最好是再深入挖掘下。
如果你只关注一个特定的性能指标,很容易对SQL Server性能问题进行误诊。
你可能有证据表明存在一个特定的瓶颈,但是在本例SQL Server磁盘IO,把磁盘性能不够或者磁盘子系统配置当成问题的根源就有点危险了。
The excessive disk IO could easily have its root cause elsewhere.你需要收集更多的数据来确认问题的根源。但是,你从哪里开始呢?
二、深入挖掘
2.1、Wait statistics
一个好的开始是分析SQL Server等待统计,它通常能够表明为什么SQL Server会话在获取所需资源以执行请求前被迫暂停处理(等待)。通过分析等待,我们可以识别繁忙的服务器上主要引起争用的资源。
查询sys.dm_os_waiting_tasks动态管理视图(DMV),显示所有正在等待资源执行的语句,可以关联其他DMVs得到相关会话和请求的详细信息。作为演示,我们执行以下脚本



--Analyze the queries that are currently running or which have recently ran and their plan is still in the cache. SELECT dm_ws.wait_duration_ms, dm_ws.wait_type, dm_es.status, dm_t.TEXT, dm_qp.query_plan, dm_ws.session_ID, dm_es.cpu_time, dm_es.memory_usage, dm_es.logical_reads, dm_es.total_elapsed_time, dm_es.program_name, DB_NAME(dm_r.database_id) DatabaseName, -- Optional columns dm_ws.blocking_session_id, dm_r.wait_resource, dm_es.login_name, dm_r.command, dm_r.last_wait_type FROM sys.dm_os_waiting_tasks dm_ws INNER JOIN sys.dm_exec_requests dm_r ON dm_ws.session_id = dm_r.session_id INNER JOIN sys.dm_exec_sessions dm_es ON dm_es.session_id = dm_r.session_id CROSS APPLY sys.dm_exec_sql_text (dm_r.sql_handle) dm_t CROSS APPLY sys.dm_exec_query_plan (dm_r.plan_handle) dm_qp WHERE dm_es.is_user_process = 1 GO --You can change CROSS APPLY to OUTER APPLY if you want to see all the details which are omitted because of the plan cache
我们看到两个等待类型,以及相关的查询文本和计划
当然,我们经常对一个问题进行回顾性调查,这样前面的DMV就没太大的用处。作为替换,我们可以查询sys.dm_os_wait_stats动态管理视图,它包含所有等待类型的"运行总值",自上次服务重启或者我们使用DBCC SQLPERF命令手动重置统计信息以来所有请求的累积值
--All wait types since the server was last restarted, or the statistics were manually reset WITH [Waits] AS (SELECT [wait_type], [wait_time_ms] / 1000.0 AS [WaitS], ([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS], [signal_wait_time_ms] / 1000.0 AS [SignalS], [waiting_tasks_count] AS [WaitCount], 100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage], ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum] FROM sys.dm_os_wait_stats WHERE [wait_type] NOT IN ( N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR', N'BROKER_TASK_STOP', N'BROKER_TO_FLUSH', N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE', N'CHKPT', N'CLR_AUTO_EVENT', N'CLR_MANUAL_EVENT', N'CLR_SEMAPHORE', -- Maybe uncomment these four if you have mirroring issues N'DBMIRROR_DBM_EVENT', N'DBMIRROR_EVENTS_QUEUE', N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD', N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE', N'EXECSYNC', N'FSAGENT', N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX', -- Maybe uncomment these six if you have AG issues