
python3抓取异步百度瀑布流动态图片(一)查找post并伪装头方法
打开流程:
用火狐打开百度图片-->打开firebug-->输入GIF图-->搜索-->点击网络-->全部
观察页面:
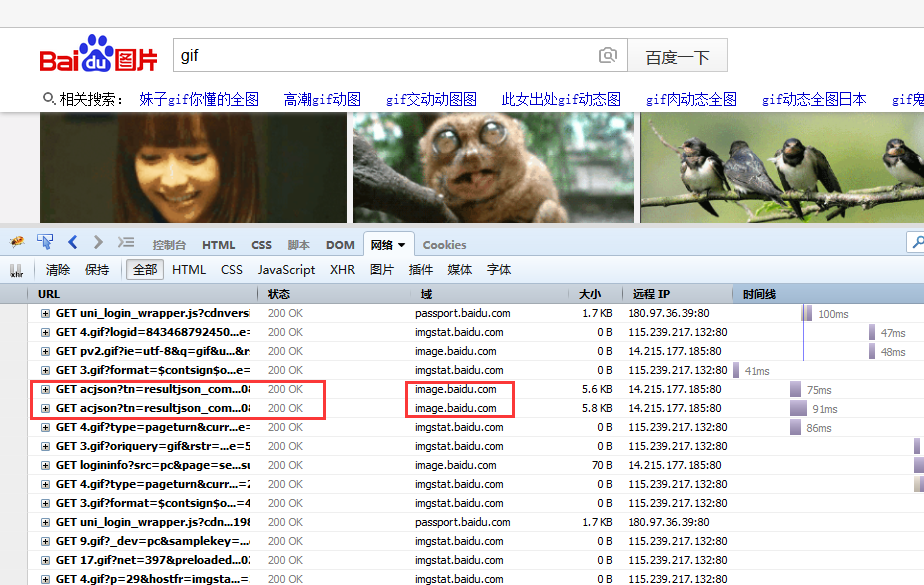
首先要观察的对象是“域”,图片的json一般是放在主要的“域”里面的,任何网站的主要的“域”就是自身,即百度图片的网址image.baidu.com,根据这个“域”我们再去查找URL。
查找方式:
点开“+”号,开打json,观察里面的json的图片网址:
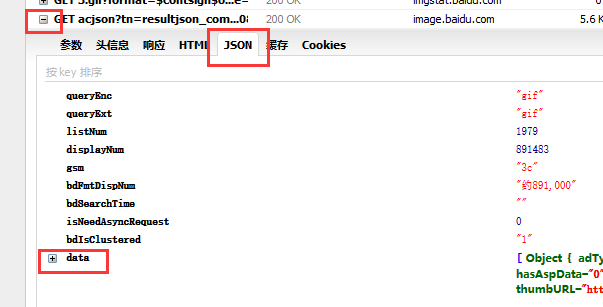
随便点开一个“data”得到一个图片网址:

在浏览器新的窗口里面打开这张图片看看是不是出现在百度图片里面的图片,图片打开时这个样子:

返回百度图片里面去查找:
