


第二次结对作业
整体概况
-
结对信息
-
github链接
-
设计说明
-
关键代码解释
-
性能分析
-
所遇到的困难及对队友的评价
-
PSP、学习进度条更新
1、结对信息
-
311 旭
-
437 辉
2、github链接
3、设计说明
-
类图
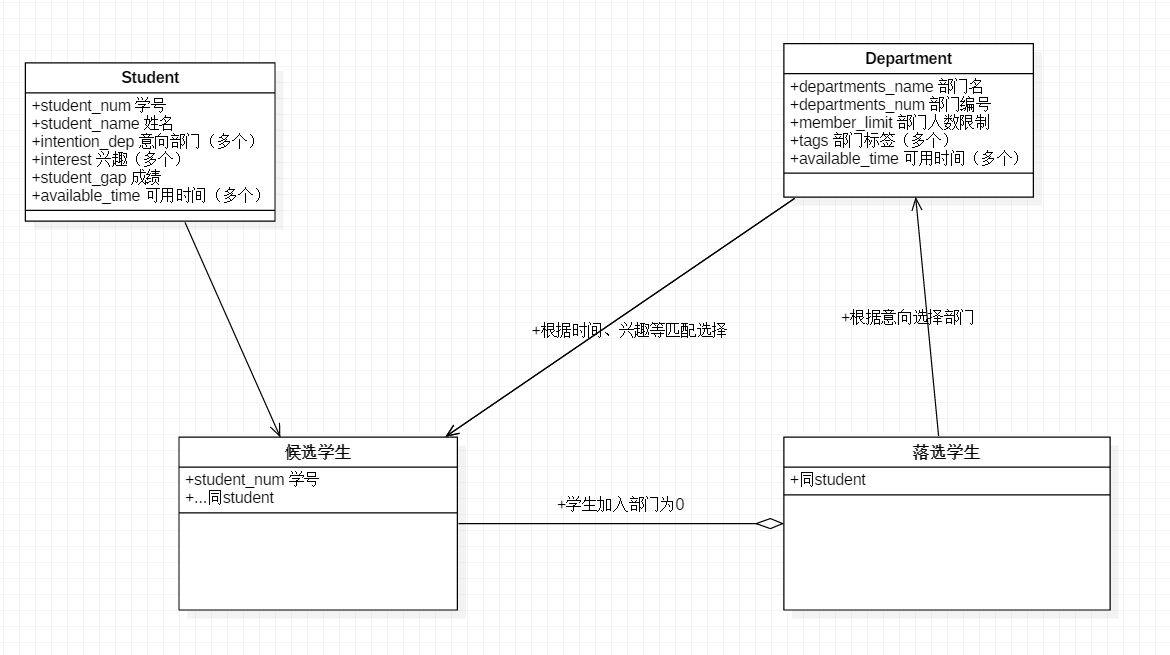
-
API接口设计
public MyC allocate
{
public void Myjson();//读入与处理json数据
public void FDmatching();//实现第一次分配
public void SDmatching();//实现第二次分配
public void TDmatching();//实现第三次分配
public void Prin();//输出
}
-
匹配算法的设计
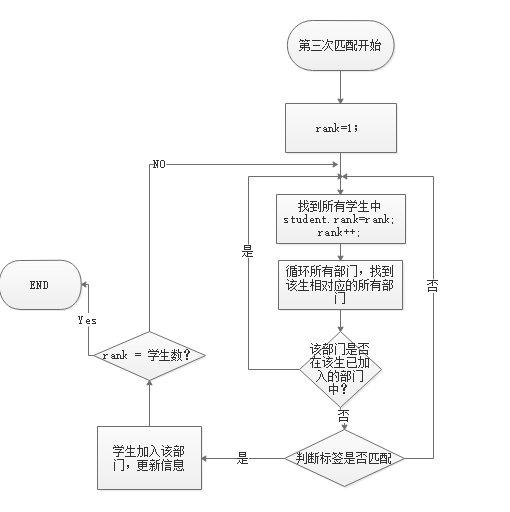
1. 流程图
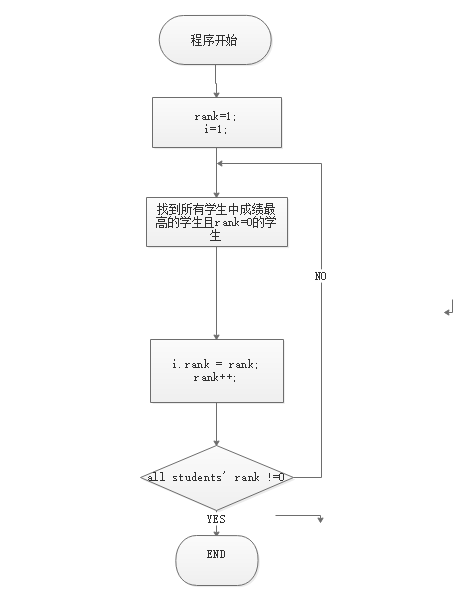
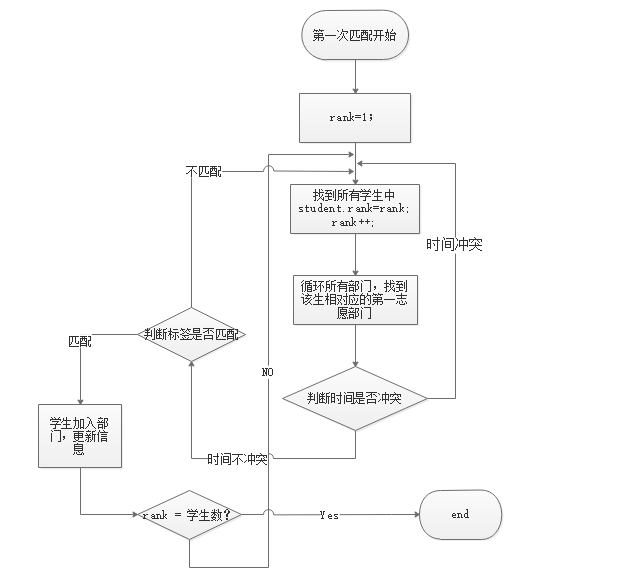
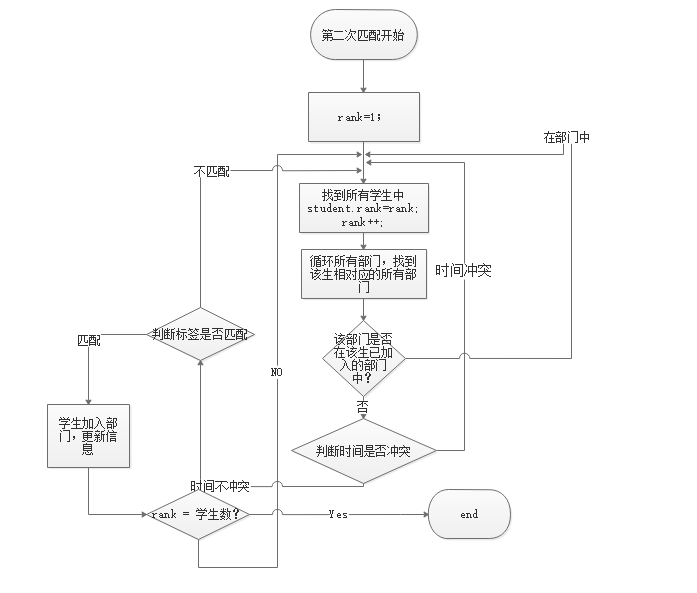
2.匹配思想
-
Step1:为了不让后生成的学生的优先级过低导致不能进入部门,首先以高考成绩换算成的评分(随机生成)排名,从高到低排名,给每个人一个rank排名。
-
Step2:在第一步的前提下,以第一志愿优先原则:从rank为1的学生开始,遍历其第一志愿,当第一志愿对应的部门的人数没有满的情况下,进行匹配判断,匹配判断分为以下两步:
-