N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION', N'HADR_LOGCAPTURE_WAIT', N'HADR_NOTIFICATION_DEQUEUE', N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE', N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP', N'LOGMGR_QUEUE', N'MEMORY_ALLOCATION_EXT', N'ONDEMAND_TASK_QUEUE', N'PREEMPTIVE_XE_GETTARGETSTATE', N'PWAIT_ALL_COMPONENTS_INITIALIZED', N'PWAIT_DIRECTLOGCONSUMER_GETNEXT', N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP', N'QDS_ASYNC_QUEUE', N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP', N'QDS_SHUTDOWN_QUEUE', N'REDO_THREAD_PENDING_WORK', N'REQUEST_FOR_DEADLOCK_SEARCH', N'RESOURCE_QUEUE', N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH', N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP', N'SLEEP_MASTERDBREADY', N'SLEEP_MASTERMDREADY', N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP', N'SLEEP_SYSTEMTASK', N'SLEEP_TASK', N'SLEEP_TEMPDBSTARTUP', N'SNI_HTTP_ACCEPT', N'SP_SERVER_DIAGNOSTICS_SLEEP', N'SQLTRACE_BUFFER_FLUSH', N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP', N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS', N'WAITFOR', N'WAITFOR_TASKSHUTDOWN', N'WAIT_XTP_RECOVERY', N'WAIT_XTP_HOST_WAIT', N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG', N'WAIT_XTP_CKPT_CLOSE', N'XE_DISPATCHER_JOIN', N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT') AND [waiting_tasks_count] > 0 ) SELECT MAX ([W1].[wait_type]) AS [WaitType], CAST (MAX ([W1].[WaitS]) AS DECIMAL (16,2)) AS [Wait_S], CAST (MAX ([W1].[ResourceS]) AS DECIMAL (16,2)) AS [Resource_S], CAST (MAX ([W1].[SignalS]) AS DECIMAL (16,2)) AS [Signal_S], MAX ([W1].[WaitCount]) AS [WaitCount], CAST (MAX ([W1].[Percentage]) AS DECIMAL (5,2)) AS [Percentage], CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgWait_S], CAST ((MAX ([W1].[ResourceS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgRes_S], CAST ((MAX ([W1].[SignalS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgSig_S], CAST ('https://www.sqlskills.com/help/waits/' + MAX ([W1].[wait_type]) as XML) AS [Help/Info URL] FROM [Waits] AS [W1] INNER JOIN [Waits] AS [W2] ON [W2].[RowNum] <= [W1].[RowNum] GROUP BY [W1].[RowNum] HAVING SUM ([W2].[Percentage]) - MAX( [W1].[Percentage] ) < 95; -- percentage threshold GO
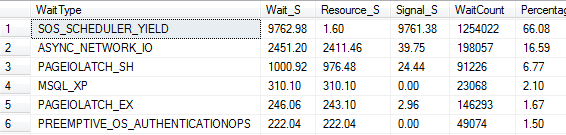
重置sys.dm_os_wait_stats统计信息
-- reset statistics DBCC SQLPERF (N'sys.dm_os_wait_stats', CLEAR); GO
当前查询的两个最贵的等待类型ASYNC_NETWORK_IO和PAGEIOLATCH_SH也出现在这里。如果我们调查的问题不是一个经常性或长期存在的问题,那么有可能相关的等待类型将被"淹没"在历史的等待之中。这就是为什么维护等待统计基线是很重要的。
ASYNC_NETWORK_IO等待类型是一个网络相关的等待,表明客户端不能足够快地处理数据(例子中的查询重重执行并返回大量数据给SSMS)。In general, watch out for this wait type as a warning of inefficient data processing on the client-side.
例子中更有趣的是PAGEIOLATCH_SH等待类型,意味着查询请求必须等待一个latch,以便从磁盘中读取没有保存在buffer cache中的数据。这似乎加强了我们最初的直觉,问题在磁盘供电或错误的配置上。如果磁盘子系统无法快速返回页面,那么它可能会导致更长的请求等待队列来获取页面,以及latch争用。
然而,如果我们怀疑磁盘瓶颈,什么是根本原因?一个有用的下一步是找出更多的IO负载。比如,磁盘活动是否有特别的数据库和数据库文件"热点"?