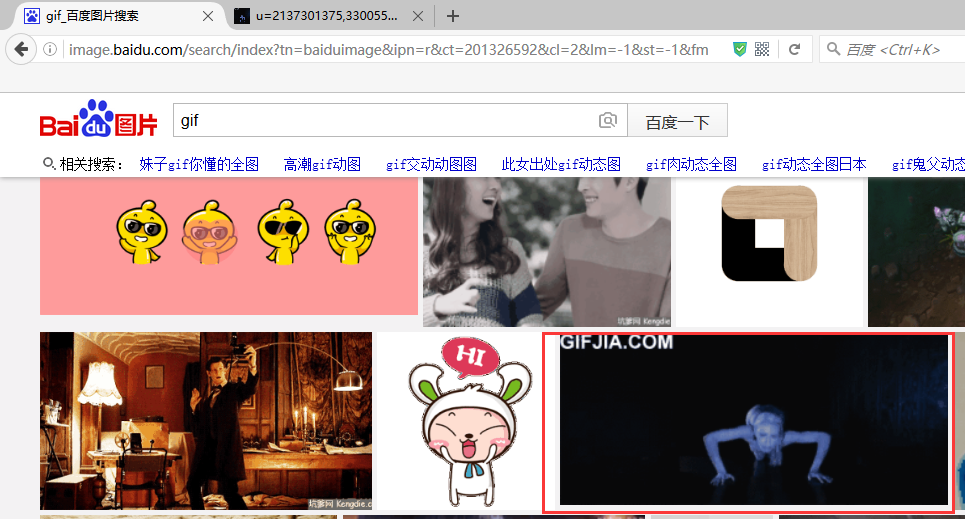
发现也在百度图片里面,那么这个url就是我们要找到的json了,返回去点击复制网址和参数下面的东西出来:
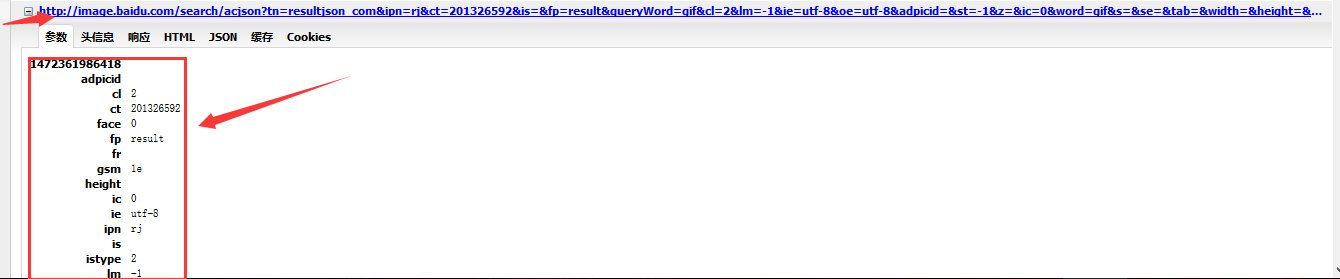
在txt里面观察:
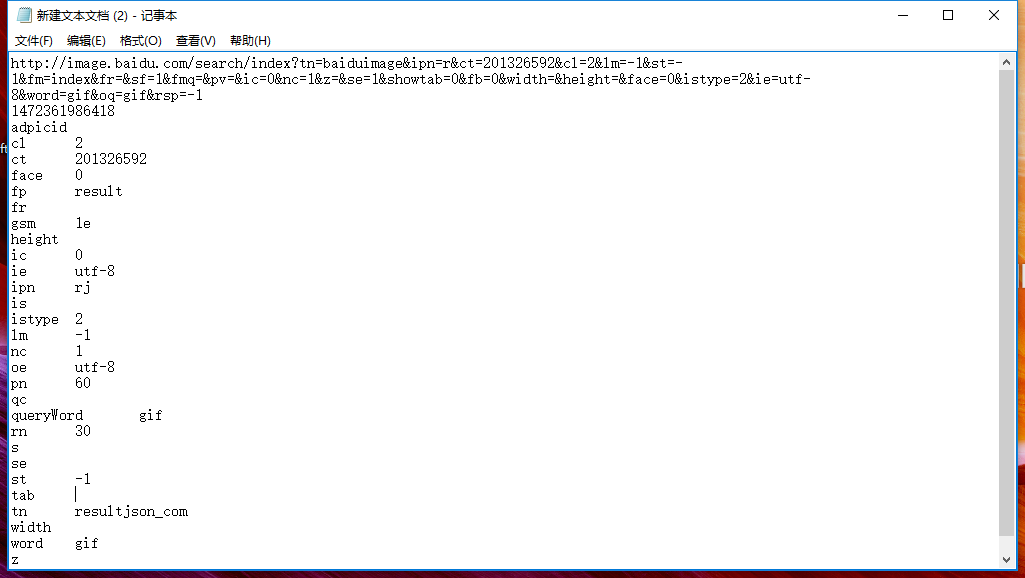
继续观察url,url包含了一大堆的参数,每一个&都固定了一个参数:
http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=gif&oq=gif&rsp=-1
从头到尾看,tn、ipn、ct...
这些在参数里面都有显示,那么我们构造的网址就是:
http://image.baidu.com/search/index?tn...&ipn...&ct...&.....&.....