Step 2.1 进行时间判断,将学生的空闲时间段与部门的基础活动时间段进行匹配,当两个时间段中有1个时间段互相匹配(同一时间段或者学生的空闲时间段大于部门的活动时间段),进行下一步判断。
-
Step 2.2 时间判断满足的情况下,进行标签匹配。将学生的兴趣标签与部门的标签进行一一对比,只要其中有两个两两匹配,即满足判断,更新学生信息与部门信息(学生:加入部门信息、加入部门数 部门:成员信息、部门人数、部门人数上限等)
-
Step3 对所有的学生,依旧按照成绩排名,从rank为1的学生开始,遍历其所有志愿,当其志愿对应的部门的人数没有满的情况下,进行匹配判断,匹配判断分为以下两步:同上
-
Step 3.1 进行时间判断,将学生的空闲时间段与部门的基础活动时间段进行匹配,当两个时间段中有1个时间段互相匹配(同一时间段或者学生的空闲时间段大于部门的活动时间段),进行下一步判断。
-
Step 3.2 时间判断满足的情况下,进行标签匹配。将学生的兴趣标签与部门的标签进行一一对比,只要其中有两个两两匹配,即满足判断,更新学生信息与部门信息(学生:加入部门信息、加入部门数 部门:成员信息、部门人数、部门人数上限等)
-
Step 4 最后一轮匹配,对所有的学生,依旧按照成绩排名,从rank为1的学生开始,遍历其所有志愿,当其志愿对应的部门的人数,且学生的已加入部门信息没有该部门没有满的情况下录取。
-
测试数据如何生成(由队友完成)
部门部分
-
部门名(department_name):部门名由事先设定好的字符串,通过随机数的组合进行随机生成,由于在下面学生的意向部门中需要用到部门名,因此先用一个字符串数组先存起来。
-
人数上限(member_limit):单个,数值,在[0,15]内,这是题目要求,但是考虑到部门的实际情况,一个部门不可能纳新人数0人,而且数字比较小,也比较奇怪,因此我们加上底数限制,范围在[10,15]中,实现方法也比较简单,只要通过一个简单的随机程序,在这个区间内随意生成一个数字即可。
