

数值计算(一)
相关概念:
误差:
截断误差:数学模型问题转化为数值问题时,用到离散化、有限展开等方式,导致数值问题与数学模型之间有误差(例如泰勒展开忽略高阶项)
舍入误差:计算机表示浮点数有固定长度,不能准确表达输入数据和输出结果(四舍五入)
向量范数:向量的误差
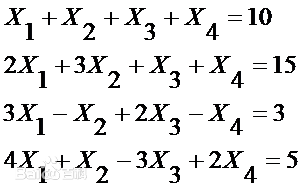 矩阵形式:
矩阵形式: 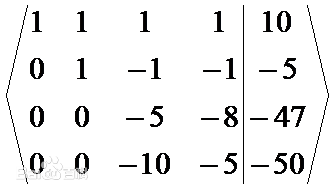 消元:
消元: 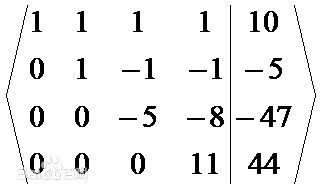 已知x4=44/11=4,回代得到其他未知量,前提对角元素不为0
已知x4=44/11=4,回代得到其他未知量,前提对角元素不为0插值:已知一个函数的数值表(离散的),找一个简单的计算公式,利用它算出给定区间上任意点的值
牛顿插值多项式:Nn(x)=a0+a1(x-x0)+a2(x-x0)(x-x1)+......+an(x-x0)(x-x1)(x-n+1)
差商:
 ;
;  ;
;a0=f(x0)=f0;
a1=f[x0,x1]=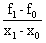
a2=f[x0,x1,x2]=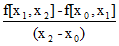 =
=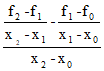
迭代法:
矩阵范数(matrix norm):
1-范数: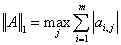
列和范数,即所有矩阵列向量绝对值之和的最大值
2-范数: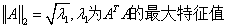
谱范数,即A'A矩阵的最大特征值的开平方
∞-范数:行和范数,即所有矩阵行向量绝对值之和的最大值
F-范数:Frobenius范数,即矩阵元素绝对值的平方和再开平方
条件数:设A为n阶非奇异矩阵(|A|≠0),称数cond(A)=cond(A)=‖A‖·‖A-1‖ 为方程组Ax=b的条件数或A的条件数。
条件数对A或者b的误差带来的微小扰动起到了放大作用。所以条件数越小,方程组的解得相对误差越小。常用的是cond2(A),cond∞(A)
基本迭代法:
Ax=b
假设A=M-N
Mx=Nx+b
x=M-1Nx+M-1b
给定一个初始向量x(0),按照x(k+1)=M-1Nx(k)+M-1b 或 Mx(k+1)=Nx(k)+b迭代至收敛于向量x*,即Ax*=b
可以将A拆成 A=D-L-U
雅克比迭代法: M=D,N=L+U, Dx(k+1)=(L+U)x(k)+b
高斯-赛德尔迭代法(GS):基于雅克比迭代法收敛 Dx(k+1)=Lx(k+1)+Ux(k)+b 或者 (D-L)x(k+1)=Ux(k)+b
超松弛(SOR)迭代法: 将高斯-赛德尔迭代法改为x(k+1)=D-1(Lx(k+1)+Ux(k)+b),可以写成 x(k+1)=x(k)+D-1(Lx(k+1)+Ux(k)-Dx(k)+b)
加一个参数w, x(k+1)=x(k)+wD-1(Lx(k+1)+Ux(k)-Dx(k)+b)可以获得更快的收敛效果
当w=1, SOR=GS;w>1,收敛速度加快
这三种迭代方法都不能保证收敛性
收敛性与稳定性
只有既收敛又稳定的方法,才能提供比较可靠的数直结果。显式算法稳定性受时间步长影响,时间步要足够小才稳定(误差积累受到控制),隐式不受时间步长影响,稳定性高于显式,结果更精准,但计算量远大于显格式。在工程项目上说,要确保结果的准确性,或排除问题不出于算法的稳定性,用隐式比较安全。