再去观察百度哪里是用get方式的,所以我们的python也应该用get方式:
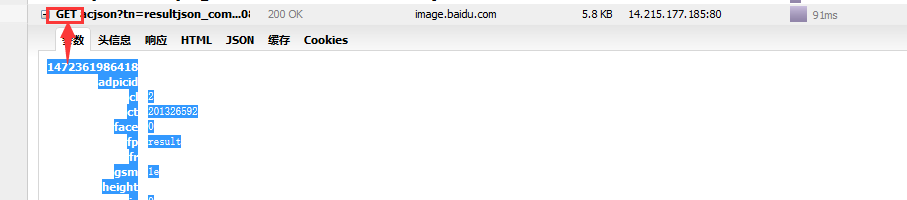
有些网址使用post的,那种方式在以后再去说
---------------------------------------我是快乐的分割线-----------------------------------------
url搞定,那么需要破解它的瀑布流。
浏览器往下拉,给百度图片加载下一个部分的url出来,下面这个是第二部分的url:
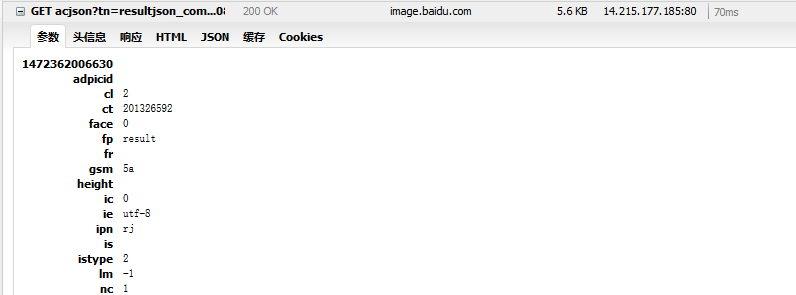
按照上面的方法观察json里面的data,得到的图片:

百度图片原文里面观察:
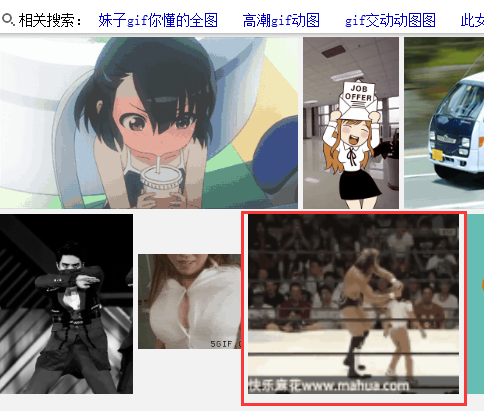
也是找到了这张图片,那么老规矩复制url和参数出来观察:
http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=gif&oq=gif&rsp=-1 http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=90&rn=30&gsm=5a&1472362006630= 1472361986418
URL不相同???
继续往下翻!!!
http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=gif&oq=gif&rsp=-1 http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=90&rn=30&gsm=5a&1472362006630= 1472361986418 http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=150&rn=30&gsm=96&1472363883056=
后面两个网址有规律了,观察之...
看到没,pn!!!!!
一个pn是90一个是150,呵呵哒终于找到了,那么就要找到这个页数的规律。
刷新浏览器,直接翻到第11页:
然后把加载出来的那个特定的url全部复制到txt里面观察,下面我放了部分出来:
http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=30&rn=30&gsm=1e&1472364207674= http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=90&rn=30&gsm=5a&1472364212829= http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=150&rn=30&gsm=96&1472364217002= http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=210&rn=30&gsm=d2&1472364220585= http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=gif&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=gif&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=270&rn=30&gsm=10e&1472364223842=
看到这里还要我多说明么:
pn=30 pn=90 pn=150 pn=210 pn=270
搞定了url,到时候写个for i in range(...),太强大,到这里构造的post就完成了
----------------------------------------------我是快乐的分割线--------------------------------------------------
伪装头部是很重要的,要防止被反爬虫、反反盗链等等,那么头部就是:
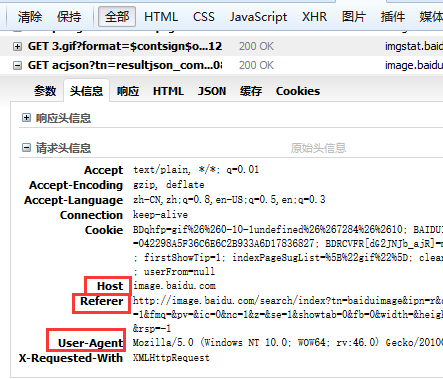
referer是反反盗链,ua是反爬虫,host是主链,这三个最重要,笔者曾经偷懒只写了ua,被反反盗链害死,得到的图片为:

假如你们抓到这样的图那么说明失败,第一篇幅搞定。