-
部门特点标签(tags):首先我们预设9个标签,但是当我们数据测试的时候其实有考虑标签的匹配,如果总标签数少,这一层的匹配率相对来说太高,也就是标签匹配没有发挥作用,因此我们将其扩充到17个,经过测试,效果上有所改善,匹配率下降了2个百分点左右,表明标签匹配发挥了作用。我们的实现方法也比较简单,预取3个目标标签,但是要考虑重复部分,因此在0-16随机生成三个数,经过简单的if去重,得到三个不重复的随机数,作为数组标志,抓取标志。
-
部门常规活动(schedule_time):最初的想法就是星期输与时间数的随机匹配,时间是控制在10点到23点。这是符合实际情况的,部门工作有一块很重要的内容就是值班,因此需要安排每个时间段都需要人值班,因此部门活动时间是一个跨度比较大的范围。实现方法也是,星期数是预存数组的随机,时间则是在10-21点随机一个数字,后一个是加上2,表示成字符串。
学生部分
-
学生姓名(student_name):原先采取和部门名一样的生成方法,生成一个乱码的字母组合来表示,后来可能觉得蛋疼,太蠢了!于是觉得做一点合乎常理的事,名字嘛,就该有正常的姓和名。于是做了三个姓和名的数组,全是将我们班级的人的姓,慢慢打入,还有所有名字拆成两个字,考虑到最终有5000个,因此每个数组分别20、35、38个,总数20 * 35 * 38 > 5000,即直接投入使用。当然会考虑到重复的问题,在下面的模块会简单阐述。
-
学号(student_number):作为一个并没有很大影响的标识(因为在名字设立板块采取去重,即无重复名字,因此名字可作为唯一标识),学号这块就主要是0315+8位的随机数组成学号,0315表示数计学院15级学生,也是有良好的寓意的。