2.2、Virtual file statistics
通过查询sys.dm_io_virtual_file_stats动态管理视图我们可以知道文件使用统计信息。使用如下脚本
-- Get I/O utilization by database (Query 31) (IO Usage By Database) WITH Aggregate_IO_Statistics AS (SELECT DB_NAME(database_id) AS [Database Name], CAST(SUM(num_of_bytes_read + num_of_bytes_written)/1048576 AS DECIMAL(12, 2)) AS io_in_mb FROM sys.dm_io_virtual_file_stats(NULL, NULL) AS [DM_IO_STATS] GROUP BY database_id) SELECT ROW_NUMBER() OVER(ORDER BY io_in_mb DESC) AS [I/O Rank], [Database Name], io_in_mb AS [Total I/O (MB)], CAST(io_in_mb/ SUM(io_in_mb) OVER() * 100.0 AS DECIMAL(5,2)) AS [I/O Percent] FROM Aggregate_IO_Statistics ORDER BY [I/O Rank] OPTION (RECOMPILE); -- Helps determine which database is using the most I/O resources on the instance
它提供洞察数据库实例上的IO活动,特别是用于揭示IO负载是否分布在不同的数据库
上图显示SQLMonTest数据库是IO热点。同样,这些统计数据是自服务上次启动以来的累积值,但不同于等待统计,不能手动重置(The DMF contains cumulative I/O information for each database file. The DMF data get reset on the instance restart, database offline, detached and reattached activities.)。下面的脚本能够明确的显示相关数据库的高读和写延迟。AdventureWorks2014和SQLMonTest出现在列表的前面
-- 下面的查询返回哪个数据库文件有最大的I/O延迟 -- Calculates average stalls per read, per write, -- and per total input/output for each database file. SELECT DB_NAME(fs.database_id) AS [database_name], mf.physical_name, CONVERT(DECIMAL(18, 2), mf.size / 128.0) AS [file_size_mb], io_stall_read_ms, num_of_reads, CAST(io_stall_read_ms / (1.0 + num_of_reads) AS NUMERIC(10, 1)) AS [avg_read_stall_ms], io_stall_write_ms, num_of_writes, CAST(io_stall_write_ms / (1.0 + num_of_writes) AS NUMERIC(10, 1)) AS [avg_write_stall_ms], io_stall_read_ms + io_stall_write_ms AS [io_stalls], num_of_reads + num_of_writes AS [total_io], CAST((io_stall_read_ms + io_stall_write_ms) / (1.0 + num_of_reads + num_of_writes) AS NUMERIC(10, 1)) AS [avg_io_stall_ms] FROM sys.dm_io_virtual_file_stats(NULL, NULL) AS fs INNER JOIN sys.master_files AS mf WITH (NOLOCK) ON fs.database_id = mf.database_id AND fs.[file_id] = mf.[file_id] ORDER BY avg_io_stall_ms DESC OPTION(RECOMPILE); -- Helps determine which database files on -- the entire instance have the most I/O bottlenecks

2.3、Query execution statistics
已经把问题缩小到一个或两个数据库,下一个逻辑问题是:哪些请求引起数据库上的IO活动?我们可以检查sys.dm_exec_query_stats中的查询执行统计信息。我们可以使用下面的脚本得到指定数据库中总物理读最高的查询以及相关的plan handles(输出结果的部分列省略)
SELECT TOP 10 t.text , execution_count , statement_start_offset AS stmt_start_offset , sql_handle , plan_handle , total_logical_reads / execution_count AS avg_logical_reads , total_logical_writes / execution_count AS avg_logical_writes , total_physical_reads / execution_count AS avg_physical_reads,t.dbid FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t --WHERE DB_NAME(t.dbid) = 'AdventureWorks2008R2' ORDER BY avg_physical_reads DESC;

我们可以将结果中的plan_handle代入sys.dm_exec_query_plan得到查询的执行计划,再去分析是否存在潜在问题。
总结
通过整体审查所有相关的性能指标,我们有最好的机会选择最有效的行动。在本例中,很明显最初的努力方向应该是查询优化和索引策略,因为我们的查询没有WHERE筛选,导致SQL Server执行整表联接。过度的页面读取导致"缓存流失",SQL Server刷新缓冲页到磁盘用于容纳新页,其后果就是"磁盘瓶颈",and sessions waiting to obtain buffer cache latches on pages that need to be read from disk.
|
|
【作者】: 醒嘞 |
| 【出处】: http://www.cnblogs.com/Uest/ | |
| 【声明】: 本文内容仅代表个人观点。如需转载请保留此段声明,且在文章页面明显位置给出原文链接! |


· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?