-
兴趣标签(Interests):本块内容与部门部分的标签相似,不做累赘说明。
-
绩点(gap):绩点这块实现难度上就不说了,比较简单,谈谈实际情况。由于福州大学今年绩点改革,因此我们决定跟上潮流,才取阶梯制加上十分制,比如87分、80分和85分的绩点都算作9,65分和60分绩点都算作6.0,也就是不再是一分一绩点,而是一段一绩点的形式。
-
意向部门(intention_dep):这一块内容也比较简单,将部门生成名字时存入的数组进行调用,随机产生三个不同的该范围内的随机场,进行调取部门。
-
可用时间(available_time):最初的想法和部门常规活动时间一样,最终改变的原因主要有两个,一个是匹配的问题,因为时间以段为单位,在时间生成上产生了11*7=77种可能性,再加上部门和学生的可用时间需要三个标签最终进行匹配,导致匹配率极低;第二个是实际情况,如工作日的10点-17点,很明显是属于学生的学习时间,不太可能将部门活动时间定在这个时间段,正常的可用活动时间段应该控制在工作日的晚上19点-23点,以及周末的一整天,实现方法是在部门的简单随机上,加了两个if的判断,即可实现。
-
如何评价自己的算法
咳咳,算法方面一定要自我检讨一下了,因为匹配算法是自己写的。算法只考虑了匹配过程的可执行性,在复杂度方面没有做过多的考虑,甚至出现了三层嵌套for循环的情况,结果就是导致在最大的5000students、100departments时,要30几秒才能完成运行,每次都等得自己要疯,队友要打人。
对不起队友,对不起老师,对不起国家。。。。。。。
-
4、关键代码解释
尴尬了,这种代码真的是来个freestyle就是:这个代码又臭又长,这个人他又笨又。。。。算了不骂自己了
int rank = 1;
for (i = 0;;i++)
{
if (stu[i].rank == 0)
break;
else if (stu[i].rank == rank) //找到当前排名的学生
{
j = 0;
while (dep[j].departments_name != "NULL")
{
if (dep[j].departments_name == stu[i].intention_dep[0] && dep[j].member_limit!=0)
{
//判断时间是否冲突
bool flag = false;
int e = 0;
while (dep[j].available_time[e] != "NULL")
{
int q = 0;
while (stu[i].available_time[q] != "NULL")
{
if (mtime(dep[j].available_time[e], stu[i].available_time[q])) //如果有一个时间段符合就被录取
flag = true;
q++;
}
e++;
}
if (flag == true)
{
//判断便签是否有一个符合
bool tflag = false;
int a = 0;
while (dep[j].tags[a] != "NULL")
{
int b = 0;
while (stu[i].interest[b] != "NULL")
{
if (dep[j].tags[a] == stu[i].interest[b]) //有一个标签符合就返回正确
tflag = true;
b++;
}
a++;
}
if (tflag == true)
{
//更新学生信息
stu[i].match[stu[i].matching] = dep[j].departments_name;
stu[i].matching++;
//部门信息更新
dep[j].member_limit--;
dep[j].member[dep[j].matching] = stu[i].student_name;
dep[j].matching++;
break;
}
}
}
j++;
}
rank++; //排名到下一位
i = -1; //让程序回到第一个学生重新开始遍历
}
else continue;
}
自行感受。。已第一次匹配为例。我一定要把它改掉。用某神的话,要优雅。。。。。
5、性能分析
-
接下来已s5000-d100为例,先上图
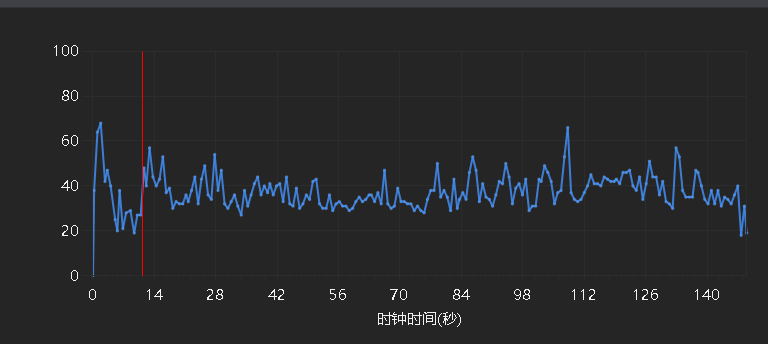
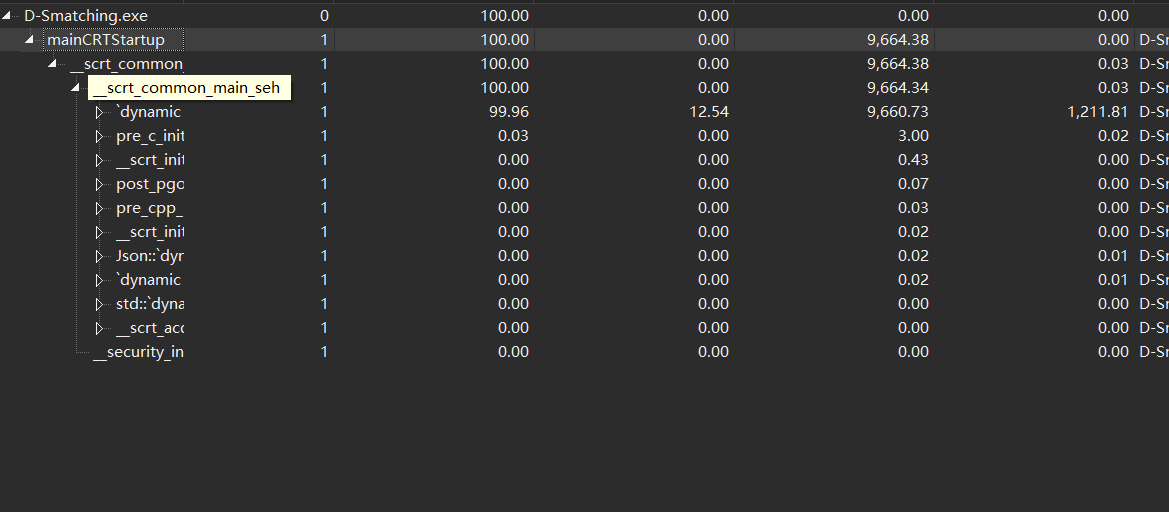
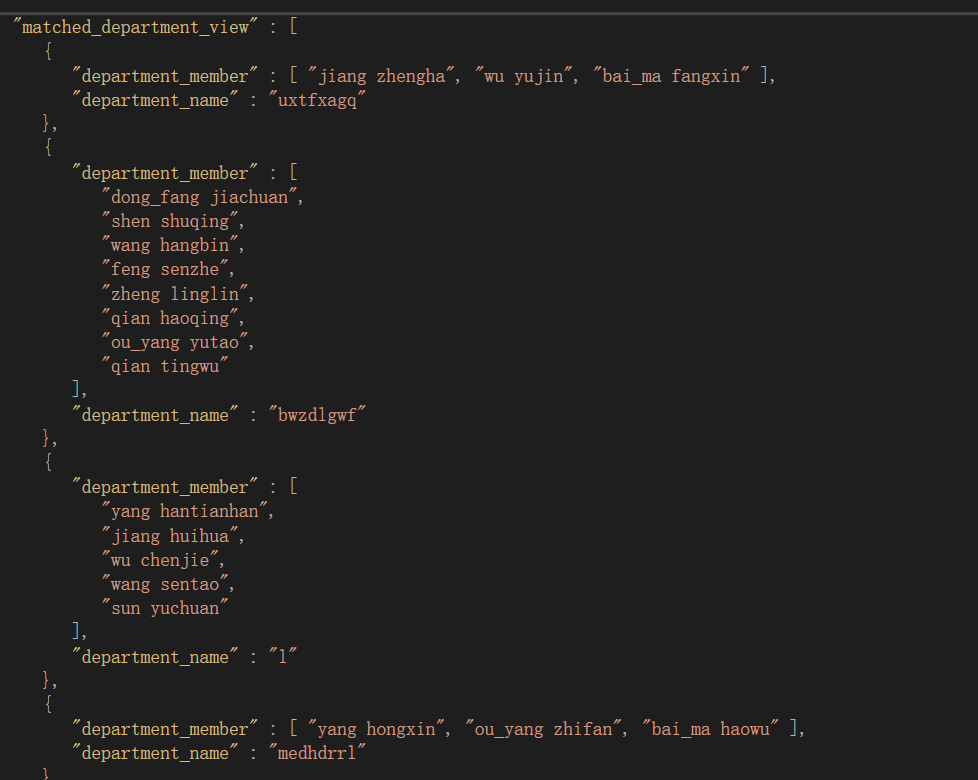
- s5000-d100
link
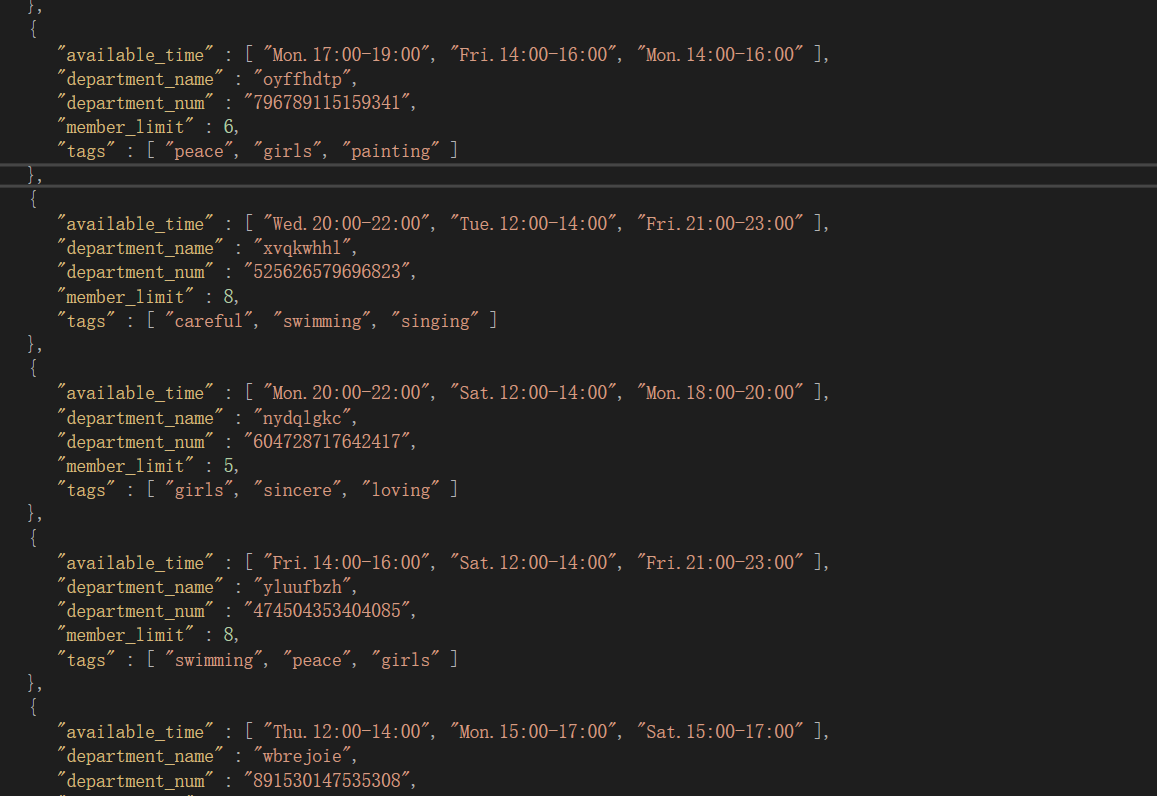
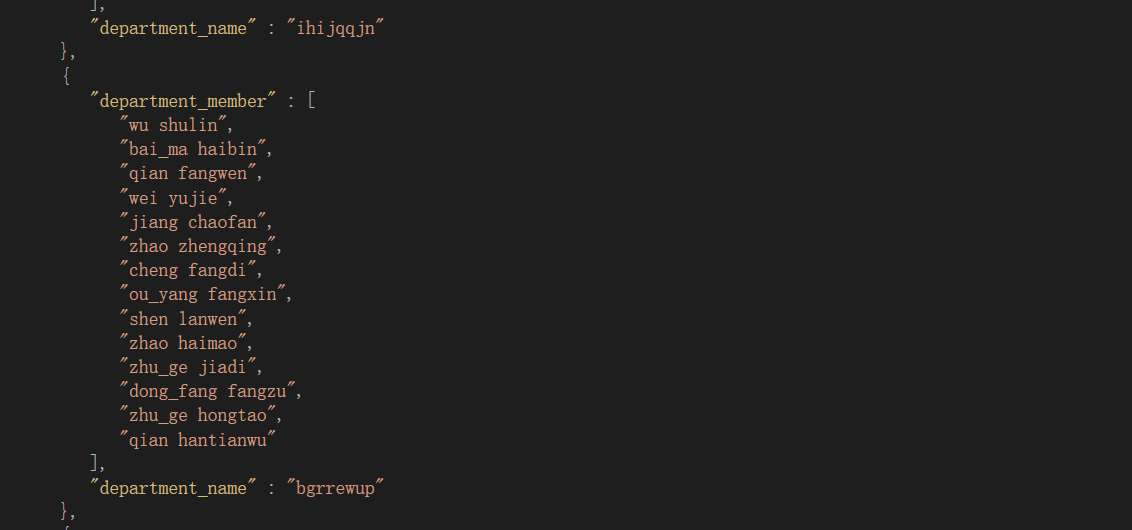
-
6、所遇到的困难以及对队友的评价
-
遇到的困难
刚开始对这次的例如json、匹配等两个人都不是很懂,也不找到该怎样入手,后来慢慢的摸索后总算走上了正轨。
我自己在写算法时,再随着慢慢的数据的变大,里面一些内容的更新,也是不断的出现错误,到后来是自己一遍一遍一行一行的跑完,才完成了算法,虽然很不优雅,但是算是完成了吧。
-
对队友的评价
就祝你保重,越来越重。
-
7、PSP、学习进度条
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 5 |
| · Estimate | · 估计这个任务需要多少时间 | 120 | 60 |
| Development | 开发 | 60 | 30 |
| · Analysis | · 需求分析 (包括学习新技术) | 50 | 20 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 20 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| · Design | · 具体设计 | 20 | 30 |
| · Coding | · 具体编码 | 120 | 240 |
| · Code Review | · 代码复审 | 60 | 120 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 100 |
| Reporting | 报告 | 60 | 30 |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 730 | 715 |
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 120 | 120 | 3.5 | 3.5 | 了解了软工的艰难,坚定了信息 |
| 2 | 720 | 840 | 30 | 33.5 | 国庆屁颠屁颠得跑到学校打代码,很开心(心里mmp) |
| 3 | 400 | 1240 | 21 | 54.5 | 开始学习Python |
| ---更新 |

